FFmpeg在Intel GPU上的硬件加速与优化

英特尔提供了一套基于VA-API/Media SDK的硬件加速方案,通过在FFmpeg中集成Intel GPU的媒体硬件加速能力,为用户提供更多的收益。本文来自英特尔资深软件开发工程师赵军在LiveVideoStackCon 2017大会上的分享,并由LiveVideoStack整理而成。
文 / 赵军
整理 / LiveVideoStack
大家好,今天与大家分享的主题是FFmpeg在 Intel GPU上的硬件加速与优化。
1、Media pipeline review

上图展示的是典型的Media Pipeline。我们知道,FFmpeg对输入格式支持非常的全面,可以是文件、网络流等,也可以使用Device的Caputer作为输入;输入的音视频经过Splitter后一般会分为两种常见场景:Play Back与Transcoder。上图的右上半部分实际是一个Transcoder的基本流程,解复用之后的Video、Audio的ES流,再经过Video、Audio的Filter,大部分情况下,Video有可能在AVFilter执行一些Scale、Frc、Crop操作(也可以在AVFiter中抓取有价值的信息);随后音视频数据会被转码成为用户指定的格式,转码时候多伴随着码率转换、指定IPB帧类型等;Audio也会经过类似的处理流程。上图的右下半部可以视为播放器处理流程也就是Playback,Playback流程与Transcoder处理流程的主要差异在于对解码的数据是否进行再次编码或者直接显示。另外,众所周知,Encoder与Decoder的复杂程度存在一个数量级的差异,计算复杂度大概为10:1,且一般情况下Encoder每十年进化为一代,从MPEG2发展到H264大概用了十年时间,而从H264发展到HEVC将近十年时间(实际不到十年),其计算复杂度提升均为上一代的十倍左右,但压缩率提升大概只有40%到50%,其背后是对计算量的大幅渴求,CPU的计算能力有时不能实时跟上计算量的需求或在高转码密度条件下不能提供较好的性价比,在此背景下,Intel提出了基于Intel GPU的媒体硬件加速解决方案。
2、何谓FFmpeg/VA-API?

作为最为流行的开源媒体解决方案,FFmpeg有两种使用方式:直接使用它自带Tools,或者把FFmpeg作为Library调用它的API而实现自己的逻辑。其中的Tools包含我们经常看到的转码工具FFmpeg;轻量媒体播放器FFPlayer;进行格式的探测分析的FFProbe ;轻量级流媒体测试的服务器FFServer等。另外,FFmpeg的内部实现基本以C语言为主,辅助以部分汇编优化;同时它支持Linux、MacOSX、Android、Windows等不同OS,有着良好的跨平台兼容性。这里另外强调一点的是FFmpeg自身的License问题,也许国内的厂商不会特别在意License,但在实际使用场景中,所使用软件或者库的License即版权是不能不考虑的问题。最近几年FFmpeg已经将License的问题澄清得比较清楚,目前它的大多数内部实现代码使用GPL2.1版本的License。
3、Linux Video API

接下来我将介绍Linux平台上Video加速API的进化历史。我们知道,每一个突破性创新都是从细微之处开始慢慢演化,最后才可能成为举世瞩目的创造;另外很多技术的进化过程中,都是工程与算法科学相互交织,Linux上的硬件加速API的进化流程也遵循了这一点。最初的Linux Video API被称为Xv,基本只能借助硬件加速实现Scaling与Color Space Conversion两个功能,明显无法满足行业需求;随后经过扩展,使得在那个MPEG-2称霸的时代实现了对MPEG-2 Decoding硬件加速API的支持, 也就是Xv/XvMC,不过这一部分在当时还停留在比较初级的阶段,iDCT、XvMC-VLD等还未实现被API所标准化;随后社区便开始尝试实现Slice层加速API标准化,以避免之前包括不支持解码所有阶段硬件加速且依赖于X-Protocol协议等在内的诸多问题,演化到现在,最终的结果就是VA-API。
4、VA-API

当时的英特尔开始涉足硬件加速领域,于是在1999年左右英特尔提出VA-API接口。这是一套在Linux上的标准接口,从上层来看大家可以将其理解为一个OS层面的Video加速Spec,且与硬件无直接关联。这套通用接口,同时需要特定的后端实现支持。与大多数开源项目相似,VA-API并没有一个特别好的Document进行说明,需要自己仔细的去读它的头文件以了解其设计思想和细节。另外,既然这是一个Spec,其设计上自然想剥离与特定硬件的强关联,所以虽然今天我的分享主要围绕Intel GPU实践进行,但实际上VA-API这套Spec并不只限于英特尔的GPU。
5、VA-API可用的后端驱动

VA-API可用的后端驱动非常多:Intel VA(i965)Driver是Intel OTC Team开发的一套全开源驱动,随后也出现了Intel Hybird Driver、Intel iHD Driver等;在后端实现中还有Mesa‘S state-trackers包括Radeon、Nouveau、Freedreno等的支持,另外,还有些公司开发了一些API Bridge,包括Vdpau-va Bridge、Powervr-va的bridge以提供VA-API的支持,但这些bridge大部分由于种种原因慢慢转为封闭而逐渐被废弃;与此同时,英特尔的态度则更为开放,它希望大部分的开发者有能力在现有成熟平台上进行更深层次的定制与探索,开放出更多的硬件能力以及驱动代码,这也是英特尔作为一个开源大厂的风范吧。
6、Intel GPU

Intel GPU从Gen 3的Pinetrail发展到Gen 9.5的Kabylake,每一代GPU的功能都在增强,在Media上的能力也在增强。关于GPU性能我们比较关注以下三部分指标:第一部分是3D渲染能力,这一部分的标准化程度较好,可以使用标准接口包括OpenGL或Vulkan,当然也有Windows上可与OpenGL与Vulkan适配的DirectX等;第二部分是Media;第三部分则为通用计算,其中包括NVIDIA的CUDA与AMD、ARM等公司采用的OpenLL。附带说一句,有人会混淆GPU的通用计算能力与Media处理能力,以为通用计算能力很强,则Media能力就很强,这并不正确,实际使用中,需要把这三个指标分开来根据具体的使用场景来分析与比较,以挑选最合适的硬件方案。
6.1 Intel GPU Media 硬件编程模型
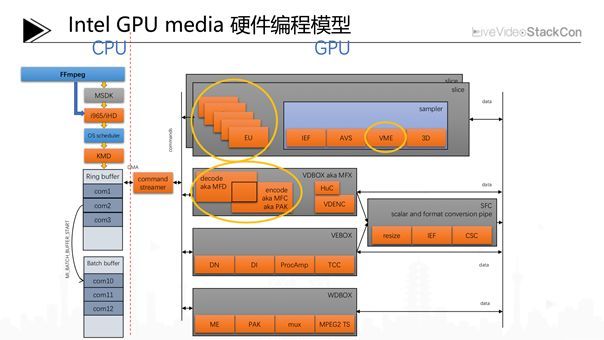
从FFmpeg到具体的GPU,是如何进行一些Media处理的?首先FFmpeg会通过VA-API接口,调到对应的Driver例如i965或iHD,之后数据经过OS Scheduler进入OS KMD,接下来经过一系列硬件编程抽象和GPU&CPU数据交换,生成Command streamer并传输给EU(也就是Intel GPU中的一个计算执行单元)或者特定的IP以执行相关的Media任务。注意,GPU的Media部分有时也会使用EU这些通用计算资源,而像Sampler、VDBOX、VEBOX、SFC等都是基于一些特定的Fix Function硬件实现相应功能。所以,可以这样理解,英特尔的GPU实际上是将媒体的大部分功能通过Fix Function方式实现,同时必要时候使用EU作为一个通用的计算资源这样协同工作的。
6.2 FFmpeg & Intel GPU加速方案

大部分客户偏向于使用FFmpeg的同时,也希望其具备出色的硬件加速能力,我们现在致力于在FFmpeg中集成Intel GPU诸多的媒体硬件加速能力,使用户可通过FFmpeg的接口使能调用英特尔的GPU的各种能力从而带来更多收益。这里的集成方式主要有两种:1)直接实现为与FFmpeg融为一体的Native Decode/Encode。FFmpeg的大部分Decode如H.264、H.265、VP8、VP9等都使用Native Decoder的方式,2)Warpper第三方库的,如在FFmpeg中集成Libx264的方式;现在部分Encode都以第三方库的形式集成进FFmpeg的。根据上图我们可以看到在Intel GPU中集成了两个Plugin到FFmpeg中:第一个是QSV Plugin,其类似于libx265的做法,其Codec实现的底层与MediaSDK相关;但FFmpeg社区更倾向于基于libva/vaapi的方式,即直接在FFmpeg中进行集成,不warpper第三方的库,一是因为此方案相对而言更加轻量,二是因为此方案更加开放;这样做意味着将全部的硬件Codec部分的代码都集成在FFmpeg中,与FFmpeg融为一体,如果客户希望进行定制或改变,那么直接在FFmpeg内部代码中修改即可实现。除了解决基本的解码/编码硬件加速问题,我们也在考虑集成OpenCL、OpenCV等以适应客户的一些其他需求。
6.3 Intel GPU 支持
1)解码支持
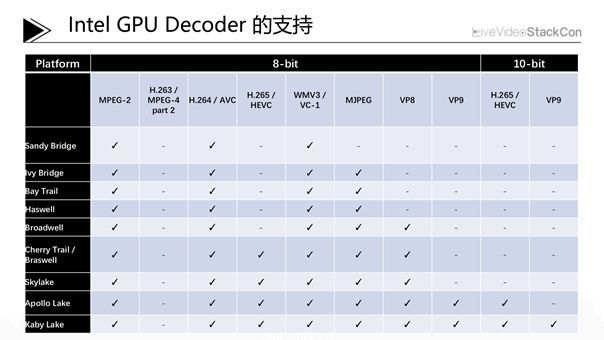
上图展示的是Intel GPU Decode部分的的支持状况。一般情况下我们可以将Decode分为8Bit与10Bit,以HEVC为例,有一些数据显示10bit的压缩率要高于8bit,感兴趣的同学可以思考一下其原因。从表也可以看到,英特尔的各代GPU逐渐进化,从开始只支持MPEG-2、H.264、VC-1解码的Sandy Bridge到增加了MJPEG解码支持的Ivy Bridge再到多用于嵌入式平台的Bay Trail乃至之后的Haswell,从Broadwell开始对VP8的支持与Cherry Trail/ Braswell对HEVC的支持再到Skylake之后的Apollo lake与 Kaby lake对VP9解码与10bit HEVC&VP9的解码支持,其解码能力稳步增加。
2)编码支持
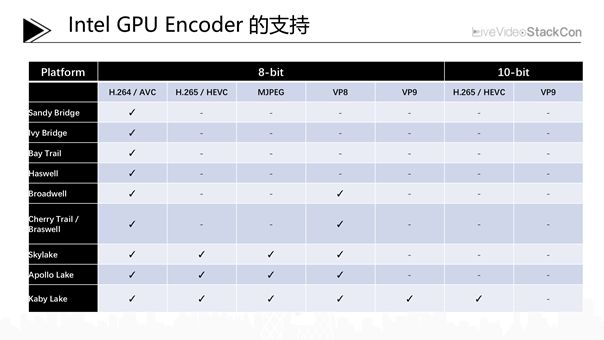
编码方面,Intel GPU很早开始就支持了H.264编码,到了Broadwell增加了对VP8的支持;而Skylake则增加HEVC和MJPEG,到了Kaby Lake时我们增加了对VP9和10Bit HEVC的编码支持。关于VP9我想强调一点,据我所知,现在量产的SoC/GPU/CPU中可能只有英特尔的Kaby Lake及其后续的产品与三星的SoC支持VP9的编码硬件加速。
6.4 使用案例

上图展示的这些Use Cases可基本涵盖大部分用户的使用场景。解码部分主要是使用hwaccel vaapi进行硬件解码,由于一款设备上可能存在多款GPU,因此我们需要是hwaccel_device选择不同的硬件设备。对比硬件编码与硬件解码我们不难发现,在解码部分我们使用hwaccel_device而编码部分则使用vaapi_device。这里的vaapi_device是一个Group Option,因为FFmpeg中存在Group Option与Per-Stream Option,解码部分的hwaccel_device是Per-Stream Option,而编码部分的vaapi_device是全局的并且Decoder和Encoder只需指定一次。从上面看来,转码的例子更为复杂,首先进行硬件解码,而后在GPU中进行de-interlace与Scall和HEVC编码,实际上整个过程是一个硬件解码结合GPU中的Deinterlace/Scale和随后的HEVC硬编的过程,这里需要注意一些关于码控设定的问题,对此问题有兴趣的同学可以直接阅读FFmpeg的文档或者代码。
7、FFmpeg硬件加速全览
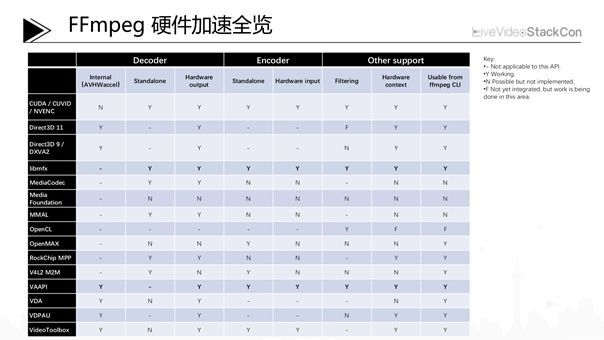
上图展示的是FFmpeg硬件加速全览,我想这一部分对探索基于FFmpeg实现跨平台的开发者来说非常有帮助。开发者经常需要面对不同的硬件厂商:Intel、NVIDIA、AMD等等,他们希望仅仅与FFmpeg经过一次集成,就可在不同硬件上实现同样的功能。而现实情况,即是存在OS层面可以进行硬件优化的API诸如Windows上的Dxva或MacOS上的VideotoolBox、Linux的Vaapi等,其实现可能还是非常分散,而FFmpeg在支持各种硬件加速接口之后,则帮助解决了上面的这个问题。另外,对于上表,Decoder部分只列举了是否支持硬件surface的输出。除此之外还有一些附加功能例如Filter,作为FFmpeg中非常重要的一部分,它主要是为了进行Video 后处理等;上表中的Hardware Context是指基于FFmpeg内部的硬件加速接口的实现,Useable from FFmpeg CLI是指FFmpeg的命令行是否直接可用硬件加速(它的典型使用场景是,在Server端将FFmpeg直接作为工具使用,通过PHP在后端直接调用FFmpeg的Tools)。另外,如果开发者需要调用FFmpeg API进行解码,此时需要关注Hwaccel的支持情况。最后我想强调一下图中Decoder部分里的Internal和Standalone。它实际上是一个历史遗产,在FFmpeg中,很早便实现了H.264的软解码,在此基础上,如果想使能GPU的解码能力则需要面临以下两个选择:可以选择重新实现有别于软解码的另一套基于GPU解码实现,可以考虑为需要完整实现一个类似h264_vaapi的解码其;也可将解码相关的一些硬件加速工作直接Hook在已有的软解码Codec中,当时的开发者选择了后者,所以大部分基于OS的硬件加速解码方案都基于后者的方案也就是Internal AVHWaccel;但诸如NVIDIA等提供NVDEC,NVENC的方案,因为自身已经是一个完整的硬件解码器,所以在FFmpeg内只需实现成一个简单的wrappe人即可,不需要借助FFmpe已有的软解码Codec的任何功能。
8、FFmpeg VA-API的细节信息

上图展示的是FFmpeg VAAPI的一些细节信息,之前我已经对HWAcceled的解码与Native的解码进行了说明。提及编码,硬件加速的编码带来的最大好处是速度优势:我曾经基于Skylake-U这样双核四线程的低电压CPU上测试1080P的转码,基本可实现240FPS的实时转码;同时,在大规模部署时不能不考虑功耗比与性价比,也就是单路的编码或转码需要消耗多少电能以及单路转码的成本。现在集成了GPU的英特尔PC处理器,其功耗在40~65w,如果是面向服务器工作站的Xeon E3系列,可在一个65w的处理器上实现14到18路的1080P转码,而能达到相同性能的NVIDIA GPU所需的能耗大约在300w左右。另外,对于硬件编码,有一些客户可能在图像质量上有更高的需求,现在英特尔的GPU在低码率上处理效果还有提升空间,但在处理中高码率文件时,其评测结果与X264相比并无明显的差距。如果客户期望借助自己的一些高阶算法通过更深度的定制实现更强大的功能,Intel也开放了被称为Flexible Encoder Interface (FEI)的底层接口。此接口可详细全面展示Intel GPU的全部硬件编码能力,并让用户拥有足够的灵活度去Tunning各种算法;如果说FFmpeg代表的是一个可以直接调用的成熟平台,那么FEI则是可定制Codec算法的通用接口。与此同时,FEI对客户的能力要求也更高,如果有高阶深层次定制化的编码需求,可以考虑FEI。最后,附带一句,我们同样在AVFilter中集成了GPU的VPP以实现硬件加速的Scaling与Deinterlace等操作,后续也会支持Overlay、CSC等。
9、其他问题

9.1 CPU与GPU的数据交换
当我们在处理一些异构计算时,始终需要面对此问题:CPU与GPU、DSP之间的数据交换。数据从CPU拷贝到GPU与从GPU拷贝到CPU并不是一个对等关系,一般而言,数据从CPU到GPU进行拷贝的速度很快且不存在性能瓶颈;而如果是GPU到CPU的拷贝交换有可能面临性能瓶颈,其原因是两者使用了不同的缓存策略。如果我们通过mmap GPU的memory到CPU侧,之后不进行任何优化而是直接使用诸如memcpy函数将数据拷贝到CPU侧,会发现性能可能不如预期。关于这个问题,英特尔也提供了一些优化办法,例如使用SSE4/AVX等指令集中提供的bypass Cache的特定指令,也就是所谓的Faster Copy背后的特定指令;另外,也可考虑直接用GPU进行拷贝而非使用CPU,或者考虑从OpenCL层面进行优化。
9.2 FFmpeg中的硬件加速
FFmpeg提供了一些Filter用于实现硬件加速pipeline的建立,分别为Hwupload、Hwdownload、Hwmap、Hwunmap,使得在组成硬件的Pipeline时尽量避免大量的数据交换,所有操作尽量在GPU内部直接完成以提升性能。
9.3 硬件或驱动不支持
如果完成了编解码的部署,需要AVFilter相关的优化但硬件或者驱动层面却不支持,面对这种情况,我们可考虑OpenCL。因为OpenCL现在可与FFmpeg Video的编解码进行Buffer Sharing,这相当于是一个GPU内部零拷贝的过程;只需要依靠Hwmap和Hwunmap实现的map就能直接用OpenCL对现有的AVFilter进行优化,从而帮助开发者解决此类由于CPU/GPU的数据交换导致的性能问题,与此同时,把OpenCL作为对GPU通用计算的标准接口,来优化我们的各种视频或图像的处理;另外,我们可以将此思路放得更宽一点,如果客户不希望直接使用来OpenCL来手动优化AVFilter,也可考虑把OpenCV作为一个已经被OpenCL优化好的算法集合再集成进FFmpeg中。我们现在也在考虑此类方式并在其上进行尝试。
10、To Do List

上图展示的是我们正在实践与探索的技术点,期待通过以上优化为音视频行业带来技术进步与行业发展。