完美避坑!记一次Elasticsearch集群迁移架构实战
作者介绍
李猛(ynuosoft),Elastic-stack产品深度用户,ES认证工程师,2012年接触Elasticsearch,对Elastic-Stack开发、架构、运维等方面有深入体验,实践过多种Elasticsearch项目,最暴力的大数据分析应用,最复杂的业务系统应用;业余为企业提供Elastic-stack咨询培训以及调优实施。
前言
Elastic自身设计了集群分片的负载平衡机制,当有新数据节点加入集群或者离开集群,集群会自动平衡分片的负载分布。
需求背景
公司原有大数据平台基于公有云构建,由于种种原因,现在需要迁移到自建机房,Elasticsearch集群承担了大数据平台主要的对外查询需求,也有部分实时计算需求基于Elasticsearch实现,所以需要在不影响应用系统体验的情况下做到平滑的迁移。本次分享讲述我们如何进行平滑迁移以及如何避坑。
需要迁移的主要有两部分:
对外提供的服务API,这些API是与Elastic集群绑定的,属于业务场景定制化开发;
Elasticsearch集群迁移,数据需要迁移,节点也需要全部迁移。

图示:公有云集群+自建机房集群示意图,业务系统查询图
迁移策略
大数据平台的Elastic集群直接对外提供实时查询服务,任何影响Elastic集群平稳的操作都应该避免,那我们的集群迁移策略也侧重平稳,时间上可以宽松一些,迁移主要的工作有以下几个:
关闭集群自动平衡;
启动自有机房新节点与公有云自建集群组成一个集群;
人工迁移集群数据到新节点;
外围访问切换到新节点;
关闭公有云节点;
开启集群自动平衡。
迁移步骤
迁移过程中有很多步骤操作,是有严格先后顺序的,如果出错则会造成集群动荡,影响应用体验。此时Elastic的版本是6.5.X,当时最新的版本,迁移完成之后也全部升级到6.8.X。
1、原有集群架构

图示:原有集群架构,数据节点与管理节点分离
1)Elasticsearch节点有很多角色(管理节点、数据节点,协调节点),默认单节点常用角色全部开启。所以在早期搭建Elastic集群时,就按照角色分离的职责将管理节点与数据节点分离部署,这也是后面集群迁移能够顺利进行的重要前提。多数初学者在刚刚接触Elastic投入生产环境时会犯一个错误,节点角色不分离,当数据节点的资源消耗过度会导致集群管理节点响应变慢,从而影响整体集群响应。
#管理节点角色设置
node.master: true
node.data: false
#数据节点角色设置
node.master: false
node.data: true
2)Elastic对外提供服务时中间会增加一层负载代理,如定制服务API与实时计算应用访问Elastic集群都需要走代理。
3)Hadoop集群与Elastic集群互相访问是基于官方提供的ES-Hadoop驱动包,由于实现原理的限制,不能做代理,所以是直接访问,都是离线任务交互。
2、配置新集群
1)因为是迁移到新集群节点,原有节点最后都需要关闭,新集群节点同样也需要管理节点与数据节点分离,新旧节点需要平滑迁移,所以新旧节点在启动之后就需要在同一集群中,新节点Hosts同时指向新管理节点与旧管理节点 ,关键设置如下:
#配置管理节点IP+PORT
discovery.zen.ping.unicast.hosts: ["多个旧管理节点 IP:PORT","多个新管理节点 IP:PORT"]
2)新集群服务器采用的全部是物理机,CPU核数很多,内存充足,挂载了多个硬盘,为了充分利用物理机性能,所以单服务器会部署多实例,主要是部署多个数据节点。在同一机器启动多个Elastic实例,需要做资源隔离,尤其是CPU核数隔离,CPU的核数决定了Elastic默认线程池的线程数,如果不做设置,默认启动多个数据实例,会出现资源竞争问题,设置如下:
#配置处理器数量
processors: 数值<=(CPU核数/实例数)
3)公有云与自建机房直接通过专线连接,新旧集群节点在启动之后依然是一个集群。
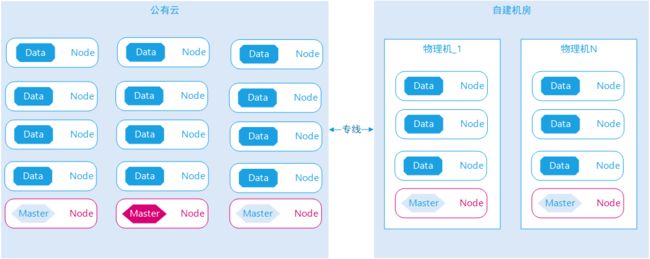
图示:新旧集群示意图与多实例示意图
3、禁用集群数据平衡
Elasticsearch集群有自动的数据分片平衡分配机制,默认是按照分片的数量平均分布,集群每个数据节点上的索引分片数量默认是相同的,最多有奇偶不一致。
当有新的带有数据角色节点加入集群或者离开集群,集群会默认启动自动平衡机制,索引分片会在数据节点之间平衡漂移,达到平均分布之后停止,频繁的集群节点加入或者下线会严重影响集群的IO,影响集群响应速度,所以要尽量避免次情况发生。说到这里,在我的从业中,发现很多初级运维人员在部署Elastic集群时,会很喜欢设置系统级别Elastic实例进程自动启动,这个其实是个很糟糕的机制,当发现服务器Elastic实例关闭,不是马上重启,而是需要人工介入分析具体原因,如果频繁关闭重启,这样很容易造成集群问题。
1)第一个是禁用集群自动平衡,首先要禁止集群新创建索引,新索引之间分配到新的数据节点,其次防止新的数据节点启动之后,集群分片开始平衡迁移,影响集群IO,设置如下:
#禁用集群新创建索引分配
cluster.routing.allocation.enable: false
#禁用集群自动平衡
cluster.routing.rebalance.enable: false
2)第二个是限制已有索引数据的分布范围,暂时只容许分布在旧的数据节点上,旧集群数据节点在早期部署时并未设置自定义标签,所以只能通过设置IP范围限制,还有就是后面在迁移数据时需要按找索引维度逐步迁移,控制集群迁移的并行度。设置如下:
#限制索引的分布范围
"index.routing.allocation.include._ip": "多个旧集群IP"
4、启动新集群数据节点
在禁用旧集群的数据自动平衡之后,启动新集群数据节点,这一步是安全的,可以全部启动,此时集群数据节点有很多,旧数据节点有数据,新数据节点无数据,新的数据节点无任何查询与写入。
由于新数据节点是全新搭建,可以提前设置节点自定义属性,方便之后运维设置。设置如下:
#集群机架属性
node.attr.rack: rack1
#集群数据中心
node.attr.zone: zone1
#实例节点硬盘
node.attr.disk: ssd1
#更多属性......
node.attr.xxxx: yyy1
...
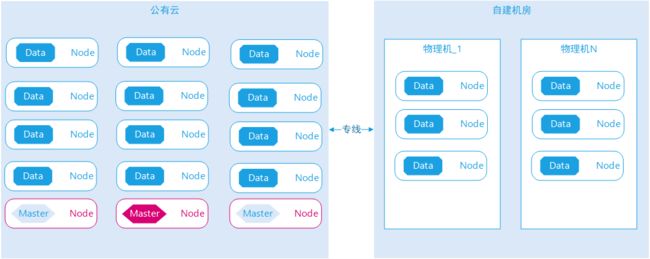
图示:仅优先启动数据节点
5、切换集群访问
Elasticsearch集群主要有几个使用方:
1)Hadoop平台离线数据写入ES,从ES抽取数据。Elastic提供了Hadoop直连访问驱动。如Hive是通过创建映射表与Elasticsearch索引关联的,新的数据节点启动之后,原有所有Hive-Es映射表需要全部重新创建,更换其中的IP+PORT指向;由于Hive有很多与Elastic关联的表,所以短时间内没有那么快替换完成,新旧数据节点需要共存一段时间,不能在数据迁移完成之后马上关闭。
#Hive指定连接
es.nodes=多个数据节点IP+PORT
2)业务系统应用实时查询。这种切换比较简单,Elastic集群对外提供了代理访问,业务系统应用访问首先要调用大数据提供的API,这些定制化的API内部也是通过代理访问Elastic集群。
3)大数据中心应用实时计算数据写入。实时计算程序上游有kafka队列,基于kafka自带的offset机制,在新集群启动实时计算应用,然后关闭旧集群实时计算应用,就可以完成切换。
6、手动转移数据
为什么要手动迁移数据 ?
公有云与新集群机房是跨网段,网络带宽有限;
集群中有很多大索引,单索引数据超过数百GB,这种索引移动会会很伤集群IO;
新旧数据节点会共存一段时间,自动平衡会导致大量的跨网络的查询与写入,很伤网络IO。
迁移数据的原则如下:
索引数据量小的优先;
离线更新的索引数据优先;
业务系统查询频率低索引数据的优先;
迁移索引数据控制并行度,每次操作控制在网络带宽限制之内。
迁移数据也是通过限制索引分布IP范围,设置如下:
#限制索引的分布范围
"index.routing.allocation.include._ip": "多个新集群IP"
7、关闭旧集群数据节点
关闭旧集群数据节点是一个逐步的过程,一个一个关闭,在一段时间内新旧集群数据节点需要共存,应用访问切换并没有那么快进行,且要支持随时回滚操作。关闭旧集群据节点有2个前提条件,如下:
旧集群索引数据必须迁移完成;
集群访问切换必须已经完成。
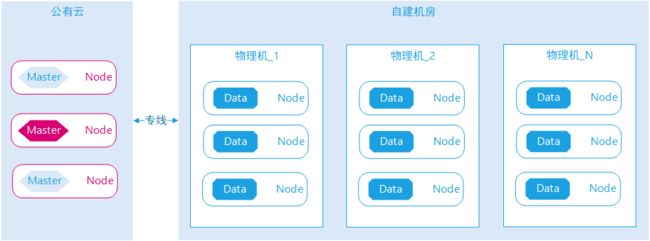
图示:关闭旧集群数据节点
8、启动新集群管理节点
为什么要在最后启动新集群管理节点?并且同步关闭旧集群管理节点?
一个Elasticsearch集群只有一个工作管理节点,负责维护集群所有的元数据信息;其余的是备选管理节点,只是同步集群元数据信息,不参与协调管理。工作主节点关闭集群需要重新选举工作主节点,此时集群会处于半停顿状态,虽然很快,也会有影响;
旧集群已经有5个管理节点,其中一个是工作主节点,其余4个是备选节点,因为Elastic版本是6.5.X,原有的集群脑裂因子设置是3=(5/2+1),当启动新集群的管理节点,若网络出现短暂通信问题,集群脑裂因子设置会无效。
切换新旧管理节点的策略如下:
每启动一个新集群管理节点 ,关闭一个旧集群备选管理节点;
最后关闭旧集群工作管理节点,集群重新选举新的工作管理节点。
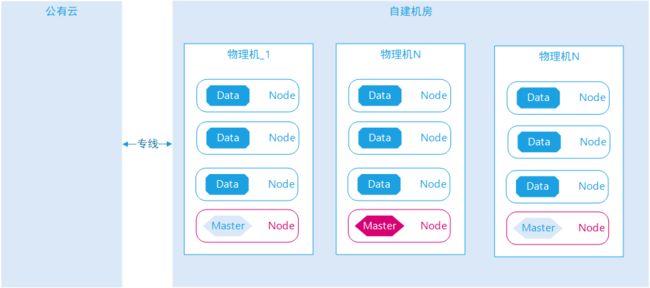
图示:启动新集群管理节点
9、启用集群自动平衡
在集群迁移之前,已经禁用了集群的自动平衡机制,集群迁移结束之后,需要恢复这种机制。
#禁用集群新创建索引分配
cluster.routing.allocation.enable: true
#禁用集群自动平衡
cluster.routing.rebalance.enable: true
涉及技术
1、集群弹性
在我们能如此平滑的完成Elasticsearch从公有云迁移到自有机房,得益于与共用集群这个概念。
个人认为这是Elasticsearch最大特性卖点,设计上任意节点都可以很容易加入集群或者离开集群,集群都可以弹性的平滑扩展,基本不影响系统运行稳定;
在业务系统发展早期,可以部署少量节点,发展后期可以部署更多节点或者部署更强的服务器,以达到最佳的性价比配置,从成本与性能平衡;
自动化运维方面节约成本,相比传统的关系型数据库集群规模庞大之后,需要关注的点很多,而Elastic很少,大中型集群规模以下几乎无需专门的Elastic运维人员。
2、集群选举
主从架构模式,一个集群只能有一个工作状态的管理节点,其余管理节点是备选,备选数量原则上不限制。很多大数据产品管理节点仅支持一主一从,如Greenplum、Hadoop、Prestodb;
工作管理节点自动选举,工作管理节点关闭之后自动触发集群重新选举,无需外部三方应用,无需人工干预。很多大数据产品需要人工切换或者借助第三方软件应用,如Greenplum、Hadoop、Prestodb。
3、节点角色
Elasticsearch支持多种节点角色,一个节点可以支持多个角色,也可以支持一种角色。

图示:集群节点角色
节点角色说明:
Master,管理节点,管理集群元数据信息,集群节点信息,集群索引元数据信息;
Voting,投票节点,参与集群管理节点选举投票,注意7.X以上版本才支持;
Data,数据节点,存储实际数据,提供初步联合查询,初步聚合查询,也可以作为协调节点;
Ingest,数据处理节点,类似ETL处理;
Coordinate,协调节点,数据查询协调、数据写入协调;
Machine Learning,机器学习节点,模型训练与模型预测。
4、协调路由
Elasticsearch集群中有多个节点,其中任一节点都可以查询数据或者写入数据,集群内部节点会有路由机制协调,转发请求到索引分片所在的节点。我们在迁移集群时采用应用代理切换,外部访问从旧集群数据节点切换到新集群数据节点,就是基于此特点。
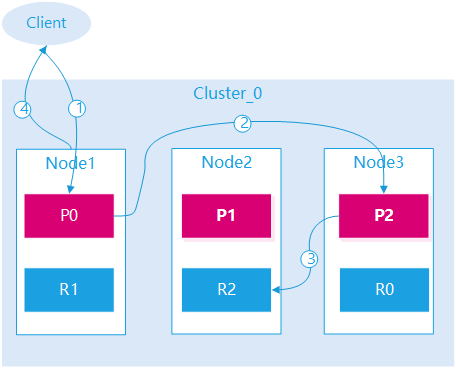
图示:集群路由示意图,查询过程/更新过程
5、分片副本
分片与副本是Elasticsearch集群实现分布式最重要前提。
分片机制,一个索引可以分成多个分片,分片数据可以分布在任意集群数据节点上,此机制可以保证我们迁移大的索引数据时,按照分片一个一个迁移,而不用一次性迁移所有的分片,有效减少磁盘IO与网络IO;
副本机制,一个索引主分片可以有多个副本分片,主分片与副本分片可以任意切换,无需人工切换。这种机制可以保证我们在迁移大的数据索引时,仅迁移主分片数据即可,有效减少磁盘IO与网络IO。
#副本设置
index.number_of_replicas: 数值,默认1
#分片迁移API
POST /_cluster/reroute
{
"commands" : [
{
"move" : {
"index" : "test_index", "shard" : 0,
"from_node" : "node1", "to_node" : "node2"
}
}
]}
6、分布过滤
Elasticsearch本身提供了多种索引分片分布过滤操作,特别是在集群规模比较大时,需要按照业务领域隔离集群资源。如有的业务索引是历史数据,数据量很大,仅偶尔低频率查询,可以做一些冷热分离设置。
# 分布过滤设置
index.routing.allocation.include.{attribute}
index.routing.allocation.require.{attribute}
index.routing.allocation.exclude.{attribute}
总结
Elastic集群迁移到物理机之后,运行性能较之前有很大的提高,并行写入性能提升好几倍,查询与写入交叉影响降低很多;
Elastic官方文档非常详细的描述了各种特性功能,但并没有针对数据迁移专门列举一个完整的步骤,掌握Elastic最好的方式是实战与理论并行,深入Elastic背后的实现原理,尝试多种项目的实战。
在跨越速运大数据部门任职时,基于公司实际需求,得出的一些经验与思考,提供后来者借鉴参考。
猜你喜欢
1、从行存储到 RCFile,Facebook 为什么要设计出 RCFile?
2、字节跳动 EB 级 HDFS 实践
3、Kafka架构原理,也就这么回事!
4、来自 Facebook 的 Spark 大作业调优经验

过往记忆大数据微信群,请添加微信:fangzhen0219,备注【进群】