prometheus配置企业微信报警
1. 告警概述
prometheus的告警管理分为两部分。通过在prometheus服务端设置告警规则, Prometheus服务器端产生告警向Alertmanager发送告警。 然后,Alertmanager管理这些告警,包括静默,抑制,聚合以及通过电子邮件,PagerDuty和HipChat等方法发送通知。
设置警报和通知的主要步骤如下:
- 设置并配置Alertmanager;
- 配置Prometheus对Alertmanager访问;
- 在普罗米修斯创建警报规则;
2. 告警管理模块 ALERTMANAGER
Alertmanager处理客户端应用程序(如Prometheus服务器)发送的告警。 它负责对它们进行重复数据删除,分组和路由,以及正确的接收器集成,例如电子邮件,PagerDuty或OpsGenie。 它还负责警报的静默和抑制。
以下描述了Alertmanager实现的核心概念。 请参阅配置文档以了解如何更详细地使用它们。
分组(Grouping)
分组将类似性质的告警分类为单个通知。 这在大型中断期间尤其有用,因为许多系统一次失败,并且可能同时发射数百到数千个警报。
示例:
发生网络分区时,群集中正在运行数十或数百个服务实例。 一半的服务实例无法再访问数据库。 Prometheus中的告警规则配置为在每个服务实例无法与数据库通信时发送告警。 结果,数百个告警被发送到Alertmanager。
作为用户,只能想要获得单个页面,同时仍能够确切地看到哪些服务实例受到影响。 因此,可以将Alertmanager配置为按群集和alertname对警报进行分组,以便发送单个紧凑通知。
这些通知的接收器通过配置文件中的路由树配置告警的分组,定时的进行分组通知。
抑制(Inhibition)
如果某些特定的告警已经触发,则某些告警需要被抑制。
示例:
如果某个告警触发,通知无法访问整个集群。 Alertmanager可以配置为在该特定告警触发时将与该集群有关的所有其他告警静音。 这可以防止通知数百或数千个与实际问题无关的告警触发。
静默(SILENCES)
静默是在给定时间内简单地静音告警的方法。 基于匹配器配置静默,就像路由树一样。 检查告警是否匹配或者正则表达式匹配静默。 如果匹配,则不会发送该告警的通知。
在Alertmanager的Web界面中可以配置静默。
客户端行为(Client behavior)
Alertmanager对其客户的行为有特殊要求。 这些仅适用于不使用Prometheus发送警报的高级用例。
3. 配置
Alertmanager通过命令行标志和配置文件进行配置。 命令行标志配置不可变系统参数,而配置文件定义禁止规则,通知路由和通知接收器。
要查看所有可用的命令行标志,请运行alertmanager -h。
Alertmanager可以在运行时重新加载其配置。 如果新配置格式不正确,则不会应用更改并记录错误。 通过向进程发送SIGHUP或向/ - / reload端点发送HTTP POST请求来触发配置重新加载。发送HTTP POST的方式比较常用,我们更改过配置文件之后,reload一下即可重启Alertmanager模块使新配置的规则生效。
4.安装配置
wget https://github.com/prometheus/alertmanager/releases/download/v0.13.0/alertmanager-0.13.0.linux-amd64.tar.gz
tar -axvf alertmanager-0.13.0.linux-amd64.tar.gz #解压即可用4.1 准备
step 1: 访问网站 注册企业微信账号(不需要企业认证)。
step 2: 访问apps 创建第三方应用,点击创建应用按钮 -> 填写应用信息:


4.2详细配置
4.2.1prometheus配置文件修改
vim /server/prometheus/prometheus.yml
global:
scrape_interval: 60s
evaluation_interval: 60s
alerting:
alertmanagers:
- static_configs:
- targets: ['localhost:9093']
rule_files:
- "/server/prometheus/rules.yml"
scrape_configs:
- job_name: 'node'
static_configs:
- targets: ['localhost:9100']rules.yml
groups:
- name: prometheus_go_goroutines
rules:
- alert: go_goroutines_numbers
expr: go_goroutines > 100
for: 15s
annotations:
summary: "prometheus的gorotine数据超过100!"
- name: node
rules:
- alert: server_status
expr: up{job="prometheus"} == 0 or up{job="linux"} == 0
for: 15s
annotations:
summary: "机器{{ $labels.instance }} 挂了"
description: "报告.请立即查看!"
alertmanger 配置:
vim /server/alertmanager/alertmanager.yml
global:
resolve_timeout: 5m
wechat_api_corp_id: 'xxxx'
wechat_api_url: 'https://qyapi.weixin.qq.com/cgi-bin/'
wechat_api_secret: 'xxxxx'
route:
group_by: ['alertname']
group_wait: 10s
group_interval: 10s
repeat_interval: 1h
receiver: 'wechat'
receivers:
- name: 'wechat'
wechat_configs:
- send_resolved: true
to_party: '1'
agent_id: 1000003
corp_id: 'xxxx'
api_url: 'https://qyapi.weixin.qq.com/cgi-bin/'
api_secret: 'xxxxx'
inhibit_rules:
- source_match:
severity: 'critical'
target_match:
severity: 'warning'
equal: ['alertname', 'dev', 'instance']
参数说明:
- corp_id: 企业微信账号唯一 ID, 可以在
我的企业中查看。 - to_party: 需要发送的组。
- agent_id: 第三方企业应用的 ID,可以在自己创建的第三方企业应用详情页面查看。
- api_secret: 第三方企业应用的密钥,可以在自己创建的第三方企业应用详情页面查看。
当停掉node_expor就会收到报警测试
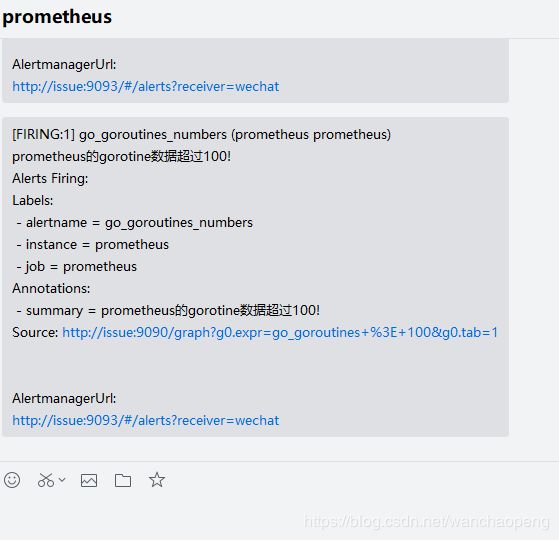
修改/server/alertmanager/alertmanager.yml
添加如下
[root@issue /server/alertmanager]# cat alertmanager.yml
global:
resolve_timeout: 5m
wechat_api_corp_id: 'xxx'
wechat_api_url: 'https://qyapi.weixin.qq.com/cgi-bin/'
wechat_api_secret: 'xxxx'
templates:
- '/server/alertmanager/template/wechat.tmpl'
route:
group_by: ['alertname']
group_wait: 10s
group_interval: 10s
repeat_interval: 1h
receiver: 'wechat'
receivers:
- name: 'wechat'
wechat_configs:
- send_resolved: true
to_party: '2'
agent_id: 1000003
corp_id: 'xxx'
api_url: 'https://qyapi.weixin.qq.com/cgi-bin/'
api_secret: 'xxxx'
inhibit_rules:
- source_match:
severity: 'critical'
target_match:
severity: 'warning'
equal: ['alertname', 'dev', 'instance']
vim /server/alertmanager/template/wechat.tmpl
{{ define "wechat.default.message" }}
{{ range .Alerts }}
========start=========
告警程序: prometheus_alert
告警级别: {{ .Labels.serverity }}
告警类型: {{ .Labels.alertname }}
故障主机: {{ .Labels.instance }}
告警主题: {{ .Annotations.summary }}
告警详情: {{ .Annotations.description }}
触发时间: {{ .StartsAt.Format "2006-01-02 15:04:05" }}
=========end===========
{{ end }}
{{ end }}
~