Kaggle第一次———Titanic: Machine Learning from Disaster
由于原始文件是ipython格式的,建议转到github下浏览(欢迎点星星^_^)
数据集地址:my github
背景介绍:
泰坦尼克号的沉没是历史上最臭名昭着的沉船之一。1912年4月15日,在她的处女航中,泰坦尼克号在与冰山相撞后沉没,在2224名乘客和机组人员中造成1502人死亡。造成海难失事的原因之一是乘客和机组人员没有足够的救生艇。 尽管幸存的人有一些运气因素,但有些人比其他人更容易生存,比如女人,孩子和上流社会。在这个挑战中,我们要求您完成对哪些人可能存活的分析,运用机器学习工具来预测哪些乘客幸免于悲剧。
一、数据的获取与分析
首先导入所需要的库:
import pandas as pd
import numpy as np
import random as rnd
import seaborn as sns
import matplotlib.pyplot as plt
from sklearn.linear_model import LogisticRegression
from sklearn.svm import SVC
from sklearn.tree import DecisionTreeClassifier
from sklearn.ensemble import RandomForestClassifier, GradientBoostingClassifier然后导入一下数据:
train_df = pd.read_csv('./data/train.csv')
test_df = pd.read_csv('./data/test.csv')先看一下部分数据:
train_df.head()
可以看出测试集主要包括以下特征:
PassengerId,Pclass,Name,Sex,Age,SibSp,Parch,Ticket,Fare,Cabin,Embarked
其中,每个特征的含义如下:
PassengerId: 乘客的id
Survived: 乘客是否存活
Pclass: 乘客的社会经济地位,分为3个等级:1代表上层,2代表中层,3代表下层
Name: 乘客姓名
Sex: 乘客性别
Age: 乘客年龄
SibSp: 与乘客同行的兄弟姐妹和配偶的数量
Parch: 与乘客同行的父母或子女的数量
Ticket: 船票号码
Fare: 船票费用
Cabin: 船舱号
Embarked: 登船港口,包含3个值,分别表示3个城市:C = Cherbourg, Q = Queenstown, S = Southampton
看一下数据的信息:
train_df.info()
从上面我们可以知道训练集中共有891个样本,其中Age,Cabin,Embarked这3个特征存在为空的值。
为了了解乘客的存活和部分特征的关系,我们可以根据经验提出以下假设:
- 女性更有可能幸存下来。
- 儿童更有可能幸存下来。
- 上层乘客(Pclass = 1)更有可能幸存下来。
为了验证我们的猜想,我们利用给出的数据分析一下:
- 女性更有可能幸存下来。
train_df[["Sex", "Survived"]].groupby(['Sex'], as_index=False).mean().sort_values(by='Survived', ascending=False)
- 上层乘客(Pclass = 1)更有可能幸存下来。
train_df[['Pclass', 'Survived']].groupby(['Pclass'], as_index=False).mean().sort_values(by='Survived', ascending=False)
利用上面的信息,我们可以直观的了解到女性的幸存率跟上层乘客的幸存率要高出不少。下面来将数据可视化一下
二、数据的可视化与分析
看一下不同年龄和幸存间的关系:
g = sns.FacetGrid(train_df, col='Survived')
g.map(plt.hist, 'Age', bins=20)
plt.show()
从上图中我们可以了解到:
- 婴儿(年龄<= 4)的存活率很高。
- 大量15-25岁的人没有活下来。
- 大多数乘客年龄在15-35岁之间。
由于年龄是一个预测能否幸存很重要的特征,所以我们需要填充缺失的年龄信息。我们也可以将乘客的年龄划分为年龄段。
接下来将乘客的级别Pclass和年龄组合一下,看这两个特征下乘客存活的信息:
grid = sns.FacetGrid(train_df, col='Survived', row='Pclass', size=2.2, aspect=1.6)
grid.map(plt.hist, 'Age', bins=20)
grid.add_legend()
plt.show()
从上图中我们可以进一步了解到:
- 大多数乘客的Pclass = 3,但多数人没有幸存下来。
- Pclass = 2和Pclass = 3的婴儿乘客大多幸免于难。进一步验证了我们的第2假设。
- Pclass = 1的大多数乘客幸免于难。 验证了第3个假设。
我们可以通过结合更多的特征来进行分析:
grid = sns.FacetGrid(train_df, row='Embarked', col='Survived', size=2.2, aspect=1.6)
grid.map(sns.barplot, 'Sex', 'Fare', ci=None)
grid.add_legend()
plt.show()
从上图中我们可以进一步了解到:
- 付费较高的乘客有更可能生存。
三、数据处理
首先我们需要丢弃掉没有用的特征,在这个项目里,特征Ticket和Cabin,Name,PassengerId都可以被丢弃(也可以根据自己的想法选择不丢弃这些特征或者根据这些特征新增一些特征),因为这些特征对乘客的幸存与否没有太大关联。需要注意的是,在丢弃特征的时候,训练集和测试集的特征应该同时被丢弃。
test_df.head()
train_df = train_df.drop(['PassengerId', 'Name', 'Ticket', 'Cabin'], axis=1)
test_df = test_df.drop(['Name', 'Ticket', 'Cabin'], axis=1)
train_df.head()
接下来,我们需要将性别转换为数值,male转为1,female转为0
train_df['Sex'] = train_df['Sex'].map({'female': 0, 'male': 1}).astype(int)
test_df['Sex'] = test_df['Sex'].map({'female': 0, 'male': 1}).astype(int)
train_df.head()
由于特征SibSp和Parch分别表示兄弟姐妹及配偶和父母子女的数量,所以我们也可以将SibSp和Parch组合成一个名为FamilySize的合成特征,它表示每个成员的船上家庭成员总数。
train_df["FamSize"] = train_df["SibSp"] + train_df["Parch"]
test_df["FamSize"] = test_df["SibSp"] + test_df["Parch"]接下来看一下新特征和乘客幸存率的关系
train_df[['FamSize', 'Survived']].groupby(['FamSize'], as_index=False).mean().sort_values(by='FamSize')
可以看到在FamSize在[0,3]时幸存率是比较高的,当FamSize>3时,幸存率就开始下降了。所以我们不防再新增一个特征FamTag,当FamSize>3时,另其为0,小于等于3时,另其为1
train_df["FamTag"] = train_df.FamSize.apply(lambda x: 1 if x <= 3 else 0)
test_df["FamTag"] = test_df.FamSize.apply(lambda x: 1 if x <= 3 else 0)接下来看一下改变后的效果:
train_df[['FamTag', 'Survived']].groupby(['FamTag'], as_index=False).mean().sort_values(by='FamTag')
然后我们丢弃掉SibSp、Parch和FamSize这3个特征
train_df = train_df.drop(['SibSp', 'Parch', 'FamSize'], axis=1)
test_df = test_df.drop(['SibSp', 'Parch', 'FamSize'], axis=1)
train_df.head()
现在我们需要填充一下缺失值了,由之前的信息可以知道现在还有Age和Embarked这两个特征存在缺失值,在训练集中Embarked仅有2个缺失值,我们可以进行一下简单的填充(比如用出现频率最高的值)。
train_df[['Embarked']].groupby('Embarked').size()
可以看出”S”出现的频率最高,接下来用”S”来填充缺失的值,并看一下现在数据的信息
train_df['Embarked'] = train_df['Embarked'].fillna('S')
test_df['Embarked'] = test_df['Embarked'].fillna('S')
train_df.info()
为了方便处理,我们还需要将特征Embarked的值转为数值型:
train_df['Embarked'] = train_df['Embarked'].map( {'S': 0, 'C': 1, 'Q': 2} ).astype(int)
test_df['Embarked'] = test_df['Embarked'].map( {'S': 0, 'C': 1, 'Q': 2} ).astype(int)
train_df.head()
接下来,我们需要对特征’Age’进行填充了,由于这个特征很重要且有100多个缺失值,所以需要通过一定的方式来进行填充,我们先看一下年龄的分布:
ageCopy = train_df.copy()
ageCopy.dropna(inplace = True)
sns.distplot(ageCopy["Age"])
plt.show()
看起来年龄分布略有偏差。因此,我们可以使用中位数填充空值,以获得最高精度。测试集的’Fare’也有1个空值,我们也用同样的方法填充:
train_df['Age'].fillna(train_df['Age'].median(), inplace = True)
test_df['Age'].fillna(test_df['Age'].median(), inplace = True)
test_df['Fare'].fillna(test_df['Fare'].median(), inplace = True)
train_df.info()
print("-"*60)
test_df.info()
现在空值都已填充完毕。由于年龄’Age’和船票费用’Fare’都是连续值,为了方便处理,我们将这两个特征分别划分为8个、4个区间,划分的区间为新的特征,分别是’AgeBand’和’FareBand’:
train_df['AgeBand'] = pd.cut(train_df['Age'], 8)
test_df['AgeBand'] = pd.cut(test_df['Age'], 8)
train_df[['AgeBand', 'Survived']].groupby(['AgeBand'], as_index=False).mean().sort_values(by='AgeBand', ascending=True)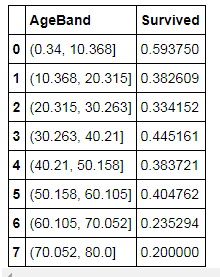
train_df['FareBand'] = pd.qcut(train_df['Fare'], 4)
test_df['FareBand'] = pd.qcut(test_df['Fare'], 4)
train_df[['FareBand', 'Survived']].groupby(['FareBand'], as_index=False).mean().sort_values(by='FareBand', ascending=True)
现在数据特征如下:
train_df.head()
然后我们根据区间的不同,将’Age’和’Fare’分别用不同的值代替,将连续值离散化,然后丢弃新增的2个特征,这个操作也需要同时在训练集和测试集中同时进行:
combine = [train_df, test_df]
for dataset in combine:
dataset.loc[ dataset['Age'] <= 10, 'Age'] = 0
dataset.loc[(dataset['Age'] > 10) & (dataset['Age'] <= 20), 'Age'] = 1
dataset.loc[(dataset['Age'] > 20) & (dataset['Age'] <= 30), 'Age'] = 2
dataset.loc[(dataset['Age'] > 30) & (dataset['Age'] <= 40), 'Age'] = 3
dataset.loc[(dataset['Age'] > 40) & (dataset['Age'] <= 50), 'Age'] = 4
dataset.loc[(dataset['Age'] > 50) & (dataset['Age'] <= 60), 'Age'] = 5
dataset.loc[(dataset['Age'] > 60) & (dataset['Age'] <= 70), 'Age'] = 6
dataset.loc[ dataset['Age'] > 70, 'Age'] = 7
dataset.loc[ dataset['Fare'] <= 7.91, 'Fare'] = 0
dataset.loc[(dataset['Fare'] > 7.91) & (train_df['Fare'] <= 14.454), 'Fare'] = 1
dataset.loc[(dataset['Fare'] > 14.454) & (train_df['Fare'] <= 31), 'Fare'] = 2
dataset.loc[ dataset['Fare'] > 31, 'Fare'] = 3
dataset['Age'] = dataset['Age'].astype(int)
dataset['Fare'] = dataset['Fare'].astype(int)
dataset.drop(['AgeBand', 'FareBand'], axis=1,inplace=True)
train_df.head()
好了,数据处理的差不多了,现在我们需要利用模型进行训练与预测了。
四、利用模型进行训练和预测
首先取出训练集、标签向量和测试集:
X_train = train_df.drop("Survived", axis=1)
Y_train = train_df["Survived"]
X_test = test_df.drop("PassengerId", axis=1).copy()接下来用不同的分类器进行测试
1. Logistic Regression
logreg = LogisticRegression()
logreg.fit(X_train, Y_train)
Y_pred = logreg.predict(X_test)
acc_log = round(logreg.score(X_train, Y_train) * 100, 2)
acc_log80.25 2. Support Vector Machine
svc = SVC()
svc.fit(X_train, Y_train)
Y_pred = svc.predict(X_test)
acc_svc = round(svc.score(X_train, Y_train) * 100, 2)
acc_svc83.1599999999999973. Decision Tree
decision_tree = DecisionTreeClassifier()
decision_tree.fit(X_train, Y_train)
Y_pred = decision_tree.predict(X_test)
acc_decision_tree = round(decision_tree.score(X_train, Y_train) * 100, 2)
acc_decision_tree86.8700000000000054. Random Forest
random_forest = RandomForestClassifier(n_estimators=50)
random_forest.fit(X_train, Y_train)
Y_pred = random_forest.predict(X_test)
random_forest.score(X_train, Y_train)
acc_random_forest = round(random_forest.score(X_train, Y_train) * 100, 2)
acc_random_forest86.7600000000000055. Gradient Tree Boosting
gbdt = GradientBoostingClassifier(n_estimators=100,max_depth=8)
gbdt.fit(X_train, Y_train)
Y_pred = gbdt.predict(X_test)
gbdt.score(X_train, Y_train)
acc_gbdt = round(gbdt.score(X_train, Y_train) * 100, 2)
acc_gbdt86.870000000000005将预测结果写导csv文件中
submission = pd.DataFrame({
"PassengerId": test_df["PassengerId"],
"Survived": Y_pred
})
submission.to_csv('./data/submission.csv', index=False)ref:
Manav Sehgal : https://www.kaggle.com/startupsci/titanic-data-science-solutions