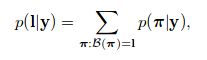CRNN论文解读与复现
一、Network Architecture
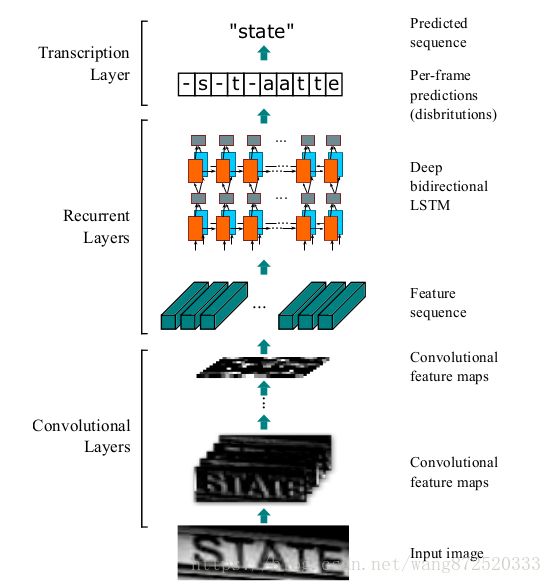
1.Convoluional Layers:
Input image:100x32(gray-scale image )
Conv0:100x32x1*3x3x1x64——>100x32x64(maps:64 k:3x3 s:1 p:1)
Maxpool0:100x32x64——>50x16x64(window:2x2 s:2)
Conv1:50x16x64*3x3x64x128——>50x16x128(maps:128 k:3x3 s:1 p:1)
Maxpool1:50x16x128——>25x8x128(window:2x2 s:2)
Conv2:25x8x128*3x3x128x256——>25x8x256(maps:256 k:3x3 s:1 p:1)
Conv3:25x8x256*3x3x256x256——>25x8x256(maps:256 k:3x3 s:1 p:1)
Maxpool2:25x8x256——>13x4x256(window:1x2 s:2)
Conv4:13x4x256*3x3x256x512——>13x4x512(maps:512 k:3x3 s:1 p:1)
BatchNormalization
Conv5:13x4x512*3x3x512x512——>13x4x512(maps:512 k:3x3 s:1 p:1)
BatchNormalization
Maxpool3:13x4x512——>7x2x512(window:1x2 s:2)
Conv6:7x2x512*2x2x512x512——>6x1x512(maps:512 k:2x2 s:1 p:0)
Map-to-Sequence:6x1x512——>6x512
2.Recurrent Layers
Bidirectional-LSTM0:6x512*512x256——>6x256
Bidirectional-LSTM1:6x256*256x5530——>6x5530
二、Details
1.Convoluional Layers
1)Before being fed into the network , all the images need to be scaled to the same height. In the 3rd and the 4th maxpooling layers,we adopt 1x2 sized rectangular pooling windows instead of the conventional squared ones.This tweak yields feature maps with lager width,hence longer feature sequence.
2)Each feature vector of a feature sequence is generated from left to right on the feature maps by column.This means the i-th feature vector is the concatenation of the i-th columns of all the maps. And because of the translation invariant,each column of the feature maps corresponds to a rectangle region of the original image(termed the receptive filed)

3)Camparing to CNN, CRNN remove the fully connected layer and convey deep features into sequential representations in order to be invariant to the length variation of sequence-like objects.
2.Recurrent Layers
1)A deep bidirectional Recurrent Neural Network is built on the top of the convolutional layers,as the recurrent layers. The recurrent layers predict a label distribution Yt for each frame Xt in the feature sequence.
2)RNN has a strong capability of capturing contextual information within a sequence.Some ambiguous characters are easier to distinguish when observing their contexts.
3)RNN can back-propagates error differentials to its input,the convolutional layer,allowing us to jointly train the recurrent layers and the convolutional layers in a unified network.
4)RNN is able to operate on sequences of arbitrary lengths,traversing from starts to ends.

3.Transcription layers
We adopt the conditional probility defined in the CTC layer. And the conditional probability is defined as the sum of probabilities of all π that are mapped by B onto l: