Deeplearning4j 实战 (18):基于DQN的强化学习在自定义迷宫游戏问题中的建模
Eclipse Deeplearning4j GitChat课程:https://gitbook.cn/gitchat/column/5bfb6741ae0e5f436e35cd9f
Eclipse Deeplearning4j 系列博客:https://blog.csdn.net/wangongxi
Eclipse Deeplearning4j Github:https://github.com/eclipse/deeplearning4j
在之前写的博客系列中,我们已经有谈到关于强化学习的相关内容。具体来讲,当时是基于RL4j并结合OpenAI提供的Gym这个开源的强化学习工具来训练了一个可以玩Cartpole游戏的DQN模型。由于Cartpole问题中的建模要素都是由Gym来提供的,因此除非debug源码,否则是无法了解这个问题涉及的action space以及state space。进一步,如果想结合自身的业务来使用强化学习模型,则需要自定义这些要素,因此我们用这篇文章的案例来说明下如何基于RL4j来自定义强化学习问题。为了方便给出最终的效果,我们依然选择做一个简单的游戏,而不是实际业务比如推荐、广告和搜索这样相对抽象的应用。我们通过Java Swing构建游戏的界面,通过RL4j训练DQN模型来连续预测游戏中agent采取的每一步从而完成这个游戏。下面我们就从四个方面来具体说下。
问题描述
我们构建一个类似于迷宫的问题,事先设定好陷阱(用一个地雷的图片来表示)以及最终的目标(用一个公主的图片来表示)。我们的勇士(用樱木花道的图片来表示)充当的是强化学习中agent的角色。游戏的目的是勇士可以通过离线的学习来掌握拯救公主的路线,并且一路上不能掉到陷阱中,一旦落入陷阱或者说踩雷了,那么游戏就结束了。如果勇士一路上畅通无阻并且最终达到了公主所在的位置,那么我们就认为游戏成功完成了。在玩游戏的过程中,我们每次可以给勇士不同的初始位置,以此来观察勇士的在不同初始state下的表现。为了便于说明问题,我们将游戏的环境设置成一个10*10的类似棋盘的界面,每次勇士可以上、下、左、右进行移动,每次只能移动一个格子。这就是我们构建的这个勇士拯救公主的简单游戏的背景。
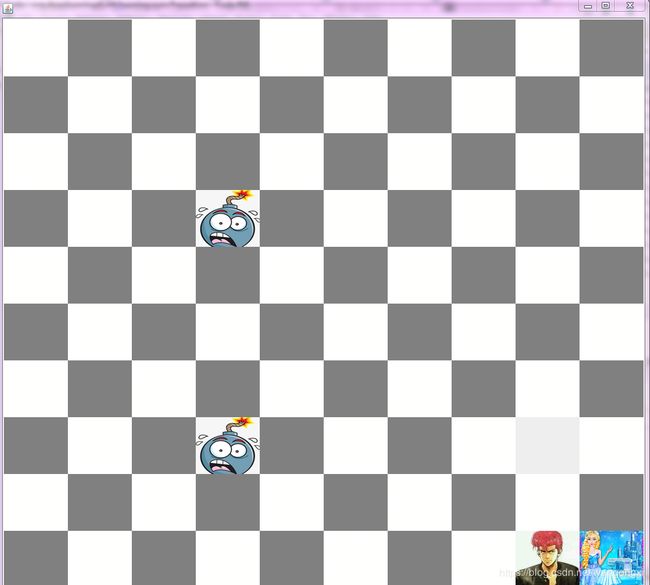
需要说明一下的是,我们做这样的简单的游戏并不是为了应用于实际的生产环境中,毕竟没有人会喜欢这样简单的游戏。而且从算法实现上看,在已经明确终点和陷阱的前提下,我们基于回溯的思想可以很方便的找到一条甚至是所有的成功路径,因此成功完成这个游戏并不是我们的最终目的,我们希望通过这个案例让大家明确如何基于RL4j这样的框架自定义一个强化学习问题,而不是只能依赖于Gym等第三方环境(第三方工具虽然设计得很好,但是不一定契合自身的业务)。另一方面则是可以通过这个例子,让大家了解到强化学习问题中奖赏塑形、action/state space定义过程这些细节,因为只有明确了这些,才可以应用到自身的业务中以及直观地了解到强化学习的特点。
Deep Q-learning(DQN)回顾
我们首先来回顾一下强化学习的一些基本知识。区别于监督学习,强化学习是一种支持连续不断做出决策的算法。一般的,我们可以基于马尔科夫决策过程(Markov Decision Process, MDP)的框架做多步强化学习的决策,也可以基于一些Bandit算法,如eplison-greedy、UCB以及Tompson采样等等做单步最大化的强化学习。这一分类方式详见周志华西瓜书关于强化学习一章的描述。这里我们重点说的是多步强化学习。
结合MDP的框架,我们说明下强化学习的一些基本要素,主要有Environment、State、Reward以及Action。对于具备做出智能决策的智慧体,具体来讲也就是可以做出Action选择的模型,我们可以称之为agent。agent是处在Environment中的一个具体的State下(实际问题中,State和Environment的关系可以是一致的,即State=Environment,当然也可以是独立或者不完全相等),根据以往经验,agent在action space中做出选择。这个具体的action会获得一定的reward或者说是future reward。与此同时,action被执行后,对Environment会产生一定的影响,State的状态也会发生迁移。
对于State的转移如果是已经明确的一个概率分布,那么我们可以称之为Model-Based的RL问题,否则就是Model-Free的RL问题。在Model-Free的RL问题中,我们可以采用蒙特卡洛算法以及时间差分算法(Temporal-Difference,简称TD)。TD算法中比较常见的有Q-learning、Sarsa等等。Deep Q-Network是神经网络与Q-learning结合的一种新形式,也属于TD算法的范畴。
Q-learning的核心其实是如何更新State-Action所构成的一张二维表格,也称之为Q表。

在初始化的时候,我们可以全部置为0。那么接下来的动作,就是通过不断的选择action,并且根据拿到的reward来更新这张Q表。这样就是强化学习学习试错的过程。我们根据如下算法来更新Q表。

这张图从周莫烦的强化学习视频课程中截取的,有兴趣的同学可以去看下他的课程,个人觉得还是很通俗易懂的。
经过不断的更新Q表中的值,我们可能最终可以得到这样的一张表。

可以看到这时候Q表中的值已经被更新了,不再是初始化时候的状态了。举个具体的例子来说,当我们处于State1的状态的时候,我们采用eplison-greedy算法(这个算法的详情请自行查阅相关资料)选择一个action,也就是在Action1和Action2中选择一个,大概率会选择Action2,因为它的Q-value比较大。
我们进一步分析下这个Q表。从另一个角度讲,Q表表示的其实是Action Space和State Space这两个变量的联合分布函数,即Q = Q(s,a)。那么它的优点在于比较直观,但是缺点其实也有很多。比如,Action Space和State Space的维度可能会很高,那么Q表的存储和更新其实就很麻烦了。如果可以通过一种算法自动地学习Q(s,a)这个函数,至少无限逼近它,那么我们只要存储这个算法的一些参数和基本结构就可以了,很自然的,神经网络是一个非常有用的工具。多层神经网络加上非线性激活函数可以无限逼近任意函数分布。因此利用神经网络来代替Q表,Q-learning与DNN的结合,就形成了现在的深度强化学习。当然DNN的选择可以是MLP、RNN、CNN等等,这里统称为DNN。
在DeepMind最早的关于DQN的论文中,还有一些必须提到的概念,比如experience replay,也是其比较主要的trick。experience replay,所谓的经验回放,实际上是打破强化学习训练样本的一个连续性。该机制将每一步的State, Action, Reward以及Next-State以四元组的数据结构存储起来,并在训练的时候从中随机抽取一个mini-batch数量的四元祖用于更新神经网络的参数。以下是DQN论文中的算法的核心描述。

那么在之后DeepMind的一系列论文中,对DQN做出了一系列的改进,包括增加Target网络(这篇文章发在Nature Letter上,因此也称为Nature DQN),以及在此基础上的DoubDQN、Dueling-DQN等等这里就不再展开讲述了。有兴趣的朋友可行自行查阅相关的论文。
基于RL4j自定义State/Reward/Action
在之前介绍Cartpole的博客中,我们不需要自定义State/Reward/Action,这些数据都可以依赖Gym客户端来获取。由于编写强化学习的环境以及交互是一个非常繁琐的过程,因此很多的强化学习案例都会以Gym来作为获取环境数据的一个源。但是对于实际业务的一些RL问题,明确上下文环境,建立奖赏机制等是必须结合业务来定义的,因此我们需要结合框架来定义自己的RL问题以及试错学习的过程。我们在第一部分已经描述了需要建模的游戏。这里我们就结合这个游戏给出基于RL4j框架的RL问题的定义过程。
对于使用RL4j定义强化学习问题,我们至少定义两个类并分别实现org.deeplearning4j.rl4j.mdp.MDP和org.deeplearning4j.rl4j.space.Encodable这两个接口。MDP这接口定义的是马尔科夫决策过程的大框架,具体来说就是里面涉及的一些操作以接口的形式提供。我们来看下下面的截图。

每当agent选择一个action并执行后,我们都可以获取一个Reply,也就是截图里的StepReply,其中包含了下一步的state以及获取的reward。我们来看下如何定义上文提到的游戏的MDP环境。

我们定义一个GameMDP的类来实现MDP接口,截图里包含了我们定义的一些成员变量。其中比较重要的是actionSpace和observationSpace这两个对象。我们定义游戏中的agent只能采取上/下/左/右这四种action,因此这是一个典型的离散的action space。我们直接声明一个维度为4的DiscreteSpace的对象即可。DiscreteSpace其实是实现了ActionSpace接口的一个实现类,它将具体的action映射成一个具体的整数。比如,上/下/左/右可以分别对应0/1/2/3。observationSpace,或者说是state space是用来定义RL问题中的状态空间。我们事先需要声明一个满足我们游戏的自定义State,也就是截图里的GameState类。这个类的的功能就是记录当前agent所处的状态,具体对于我们的游戏来说,其实就是agent所处的位置或者说坐标。我们看下它的实现。
@Getter
@Setter
public class GameState implements Encodable{
private double x;
private double y;
public GameState(double x, double y){
this.x = x;
this.y = y;
}
@Override
public double[] toArray() {
double[] ret = new double[2];
ret[0] = x;
ret[1] = y;
return ret;
}
}
这个类的实现很清晰,就是记录下当前agent的(X,Y)坐标。其中toArray的方法用于以数组的形式返回当前的state,其实也就是返回模型输入的特征,这个后面会说明。我们再回到上面GameMDP的定义中observationSpace的定义,这个对象并不是用来存储GameState,它的主要作用是记录GameState返回的特征的shape,这里就是(X,Y)坐标构成的长度为2的向量的shape,也就是1*2。GameMDP中其他的一些成员变量,如:traps是用来存储陷阱的位置的,curState用来记录当前的位置,trace主要服务于日志用于记录agent移动的轨迹,reward和step分别是到目前为止获得回报以及走的步数。下面看下GameMDP一些主要方法的实现。首先是isDone。

isDone的实现直接关系到训练和预测阶段游戏是否结束。这里我们考虑两种状态会结束游戏。一个是掉入陷阱,一个是成功救到公主。我们再看reset方法的实现。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-gdmgDhM4-1576650131879)(…/RL4j/GameMDP-reset-define.jpg)]
reset方法就是重置整个游戏,具体来说就是当游戏结束的时候,重新初始化agent的位置。这里我们通过随机数生成的方式给agent随机生成X,Y的坐标,因此不管是在训练还是在实际玩游戏的时候,每一次游戏的执行agent的位置都是随意的。到这里,我相信是有很多疑问的。比如,为什么每次reset都是取随机的位置,而不是固定一个位置,比如(0,0)这样一个特殊的起始位置。还有isDone的实现,为什么不可以将移动出边界也算是游戏结束呢。这里我们先不多做解释,在下一个部分会给出我们的看法和解释。最后我们来看下step方法的实现。

之前说过,step方法需要做的是在agent执行完某一步后,给到的reward和下一步的state。对于算法生成的action(默认采用epsilon-greedy算法),我们执行完之后,可以获取当前的state,也就是游戏中agent的坐标,并更新curState对象内存储的坐标的具体值。如果执行完这个action后,agent移动出了棋盘,那么我们人为做下调整,将其反向移动一个位置。最后,根据最新状态,判断是掉入陷阱、救到公主、出界还是一般移动我们给出reward的策略。可以看到,只有救到公主是加分,其他都有不同程度的扣分。最后我们在trace对象中做下记录,并且更新当前步数然后构建StepReply对象并返回。到此,GameMDP类的实现就基本完成了。
DQN模型训练
在上面的部分中我们结合游戏的实际情况定义的RL的相关内容,比如游戏的状态,游戏中agent可以采取的action以及奖赏机制等等。总的来说,这里的RL问题是基于MDP框架来实现。那么定义好这些环境相关的信息后,我们给出DQN建模的相关逻辑。
public static QLearning.QLConfiguration QL_CONFIG =
new QLearning.QLConfiguration(
123, //Random seed
30, //Max step Every epoch 批次下最大执行的步数
100*2000, //Max step 总执行的部署
100*2000, //Max size of experience replay 记忆数据
40, //size of batches
10, //target update (hard) 每10次更新一次参数
0, //num step noop warmup 步数从0开始
0.01, //reward scaling
0.9, //gamma
1.0, //td-error clipping
0.1f, //min epsilon
100, //num step for eps greedy anneal
false //double DQN
);
public static DQNFactoryStdDense.Configuration DQN_NET =
DQNFactoryStdDense.Configuration.builder()
.updater(new Adam(0.001))
.numLayer(2)
.numHiddenNodes(16)
.build();
以上两个对象的定义用于确定DQN网络的结构以及相关的超参数设置。这里对部分关键超参数做一些说明。在QLConfiguration的入参中,有maxEpochStep、maxStep、expRepMaxSize(分别设置成30、100x2000、100x2000)这几个参数,其中maxEpochStep表示的是在一轮模型训练中,agent可以执行的step的步数,maxStep表示在整个训练过程中agent可以执行的总的步数,expRepMaxSize则表示experience reply的总数据量。因此,maxStep / maxEpochStep就是理论上的训练轮次,实际轮次可能会更多,因为部分轮次会提前结束。targetDqnUpdateFreq这个参数(我们取的是40)指的是更新目标网络的频次。在第二部分回顾DQN的相关内容的时候,我们提到过DQN、Nature DQN、Double DQN以及Dueling DQN这些概念。其中除了DQN,其他都含有target网络,换言之模型中其实有两个神经网络,而DQN只有一个。因此这个参数的作用指的就是更新target网络的频次。如果最后一个入参是false,那么其实这个频次没什么实际作用(虽然底层实现的时候,默认还是会去更新,但是不参与实际的预测了),否则这个参数将决定target网络的参数情况。第二个对象定义的是神经网络结构,这里用的就是一个普通的两层的每层含有16个神经元的全连接网络,优化器用的Adam。这个应该没什么特别。需要注意的是,如果你用Double DQN,那么target网络的结构和它是一模一样的,只是模型参数不同,底层实现的时候clone一下就可以了。下面看下训练的逻辑。
public static void learning() throws IOException {
DataManager manager = new DataManager();
GameMDP mdp = new GameMDP();
QLearningDiscreteDense dql = new QLearningDiscreteDense(mdp, DQN_NET, QL_CONFIG, manager);
DQNPolicy pol = dql.getPolicy();
dql.train();
pol.save("game.policy");
mdp.close();
}
这部分和之前Cartpole问题的建模逻辑基本是一致的,我就不多解释了,有需要的可以看之前的博客。
那么调用这个方法我们就可以训练这个DQN模型,并且将模型的相关信息,包括环境参数等信息保存在game.policy这个二进制文件中,具体底层通过序列化来实现。以下是训练日志。
下面的章节我们尝试来玩下这个游戏。
游戏效果与说明
在上面一部分建模结束的基础上,我们编写了游戏的一些效果。如果是基于Java Swing做一个游戏界面,这个在第一部分中就有提及。我们每次会给agent(樱木花道的图片)一个随机的初始位置,然后根据DQN的输出来决策当前状态下采取的行动,也就是往上/下/左/右走。执行完这个action后,我们判断下究竟是掉入了陷阱还是救到了公主还是普通的行走,然后再采取下一步的action,如果掉入陷阱或者救到了公主,那么我们会提示游戏结束,并且reset整个游戏,否则就是agent在游戏界面上继续移动。我们给出核心的逻辑。
public static void main(String[] args) throws IOException, InterruptedException {
//learning();
GameMDP mdp = initMDP();
GameBoard board = initGameBoard(mdp);
//
boolean success = false, trap = false;
DQNPolicy policy = DQNPolicy.load("game.policy");
while( true ){
Point p = playByStep(mdp ,policy);
board.shiftSoilder(p.getX(), p.getY());
//
success = isSuccess(mdp);
if( success ){
board.dialog("成功救到公主", "Game Over");
board = initGameBoard(mdp);
}
trap = isTraped(mdp);
if( trap ){
board.dialog("掉入陷阱", "Game Over");
board = initGameBoard(mdp);
}
//
Thread.sleep(1000);
}
//
}
这个就是整个游戏的核心逻辑。我们首先初始化一个MDP环境以及游戏界面。然后加载预训练好的DQN模型以及相关环境参数。接着,我们基于DQN给出的决策,也就是在不同state下的action,将agent在界面上进行移动,根据移动后的状态给出游戏的状态。下面给出我录制的视频。
视频文件已经上传到bilibili
DQN-Maze
视频里我已经给出了一些说明,这里再讲解一下。经过训练之后,agent大体上是可以不断向着目标,也就是右下角公主的那个坐标不断靠近的。如果不经过训练,那么结果很可能是agent在界面随机上下左右胡乱行动。至于为什么依然会有踩到地雷的情况,主要是因为每次踩到地雷后,整个训练其实是会结束的,也就是上面提到的isDone方法的那个实现。这个设计的结果是,在训练过程中,踩到地雷之后训练就立即结束无法学习到后续的一个情况,因此可以考虑在训练的时候踩到地雷依然继续执行,但是预测的时候终止,这样由于踩到地雷的reward是-1,是比较大的一个惩罚,因此理论上可以让模型学习到这样的走法是不好的,从而避开地雷。
调优相关
DQN网络的调优是一个比较麻烦的事情,因为其涉及神经网络本身的调优以及MDP框架下参数的一些调优。
- 奖赏机制的调优
- 单轮最大执行次数的调优
- batchsize的调优
- agent初始化位置最终效果的影响
大概先列这几项并做些说明。
第一个是奖赏机制。我们对于掉入陷阱的是-1的激励,救到公主的是+1的激励,其余出界或者正常移动的是-0.2和-0.1的激励。可以看到,除了就到公主是正激励,其余都是大小不等的负激励。需要特别注意的是,正常移动也是给的负激励,而不是正激励,这是因为我们其实并不鼓励agent的随意走动。如果正常移动都给与正激励,那么极端情况下agent可以在原地来回走一段时间,这样不利于模型的收敛,因此正常移动给予负激励或者0激励。
第二个单轮最大执行次数。这个参数的主要目的是约束agent在每一轮执行action的次数。如果在试错的过程中,已经达到甚至超过了这个参数的值,那么就会结束本轮的训练。因此极端情况,我们设置一个很小的数值,比如说1,那么agent永远到不了目的地,所以这样的训练是没有意义的。而如果设置得过大,那么容错的余地会很大,agent可能会在“闲逛”很长一段时间才到终点,因此模型的收敛速度会比较慢,但是最终理论上是会收敛的。所以最好设置一个相对合理的值,这里设置成30,50,100都可以尝试。
第三个是batchsize的大小。这个参数一开始我设置成8,16这样比较小的值。但是这样会有些问题。因为实际DQN在训练过程中取的是experience replay机制下存储的过往的经验数据,而每次我们的可能会需要移动20甚至30步才会到终点,因此理论上batchsize中的样本应该覆盖这30种情况,即不要小于单轮次的最大步数,取一到两倍的整数倍即可。这里取的40 ,就接近于一倍。
第四个是agent初始化位置的问题。实际我们在每一轮训练或者说每一次play的过程中,初始化位置可以定位在一个固定的位置,比如左上角(0,0)的位置,但我们的选择是每次随机初始化一个位置。如果每次固定在左上角,那么相应的,agent走到终点的步数肯定会增加,这样单轮最大执行次数如果还是30可能收敛得很慢甚至不收敛,这个参数肯定需要增加。另外,左上角位置的初始化方法相对比较容易掉到陷阱中。
总结
最后我们做下总结。我们基于RL4j自定义了一个简单游戏的强化学习过程,具体可以分为自定义MDP,自定义RL的state以及自定义reward和训练过程。从最终的效果看,agent确实学习到了如何成功达到目的地的移动方法,但仍然有一定的几率会落到陷阱中。通过这个简单的案例,希望可以帮助有需要的同学了解如何基于RL4j建立和自身业务相关的强化学习算法。这些业务不仅限于游戏,推荐、广告、搜索等互联网场景,工控软件、工业机器人等制造业场景同样可以尝试。
需要注意的是,RL4j 1.0.0-beta5之前的版本中抽象类org.deeplearning4j.rl4j.policy.Policy存在一些问题,所以需要依赖最新的1.0.0-beta6或者1.0.0-SNAPSHOT的版本。我们最后把这个依赖也贴一下。
1.0.0-SNAPSHOT:https://deeplearning4j.org/docs/latest/deeplearning4j-config-snapshots
1.0.0-beta6:
org.deeplearning4j
rl4j-core
1.0.0-beta6
所有代碼已經托管到Github:https://github.com/AllenWGX/RL4j-Demos.git