Redis 5种数据结构(底层原理,性能分析,使用场景)
Redis中的每个对象都是由一个RedisObject结构表示,该结构中和保存数据有关的三个属性分别为type属性,encoding属性,以及ptr属性

Redis 数据结构(type)有5种,分别为:字符串(String)列表(List)哈希(Hash) 集合(Set)有序集合(ZSet)
字符串(String)
字符串对象的编码可以是int、raw(SDS)或者embstr(专门保存段字符串的优化编码方式)
重点讲解SDS,当字符串长度大于32字节的时候,底层实现为SDS,encoding 编码设置为raw
Redis没有直接使用C语言传统的字符串表示,而是自己构建了一种名为简单动态字符串(simple dynamic string,SDS)的抽象类型,并将SDS用作Redis的默认字符串表示.
在Redis 里面,C字符串只会作为字符串面量(string literal)用在一些无须对字符串值进行修改的地方。
在一个可以被修改的字符串值里面,Redis就会使用SDS来表示字符串值,比如:Redis数据库里面,包含字符串值得健值对在底层得实现都是由SDS实现的
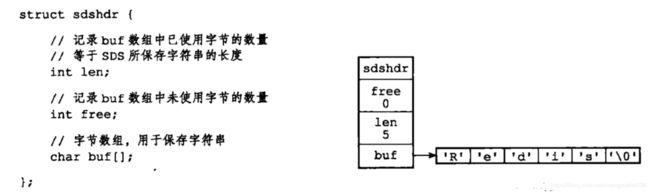
对象种包含了一些额外信息,因此
获取字符长度 时间可以为O(1)
free动态分配空间的时候,可以判定如何分配(预分配空间,可减少分配次数)
由此可以得出以下特性:
(1)redis为字符分配空间的次数是小于等于字符串的长度N,而原C语言中的分配原则必为N。降低了分配次数提高了追加速度,代价就是多占用一些内存空间,且这些空间不会自动释放。
(3)二进制安全的
(4)高效的计算字符串长度(时间复杂度为O(1))
(5)高效的追加字符串操作。
列表(List)
在3.2版本之前,列表是使用ziplist和linkedlist实现的,在这些老版本中,当列表对象同时满足以下两个条件时,列表对象使用ziplist编码:
(1)列表对象保存的所有字符串元素的长度都小于64字节
(2)列表对象保存的元素数量小于512个
当有任一条件 不满足时将会进行一次转码,使用linkedlist。
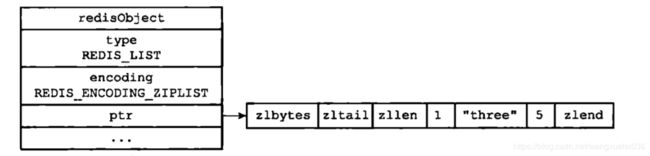
ziplist
ziplist编码的列表对象使用压缩列表作为底层实现,每个压缩列表节点保存了一个列表元素
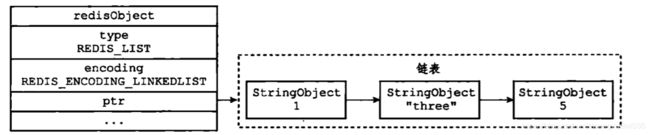
linklist
linklist编码的列表使用双端链表作为底层实现,每个双端表节点(Node)都保存了一个字符串对象,而每个字符串对象都保存了一个列表元素
而在3.2版本之后,重新引入了一个quicklist的数据结构,列表的底层都是由quicklist实现的,它结合了ziplist和linkedlist的优点。按照原文的解释这种数据结构是【A doubly linked list of ziplists】意思就是一个由ziplist组成的双向链表。那么这两种数据结构怎么样结合的呢?
quickList
quickList 是 zipList 和 linkedList 的混合体,它将 linkedList 按段切分,每一段使用 zipList 来紧凑存储,多个 zipList 之间使用双向指针串接起来
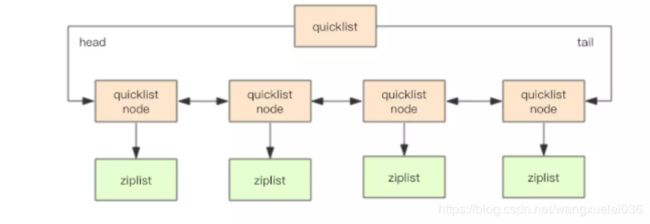
它整体宏观上就是一个链表结构,只不过每个节点都是以压缩列表ziplist的结构保存着数据,而每个ziplist又可以包含多个entry。也可以说一个quicklist节点保存的是一片数据,而不是一个数据。总结:
整体上quicklist就是一个双向链表结构,和普通的链表操作一样,插入删除效率很高,但查询的效率却是O(n)。不过,这样的链表访问两端的元素的时间复杂度却是O(1)。一般实际场景 对list的操作多数都是poll和push。
每个quicklist节点就是一个ziplist,具备压缩列表的特性。
在redis.conf配置文件中,有两个参数可以优化列表:
list-max-ziplist-size 表示每个quicklistNode的字节大小。默认为-2 表示8KB
list-compress-depth 表示quicklistNode节点是否要压缩。默认是0 表示不压缩
哈希(Hash)
哈希对象可以是zipList 或者 hashtable
zipList
zipList编码的哈希对象使用压缩列表作为底层实现,每当有新的健值对要加入到哈希对象时,程序会先将保存了健的压缩列表节点推入到压缩列表尾,然后再将保存了值得压缩节点推入到压缩列表尾,因此:
保存了同一健值对得两个节点总是紧挨在一起,保存健得节点在前,保存值的节点在后
先添加到哈希对象种的健值对会被放在压缩列表的表头方向,而后来添加到哈希对象中的键值对会被放在压缩列表的表尾方向

hashtable
hashtable编码的哈希独享使用字典作为底层实现,哈希对象中的每个键值对都使用一个字典健值对来保存
字典的每个键(key)和每个值(value)都是一个字符串对象,对象中保存了键或值。
这种结构的时间复杂度为O(1),但是会消耗比较多的内存空间。
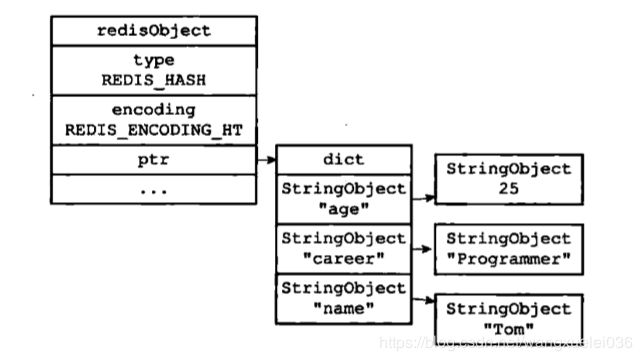
当哈希对象可以同时满足以下两个条件时,哈希对象使用ziplist编码:
- 当键的个数小于hash-max-ziplist-entries(默认512)
- 当所有值都小于hash-max-ziplist-value(默认64)
集合(Set)
集合对象的编码可以时intset或者hashtable
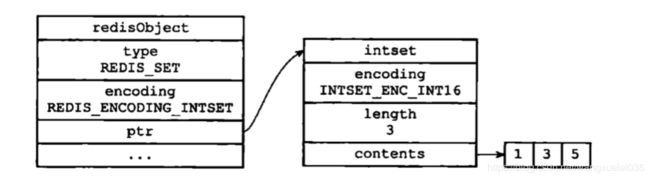
intset
intset编码的集合对象使用证书集合作为底层实现,集合对象包含的所有元素都被保存在整数集合里面
hashtable 参考上面
intset限制:
(1)集合对象保存的元素全部都是整数
(2)集合对象保存的元素不超过512个
不满足以上条件,集合对象需要使用hashtable
注:第二个条件的上限可以修改,set-max-intset-entries默认值为512。表示如果entry的个数小于此值,则可以编码成REDIS_ENCODING_INTSET类型存储,节约内存。否则采用dict的形式存储。
有序集合(zset)
有序集合的编码可以时ziplist或者skiplist
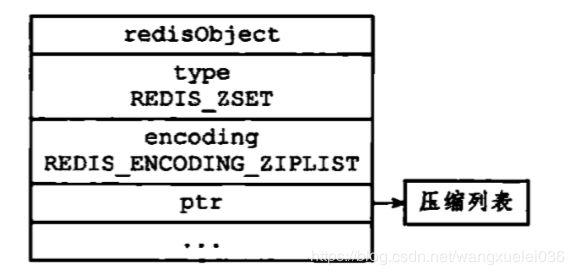
ziplist
ziplist编码的压缩对象使用压缩列表作为底层实现,每个集合元素使用两个紧挨在一起的压缩列表节点来保存,第一个节点保存元素的成员(member),而第二个原属则保存元素的分值(score)
压缩列表内的集合原属按分值从小到大进行排序,分值较小的元素放置在靠近表头的方向,而分值较大的元素则放置在靠近表位的方向

skiplist
skiplist编码的有序集合对象使用zset结构作为底层实现,一个zset结构包含一个字典和一个跳跃表

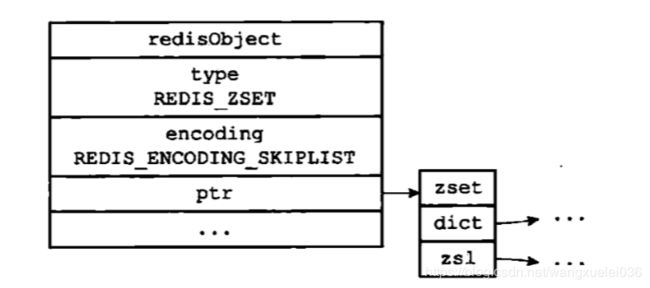
zset结构中的zsl跳跃表按分值从小到大保存了所有元素,每个跳跃表节点都保存了一个集合元素:跳跃表节点的object属性保存了元素的成员,而跳跃表节点的score属性则保存了元素的分值,通过跳跃表,程序可以对所有有序集合进行范围操作
dict字典为有序集合创建了一个从成员到分值的映射,字典中的每个健值对都保存了一个集合元素:字典的键保存了元素的成员,而字典的值保存了元素的分值,通过这个字典,程序可以用O(1)复杂度查找给定成员的分值
有序
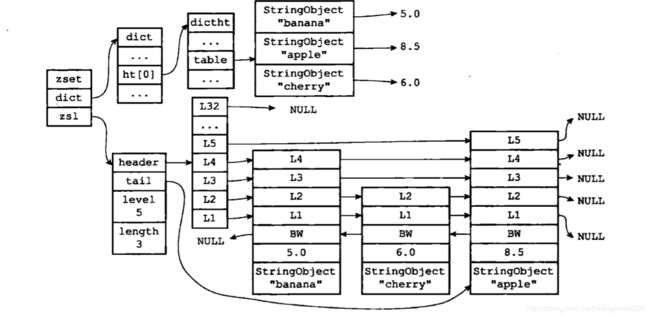
注:图上为了展示清晰,重复展示了跳跃表中各元素信息,但实际上是只向同一内存(共享对象),因此不会造成空间浪费
ziplist编码限制:
(1)有序集合保存的元素数量小于128个
(2)有序集合保存的所有元素成员长度小于64字节
上限值可以根据配置文件中的配置进行调整
思考:
为什么要用字典和跳跃表两个混合实现?为什么不只使用其中一种实现?
结合两者的优点,互相补其短板,跳跃表在进行范围操作的很有优势,但是其根据成员查找分数耗时长,字典根据成员查找分值时间复杂度为O(1),但是无序的结构,会使得其范围操作耗时长
Redis一般应用场景
缓存会话(单点登录)分布式锁,比如:使用setnx
各种排行榜或计数器
商品列表或用户基础数据列表等
使用list作为消息对列
秒杀,库存扣减等
五种类型的应用场景
(1)String,redis对于KV的操作效率很高,可以直接用作计数器。例如,统计在线人数等等,另外string类型是二进制存储安全的,所以也可以使用它来存储图片,甚至是视频等。
(2)hash,存放键值对,一般可以用来存某个对象的基本属性信息,例如,用户信息,商品信息等,另外,由于hash的大小在小于配置的大小的时候使用的是ziplist结构,比较节约内存,所以针对大量的数据存储可以考虑使用hash来分段存储来达到压缩数据量,节约内存的目的,例如,对于大批量的商品对应的图片地址名称。比如:商品编码固定是10位,可以选取前7位做为hash的key,后三位作为field,图片地址作为value。这样每个hash表都不超过999个,只要把redis.conf中的hash-max-ziplist-entries改为1024,即可。
(3)list,列表类型,可以用于实现消息队列,也可以使用它提供的range命令,做分页查询功能。
(4)set,集合,整数的有序列表可以直接使用set。可以用作某些去重功能,例如用户名不能重复等,另外,还可以对集合进行交集,并集操作,来查找某些元素的共同点
(5)zset,有序集合,可以使用范围查找,排行榜功能或者topN功能。
总结:
知晓了Redis各个数据结构的底层实现原理,知道了为了达到节省内存和快速访问的目的每种数据结构可能有两种存储和访问结构,在必要的时候会由一种结构转换成另一种结构,但这个转换的过程会消耗系统性能和内存空间的,所以在使用的过程中需要注意这些配置参数,开发中尽量避免达到这些峰值,使得redis能够持续的提供高效的服务(根据实际业务的需求,量和体系进行提前预测)。