基于docker的spark-hadoop分布式集群搭建:pyspark
基于docker的spark-hadoop分布式集群之一: 环境搭建
一、软件准备
1、基础docker镜像:ubuntu,目前最新的版本是18
-
下载hadoop安装包 (wget http://mirrors.shu.edu.cn/apache/hadoop/common/hadoop-2.7.3/hadoop-2.7.3.tar.gz)
-
下载spark安装包 (wget http://mirrors.shu.edu.cn/apache/spark/spark-2.3.0/spark-2.3.0-bin-hadoop2.7.tgz)
-
下载scala(wget https://downloads.lightbend.com/scala/2.11.8/scala-2.11.8.tgz)
-
下载hive(wget http://mirrors.shu.edu.cn/apache/hive/hive-2.3.2/apache-hive-2.3.2-bin.tar.gz)
-
下载hbase(wget http://mirrors.shu.edu.cn/apache/hbase/1.2.6/hbase-1.2.6-bin.tar.gz)
-
下载zookeeper(wget http://mirrors.shu.edu.cn/apache/zookeeper/zookeeper-3.4.11/zookeeper-3.4.11.tar.gz)
-
下载mysql(wget https://cdn.mysql.com//Downloads/MySQL-5.5/mysql-5.5.62-linux-glibc2.12-i686.tar.gz)
2、需准备的环境软件包:
(1) spark-2.3.0-bin-hadoop2.7.tgz
(2) hadoop-2.7.3.tar.gz
(3) apache-hive-2.3.2-bin.tar.gz
(4) jdk-8u201-linux-x64.tar.gz
(5) mysql-5.5.45-linux2.6-x86_64.tar.gz、mysql-connector-java-5.1.37-bin.jar
(6) scala-2.11.8.tgz
(7) zeppelin-0.8.0-bin-all.tgz
二、ubuntu镜像准备
1、获取官方的镜像:
docker pull ubuntu
2、因官方镜像中的apt源是国外资源,后续扩展安装软件包时较麻烦。先修改为国内源:
(1)启动ubuntu容器,并进入容器中的apt配置目录
$ docker run -it -d ubuntu<br data-filtered="filtered">docker exec -it ubuntu /bin/bash<br data-filtered="filtered">cd /etc/apt
(2)先将原有的源文件备份:
mv sources.list sources.list.bak
(3)换为国内源,这里提供阿里的资源。因官方的ubuntu没有艰装vi等软件,使用echo指令写入。需注意一点,资源必须与系统版本匹配。
echo deb http://mirrors.aliyun.com/ubuntu/ bionic main restricted universe multiverse >> sources.listecho deb http://mirrors.aliyun.com/ubuntu/ bionic-security main restricted universe multiverse >> sources.listecho deb http://mirrors.aliyun.com/ubuntu/ bionic-updates main restricted universe multiverse >> sources.listecho deb http://mirrors.aliyun.com/ubuntu/ bionic-proposed main restricted universe multiverse >> sources.listecho deb http://mirrors.aliyun.com/ubuntu/ bionic-backports main restricted universe multiverse >> sources.listecho deb-src http://mirrors.aliyun.com/ubuntu/ bionic main restricted universe multiverse >> sources.listecho deb-src http://mirrors.aliyun.com/ubuntu/ bionic-security main restricted universe multiverse >> sources.listecho deb-src http://mirrors.aliyun.com/ubuntu/ bionic-updates main restricted universe multiverse >> sources.listecho deb-src http://mirrors.aliyun.com/ubuntu/ bionic-proposed main restricted universe multiverse >> sources.listecho deb-src http://mirrors.aliyun.com/ubuntu/ bionic-backports main restricted universe multiverse >> sources.lis
3、退出容器,提交镜像
$ exit
$ docker commit 容器id ubuntu:latest
生成的ubuntu镜像,就可以做为基础镜像使用。
三、spark-hadoop集群配置
先前所准备的一列系软件包,在构建镜像时,直接用RUN ADD指令添加到镜像中,这里先将一些必要的配置处理好。这些配置文件,都来自于各个软件包中的conf目录下。
1、Spark配置
(1)spark-env.sh
声明Spark需要的环境变量
SPARK_MASTER_WEBUI_PORT=8888
export SPARK_HOME=$SPARK_HOMEls
export HADOOP_HOME=$HADOOP_HOME
export MASTER=spark://hadoop-maste:7077
export SCALA_HOME=$SCALA_HOME
export SPARK_MASTER_HOST=hadoop-maste
export JAVA_HOME=/usr/local/jdk1.8.0_101
export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop
(2)spark-default.conf
关于spark的默认配置
spark.executor.memory=2G
spark.driver.memory=2G
spark.executor.cores=2#spark.sql.codegen.wholeStage=false#spark.memory.offHeap.enabled=true#spark.memory.offHeap.size=4G
#spark.memory.fraction=0.9#spark.memory.storageFraction=0.01#spark.kryoserializer.buffer.max=64m
#spark.shuffle.manager=sort
#spark.sql.shuffle.partitions=600spark.speculation=truespark.speculation.interval=5000spark.speculation.quantile=0.9spark.speculation.multiplier=2spark.default.parallelism=1000spark.driver.maxResultSize=1g
#spark.rdd.compress=falsespark.task.maxFailures=8spark.network.timeout=300spark.yarn.max.executor.failures=200spark.shuffle.service.enabled=truespark.dynamicAllocation.enabled=truespark.dynamicAllocation.minExecutors=4spark.dynamicAllocation.maxExecutors=8spark.dynamicAllocation.executorIdleTimeout=60#spark.serializer=org.apache.spark.serializer.JavaSerializer
#spark.sql.adaptive.enabled=true#spark.sql.adaptive.shuffle.targetPostShuffleInputSize=100000000#spark.sql.adaptive.minNumPostShufflePartitions=1##for spark2.0#spark.sql.hive.verifyPartitionPath=true#spark.sql.warehouse.dir
spark.sql.warehouse.dir=/spark/warehouse
(3)节点声明文件,包括masters文件及slaves文件
主节点声明文件:masters
hadoop-maste
从节点文件:slaves
hadoop-node1
hadoop-node2
2、Hadoop配置
(1)hadoop-env.sh
声明Hadoop需要的环境变量
export JAVA_HOME=/usr/local/jdk1.8.0_101
export HADOOP_CONF_DIR=${HADOOP_CONF_DIR:-"/etc/hadoop"}
for f in $HADOOP_HOME/contrib/capacity-scheduler/*.jar; do
if [ "$HADOOP_CLASSPATH" ]; then
export HADOOP_CLASSPATH=$HADOOP_CLASSPATH:$f
else
export HADOOP_CLASSPATH=$f
fi
done
export HADOOP_OPTS="$HADOOP_OPTS -Djava.net.preferIPv4Stack=true"
export HADOOP_NAMENODE_OPTS="-Dhadoop.security.logger=${HADOOP_SECURITY_LOGGER:-INFO,RFAS} -Dhdfs.audit.logger=${HDFS_AUDIT_LOGGER:-INFO,NullAppender} $HADOOP_NAMENODE_OPTS"
export HADOOP_DATANODE_OPTS="-Dhadoop.security.logger=ERROR,RFAS $HADOOP_DATANODE_OPTS"
export HADOOP_SECONDARYNAMENODE_OPTS="-Dhadoop.security.logger=${HADOOP_SECURITY_LOGGER:-INFO,RFAS} -Dhdfs.audit.logger=${HDFS_AUDIT_LOGGER:-INFO,NullAppender} $HADOOP_SECONDARYNAMENODE_OPTS"
export HADOOP_NFS3_OPTS="$HADOOP_NFS3_OPTS"
export HADOOP_PORTMAP_OPTS="-Xmx512m $HADOOP_PORTMAP_OPTS"
export HADOOP_CLIENT_OPTS="-Xmx512m $HADOOP_CLIENT_OPTS"
export HADOOP_SECURE_DN_USER=${HADOOP_SECURE_DN_USER}
export HADOOP_SECURE_DN_LOG_DIR=${HADOOP_LOG_DIR}/${HADOOP_HDFS_USER}
export HADOOP_PID_DIR=${HADOOP_PID_DIR}
export HADOOP_SECURE_DN_PID_DIR=${HADOOP_PID_DIR}
export HADOOP_IDENT_STRING=$USER
(2)hdfs-site.xml
主要设置了Hadoop的name及data节点。name节点存储的是元数据,data存储的是数据文件
dfs.namenode.name.dir
file:/usr/local/hadoop2.7/dfs/name
dfs.datanode.data.dir
file:/usr/local/hadoop2.7/dfs/data
dfs.webhdfs.enabled
true
dfs.replication
2
dfs.permissions.enabled
false
(3)core-site.xml
设置主节点的地址:hadoop-maste。与后面启动容器时,设置的主节点hostname要一致。
fs.defaultFS
hdfs://hadoop-maste:9000/
hadoop.tmp.dir
file:/usr/local/hadoop/tmp
hadoop.proxyuser.root.hosts
*
hadoop.proxyuser.root.groups
*
hadoop.proxyuser.oozie.hosts
*
hadoop.proxyuser.oozie.groups
*
(4)yarn-site.xml
yarn.nodemanager.aux-services
mapreduce_shuffle
yarn.nodemanager.aux-services.mapreduce_shuffle.class
org.apache.hadoop.mapred.ShuffleHandler
yarn.resourcemanager.hostname
hadoop-maste
yarn.resourcemanager.address
hadoop-maste:8032
yarn.resourcemanager.scheduler.address
hadoop-maste:8030
yarn.resourcemanager.resource-tracker.address
hadoop-maste:8035
yarn.resourcemanager.admin.address
hadoop-maste:8033
yarn.resourcemanager.webapp.address
hadoop-maste:8088
yarn.log-aggregation-enable
true
yarn.nodemanager.vmem-pmem-ratio
5
yarn.nodemanager.resource.memory-mb
22528
每个节点可用内存,单位MB
yarn.scheduler.minimum-allocation-mb
4096
单个任务可申请最少内存,默认1024MB
yarn.scheduler.maximum-allocation-mb
16384
单个任务可申请最大内存,默认8192MB
(5)mapred-site.xml
mapreduce.framework.name
yarn
mapreduce.jobhistory.address
hadoop-maste:10020
mapreduce.map.memory.mb
4096
mapreduce.reduce.memory.mb
8192
yarn.app.mapreduce.am.staging-dir
/stage
mapreduce.jobhistory.done-dir
/mr-history/done
mapreduce.jobhistory.intermediate-done-dir
/mr-history/tmp
(6)主节点声明文件:master
hadoop-maste
3、hive配置
(1)hive-site.xml
主要两个:一是hive.server2.transport.mode设为binary,使其支持JDBC连接;二是设置mysql的地址。
hive.metastore.warehouse.dir
/home/hive/warehouse
hive.exec.scratchdir
/tmp/hive
hive.metastore.uris
thrift://hadoop-hive:9083
Thrift URI for the remote metastore. Used by metastore client to connect to remote metastore.
hive.server2.transport.mode
binary
hive.server2.thrift.http.port
10001
javax.jdo.option.ConnectionURL
jdbc:mysql://hadoop-mysql:3306/hive?createDatabaseIfNotExist=true
javax.jdo.option.ConnectionDriverName
com.mysql.jdbc.Driver
javax.jdo.option.ConnectionUserName
root
javax.jdo.option.ConnectionPassword
root
hive.metastore.schema.verification
false
hive.server2.authentication
NONE
4、Zeppelin配置
(1)zeppelin-env.sh
export JAVA_HOME=/usr/local/jdk1.8.0_101
export MASTER=spark://hadoop-maste:7077
export SPARK_HOME=$SPARK_HOME
export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop
(2)zeppelin-site.xml
http端口默认8080,这里改为18080。为方便加载第三方包,mvnRepo也改为阿里的源。
zeppelin.server.addr
0.0.0.0
Server address
zeppelin.server.port
18080
Server port.
zeppelin.server.ssl.port
18443
Server ssl port. (used when ssl property is set to true)
zeppelin.server.context.path
/
Context Path of the Web Application
zeppelin.war.tempdir
webapps
Location of jetty temporary directory
zeppelin.notebook.dir
notebook
path or URI for notebook persist
zeppelin.notebook.homescreen
id of notebook to be displayed in homescreen. ex) 2A94M5J1Z Empty value displays default home screen
zeppelin.notebook.homescreen.hide
false
hide homescreen notebook from list when this value set to true
zeppelin.notebook.storage
org.apache.zeppelin.notebook.repo.GitNotebookRepo
versioned notebook persistence layer implementation
zeppelin.notebook.one.way.sync
false
If there are multiple notebook storages, should we treat the first one as the only source of truth?
zeppelin.interpreter.dir
interpreter
Interpreter implementation base directory
zeppelin.interpreter.localRepo
local-repo
Local repository for interpreter's additional dependency loading
zeppelin.interpreter.dep.mvnRepo
http://maven.aliyun.com/nexus/content/groups/public/
Remote principal repository for interpreter's additional dependency loading
zeppelin.dep.localrepo
local-repo
Local repository for dependency loader
zeppelin.helium.node.installer.url
https://nodejs.org/dist/
Remote Node installer url for Helium dependency loader
zeppelin.helium.npm.installer.url
http://registry.npmjs.org/
Remote Npm installer url for Helium dependency loader
zeppelin.helium.yarnpkg.installer.url
https://github.com/yarnpkg/yarn/releases/download/
Remote Yarn package installer url for Helium dependency loader
zeppelin.interpreters
org.apache.zeppelin.spark.SparkInterpreter,org.apache.zeppelin.spark.PySparkInterpreter,org.apache.zeppelin.rinterpreter.RRepl,org.apache.zeppelin.rinterpreter.KnitR,org.apache.zeppelin.spark.SparkRInterpreter,org.apache.zeppelin.spark.SparkSqlInterpreter,org.apache.zeppelin.spark.DepInterpreter,org.apache.zeppelin.markdown.Markdown,org.apache.zeppelin.angular.AngularInterpreter,org.apache.zeppelin.shell.ShellInterpreter,org.apache.zeppelin.file.HDFSFileInterpreter,org.apache.zeppelin.flink.FlinkInterpreter,,org.apache.zeppelin.python.PythonInterpreter,org.apache.zeppelin.python.PythonInterpreterPandasSql,org.apache.zeppelin.python.PythonCondaInterpreter,org.apache.zeppelin.python.PythonDockerInterpreter,org.apache.zeppelin.lens.LensInterpreter,org.apache.zeppelin.ignite.IgniteInterpreter,org.apache.zeppelin.ignite.IgniteSqlInterpreter,org.apache.zeppelin.cassandra.CassandraInterpreter,org.apache.zeppelin.geode.GeodeOqlInterpreter,org.apache.zeppelin.jdbc.JDBCInterpreter,org.apache.zeppelin.kylin.KylinInterpreter,org.apache.zeppelin.elasticsearch.ElasticsearchInterpreter,org.apache.zeppelin.scalding.ScaldingInterpreter,org.apache.zeppelin.alluxio.AlluxioInterpreter,org.apache.zeppelin.hbase.HbaseInterpreter,org.apache.zeppelin.livy.LivySparkInterpreter,org.apache.zeppelin.livy.LivyPySparkInterpreter,org.apache.zeppelin.livy.LivyPySpark3Interpreter,org.apache.zeppelin.livy.LivySparkRInterpreter,org.apache.zeppelin.livy.LivySparkSQLInterpreter,org.apache.zeppelin.bigquery.BigQueryInterpreter,org.apache.zeppelin.beam.BeamInterpreter,org.apache.zeppelin.pig.PigInterpreter,org.apache.zeppelin.pig.PigQueryInterpreter,org.apache.zeppelin.scio.ScioInterpreter,org.apache.zeppelin.groovy.GroovyInterpreter
Comma separated interpreter configurations. First interpreter become a default
zeppelin.interpreter.group.order
spark,md,angular,sh,livy,alluxio,file,psql,flink,python,ignite,lens,cassandra,geode,kylin,elasticsearch,scalding,jdbc,hbase,bigquery,beam,groovy
zeppelin.interpreter.connect.timeout
30000
Interpreter process connect timeout in msec.
zeppelin.interpreter.output.limit
102400
Output message from interpreter exceeding the limit will be truncated
zeppelin.ssl
false
Should SSL be used by the servers?
zeppelin.ssl.client.auth
false
Should client authentication be used for SSL connections?
zeppelin.ssl.keystore.path
keystore
Path to keystore relative to Zeppelin configuration directory
zeppelin.ssl.keystore.type
JKS
The format of the given keystore (e.g. JKS or PKCS12)
zeppelin.ssl.keystore.password
change me
Keystore password. Can be obfuscated by the Jetty Password tool
zeppelin.ssl.truststore.path
truststore
Path to truststore relative to Zeppelin configuration directory. Defaults to the keystore path
zeppelin.ssl.truststore.type
JKS
The format of the given truststore (e.g. JKS or PKCS12). Defaults to the same type as the keystore type
zeppelin.server.allowed.origins
*
Allowed sources for REST and WebSocket requests (i.e. http://onehost:8080,http://otherhost.com). If you leave * you are vulnerable to https://issues.apache.org/jira/browse/ZEPPELIN-173
zeppelin.anonymous.allowed
true
Anonymous user allowed by default
zeppelin.username.force.lowercase
false
Force convert username case to lower case, useful for Active Directory/LDAP. Default is not to change case
zeppelin.notebook.default.owner.username
Set owner role by default
zeppelin.notebook.public
true
Make notebook public by default when created, private otherwise
zeppelin.websocket.max.text.message.size
1024000
Size in characters of the maximum text message to be received by websocket. Defaults to 1024000
zeppelin.server.default.dir.allowed
false
Enable directory listings on server. 三、集群启动脚本
整套环境启动较为烦琐,这里将需要的操作写成脚本,在容器启动时,自动运行。
1、环境变量
先前在处理集群配置中,用到许多环境变量,这里统一做定义profile文件,构建容器时,用它替换系统的配置文件,即/etc/profile
profile文件:
if [ "$PS1" ]; then
if [ "$BASH" ] && [ "$BASH" != "/bin/sh" ]; then
# The file bash.bashrc already sets the default PS1.
# PS1='\h:\w\$ '
if [ -f /etc/bash.bashrc ]; then
. /etc/bash.bashrc
fi
else
if [ "`id -u`" -eq 0 ]; then
PS1='# '
else
PS1='$ '
fi
fi
fi
if [ -d /etc/profile.d ]; then
for i in /etc/profile.d/*.sh; do
if [ -r $i ]; then
. $i
fi
done
unset i
fi
export JAVA_HOME=/usr/local/jdk1.8.0_101
export SCALA_HOME=/usr/local/scala-2.11.8
export HADOOP_HOME=/usr/local/hadoop-2.7.3
export SPARK_HOME=/usr/local/spark-2.3.0-bin-hadoop2.7
export HIVE_HOME=/usr/local/apache-hive-2.3.2-bin
export MYSQL_HOME=/usr/local/mysql
export PATH=$HIVE_HOME/bin:$MYSQL_HOME/bin:$JAVA_HOME/bin:$SCALA_HOME/bin:$HADOOP_HOME/bin:$SPARK_HOME/bin:$PATH
2、SSH配置
各个容器需要通过网络端口连接在一起,为方便连接访问,使用SSH无验证登录
ssh_config文件:
Host localhost
StrictHostKeyChecking no
Host 0.0.0.0
StrictHostKeyChecking no
Host hadoop-*
StrictHostKeyChecking no
3、Hadoop集群脚本
(1)启动脚本:start-hadoop.sh
#!/bin/bash
echo -e "\n"
hdfs namenode -format -force
echo -e "\n"
$HADOOP_HOME/sbin/start-dfs.sh
echo -e "\n"
$HADOOP_HOME/sbin/start-yarn.sh
echo -e "\n"
$SPARK_HOME/sbin/start-all.sh
echo -e "\n"
hdfs dfs -mkdir /mr-history
hdfs dfs -mkdir /stage
echo -e "\n":
(2)重启脚本:restart-hadoop.sh
#!/bin/bash
echo -e "\n"
echo -e "\n"
$HADOOP_HOME/sbin/start-dfs.sh
echo -e "\n"
$HADOOP_HOME/sbin/start-yarn.sh
echo -e "\n"
$SPARK_HOME/sbin/start-all.sh
echo -e "\n"
hdfs dfs -mkdir /mr-history
hdfs dfs -mkdir /stage
echo -e "\n"
3、Mysql脚本
(1)mysql 初始化脚本:init_mysql.sh
#!/bin/bash
cd /usr/local/mysql/
echo ..........mysql_install_db --user=root.................
nohup ./scripts/mysql_install_db --user=root &
sleep 3
echo ..........mysqld_safe --user=root.................
nohup ./bin/mysqld_safe --user=root &
sleep 3
echo ..........mysqladmin -u root password 'root'.................
nohup ./bin/mysqladmin -u root password 'root' &
sleep 3
echo ..........mysqladmin -uroot -proot shutdown.................
nohup ./bin/mysqladmin -uroot -proot shutdown &
sleep 3
echo ..........mysqld_safe.................
nohup ./bin/mysqld_safe --user=root &
sleep 3
echo ...........................
nohup ./bin/mysql -uroot -proot -e "grant all privileges on *.* to root@'%' identified by 'root' with grant option;"
sleep 3
echo ........grant all privileges on *.* to root@'%' identified by 'root' with grant option...............
4、Hive脚本
(1)hive初始化:init_hive.sh
#!/bin/bash
cd /usr/local/apache-hive-2.3.2-bin/bin
sleep 3
nohup ./schematool -initSchema -dbType mysql &
sleep 3
nohup ./hive --service metastore &
sleep 3
nohup ./hive --service hiveserver2 &
sleep 5
echo Hive has initiallized!
四、镜像构建
(1)Dockfile
FROM ubuntu:lin
MAINTAINER reganzm [email protected]
ENV BUILD_ON 2018-03-04
COPY config /tmp
#RUN mv /tmp/apt.conf /etc/apt/
RUN mkdir -p ~/.pip/
RUN mv /tmp/pip.conf ~/.pip/pip.conf
RUN apt-get update -qqy
RUN apt-get -qqy install netcat-traditional vim wget net-tools iputils-ping openssh-server libaio-dev apt-utils
RUN pip install pandas numpy matplotlib sklearn seaborn scipy tensorflow gensim #--proxy http://root:[email protected]:7890/
#添加JDK
ADD ./software/jdk-8u101-linux-x64.tar.gz /usr/local/
#添加hadoop
ADD ./software/hadoop-2.7.3.tar.gz /usr/local
#添加scala
ADD ./software/scala-2.11.8.tgz /usr/local
#添加spark
ADD ./software/spark-2.3.0-bin-hadoop2.7.tgz /usr/local
#添加Zeppelin
ADD ./software/zeppelin-0.8.0-bin-all.tgz /usr/local
#添加mysql
ADD ./software/mysql-5.5.45-linux2.6-x86_64.tar.gz /usr/local
RUN mv /usr/local/mysql-5.5.45-linux2.6-x86_64 /usr/local/mysql
ENV MYSQL_HOME /usr/local/mysql
#添加hive
ADD ./software/apache-hive-2.3.2-bin.tar.gz /usr/local
ENV HIVE_HOME /usr/local/apache-hive-2.3.2-bin
RUN echo "HADOOP_HOME=/usr/local/hadoop-2.7.3" | cat >> /usr/local/apache-hive-2.3.2-bin/conf/hive-env.sh
#添加mysql-connector-java-5.1.37-bin.jar到hive的lib目录中
ADD ./software/mysql-connector-java-5.1.37-bin.jar /usr/local/apache-hive-2.3.2-bin/lib
RUN cp /usr/local/apache-hive-2.3.2-bin/lib/mysql-connector-java-5.1.37-bin.jar /usr/local/spark-2.3.0-bin-hadoop2.7/jars
#增加JAVA_HOME环境变量
ENV JAVA_HOME /usr/local/jdk1.8.0_101
#hadoop环境变量
ENV HADOOP_HOME /usr/local/hadoop-2.7.3
#scala环境变量
ENV SCALA_HOME /usr/local/scala-2.11.8
#spark环境变量
ENV SPARK_HOME /usr/local/spark-2.3.0-bin-hadoop2.7
#Zeppelin环境变量
ENV ZEPPELIN_HOME /usr/local/zeppelin-0.8.0-bin-all
#将环境变量添加到系统变量中
ENV PATH $HIVE_HOME/bin:$MYSQL_HOME/bin:$SCALA_HOME/bin:$SPARK_HOME/bin:$ZEPPELIN_HOME/bin:$HADOOP_HOME/bin:$JAVA_HOME/bin:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar:$PATH
RUN ssh-keygen -t rsa -f ~/.ssh/id_rsa -P '' && \
cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys && \
chmod 600 ~/.ssh/authorized_keys
COPY config /tmp
#将配置移动到正确的位置
RUN mv /tmp/ssh_config ~/.ssh/config && \
mv /tmp/profile /etc/profile && \
mv /tmp/masters $SPARK_HOME/conf/masters && \
cp /tmp/slaves $SPARK_HOME/conf/ && \
mv /tmp/spark-defaults.conf $SPARK_HOME/conf/spark-defaults.conf && \
mv /tmp/spark-env.sh $SPARK_HOME/conf/spark-env.sh && \
mv /tmp/zeppelin-env.sh $ZEPPELIN_HOME/conf/zeppelin-env.sh && \
mv /tmp/zeppelin-site.xml $ZEPPELIN_HOME/conf/zeppelin-site.xml && \
cp /tmp/hive-site.xml $SPARK_HOME/conf/hive-site.xml && \
mv /tmp/hive-site.xml $HIVE_HOME/conf/hive-site.xml && \
mv /tmp/hadoop-env.sh $HADOOP_HOME/etc/hadoop/hadoop-env.sh && \
mv /tmp/hdfs-site.xml $HADOOP_HOME/etc/hadoop/hdfs-site.xml && \
mv /tmp/core-site.xml $HADOOP_HOME/etc/hadoop/core-site.xml && \
mv /tmp/yarn-site.xml $HADOOP_HOME/etc/hadoop/yarn-site.xml && \
mv /tmp/mapred-site.xml $HADOOP_HOME/etc/hadoop/mapred-site.xml && \
mv /tmp/master $HADOOP_HOME/etc/hadoop/master && \
mv /tmp/slaves $HADOOP_HOME/etc/hadoop/slaves && \
mv /tmp/start-hadoop.sh ~/start-hadoop.sh && \
mkdir -p /usr/local/hadoop2.7/dfs/data && \
mkdir -p /usr/local/hadoop2.7/dfs/name && \
mv /tmp/init_mysql.sh ~/init_mysql.sh && chmod 700 ~/init_mysql.sh && \
mv /tmp/init_hive.sh ~/init_hive.sh && chmod 700 ~/init_hive.sh && \
mv /tmp/restart-hadoop.sh ~/restart-hadoop.sh && chmod 700 ~/restart-hadoop.sh && \
mv /tmp/zeppelin-daemon.sh ~/zeppelin-daemon.sh && chmod 700 ~/zeppelin-daemon.sh
#创建Zeppelin环境需要的目录,设置在zeppelin-env.sh中
RUN mkdir /var/log/zeppelin && mkdir /var/run/zeppelin && mkdir /var/tmp/zeppelin
RUN echo $JAVA_HOME
#设置工作目录
WORKDIR /root
#启动sshd服务
RUN /etc/init.d/ssh start
#修改start-hadoop.sh权限为700
RUN chmod 700 start-hadoop.sh
#修改root密码
RUN echo "root:555555" | chpasswd
CMD ["/bin/bash"]
(2)构建脚本:build.sh
echo build Spark-hadoop images
docker build -t="spark" .
(3)构建镜像,执行:
./build.sh
五、容器构建脚本
(1)创建子网
所有的网络,通过内网连接,这里构建一个名为spark的子网:build_network.sh
echo create network
docker network create --subnet=172.16.0.0/16 spark
echo create success
docker network ls
(2)容器启动脚本:start_container.sh
echo start hadoop-hive container...
docker run -itd --restart=always --net spark --ip 172.16.0.5 --privileged --name hive --hostname hadoop-hive --add-host hadoop-node1:172.16.0.3 --add-host hadoop-node2:172.16.0.4 --add-host hadoop-mysql:172.16.0.6 --add-host hadoop-maste:172.16.0.2 --add-host zeppelin:172.16.0.7 spark-lin /bin/bash
echo start hadoop-mysql container ...
docker run -itd --restart=always --net spark --ip 172.16.0.6 --privileged --name mysql --hostname hadoop-mysql --add-host hadoop-node1:172.16.0.3 --add-host hadoop-node2:172.16.0.4 --add-host hadoop-hive:172.16.0.5 --add-host hadoop-maste:172.16.0.2 --add-host zeppelin:172.16.0.7 spark-lin /bin/bash
echo start hadoop-maste container ...
docker run -itd --restart=always --net spark --ip 172.16.0.2 --privileged -p 18032:8032 -p 28080:18080 -p 29888:19888 -p 17077:7077 -p 51070:50070 -p 18888:8888 -p 19000:9000 -p 11100:11000 -p 51030:50030 -p 18050:8050 -p 18081:8081 -p 18900:8900 -p 18088:8088 --name hadoop-maste --hostname hadoop-maste --add-host hadoop-node1:172.16.0.3 --add-host hadoop-node2:172.16.0.4 --add-host hadoop-hive:172.16.0.5 --add-host hadoop-mysql:172.16.0.6 --add-host zeppelin:172.16.0.7 spark-lin /bin/bash
echo "start hadoop-node1 container..."
docker run -itd --restart=always --net spark --ip 172.16.0.3 --privileged -p 18042:8042 -p 51010:50010 -p 51020:50020 --name hadoop-node1 --hostname hadoop-node1 --add-host hadoop-hive:172.16.0.5 --add-host hadoop-mysql:172.16.0.6 --add-host hadoop-maste:172.16.0.2 --add-host hadoop-node2:172.16.0.4 --add-host zeppelin:172.16.0.7 spark-lin /bin/bash
echo "start hadoop-node2 container..."
docker run -itd --restart=always --net spark --ip 172.16.0.4 --privileged -p 18043:8042 -p 51011:50011 -p 51021:50021 --name hadoop-node2 --hostname hadoop-node2 --add-host hadoop-maste:172.16.0.2 --add-host hadoop-node1:172.16.0.3 --add-host hadoop-mysql:172.16.0.6 --add-host hadoop-hive:172.16.0.5 --add-host zeppelin:172.16.0.7 spark-lin /bin/bash
echo "start Zeppeline container..."
docker run -itd --restart=always --net spark --ip 172.16.0.7 --privileged -p 38080:18080 -p 38443:18443 --name zeppelin --hostname zeppelin --add-host hadoop-maste:172.16.0.2 --add-host hadoop-node1:172.16.0.3 --add-host hadoop-node2:172.16.0.4 --add-host hadoop-mysql:172.16.0.6 --add-host hadoop-hive:172.16.0.5 spark-lin /bin/bash
echo start sshd...
docker exec -it hadoop-maste /etc/init.d/ssh start
docker exec -it hadoop-node1 /etc/init.d/ssh start
docker exec -it hadoop-node2 /etc/init.d/ssh start
docker exec -it hive /etc/init.d/ssh start
docker exec -it mysql /etc/init.d/ssh start
docker exec -it zeppelin /etc/init.d/ssh start
echo start service...
docker exec -it mysql bash -c "sh ~/init_mysql.sh"
docker exec -it hadoop-maste bash -c "sh ~/start-hadoop.sh"
docker exec -it hive bash -c "sh ~/init_hive.sh"
docker exec -it zeppelin bash -c "$ZEPPELIN_HOME/bin/zeppelin-daemon.sh start"
echo finished
docker ps
(3)容器停止并移除:stop_container.sh
docker stop hadoop-maste
docker stop hadoop-node1
docker stop hadoop-node2
docker stop hive
docker stop mysql
docker stop zeppelin
echo stop containers
docker rm hadoop-maste
docker rm hadoop-node1
docker rm hadoop-node2
docker rm hive
docker rm mysql
docker rm zeppelin
echo rm containers
docker ps
六、运行测试
依次执行如下脚本:
1、创建子网
./build_network.sh
2、启动容器
./start_container.sh
3、进入主节点:
docker exec -it hadoop-maste /bin/bash
jps一下,进程是正常的
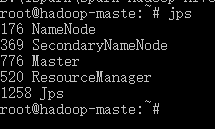
4、访问集群子节点
ssh hadoop-node2
一样可以看到,与主节点类似的进程信息
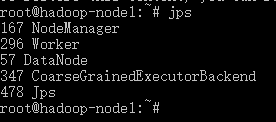
5、Spark测试
访问:http://localhost:38080
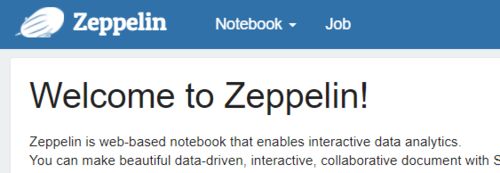
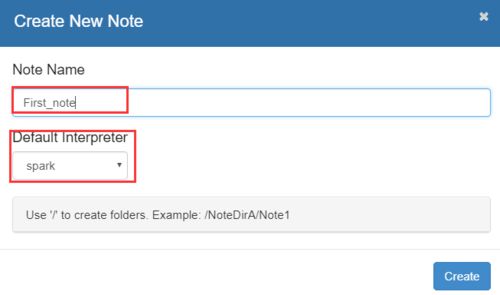
(2)新建一个note,使用Spark环境
(