Linux配置并编译内核
-
几种配置方法
配置内核代码并不会花费太长时间。配置工具会询问许多问题并且允许开发者配置内核的每个方面。如果你有不确定的问题或者特性,你最好使用配置工具提供的默认值。本系列教程会使读者逐步了解配置内核的整个过程。
配置代码前需要在源文件的文件夹内打开一个终端。当终端打开后,基于你喜好的配置界面,这里有几种不同的配置方法:
- make config - 纯文本界面 (最常用的选择)。
- make menuconfig - 基于文本彩色菜单和单选列表。这个选项可以加快开发者开发速度。需要安装ncurses(ncurses-devel)。
- make nconfig - 基于文本的彩色菜单。需要安装curses (libcdk5-dev)。
- make xconfig - QT/X-windows 界面。需要安装QT。
- make gconfig - Gtk/X-windows 界面。需要安装GTK。
- make oldconfig - 纯文本界面,但是其默认的问题是基于已有的本地配置文件。
- make silentoldconfig - 和oldconfig相似,但是不会显示配置文件中已有的问题的回答。
- make olddefconfig -和silentoldconfig相似,但有些问题已经以它们的默认值选择。
- make defconfig - 这个选项将会创建一份以当前系统架构为基础的默认设置文件。
- make ${PLATFORM}defconfig - 创建一份使用arch/$ARCH/configs/${PLATFORM}defconfig中的值的配置文件。
- make allyesconfig - 这个选项将会创建一份尽可能多的问题回答都为‘yes’的配置文件。
- make allmodconfig - 这个选项将会创建一份将尽可能多的内核部分配置为模块的配置文件。
注意:内核代码可以放进内核自身,也可以成为一个模块。例如,用户可以将蓝牙驱动作为一个模块加入(独立于内核),或者直接放到内核里,或者完全不加蓝牙驱动。
- 当代码放到内核本身时,内核将会请求更多的内存并且启动会花费更长的时间。然而,内核会执行的更好。
- 如果代码作为模块加入,代码将会一直存在于硬盘上,需要时进行加载,接着模块被加载到内存中。这可以减少内核内存的使用,并减少启动的时间。但是,由于内核和模块在内存上相互独立所以会影响内核的性能。
- 另一种选择是不添加蓝牙代码。举例来说,内核开发人员假如知道系统永远都不会使用蓝牙设备,因此这个驱动就可以不加到内核中。这提升了内核的性能。然而,如果用户之后需要蓝牙设备,那么他么需要安装蓝牙模块或者升级内核才行。
make allnoconfig - 这个选项只会生成内核所必要代码的配置文件。它对尽可能多的问题都回答no。这有时会导致内核无法工作在为编译该内核的硬件上。
make randconfig - 这个选项会对内核选项随机选择(译注:这是做什么用途的?!)。
make localmodconfig - 这个选项会根据当前已加载模块列表和系统配置来生成配置文件。
make localyesconfig - 将所有可装载模块(LKM)都编译进内核(译者注:这里与原文 ‘This will set all module options to yes - most (or all) of the kernel will not be in modules’的意思不同,作者也作出了解释:13307)。
贴士:最好使用“make menuconfig”,因为用户可以保存进度。“make config”不会提供这样的便利,因为配置过程会耗费大量时间。
-
配置:
大多数开发者选择使用“make menucongfig”或者其他图形菜单之一。如下图所示。
"Cross-compiler tool prefix (CROSS_COMPILE) []"(交叉编译器工具前缀):如果你不是做交叉编译就不用设置。如果你正在交叉编译,对ARM系统输入像"arm-unknown-linux-gnu-",对64位PC输入像"x86_64-pc-linux-gnu-"的字样。对其他处理器而言还有许多其他可能的命令,但是这个表太大了。一旦一名开发者知道他们想要支持的处理器,很容易就可研究出处理器需要的命令。
注意:交叉编译是为别的处理器编译代码。比如,一台Intel系统正编译着不在Intel处理器上运行的程序,比如,这个系统可能正在编译着要在ARM或AMD处理器上运行的代码。
注意:每一项选择会改变接下来显示什么问题及何时显示。
“Local version - append to kernel release (LOCALVERSION) []”(本地版本号,附加到内核版本号后面):这使开发人员可以给定一个特殊版本号或命名他们自定义的内核。我将输入“LinuxDotOrg”,这样,内核版本会显示为“3.9.4-LinuxDotOrg”。接下来。
“Automatically append version information to the version string (LOCALVERSION_AUTO)(是否自动添加版本信息到版本号后):如果本地有一个Git版本库,git的修订号会被添加到版本号后面。没有使用git,则不选中该项。不然git修订号将会追加到版本号中。
Kernel compression mode (Gzip) ---> 使用哪一种格式压缩内核:开发人员可以从五个选项中选择一个。
- Gzip (KERNEL_GZIP)
- Bzip2 (KERNEL_BZIP2)
- LZMA (KERNEL_LZMA)
- XZ (KERNEL_XZ)
- LZO (KERNEL_LZO)
Gzip是默认值。每种压缩格式和其他压缩格式相比都有更高或者更低的压缩比,更好的压缩比意味着更小的体积,但是与低压缩比文件相比,它解压时需要更多的时间。
“((none))Default hostname”(默认主机名):这里可以配置主机名。通常地,开发者这行留空(我这里留空),以便以后Linux用户可以自己设置他们的主机名。
"System V IPC"(内核是否支持IPC):进程间通信使进程间可以通信和同步。最好启用IPC不然许多程序将无法工作。
“POSIX Message Queues”(是否使用POSIX消息队列):这个问题只会在IPC启用后看见。POSIX消息队列是一种给每条消息一个优先级的消息队列(一种进程间通信形式)。
“open by fhandle syscalls”(是否使用文件句柄系统调用来打开文件):当有需要进行文件系统操作的时候,程序是否允许使用文件句柄而不是文件名进行。
“Auditing support”(是否支持审计):审计支持会记录所有文件的访问和修改,如果选中,才会弹出下一条“Make audit loginuid immutable ”。
“Make audit loginuid immutable ”(是否要审计进程身份ID不可变):进程是否可以改变它们的loginuid(LOGIN User ID),如果启用,用户空间的进程将无法改变他们的loginuid。为了更好的性能,我们这里禁用这个特性。(译注:对于使用systemd这样的系统,其是通过中央进程来重启登录服务的,设置为“y”可以避免一些安全问题;而使用较旧的SysVinit和Upstart的系统,其需要管理员手工重启登录服务,应该设置为“N”)
注意:当通过"make menuconfig"配置时,无论用户按任何键都无法改变选项。开发者不需要去改变这些选项,因为之前的选择决定了另外一个问题的选择。
"IRQ subsystem--->"配置内核IRQ子系统:中断请求(IRQ)是硬件发给处理器的一个信号,它暂时停止一个正在运行的程序并允许一个特殊的程序占用CPU运行。
IRQ subsystem目录中的第一个问题属于内核特性,"Expose hardware/virtual IRQ mapping via debugfs "(通过debugfs来显示硬件/虚拟的IRQ映射):使用虚拟的调试文件系统来映射硬件及Linux上对应的IRQ中断号。这个用作调试目的,大多数用户不需要用到,所以我选择了"no"。
"Timers subsystem --->"(计时器子系统):
“[ ] Old Idle dynticks config:旧的入口,此选项被用来保持与旧版本的兼容,未来会被删除。
"[ ] High Resolution Timer Support"(高精度定时器):并不是所有的硬件支持这个,通常地说,如果硬件很慢或很旧,那么选择"no",否则像我一样选择"yes"。如果你的硬件不能胜任这个选项,那么开启这个选项仅仅是给内核增加体积。高精度定时器(hrtimer)是从2.6.16开始被引入内核,采用红黑树算法(传统timer使用时间轮算法),在硬中断中执行中断服务例程,它可以为我们提供纳秒级的定时精度,以满足对精确时间有迫切需求的应用程序或内核驱动,例如多媒体应用,音频设备的驱动程序等等
"CPU/Task time and stats accounting --->"(CPU/任务用时与状态统计):这个是关于进程的追踪。第一个问题看上去像这样:
"Cputime accounting ( ) --->"CPU时间统计方式,总共有三种选择:
- Simple tick based cputime acounting(简单基于滴答的用时统计):最简单的基于tick统计方式,使用jiffies变量(这个变量记录了系统自启动以来经过的操作系统节拍的数目) 官方推荐:if unsure, say Y(yes)
- Full dynticks CPU time accounting(全动态滴答的用时统计):利用上下文跟踪子系统,通过观察每一个内核与用户空间的边界来统计,如果你不是在帮助开发内核的动态定时器(dynticks)的话,不要选择这个
- Fine granularity task level IRQ time accounting(细粒度的任务级IRQ用时统计):通过读取TSC时间戳进行CPU时间统计,这是统计CPU时间的更细粒度的方式,对系统性能有显著不良影响 官方推荐:if in doubt , say No
注意:CPU滴答是抽象测量CPU时间的方式。每个处理器、操作系统和安装的系统都不同,比如说,一个更强大的处理器会比老的处理器拥有更多的CPU滴答。如果你安装了一个Linux系统,然后接着在同一块磁盘上重新安装了它,你可能会得到一个更快或更慢的CPU滴答时间(至少一些计算机技术书上这么说)。通常来讲,一个更快的时钟速度意味着更多的CPU滴答。
"BSD Process Accounting"(BSD进程记账):这个内核特性会记录每个进程不同的关闭信息。为了得到一个更小和更快的内核,选择"no".
"Export task/process statistics through netlink (通过netlink导出任务/进程统计数据) ": 使内核可以通过网络套接字导出进程统计。网络套接字是内核和用户空间进程间IPC通信的一种形式。如果启用本项,才会弹出下两项:
Enable per-task delay accounting (TASK_DELAY_ACCT) (启用针对每个任务的延迟统计)
Enable extended accounting over taskstats (TASK_XACCT) (启用taskstats的扩展统计)
TASK_DELAY_ACCT监视进程并注意资源访问的延迟。比如,TASK_DELAY_ACCT可以看到X进程正在为了CPU时间而等待,如果TASK_DELAY_ACCT观察到进程已经等待了太长时间,这个进程接着就会被给予一些CPU时间。TASK_XACCT会收集额外的统计数据,为了更小的内核负载我会禁用这个。
"RCU Subsyctem --->"显示RCU子系统:读取-复制-更新子系统是一种低负载的同步机制,它允许程序查看到正在被修改/更新的文件。配置工具已经回答了第一个问题。
RCU Implementation (RCU 实现方式)
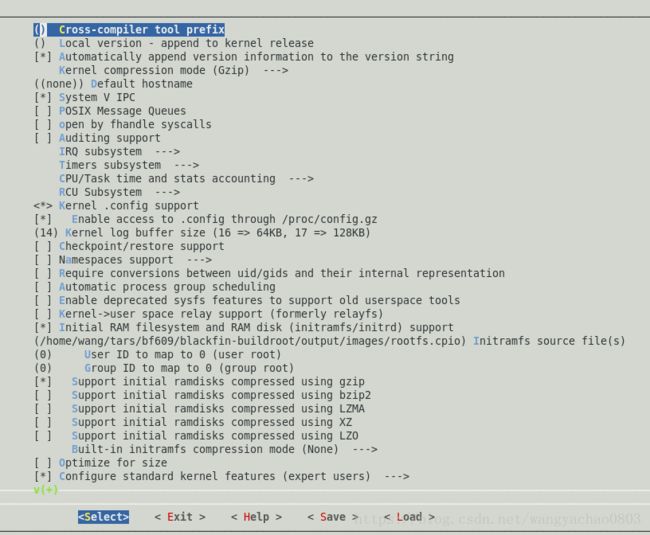
"Kernel . config support":允许.config文件(即编译LINUX时的配置文件)保存在内核当中。开发人员可以选择保存由这个配置工具生成的设置到一个文件中。这个文件可以放在内核中,也可在一个模块中,或者完全不保存。这个文件可以被想要编译一个完全跟某人相同内核的开发者使用。这个文件还可以帮助开发人员使用一个更新的编译器重新编译一个内核。举例来说,开发人员配置并编译了一个内核,然而编译器有一些bug,但开发人员仍然需要一个使用这些设置的内核。而值得庆幸的是,开发人员可以升级他们的编译器,并使用设置文件来节省他们重新配置内核的时间。开发人员也可以在另一台计算机上保存源代码和配置文件并编译内核。至于另一个目的,开发人员可以加载该文件,并根据需要调整设置。
"[ * ] Enable access to .config through /proc/config.gz "(启用通过/proc/config.gz来访.config)。
"(14) Kernel log buffer size (16 => 64KB, 17 => 128KB) "(内核日志缓冲区大小):小的缓冲区意味着它无法像更大的缓冲区那样保持日志更长的时间。这个选择取决于开发者想要日志保持的时间。
"Namespaces support --->" 命名空间支持:允许服务器为不同的用户信息提供不 同的用户名空间服务
[*] UTS namespace 通用终端系统的命名空间。它允许容器,比如Vservers利用UTS命名空间来为不同的服务器提供不同的UTS。如果不清楚,选N。
[*] IPC namespace IPC命名空间,不确定可以不选
[*] User namespace User命名空间,不确定可以不选
[*] PID Namespaces PID命名空间,不确定可以不选
[*] Network namespace
"Automatic process group scheduling": 自动进程组调度
"[ ] enable deprecated sysfs features to support old userspace tools "
"Kernel->user space relay support (formerly relayfs) ":在某些文件系统上( 比如debugfs ) 提供从内核空间向用户空间传递大量数据的接口,我目前没有此类应用场景
"[*] Initial RAM filesystem and RAM disk (initramfs/initrd) support":用于在真正内核装载前,做一些操作(俗称两阶段启动),比如加载module ,mount 一些非root 分区,提供灾难恢复shell 环境等。
接下来,关于初始虚拟磁盘(Linux的内核映像文件)所支持的压缩格式。你可以启用所有支持的压缩格式。
- Support initial ramdisks compressed using gzip
- Support initial ramdisks compressed using bzip2
- Support initial ramdisks compressed using LZMA
- Support initial ramdisks compressed using XZ
- Support initial ramdisks compressed using LZO
"Optimize for size "(优化大小):设置了内核的编译内核编译选项。开发者可以让编译器在编译时优化代码。
"Configure standard kernel features (expert users)---> "(配置标准内核特性(专家级用户)):配置更多的内核特性。
Enable 16-bit UID system calls (UID16)): 启用过时的16位UID系统调用封装器,,系统调用就会使用16位UID。
"sysctl syscall"(Sysctl syscall support )支持。这使/proc/sys成为二进制路径的接口。
"Load all symbols for debugging/ksymoops "(载入所以的调试符号)
"Include all symbols in kallsyms "(包括所有的kallsyms符号)。这些都是启用调试标志。
( (Enable support for printk)启用printk支持,这会输出内核消息到内核日志中。这在内核出错时是很重要的。编译一个"哑巴"内核并不是一个好主意。然而,如果我们启用了这个支持,就会被一些开发者看到这些出错,要么就不要启用。
(BUG() support)bug支持: 除非有必要,否则可以禁用。禁用这项将会不支持WARN信息和BUG信息。这会减小内核的体积。
(Enable ELF core dumps ):内核是否可以生成内核转储文件。这会使内核变大4KB。所以选择了"no"。
注意:内核转储文件(内存或者系统的转储)是程序崩溃前已记录的状态。内核转储是用来调试问题的。这个转储文件的格式是ELF(Executable and Linkable Format )。
(Enable full-sized data structures for core)(启用完全大小的内核数据结构):虽然会增加内核的大小,但性能也随之增加。所以选择"yes"。
(Enable futex support ):为了使内核可以运行基于glibc的程序,必须启用FUTEX。这个特性启用了快速用户空间互斥锁(Fast Userspace muTEXes)。
注意:glibc(GNU C Library)是由GNU实现的标准C库。
注意:FUTEX (fast userspace mutex)是用来防止两个线程访问同一个不能被多个线程使用的共享资源。
(Enable eventpoll support ):使能epoll系统调用。epoll是一种I/O事件通知系统。
(Enable signalfd() system call) :使能signalfd系统调用,可收到来自文件描述符的信号。
(Enable timerfd() system call ):它允许程序使用定时器事件获取文件描述符。
(Enable eventfd() system call ):使能eventfd系统调用。它默认启用访问共享内存文件系统(Use full shmem filesystem (SHMEM)。共享内存文件系统是一种虚拟内存文件系统。
"Enable AIO support (AIO)":使能线程化程序使用的POSIX异步I/O。
注意:异步I/O用来处理输入/输出,它允许线程在传输完成前就完成处理。
“Embedded system ”:如果你正在给一个嵌入式系统配置一个内核,那么可以选择"yes"。
注意:嵌入式系统是运行在一个更大的电子系统的实时计算机。
(Kernel performance events and counters ))(内核性能事件和计数器):配置内核性能事件和计时器。配置工具没有给开发者选择,直接启用了事件和计数器。这是一个重要特性。
(Enable VM event counters for /proc/vmstat )(VM事件计数器):如果启用,那么事件计数就会显示在/proc/vmstat。如果禁用就不会显示,/proc/vmstat只会显示内存页计数。
(Disable heap randomization )禁用随机heap:(heap堆是一个应用层的概念,即堆对CPU是不可见的,它的实现方式有多种,可以由OS实现,也可以由运行库实现,如果你愿意,也可以在一个栈中来实现一个堆) 。然而我们不应该去启用它,因为任何基于libc5的软件都无法工作在这个系统上!只有我们有特别的理由这么做或者如果你不会使用基于libc5的软件时才去启用它。
"Choose SLAB allocator"SLAB分配器: SLAB分配器是一个没有碎片且有效率地将内核对象放置在内存中的内存管理系统。
1. SLAB (SLAB)
2. SLUB (Unqueued Allocator) (SLUB)
3. SLOB (Simple Allocator) (SLOB)
(Profiling support ):支持扩展性能。
"GCOV-based kernel profiling --->"
(Enable gcov-based kernel profiling )基于gcov的内核分析。这可以被禁用。
"[*] Enable loadable module support --->"为了允许内核加载模块,需要启用可加载模块支持。
(Forced module loading )(允许强制加载模块 ):内核一般只能加载有版本号的模块。如果想允许内核加载没有版本 号的模块,就启用这个特性。除非你有特定的需求需要这个特性,否则不要启用。
(Module unloading)允许卸载已经加载的模块:如果启用,Linux内核也能卸载模块。如果内核判断你要卸载的模块不应 该被卸载,那么用户则无法卸载模块。
(Forced module unloading )允许强制卸载正在使用中的模块(比较危险):这个选项允许你强行卸除模块,即使内核认为 这不安全。内核将会立即移除模块,而不管是否有人在使用它(用 rmmod -f 命令)。这主要是针对开发者和冲动的用 户提供的功能。如果不清楚,选N。
(Module versioning support )允许使用其他内核版本的模块:使用不是为你的内核开发的、或者并不适用你的版本号的 模块,可以启用。最好不要混用不同版本号的模块,所以我禁用了这个特性。
(Source checksum for all modules ):为所有的模块校验源码,如果你不是自己编写内核模块就不需要它。这个功能是 为了防止你在编译模块时不小心更改了内核模块的源代码但忘记更改版本号而造成版本冲突。如果不清楚,选N。。
(Module signature verification (MODULE_SIG)):模块签名验证,并不必要,选中则内核在加载模块前会检查并验证签 名。
(Enable the block layer):块设备支持,禁用这个将会使块设备无法使用并且无法启用某些文件系统。
(Block layer SG support v4):仅在使用大于2TB的块设备时需要
(Block layer SG support v4 helper lib ):通用scsi块设备第4版支持 。
(Block layer data integrity support ):对块设备的数据完整性支持。这个特性允许拥有更好的数据完整性来提供设备数据保护特性。许多设备不支持这个特性。
(Block layer bio throttling support ):可用于限制设备的IO速度,如果启用那就可以限制设备的IO速率。
(Advanced partition selection ):支持外部分区,如果你想要在linux上使用一个在其他的介质上运行着操作系统的硬盘时,选择Y,如果你不确定时可以选N 。
IO Schedulers:IO调度器I/O是输入输出带宽控制,主要针对硬盘,是核心的必须的东西。这里提供了三个IO调度器:
Deadline I/O scheduler:轮询的调度器,简洁小巧,提供了最小的读取延迟和尚佳的吞吐量,特别适合于读取较多的环境(比如数据库)Deadline I/O调度器简单而又紧密,在性能上和抢先式调度器不相上下,在一些数据调入时工作得更好。至于在单进程I/O磁盘调度上,它的工作方式几乎和抢先式调度器相同,因此也是一个好的选择。
CFQ I/O scheduler:QoS策略为所有任务分配等量的带宽,避免进程被饿死并实现了较低的延迟,可以认为是上述两种调度器的折中.适用于有大量进程的多用户系统CFQ调度器尝试为所有进程提供相同的带宽。它将提供平等的工作环境,对于桌面系统很合适。
Default I/O scheduler (No-op) :默认IO调度器我这样理解上面三个IO调度器:
抢先式是传统的,它的原理是一有响应,就优先考虑调度。如果你的硬盘此时在运行一项工作,它也会暂停下来先响应用户。 期限式则是:所有的工作都有最终期限,在这之前必须完成。当用户有响应时,它会根据自己的工作能否完成,来决定是否响应用户。 CFQ则是平均分配资源,不管你的响应多急,也不管它的工作量是多少,它都是平均分配,一视同仁的。
( ) Deadline
( ) CFQ
(* ) No-op
在下一个选项中可以选择抢占模式。
Preemption Model(抢占模式)
1. No Forced Preemption (Server) (非强制抢占)
> 2. Voluntary Kernel Preemption (Desktop) (自愿内核抢占)
3. Preemptible Kernel (Low-Latency Desktop) (可抢占内核)
抢占就是暂停一个意图让它之后继续执行的中断任务的过程。抢占强制一个进程暂停,执行中的任务无法忽视抢占。
接着,我们被询问关于"Reroute for broken boot IRQs (X86_REROUTE_FOR_BROKEN_BOOT_IRQS)"。这是一个对于假中断的简单修复。假中断是一种无用的硬件中断,这些通常是有电子干扰或者错误连接的电子产品触发。记住,中断是发送给处理器需要马上注意的信号。
这个选项对任何机器都很重要;我怀疑任何人可能都会有禁用这个特性的理由(Machine Check / overheating reporting (X86_MCE))。内核必须意识到过热和数据损坏,不然,系统将会继续操作,这样只会导致进一步的破坏。
下面,用户可以启用禁用"Intel MCE features (X86_MCE_INTEL)",这是一种额外的对像热度监控的Intel MCE特性的支持。因为我是为AMD64处理器编译内核所以我选择了"no"。机器检测异常(MCE)是一种当处理器发现硬件问题时的错误输出。MCE通常会导致内核严重错误(kernel panic)(相当于Windows中的"蓝屏")。
这个除了是AMD设备外是同一个问题Intel MCE features (X86_MCE_INTEL)。
下一个是我会禁用的调试特性(Machine check injector support (X86_MCE_INJECT))。这个会允许注射检查。如果你偶尔执行机器注射,那最好编译成模块而不是编译进内核。机器注射可以使设备即使实际没有错误也可以发送一个伪造的错误信息。这个用来确认内核和其他进程可以正常处理错误。比如,如果CPU过热,接着应该关机,但是开发者如何在不损坏CPU的情况下测试代码。注射错误是一种最好的方法,因为它只是一种告诉硬件发送错误信号的软件。
注:模块是对可能被使用或者很少执行的特性/驱动而言的。只加入在许多使用该内核的系统中用到的特性/驱动到内核中。
如果内核很可能用在Dell笔记本上,那么启用这个特性(Dell laptop support (I8K))。否则,如果一些用户可能在戴尔笔记本电脑上用到这个内核,将其作为一个模块加入。如果这个内核不打算支持Dell笔记本,那就像我一样忽略掉它。特别地,这个支持是一个允许Dell Inspiron 8000系列笔记本访问处理器的系统管理模式的驱动。系统管理模式的目的是得到处理器的温度和风扇状态,这对一些需要控制风扇的系统有用。
下面,用户可以选择微码加载支持(CPU microcode loading support (MICROCODE))。这可以允许用户在支持这个特性的AMD或者Intel芯片上更新微码。
注意:为了加载微码,你必须拥有一个为你的处理器设计的合法的二进制微代码拷贝。
如果要加载微码补丁(修复bug或加入次要的特性)到intel芯片上(Intel microcode loading support (MICROCODE_INTEL)),这个就必须启用。这里我禁用了它。
然后是AMD芯片的类似选项(AMD microcode loading support (MICROCODE_AMD))。
启用这个支持(/dev/cpu/*/msr - Model-specific register support (X86_MSR))可以允许某个处理器有权限使用x86特殊模块寄存器(Model-Specific Registers (MSRs))。这些寄存器是一些字符设备,包括major 202下minor 0到31的设备((/dev/cpu/0/msr to /dev/cpu/31/msr))。这个特性用在多处理器系统上。每个虚拟字符设备都连接到一个特定的CPU。
注意:MSRs被用来改变CPU设备、调试、性能监控和执行追踪。MSRs使用x86指令集。
在这之后,我们有一个选项"CPU information support (X86_CPUID)",启用这个特性允许处理器访问x86 CPUID指令,这需要通过字符设备在一个特定的CPU上执行。这些字符设备包括major 202下minor 0到31的设备(/dev/cpu/0/msr to /dev/cpu/31/msr),就像上面x86_MSR支持的这些。
如果处理器支持,启用内核线性映射来使用1GB的内存页(Enable 1GB pages for kernel pagetables (DIRECT_GBPAGES))。启用这个可以帮助减轻TLB的压力。
页是内存本身的基本单位(位是数据的基本单位)。页的大小是由硬件自身决定的。页码表是虚拟和物理内存间的映射。物理内存是设备上的内存。虚拟内存是到内存的地址。依赖于系统架构,硬件可以访问大于实际内存地址的地址。举例来说,一个64位系统拥有6GB内存,管理员在需要时可以加上更多的内存。这是因为还有很多虚拟内存地址。然而,在很多32位系统上,系统管理员可以增加一条8GB的内存,但是系统无法完全使用它,因为系统中没有足够的虚拟内存地址去访问大容量的内存。转换后援缓冲器(Translation Lookaside Buffer (TLB))是一种提升虚拟内存转换速度的缓存系统。
下面,我们看到了NUMA选项(Numa Memory Allocation and Scheduler Support (NUMA))。这可以允许内核在CPU本地内存分配器上分配CPU可使用的内存。这个支持同样可使内核更好感知到NUMA。很少的32位系统需要这个特性,但是一些通用的645位处理器使用这个特性。我选择了"no"。
为了系统使用旧方式来检测AMD NUMA节点拓扑,启用这个特性(Old style AMD Opteron NUMA detection (AMD_NUMA))。下一个选项是一种更新的检测方式(ACPI NUMA detection (X86_64_ACPI_NUMA))。如果两个都启用,新的方式将会占支配作用。一些硬件在使用其中一种方式而不是另外一个时工作得更好。
如果为了调试目的的NUMA仿真,可以启用下一个特性(NUMA emulation (NUMA_EMU))。
注意:如果你不打算进行调试并且你需要一个快速、轻量级系统,那么禁用尽可能多的调试特性。
下一个选项中,选择你的内核打算如何处理NUMA节点的最大数量。接下来选择内存模型,这里可能只有一个内存模型选择。内存模型指定了内存如何存储。
Maximum NUMA Nodes (as a power of 2) (NODES_SHIFT) [6]
Memory model
> 1. Sparse Memory (SPARSEMEM_MANUAL)
choice[1]: 1
为了提升性能,这里有一个选项用通过虚拟内存映射(Sparse Memory virtual memmap (SPARSEMEM_VMEMMAP))来优化pfn_to_page和page_to_pfn操作。页帧号是每页被给定的号码。这两个操作用来从号码得到页或者从页得到号码。
下一个选项是允许一个节点可以移除内存(Enable to assign a node which has only movable memory (MOVABLE_NODE))。内核页通常无法移除。当启用后,用户可以热插拔内存节点,同样可移除内存允许内存整理。作为出入内存的数据,只要有可用空间一组数据可能被划分到不同内存。
接着前面的内存问题,我们还有更多的问题。这些可能已被配置工具预配置了。第三个选项(BALLOON_COMPACTION),当启用时可以帮助减少内存碎片。碎片内存会减慢系统速度。第四个选项(COMPACTION)允许内存压缩。下面列到的第五个选 (MIGRATION)允许页面被移动。
Allow for memory hot-add (MEMORY_HOTPLUG) (允许内存热添加)
Allow for memory hot remove (MEMORY_HOTREMOVE) (允许内存热移除)
Allow for balloon memory compaction/migration (BALLOON_COMPACTION) (允许泡状内存规整和合并)
Allow for memory compaction (允许内存规整)
Page migration (MIGRATION) (页合并)
注意:启用可移动内存会启用以上5个特性。
下一步,我们可以"Enable KSM for page merging (KSM)"。内核同页合并(Kernel Samepage Merging (KSM))会查看程序认为可以合并的内核。如果两页内存完全相同这可以节约内存。一块内存可以被删除或者被合并,并且只有一块可以使用。
配置工具可能会自动选择保存多少内存用于用户分配(Low address space to protect from user allocation (DEFAULT_MMAP_MIN_ADDR) [65536])。
下一个选项很重要(Enable recovery from hardware memory errors (MEMORY_FAILURE))。如果内存故障并且系统有MCA恢复或者ECC内存,系统就可以继续运行并且恢复。要使用这个特性,硬件自身和内核都必须支持。
机器检测架构(Machine Check Architecture (MCA))是一个一些CPU上可以发送硬件错误信息给操作系统的特性。错误更正码内存(Error-correcting code memory (ECC memory))是一种内存设备检测和纠正错误的形式。
下面,配置工具会自动启用"HWPoison pages injector (HWPOISON_INJECT)"。这个特性允许内核标记一块坏页为"poisoned",接着内核会杀死创建坏页的程序。这有助于停止并纠正错误。
为了允许内核使用大页(Transparent Hugepage Support (TRANSPARENT_HUGEPAGE)),启用这个特性。这可以加速系统但是需要更多内存。嵌入式系统不必使用这个特性。嵌入式系统通常只有非常小的内存。
如果启用了上面的,那么必须配置大页的sysfs支持。
Transparent Hugepage Support sysfs defaults
1. always (TRANSPARENT_HUGEPAGE_ALWAYS)
> 2. madvise (TRANSPARENT_HUGEPAGE_MADVISE)
choice[1-2?]: 2
下面的选项是增加process_vm_readv和process_vm_writev这两个系统调用(Cross Memory Support (CROSS_MEMORY_ATTACH))。这允许特权进程访问另外一个程序的地址空间。
如果有tmem,启用缓存清理(cleancache)通常是一个好主意 (Enable cleancache driver to cache clean pages if Transcendent Memory (tmem) is present (CLEANCACHE))。当一些内存页需要从内存中移除时,cleancache会将页面放在cleancache-enabled的文件系统上。当需要该页时,页会被重新放回内存中。超内存(tmem)没有一组已知大小的内存,内核对此内存使用间接寻址。
下一个选项允许在tmen激活后缓存交换页(Enable frontswap to cache swap pages if tmem is present (FRONTSWAP))。frontswap在交换分区放置数据。交换特性的支持需要这个。
最好启用下一个特性(Check for low memory corruption (X86_CHECK_BIOS_CORRUPTION))。这会检测低位内存的内存损坏情况。这个特性在执行期被禁止。为了启用这个特性,在内核命令行内加入 "memory_corruption_check=1"(这会在以后的文章中讨论;这不同于任何命令行)。即使经常执行这个特性,也只使用非常小的开销(接近没有)。
接下来我门可以设置内存损坏检测的默认设置(“Set the default setting of memory_corruption_check (X86_BOOTPARAM_MEMORY_CORRUPTION_CHECK))。这可以选择是否开启或关闭memory_corruption_check。最好启用内存损坏检测不然如果一部分重要内存损坏后可能会导致数据丢失和系统崩溃。
这个选项关注的是BIOS(Amount of low memory, in kilobytes, to reserve for the BIOS (X86_RESERVE_LOW) [64])。配置工具通常知道给BIOS预留内存的最佳大小。
对于Intel P6处理器,开发者可以启用存储区域类型寄存器(MTRR (Memory Type Range Register) support (MTRR))。这用于连接着VGA卡的AGP和PCI卡。启用这个特性内核会创建/proc/mtrr。
如果X驱动需要加入回写入口,那么启用下面的选项(MTRR cleanup support (MTRR_SANITIZER))。这会将MTRR的布局从连续转换到离散。存储区域类型寄存器(Memory type range registers (MTRRs))提供了一种软件访问CPU缓存的方法。
下面,配置工具已经设置了一些MTRR选项
MTRR cleanup enable value (0-1) (MTRR_SANITIZER_ENABLE_DEFAULT) [1]
MTRR cleanup spare reg num (0-7) (MTRR_SANITIZER_SPARE_REG_NR_DEFAULT) [1]
为了设置页级缓冲控制,那就启用PAT属性(x86 PAT support (X86_PAT))。页属性表(Page Attribute Table (PATs))是现在版的MTRRs并比它更灵活。如果你经历过因启用它而引发的启动问题,那么禁用这个特性后重新编译内核。我选择了"no"。
Linux内核拥有许多可以配置的特性,接下来我们还有许多要配置。
下一个可以配置的特性是x86的随机数生成器(x86 architectural random number generator (ARCH_RANDOM))。记住,我们现在配置的是针对AMD64系统的内核代码。这个随机数生成器使用Intel x86的RDRAND指令。这并不通用,所以为了一个更轻量的内核我禁用了它。
接着,我们可以启用或者禁用"Supervisor Mode Access Prevention (X86_SMAP)"。这是Intel处理器使用的安全特性。SMAP在一些条件下只允许内核访问用户空间。这个有助于保护用户空间。如果启用,这里有一点性能和内核大小的开销,但是开销很小。由于我是用的是AMD系统,所以我禁用了这个特性。
开发者可以启用"EFI runtime service support (EFI)"。只有在有EFI固件的系统上启用它。拥有这个特性,内核可以使用的EFI服务。EFI是一个操作系统和硬件如何交流的规范,所以EFI固件是使用这个规范的硬件代码。因为我没有EFI固件,所以我禁用了它。
这是一个应该被启用的有用的安全方式(Enable seccomp to safely compute untrusted bytecode (SECCOMP))。这个安全特性在使用非可信的字节码的数值计算(执行大量计算的软件)中使用。字节码(可移植代码)是一种被解释器有效读取的代码。字节码不是源代码,但它也不是汇编或者二进制代码。非可信的代码是一种可能导致系统/数据损坏的代码。可能会破坏系统或者毁坏数据的非可信的代码通过seccomp被隔离在独立的地址空间中。这是通过文件描述符传输的方法。通常上,最好启用这个安全特性,即使会有一些性能开销,除非你在制作一个需要榨干性能的内核。
这里是另外一个安全特性(Enable -fstack-protector buffer overflow detection (CC_STACKPROTECTOR))。缓冲溢出是数据被写在超出了它的内存界限而进入了邻近的内存中。这是一个安全威胁。一些恶意软件使用缓冲区溢出来破坏系统。启用这个会使用GCC选项 "-fstack-protector"。GCC是一个Linux编译器,在你配置完成后用它来编译内核。这个编译器参数会在返回地址前在栈上加入一个canary值(特殊的安全代码)。这个值会在返回前被验证。当内存溢出发生时,canary值会得到覆盖消息。这时,会导致内核崩溃。如许多人知道的那样,内核错误意味着系统将要崩溃,但是这比系统被入侵或者数据永久损害的好。发生内核错误,系统会重启,但是如果缓冲溢出则可能导致系统被入侵。一个简单的重启无法修复破坏(译注:但也不会更坏)。你必须用GCC 4.2或者更高版本支持这个参数的GCC来编译内核。
提示:要知道你使用的版本号,在命令行内键入"gcc --version"。
在这之后,我们可以配置定时器频率。配置工具建议使用250Hz,所以我们使用这个值。
Timer frequency
1. 100 HZ (HZ_100)
>2. 250 HZ (HZ_250)
3. 300 HZ (HZ_300)
4. 1000 HZ (HZ_1000)
choice[1-4?]: 2
使用1000Hz通常来讲对许多系统而言太快了。定时器频率决定着定时器中断被使用的频率。这有助于在时间线上的系统操作。程序并不是随机地执行一条命令,相反它们会等到定时器中断结束。这保持着有组织和结构的处理。频率为100Hz的定时器中断之间的时间是10ms,250Hz是4ms,1000Hz是1ms。现在许多开发者会马上想到1000Hz是最好的。好吧,这取决于你对开销的要求。一个更大的定时器频率意味着更多的能源消耗和更多的能源被利用(在定时器上),产生更多的热量。更多的热量意味着硬件损耗的更快。
注意:如果某个特定的特性对你并不重要或者你不确定该选择什么,就使用配置工具选择的默认值。比如,就我现在正在配置的内核而言,使用哪个定时器对我并不重要。总的来说,如果你没有特别的原因去选择任何一个选项时,就使用默认值。
下面这个有趣的系统调用可能会对一些用户有用(kexec system call (KEXEC))。kexec调用会关闭当前内核去启动另外一个或者重启当前内核。硬件并不会关闭,并且这个调用可以无需固件的帮助工作。bootloader是不执行的(bootloader是启动操作系统的软件) 。这个重启发生在操作系统级别上而不是硬件上。使用这个系统调用会快于执行一个标准的关机或者重启,这会保持硬件在加电状态。这个系统调用并不能工作在所有系统上。为了更高性能,启用这个热启动功能。
为了使用kexec,对重启后要使用的内核使用如下命令替换""。同样,使用之前我们讲过的内核参数替换"" (我会在以后的文章中更深入的讨论。)
kexec -l
特别地,我这里输入:
kexec -l /boot/vmlinuz-3.8.0-27-generic –append="root=/dev/sda1"
注意:硬件有时不需要重置,所以这不依赖于kexec。
下面,我们有一个适用于kexec的调试特性(kernel crash dumps (CRASH_DUMP))。当kexec被调用时,一个崩溃信息(crash dump)会生成。除非你有必要调试kexec,否则这个并不必要。我禁用了这个特性。
再者,我们有另外一个kexec特性(kexec jump (KEXEC_JUMP))。kexec跳允许用户在原始内核和kexec启动的内核之间切换。
最好对内核启动地址使用默认值(Physical address where the kernel is loaded (PHYSICAL_START) [0x1000000])。
下一个内核选项(Build a relocatable kernel (RELOCATABLE))允许内核放在内存的任何地方。内核文件会增大10%,但是超出部分会在执行时从内存移除。许多人也许想知道这为什么很重要。在2.6.20内核前,救援内核(rescue kernel)必须被配置和编译运行在不同的内存地址上。当这个特性发明后,开发者不必再编译两个内核。救援内核不会在第一个已加载的内核的地方加载,因为该块内存已被占用或者发生了错误。(如果你正在使用救援内核,那么明显第一个内核发生了错误)
下面这个特性应该在可以增加CPU数量的系统中启用,除非你有特别的理由不去这么做(Support for hot-pluggable CPUs (HOTPLUG_CPU))。配置工具会自动启用这个特性。在这个特性下,你可以在一个拥有很多处理器的系统上激活/停用一个CPU,这并不是说在系统中插入新的CPU,所有的CPU必须已经安装在系统中。
下面的选项会让我们选择设置上面的特性是否默认启用(Set default setting of cpu0hotpluggable (BOOTPARAM\HOTPLUG_CPU0))。为了性能最好禁用这个特性直到需要的时候。
接着的这个调试特性允许开发者调试CPU热插拔特性(Debug CPU0 hotplug (DEBUG_HOTPLUG_CPU0))。我禁用了它。
为了兼容旧版本的glibc(<2.3.3),可以启用这个特性(Compat VDSO support (COMPAT_VDSO))。这适用于通过映射32位在VDSO(虚拟动态链接共享对象)的旧式地址。Glibc是GNC C库;这是GNU工程实现的C标准库。
如果系统内核被用于一个缺乏完整功能的bootloader上,那么启用这个特性(Built-in kernel command line (CMDLINE_BOOL))。这允许用户在内核自身上使用一条命令行(译注:及其参数),那么管理员可以修复内核问题。如果bootloader已经有了一条命令行(像grub),那么这个特性不必启用。
现在我们可以配置ACPI和电源了。首先,我们被要求选择系统是否可以挂起到内存(Suspend to RAM and standby (SUSPEND))。高级配置和电源接口(ACPI)是一种对于设备配置和电源管理的开放标准。挂起系统会将数据放在内存上,同时硬件进入一种低功耗的状态。系统不会完全关机。如果用户需要计算机进入一个低功耗的状态,但是希望保留当前已打开程序时是非常有用的。关闭一个系统会完全关闭系统电源并且清理内存。
下面,我们可以启用睡眠(Hibernation (aka 'suspend to disk') (HIBERNATION))。睡眠就像挂起模式,但是内存中所有数据被保存到硬盘上,并且设备完全关闭。这允许用户在电源恢复后继续使用他们已打开的程序。
这里,我们可以设置默认的恢复分区(Default resume partition (PM_STD_PARTITION))。很少有开发者和管理员需要这个特性。当系统从睡眠中恢复时,他会加载默认的恢复分区。
"Opportunistic sleep "。启用会让内核在没有活跃的唤醒调用被调用时进入挂起或者睡眠状态。这意味着空闲的系统将会进入挂起模式以节省电源。
sysfs是位于/sys/的虚拟文件系统。这个虚拟文件系统包含了关于设备的信息。当进入/sys/时,它似乎是硬盘的一部分,但是这个并不是一个真正的挂载点。这些文件实际存在于内存中。这与/proc/是同一个概念。
注意:"/sysfs/"是一个文件夹,而"/sysfs"则可以是一个根目录下名为"sysfs"的文件。许多Linux用户会混淆这两种命名约定。
如果启用了上面的选项,那么你可以设置"Maximum number of user space wakeup sources (0 = no limit) (PM_WAKELOCKS_LIMIT)"。最好选择默认,那么你就可以启用垃圾收集器(Garbage collector for user space wakeup sources (PM_WAKELOCKS_GC))。垃圾收集是一种内存管理方式。
注意: 在需要更多内存的系统中,通常最好在大多数情况下尽可能启用垃圾收集。不然内存会消耗得更快且杂乱。
"User space wakeup sources interface "。启用这个特性将会允许唤醒源对象被激活、停用,并通过基于sysfs接口由用户空间创建。唤醒源对象会追踪唤醒事件源。
(Run-time PM core functionality)。这个选项允许IO硬件在运行时进入低功耗状态。
(Power Management Debug Support): 电源管理代码调试支持。
注意: 注意这些我引用/显示的配置工具上的选项或问题不再显示选项代码(括号间所有的大写字母)。这是因为我没有使用基于ncurses的配置工具(make menuconfig)而是使用默认工具去得到选项、设置和问题。记住,"make config"缺乏保存当前进度的能力。
在这之后,配置工具会启用"ACPI (Advanced Configuration and Power Interface) Support"。最好允许这个电源管理规范。通常配置工具会启用这个特性。
为了允许向后兼容,启用"Deprecated /proc/acpi files"。新的实现使用更新的在/sys下的实现。我禁用了这个选项。一个相似的问题询问关于"Deprecated power /proc/acpi directories"。通常上,如果你禁用了这些文件,你不再需要这些文件夹,所以我禁用了他们。一些旧的程序可能会使用这些文件和文件夹。如果你在给旧的的Linux系统上编译一个新的内核,最好启用这个选项。
下面,我们有另外一个文件接口可以启用或者禁用(EC read/write access through)。这会在/sys/kernek/debug/ec下创建一个嵌入式控制器接口。嵌入式控制器通常在笔记本中读取传感器,内核代码通过系统的BIOS表提供的ACPI代码访问嵌入式控制器。
这里有另外一个可以启用或者禁用的向后兼容特性 (Deprecated /proc/acpi/event support)。acpi守护进程可能会读取/proc/api/event来管理ACPI生成的驱动。不同于这个接口,守护进程使用netlink事件或者输入层来得到送给用户空间的事件,acpi守护进程管理ACPI事件。
下一个选项允许开发者启用一个特性,它会通知内核现在使用的是交流电源(AC Adapter)还是电池。下一个选项从/proc/acpi/battery/ (Battery)中提供电池信息。
为了内核在电源/睡眠按钮按下或者盖子合上时不同表现,启用这个“按钮”选项(Button)。这些事件在/proc/acpi/event/中控制。比如这样的行为,如果在用户账户的电源选项启用了挂起,当笔记本电脑的盖子关闭后系统将会挂起。
下一个ACPI扩展是针对显卡的(Video)。
ACPI风扇控制可以被启用/禁用(Fan)。最好启用ACPI风扇管理,这有助于节能。
我们正在进一步配置内核中,但在接下来的文章中还有更多要做。
欢迎进入Linux内核系列文章的下一篇!本篇我们继续配置文件系统。
首先,我们启用"General filesystem local caching manager",它允许内核存储文件系统缓存。这可以增加在存储空间开销上的性能。
为了调试目的,缓存系统可以通过统计信息监控(Gather statistical information on local caching)。通常上,这个特性应该只在你计划调试的时候启用。
下面的特性很像上面的,但是这个特性存储延迟信息(Gather latency information on local caching)。再说一次,这是个调试特性。
"Debug FS-Cache"提供了很多其他的缓存系统的调试功能。
下面的缓存调试工具会保存文件系统缓存对象的全局列表(任何进程可以访问这个列表)(Maintain global object list for debugging purposes)。
为了增强网络文件系统的速度,启用接下来的驱动(Filesystem caching on files)。这个特性允许整个本地文件系统被用于远程文件系统和存储单元的缓存。Linux内核会管理这个分区。
有两种不同的用于调试的驱动可用于本地缓存系统和远程文件系统,它们是(Debug CacheFiles)和(Gather latency information on CacheFiles)。
大多数通常的光盘文件系统是ISO 9660标准的ISO-9660,故名(ISO 9660 CDROM file system support)。这个驱动用于读/写主流的光盘。
当读取光盘中的长Unicode文件名或者这类文件时,需要这个驱动(Microsoft Joliet CDROM extensions)。这是ISO-9660文件系统的扩展。
"Transparent decompression extension"允许数据以压缩形式写入并以透明方式解压读出。这允许光盘上存放更多的数据。
"UDF file system support"允许内核读/写UDF文件系统的可重写光盘。UDF被设计用来管理增量写入。UDF允许光盘思想闪存盘那样使用。系统可以比常规ISO-9660文件系统写入的光盘更快地写入以及更新。然而,这并不比使用闪存快。
如你所知,Windows是一个很流行的系统。有很多存储器使用FAT文件系统。万幸的是,Linux支持这样的文件系统。这会明显地增加内核的大小,但是既然FAT文件系统是如此的通用,那么这点开销也是值得的。
为了支持FAT文件系统,启用这个驱动(VFAT (Windows-95) fs support)。在写本篇的时候。驱动还不支持FAT64(通常成为exFAT)。
代码页的大小可以在这里设置(Default codepage for FAT)。
在此之后,可以设置FAT文件系统的默认字符集(Default iocharset for FAT)。
NTFS文件系统在这个驱动提供支持(Default iocharset for FAT)。驱动提供了只读特性。为了写入NTFS,启用这个驱动(NTFS write support)。
Linux内核提供了NTFS文件系统的调试工具(NTFS debugging support)。
要在root根目录下有个proc目录,必须启用这个特性(/proc file system support)。一些其他相似的驱动依赖于这个,包括(/proc/kcore support)、(/proc/vmcore support)和 (Sysctl support (/proc/sys))。proc系统("process"的缩写)使用的proc文件系统有时称作procfds。这个文件系统在硬件的内存中,并在启用时创建。因此,当你在浏览proc中的文件时,用户仿佛像在其他存储单元上那样浏览内存。proc扮演一个用户空间和内核空间之间接口的角色。proc是在内核空间。
"Enable /proc page monitoring"提供了一些文件监视进程的内存利用。
"sysfs file system support"创建/sys文件加。sys文件系统在内存中并提供了内核对象的接口。
tmp目录被许多应用需要,包括Linux自己,因此强烈建议启用这个驱动(Tmpfs virtual memory file system support (former shm fs))。tmp文件系统可能存储在硬盘或者内存中,并只被用于存储临时文件。
Tmpfs POSIX Access Control Lists"驱动tmpfs虚拟文件系统额外的文件权限特性。
"Tmpfs extended attributes"提供了通常的tmpfs更多的属性。
"HugeTLB file system support"驱动提供了基于ramfs的hugetlbfs文件系统。这个虚拟文件系统包含了HugeTLB页。
configfs文件系统是一个以文件系统形式存在的内核对象管理器(Userspace-driven configuration filesystem)。强烈建议启用这个驱动。ConfigFS很像sysfs。然而,ConfigFS被用于创建和删除内核对象,而sysfs被用于浏览和修改内核对象。
下面,我们可以回到"真正"的文件系统了。那就是用户用来存放他们个人文件的文件系统。下面,内核能够读取ADFS文件系统(ADFS file system support)。
AFDFS文件系统写入被一个独立且不稳定的驱动提供 (ADFS write support (DANGEROUS))。ADFS代表Advanced Disc Filing System(高级光盘归档系统)。
Linux同样支持Amiga快速文件系统(Amiga FFS file system support)。
"eCrypt filesystem layer support"提供了POSIX兼容的加密文件系统层。这个eCrypt可以 用于任何文件系统无论驻留的文件系统分区表是什么。
eCrypt层可以有一个设备文件如果启用了这个驱动(Enable notifications for userspace key wrap/unwrap)。设备路径是/dev/ecryptfs。
Linux同样支持HFS和HFS+(Apple Macintosh file system support)和(Apple Extended HFS file system support)。与
BeFS可以在Linux上作为只读文件系统使用(BeOS file system (BeFS) support (read only))。通常上,编写读取特性比编写写入能力简单。
特殊的BeFS调试特性(Debug BeFS)。
EFS是另外一个Linux只读不写的文件系统。 (EFS file system support (read only)).
一些闪存可能使用JFFS2文件系统(Journalling Flash File System v2 (JFFS2) support)。下面,可以设置调试层 (JFFS2 debugging verbosity)。
为了在NAND和NOR闪存上使用JFFS2,需要这个驱动(JFFS2 write-buffering support)。
下面的驱动提供了更好的错误保护(Verify JFFS2 write-buffer reads)。
启用"JFFS2 summary support"可以更快挂载JFFS文件系统。这个驱动存储文件系统的信息。
像其他的文件系统的扩展/额外属性驱动一样,JFFS2也有这种驱动(JFFS2 XATTR support)。
JFFS2文件系统支持不同的透明压缩系统。这允许JFFS2系统上的文件更小,并且在读取时不需要用户任何特殊的操作。 (Advanced compression options for JFFS2)、 (JFFS2 ZLIB compression support)、(JFFS2 LZO compression support)、(JFFS2 RTIME compression support) 和 (JFFS2 RUBIN compression support)。默认的压缩格式定义在下面的选项中(JFFS2 default compression mode)。
JFFS2的继任者也被Linux内核支持(UBIFS file system support)。无排序块图像文件系统(Unsorted Block Image File System (UBIFS)) 同样与LogFS竞争。
Linux内核同样支持LogFS(LogFS file system)。
基于ROM的嵌入式系统需要CramFS的支持(Compressed ROM file system support (cramfs))。
此外,嵌入式系统可以使用SquashFS,这是一种只读压缩文件系统(SquashFS 4.0 - Squashed file system support)。Linux内核也支持SquashFS的扩展属性(Squashfs XATTR support)。
SquashFS支持三种不同的压缩格式 (Include support for ZLIB compressed file systems)、(Include support for LZO compressed file systems) 和 (Include support for XZ compressed file systems)。SquashFS的块大小可以设置为4KB (Use 4K device block size?)。同样,可以设置缓存大小(Additional option for memory-constrained systems)。
Linux内核支持 FreeVxFS (FreeVxFS file system support (VERITAS VxFS(TM) compatible))、 Minix (Minix file system support)、 MPEG filesystem (SonicBlue Optimized MPEG File System support)、 HPFS (OS/2 HPFS file system support)、 QNX4 (QNX4 file system support (read only))、 QNX6 (QNX6 file system support (read only)) 和 ROM 文件系统 (ROM file system support)。
"RomFS backing stores (Block device-backed ROM file system support)"提供了ROMfs不同额外的属性和能力的列表。
"Persistent store support"驱动提供对pstore文件系统的支持,这允许访问平台级的持久性存储。
pstore文件系统可以存储内核日志/消息(Log kernel console messages)。
当内核崩溃时(相当于Windows中的蓝屏死机),"Log panic/oops to a RAM buffer"会在RAM中存储日志。
下面一个驱动提供对Xenix、 Coherent、Version 7 和 System V 文件系统的支持(System V/Xenix/V7/Coherent file system support)。
Linux内核同样支持UFS(UFS file system support (read only))、 (UFS file system write support (DANGEROUS)) 和 (UFS debugging)。
内核也支持exofs(exofs: OSD based file system support)。
flash友好型文件系统(Flash-Friendly FileSystem)是一种对于闪存设备的特殊文件系统(F2FS filesystem support (EXPERIMENTAL))、 (F2FS Status Information )、 (F2FS extended attributes) 和 (F2FS Access Control Lists).
下篇文章我们将配置网络文件系统。谢谢!
欢迎来到下一篇关于内核配置文章!还有大量的选项需要配置。这篇文章将主要讨论PCI和ACPI。
这里我们可以启用由ACPI控制的扩展坞和可移动驱动器槽的支持(Dock)。记住,ACPI(Advanced Configuration and Power Management Interface)是一个电源管理系统。扩展坞是一种其他的设备通过额外的接口插入的设备。扩展坞可以容纳许多不同的端口和连接器。一个ACPI控制的扩展坞是指其电源管理是通过ACPI进行的。驱动器槽是一套可以增加硬盘的设备,这也可以由ACPI管理。
下面,我们允许ACPI用来管理空闲的CPU(Processor)。这会让处理器在空闲时进入ACPI C2或者C3状态。这可以节省电源并降低CPU芯片的温度。处理器只在100%没有占用时才进入空闲状态。没有程序必须请求一个特定时间的CPU资源。
CPU电源有四个状态 - C0、C1、C2和C3。C0是操作激活状态。C1(Halt)是一个不执行指令激活状态,但是可以立刻执行指令。C2(Stop-Clock)是一种断电状态。C3(Sleep)是一种比C2更彻底的断电状态。在C3状态中,现在缓存不再被同步或者管理,直到CPU离开这个状态。第五个状态称作C1E(Enhanced Halt State),他拥有低功耗。
如果启用了IPMI驱动,那么ACPI可以访问BMC控制器(IPMI)。基板管理控制器(BMC)是一种管理软件和硬件间连接的微控制器。智能平台管理接口(IPMI)是一种框架,通过直接的硬件层面而不是登录shell或者操作系统层面来管理计算机。
ACPI v4.0进程聚合器允许内核应用一个CPU配置到所有系统中的处理器中(Processor Aggregator)。截止到ACPI v4.0,只有idle状态可以用这个方式配置。
接下来,可以启用ACPI热区(Thermal Zone)。多数硬件支持这个特性。这允许风扇的电源由ACPI管理。
如果启用这个选项,自定义DSDT可以链接到内核。在这个设置中,开发者必须在文件中包含完整的路径名。系统差异表(DSDT)是一个包含了系统支持的电源事件信息的文件。它不需要输入路径名,这些表存在于固件中。内核会帮你处理这些。这个主要的目的是用于如果开发者需要使用不同于设备内置的表时用到。
任意ACPI表都可以通过initrd来覆盖(ACPI tables override via initrd)。ACPI表是指示如何控制并与硬件交互的基础规则和指令。
像内核的其他部分一样,ACPI系统也可以生成调试信息(Debug Statements)。像其他调试特性一样,你或许希望禁用它并省下50KB。
启用下面的特性会为系统检测到的每个PCI插槽(PCI slot detection driver)创建文件(/sys/bus/pci/slots/)。一个PCI插槽是在PCI主板上的一个端口,它允许用户接上其他的PC设备。PCI是主板的一种类型。PCI是指组件互相通信的方式。有些应用程序可能需要这些文件。
电源管理定时器是另外一种电源管理系统(Power Management Timer Support)。这是许多系统追踪时间的方式。这个只需要很少的能源。处理器的空闲、电压/频率调节和节流都不会影响这个定时器。大量的系统需要使用这个特性。
下面,可以启用ACPI模块和容器设备驱动(Container and Module Devices)。这会启用处理器、内存和节点的热插拔支持。它需要NUMA系统。
下面的驱动提供对ACPI内存的热插拔支持(Memory Hotplug)。有些设备甚至启用这个驱动也不支持热插拔。如果驱动以模块形式加入,那么模块将会被acpi_memhotplug调用。
注意:对于内核某个特定的功能,硬件、BIOS和固件在必须支持时会有问题。有些系统的BIOS是不控制硬件的。这种类型的BIOS通常不会限制特性。如果内核确实有一个特定的功能,硬件必须有能力完成这样的任务。
智能电源管理驱动提供访问电池的状态和信息(Smart Battery System)。
下面,我们有一个"Hardware Error Device"驱动。设备通过SCI报告硬件错误。通常上,大多数的错误会是已纠正的错误。
下面的是ACPI调试特性(Allow ACPI methods to be inserted/replaced at run time)。这允许ACPI AML方式不通过重启系统管理。 AML代表的是ACPI机器语言(ACPI Machine Language)。AML代码可以通过请求重启来改变和测试。
APEI是ACPI的错误接口(ACPI Platform Error Interface (APEI))。APEI从芯片给操作系统报告错误。这个错误接口同样提供错误注射的能力。
当"SFI (Simple Firmware Interface) Support" 启用后,硬件固件可以发送消息给操作系统。固件与操作系统间的通信通过内存中的静态表。SFI-only的计算机的内核工作需要这个特性。
(CPU Frequency scaling): 改变处理器的时钟速度和运行。CPU频率调整意味着改变处理器的时钟速度。这个驱动可以用于降低时钟频率以节能。
下面是另外一个电源管理子系统(CPU idle PM support)。当处理器不在活跃状态时,它最好处在有效的空闲方式来减少电源消耗和减少CPU损耗。减少电源消耗同样可以降低内部元件的发热。
Linux内核提供了很多CPU空闲驱动。在多处理器系统上,一些用户可能有一个理由在每个CPU上使用不同的驱动(Support multiple cpuidle drivers)。启用这个驱动可以允许用户给每个处理器设置不同的驱动。
对于Intel处理器,内核有一个特别为管理这类CPU芯片空闲的驱动(Cpuidle Driver for Intel Processors)。
当内存芯片空闲时,这些同样可以处于低功耗状态(Intel chipset idle memory power saving driver)。这个驱动是特别支持IO AT的Intel设备的。
不同的计算机使用不同类型的主板(PCI support)。其中一种类型是PCI。这个驱动允许内核运行在PCI主板上。
下面,我们可以启用/禁用 "Support mmconfig PCI config space access"。
接下来,我们有一个选择启用/禁用主桥窗口驱动(Support mmconfig PCI config space access)。警告:这个驱动还没有完成(至少在3.9.4中是这样)。
像上面提到的主板,还有另一种类型的主板。写一个选项是提供"PCI Express (PCIe) support"的驱动。PCIe是一种改进并且更快速的PCI。
在这之后,下面的驱动应该被启用以支持PCIe主板上的热插拔(PCI Express Hotplug driver)。
接着,我们可以启用/禁用PCIe主板报错(Root Port Advanced Error Reporting)。这就是PCIe AER驱动。
下一个特性允许用户使用PCIe EREC(PCI Express ECRC settings control)覆盖BIOS和固件设置。下一个选项,这是对PCIe的错误注射(PCIe AER error injector support)。
下面的设置提供了操作系统控制PCI的活跃状态和时钟电源管理(PCI Express ASPM control)。通常上,固件会控制ASPM,但是这个特性允许操作系统采取控制。
如前面一样,像内核的许多组件一样,这里提供了ASPM的调试支持(Debug PCI Express ASPM)。
下面,在这个菜单选择"Default ASPM policy"。
在这选项之后,下一个是关于允许设备驱动启消息信号中断(Message Signaled Interrupts (MSI))。通常上最好允许设备给CPU发送中断。
为了在系统日志中加入大量的调试信息,启用"PCI Debugging"。
下一个选项允许PCI核心检测是否有必要启用PCI资源重分配(Enable PCI resource re-allocation detection)。
当在Linux上托管一个虚拟操作系统时,它有时可以用于为虚拟系统保留PCI设备(PCI Stub driver)。在系统虚拟化下,一个操作系统可能在另一个系统的内部或者并行。有时它们会竞争资源。可以为客户机保留设备可以减小竞争和增加性能。
下面的驱动允许超传输设备(hypertransport devices)使用中断(Interrupts on hypertransport devices)。HyperTransport是一种系统/协议总线用于处理器之间的高速通信。
下一个驱动用于PCI虚拟化,它允许虚拟设备间共享它们的物理资源(PCI IOV support)。
PCI页面请求接口(PRI)使在IOMMU(输入/输出内存管理单元)之后的PCI设备能够从页错误中恢复(PCI PRI support)。页错误不是一种错误;它指的是软件尝试访问不在物理内存上的数据的事件。
再次说明,你会在之后的文章中看到更多的需要配置Linux内核特性。
来享受这个Linux内核系列的下一篇文章。我们将继续配置PCI特性,接着是计算机中最重要的特性-网络。
进程地址空间标识符(Process Address Space Identifiers (PASIDs))允许PCI设备同时访问多个IO地址空间(PCI PASID support)。这个特性需要一个支持PASIDs支持的IOMMU。
下面我们可以启用/禁用"PCI IO-APIC hotplug support"。APIC代表高级可编程中断控制器(Advanced Programmable Interrupt Controllers)。可编程中断控制器(PIC)收集所有来自不同源发给一个或者多个CPU流水线的中断。高级PIC与PIC一样,但是它们有更多的特性像高级中断管理和更多的优先级模型。热插拔是一种在系统在运行时加入一件设备的能力并且不需要重启。这个驱动是为了PCI主板能拥有处理输入/输出APIC热插拔的能力。
在这之后,下面的问题询问的是启用"ISA-style DMA support"。在前文中提到过,DMA是直接内存访问,它是一种设备无需借助CPU直接访问内存的能力。ISA代表的是工业标准架构(Industry Standard Architecture),它是一种像PCI的总线标准。这个特性允许在ISA主板上支持DMA。
现在,我们可以移步到"PC Card (PCMCIA/CardBus) support"。PCMCIA代表的是个人计算机存储卡国际协会(Personal Computer Memory Card International Association)。PC卡、PCMCIA卡和Cardbus卡都是卡片形状的笔记本外设。
下一个PCMCIA选项处理"16-bit PCMCIA support"。一些旧的计算机使用16位PCMCIA卡。
为了从用户空间加载卡式信息结构(Card Information Structure (CIS))以使PCMCIA卡正常工作,这个特性应该启用(Load CIS updates from userspace)。
CardBus是16位PCMCIA的更新32位版本。这个驱动提供对这类设备的支持(32-bit CardBus support)。为了使用32位PC卡,需要一个兼容Cardbus的主机桥。
下面的驱动提供对上面提到的CardBus桥支持(CardBus yenta-compatible bridge support)。这是PCMCIA卡插入的硬件端口。
下面三个选项"Special initialization for O2Micro bridges"、"Special initialization for Ricoh bridges"和"Special initialization for TI and EnE bridges"。它们都是不同类型卡桥。
接下来,提供了"Auto-tune EnE bridges for CB cards"的驱动。
"Special initialization for Toshiba ToPIC bridges"可以在下一个选项中启用/关闭。
下一个提供的设备驱动是"Cirrus PD6729 compatible bridge support"。这在一些老的笔记本上需要。
下一个PCMCIA桥驱动是Itel的"i82092 compatible bridge support"。这也在一些老的笔记本上出现。这是另外一种桥驱动。
在这之后,以下的选项询问关于是否启用"Support for PCI Hotplug"。
下一步,ACPI PCI热插拔可以启用(ACPI PCI Hotplug driver)。这个驱动允许拥有ACPI的PCI设备热插拔(这个特性之前已经讨论过)。
对于IBM系统,为了ACPI热插拔下一个驱动应该启用(ACPI PCI Hotplug driver IBM extensions)。这就像上面的特性但特定与IBM设备。
对于带有支持CompactPCI热插拔支持的CompactPCI卡的系统,启用"CompactPCI Hotplug driver"。
下面,我们有一个选项对于另一种CompactPCI系统卡(Ziatech ZT5550 CompactPCI Hotplug)。
使用#ENUM热插拔信号通过标准IO口作为系统注册位的CompactPCI卡需要这个驱动(Generic port I/O CompactPCI Hotplug)。
使用SHPC PCI热插拔控制器的主板需要下一个驱动(SHPC PCI Hotplug driver)。SHPC代表的是标准热插拔控制器(Standard Hot-Plug Controller)。这对于PCI主板是一个通用热插拔系统。
RapidIO互联设备也需要一个特殊的驱动(RapidIO support)。RapidIO芯片和主板快于PCI和PCIe。
"IDT Tsi721 PCI Express SRIO Controller"是一个特殊类型的RapidIO控制器。
下一个选项允许开发者输入在主机完成枚举前系统发现节点应该等待多久时间(以秒计)。这通常选择默认值
下一个特性会允许RapidIO系统接受除了维护信号外其他流量(Enable RapidIO Input/Output Ports)。
为了使用DMA引擎框架从RIO设备上发送或接收RapidIO数据,启用这个驱动(DMA Engine support for RapidIO)。RIO设备是可重配的输入/输出设备。RapidIO使用NREAD和NWRITE请求来在本地和远程内存间传输数据,因此驱动需要允许RapidIO使用DMA访问RIO设备。DMA控制器需要在内存中完成这个特性。
如果允许,RapidIO可以提供调试信息(RapidIO subsystem debug messages)。如前面所说,调试特性可以禁用,除非你或者其他人使用的内核需要调试特性。
下一个驱动提供"IDT Tsi57x SRIO switches support"。这是一组串口RapidIO开关,下面的四个选项是对于不同串口RapisIO开关驱动-"IDT CPS-xx SRIO switches support"、"Tsi568 SRIO switch support"、"IDT CPS Gen.2 SRIO switch support"和"Tsi500 Parallel RapidIO switch support"。
管理这些驱动后,我们可以继续其他的内核选项。下一个选项提供对ELF的支持(Kernel support for ELF binaries)。可执行与可链接格式(Executable and Linkable Format (ELF))支持是一种可执行文件规范。强烈建议启动这个。
为了执行那些需要解释器的脚本和二进制文件,这个特性必须启用(Kernel support for MISC binaries)。这些可执行文件的类型通常称为包装器驱动的二进制格式。例如包括Python2/3、 .NET、Java、DOS执行程序等等。
当这个选项启用时(Enable core dump support),内核可以生成崩溃文件。这是一个调试特性。除非这个内核是用来调试(无论内核本身还是软件),不然这个并不必要。
64位处理器可以执行32位程序如果启用了"IA32 Emulation"。最好启用这个特性除非开发者确定内核永远不会运行32位代码。
老式的a.out二进制文件也被支持(IA32 a.out support)。就像它称呼的那样,"汇编输出"(Assembler Output),这是一种已编译代码的文件格式。
下一个设置允许32位处理器访问完整的64位寄存器文件和宽数据路径(x32 ABI for 64-bit mode)。然而,仍旧使用32位指针。这些32位进程将比同样的为64位编译的进程使用内存更少,因为他们使用32位指针
下面,我们将讲网络支持。
我们第一个网络设定是启用一般的网络(Networking Support)。很少有开发者会禁用这个特性。如果他们这么做了,内核会变得又小又快,但是它将无法使用Wifi、蓝牙、以太网或者任何由网络设备或协议处理的连接。一些在独立系统上程序也需要这个特性,即使硬件上不存在网络设备。举例来说,X11依赖于网络特性。如果你能提供一个替代方案在屏幕上显示图形,你才能在内核中禁用网络特性。
"Packet socket"允许在没有中介物的情况下,进程与网络设备间进行通信。这个增强了性能。
ss工具需要启用这个特性用来数据包监控(Packet: sockets monitoring interface)。包监控意味着监视相关本地设备的网络流量。
"Unix domain sockets" (Unix域套接字)是用来建立和访问网络连接。X窗口系统需要这个特性;这是一个极好的例子来说明为什么即使系统中不会使用网络但是仍然在内核中启用网络特性。Unix域套接字是运行在同一台机器上的进程间的网络协议。
上面的Unix套接字可以被ss工具监控,但是下面一个特性必须先启用(UNIX: socket monitoring interface)。
转换(Transformation (XFRM))用户配置接口被许多Linux原生工具用到,所以这个特性强烈建议启用(Transformation user configuration)。这个会启用Ipsec-Internet Protocol SECurity(互联网协议安全)。Ipsec控制着验证并且/或者加密IP数据包。
下一个特性允许开发者给予网络数据包第二个政策(称作sub-policy)(Transformation sub policy support)。
IPsec安全联合定位器可以当这个特性启用时(Transformation migrate database)动态更新。使用移动IPv6的设备需要这个特性。当计算机与路由器或者任何形式的网络设备设置了一个网络连接,安全协议会确保两者不会意外地连接到网络上的其他设备上。IP数据包被设定发送到一个特定的设备上。然而,移动设备会使用不同的网络,比如说提供了4G信号,也需要能够使用相同的连接到新的网络点上。即使可能是相同的4G供应商,不同的设备会提供一个4G连接到它的物理位置。当设备处在新的区域时,它仍会使用相同的IP地址。
下一个特性是显示在包处理中的传输错误统计(Transformation statistics)。这对开发者有用。如果不需要,可以禁用掉它。
"PF_KEY sockets"与KAME套接字兼容且它在使用从KAME移植来的IPsec工具时有用。KAME是IPv4 IPsec、IPv6 IPsec和IPv6的免费协议栈。
这是另外一个需要的移动IPv6特性,它增加了到PF_KEYv2套接字的PF_KEY MIGRATE消息(PF_KEY MIGRATE)。
下面的是最重要的并且是在网络中最著名的需要启用的特性-"TCP/IP networking"。大多数网络(包括因特网)依赖于这个协议。甚至X窗口系统也使用TCP/IP。这个特性甚至允许用户ping它们自己(命令:ping 127.0.0.1)。要使用因特网或者X11,这个必须启用。
为了寻找网络中数个计算机,"IP: multicasting"必须启用。多播是一种给多台计算机但不是全部计算机发送消息的能力。广播会给网络中的所有计算机发送信号。
如果这是一个路由器Linux系统的内核,那就启用这个选项(IP: advanced router)。
如果下面的特性启用了,那么IP地址会在启动时自动配置(IP: kernel level autoconfiguration)。当用户希望不用配置就能连接到一个网络时是很有用的。
启用了DHCP协议支持,那么Linux系统可以通过网络像NFS挂载它的根文件系统并且使用DHCP发现IP地址(IP: DHCP support)。这允许Linux系统通过网络拥有它的远程根文件系统而不必用户在每次系统启动时手动管理进程。
下面的选项和上面的类似除了使用的是BOOTP而不是DHCP(IP: BOOTP support。BOOTP是自举协议;这个协议使用UDP而不是TCP并且只能使用IPv4网络
RARP是一个被BOOTP和DHCP替代了的旧协议,但是它仍可以加到内核中(IP: RARP support)。
网络协议可以在另一个概念中使用,称作"隧道"。这个特性可以用在Linux内核中(IP: tunneling)。安全shell协议(The secure shell protocol (SSH))就是隧道协议的一个例子。SSH需要这个特性。
下面的驱动可以多路复用通用路由封装包(GRE (Generic Routing Encapsulation))(IP: GRE demultiplexer)。多路复用是一个使单个信号进入不同部分的过程(这不会复制消息,只是分解它)。GRE是一种隧道协议。
下面的特性允许GRE通道在IP连接中形成(IP: GRE tunnels over IP)。这允许GRE隧道在IP网络中形成。
当启用这个特性(IP: broadcast GRE over IP),广播可以通过IP使用GRE。
在Linux系统的路由器内,为了让IP包发往多个地址,需要启用这个(IP: multicast routing)。
在本篇中,我们将继续配置网络特性。记住,网络是计算机最重要的特性,这篇文章和这之后的网络相关文章都要重点了解。
在我们开启这系列之前,我先要澄清一些事情。配置进程不会编辑你当前系统的内核。这个进程配置的是你编译(或者交叉编译)新内核前的源代码。一旦我完成了配置过程,那么我会讨论读者建议的话题。同样,作为提醒,每个段落中在引号或者括号中的第一句或者第二句(很少)的文本是配置工具中设置的名字。
首先,我们可以启用两个不同的稀疏型独立协议组播路由协议("IP: PIM-SM version 1 support" 和 "IP: PIM-SM version 2 support"),组播有点像广播,但是广播会给所有计算机发送信号而组播只会给选定的组或者计算机发送信号。所有PIM协议都是工作在IP的组播路由协议。
注意:当计算机与另外一台计算机或者服务器通信时,这叫做单播 - 只是以防你们想知道。
下一个要配置的网络特性是"ARP daemon support"。这让内核有一张IP地址表以及它们相应的在内部缓存中的硬件地址。ARP代表的是地址解析协议(Address-Resolution-Protocol)。
为了额外的安全,"TCP syncookie support"应该要启用。这保护计算机免于受到SYN洪水攻击。黑客或者恶意软件可能会发送SYN信息给一台服务器来消耗它的资源,以便让真实的访客无法使用服务器提供的服务。SYN消息会打开一个计算机和服务器之间的连接。Syncookie会阻断不正当的SYN消息。那么,真实的用户可以仍旧访问访问网站,而黑客则没办法浪费你的带宽。服务器应该启用这个特性。
下面的特性是用于 "Virtual (secure) IP: tunneling"。隧道是一个网络协议到另外一个网络协议的封装。当在使用虚拟私人网络(VPN)时需要使用安全隧道。
接下来,启用"AH transformation"增加对IPSec验证头的支持。这是一种管理数据验证的安全措施。
在这之后,启用"ESP transformation"增加对IPSec封装安全协议的支持。这是加密与可选择的数据验证的安全措施。
如果启用了这个特性(IP: IPComp transformation),Linux内核会支持IP负载压缩协议。这是一种无损压缩系统。无损指的是数据仍会保持完整,在解压缩后,数据在压缩前后没有变化。压缩在加密前先执行。由于更少的数据传输,所以这个压缩协议可以加速网络。
下面三个设置用于处理不同的IPsec特性("IP: IPsec transport mode"、"IP: IPsec tunnel mode"和"IP: IPsec BEET mode")。IPSec代表的是因特网安全协议(Internet Protocol SECurity).两台计算机之间并且/或者服务器间的传输模式是默认的IPSec模式。传输模式使用AH或者ESP头并且只加密IP头。在隧道模式下,IP头和负载会被加密。隧道模式通常用于连接网关到服务器/服务器或者服务器到服务器。BEET模式(Bound End-to-End Tunnel)不会在IP地址改变时重连。BEET模式下的连接会仍然存在。BEET模式比其他几种模式使用更少的字节。
下面,内核可以支持收到大量IPv4/TCP包时减轻栈负担(Large Receive Offload (ipv4/tcp))。网卡(NIC)处理TCP/IP栈。这个特性在内核中增加了处理大型栈的代码。
INET套接字可以启用(INET: socket monitoring interface)。INET套接字用于因特网。这个特性(当启用时)会监视来自或者发往因特网的连接与流量。
这里有另外一个套接字监视接口(UDP: socket monitoring interface)。这个用于用户数据报协议(User Datagram Protocol (UDP))。再说一下,这个特性监视UDP的套接字。
以下的设定会启用不同的TCP拥塞控制(TCP: advanced congestion control)。如果网络变得太忙或者带宽已满,那么许多计算机必须等待一些带宽或者它们的数据流会变慢。如果流量被合理管理,这回有助于网络性能提升。
TCP连接可以被MD5保护(TCP: MD5 Signature Option support)。这用于保护核心路由器之间的边界网关协议(Border Gateway Protocol (BGP))连接。核心路由器是网络中主要的路由器;这些路由器有时指的是因特网/网络的骨干。BGP是一种路由决策协议。
下一个设定允许你启用/禁用"The IPv6 protocol"。当你启用它,IPv4仍旧可以很好地工作。
下面的特性是一个特殊的隐私特性(IPv6: Privacy Extensions (RFC 3041) support)。这使得系统在网络接口中生成并使用不同的随即地址。
注意:计算机中没有数据是真正随机的。计算机中随机数和随机字串通常称为伪随机。
在多路由的网络中,这个特性允许系统能够更有效地计算出该使用哪一个(IPv6: Router Preference (RFC 4191))。
在这之后,一个用于处理路由信息的实验性特性可以启用/禁用(IPv6: Route Information (RFC 4191))。记住,在编译一个稳定内核时,除非你确实需要这个问题中特性,才去安装实验性的功能。
有时,当系统自动配置它的IPv6地址时,它可能会得到一个网络中已被使用的IPv6地址。这是一个允许重复地址检测(Duplicate Address Detection (DAD)的实验性特性(IPv6: Enable RFC 4429 Optimistic DAD)。
IPv6可以有不同的IPsecc特性支持("IPv6: AH transformation" 和 "IPv6: ESP transformation")。
IPv6同样可以使用先前讨论过的IP负载压缩协议(IP Payload Compression Protocol)(IPv6: IPComp transformation)。
这里甚至有IPv6移动支持(IPv6: Mobility)。这允许使用IPv6的移动设备在保留同样地址的情况下使用其他的网络。
再说一次,这里同样有一些针对IPv6的IPsec特性("IPv6: IPsec transport mode"、"IPv6: IPsec tunnel mode"、"IPv6: IPsec BEET mode")。
当启用此项后,IPv6可以支持MIPv6路由优化(IPv6: MIPv6 route optimization mode)。这样就可以确保最短和最佳网络路径了。如果消息在更少的路由和网络设备间发送,那么下载和上传速度就可以更快。
如果一个管理员需要连接到两个IPv6网络,但是只能通过IPv4来连接,这时内核使这个变得可能(IPv6: IPv6-in-IPv4 tunnel (SIT driver)。这通过隧道使IPv6报文穿越IPv4网络。
这个隧道特性是用于IPv6-in-IPv6 和 IPv4 tunneled in IPv6 (IPv6: IP-in-IPv6 tunnel (RFC2473))
另外一个隧道特性是(IPv6: GRE tunnel)。他只允许GRE隧道。(GRE:通用路由封装(Generic Routing Encapsulation))
允许支持多重路由表(IPv6: Multiple Routing Tables)。路由表是一张网络位置列表和数据要去目的地的路径。
允许根据源地址或前缀进行路由如果启用了(IPv6: source address based routing)。
"IPv6 Multicast routing"(IPv6组播路由)仍然是实验性质。IPv4和IPv6处理组播的方式不同。
典型的组播路由根据目标地址和源地址来处理组播包(IPv6: multicast policy routing)。启用这个选项会将接口和包的标记(mark)包含到决策中。
下面可以启用IPv6的PIM-SMv2 组播路由协议(IPv6: PIM-SM version 2 support)。这与先前提到的IPv4 PIM相同。因为IPv4和IPv6不同,所以PIM可以被v4/v6同时/分别激活
网络包标签协议(Network packet labeling protocols)(就像CIPSO和RIPSO)可以启用(NetLabel subsystem support)。这些标签包含了安全信息和权限。
网络包可以通过启用安全标记(Security Marking)变得更安全。
这个网络特性增加了一些开销(Time-stamping in PHY devices)。物理层(PHY)设备可以给网络包打上时间戳。PHY代表的是"PHYsical layer"。这些设备管理收到和发送的消息。
可以启用netfilter(Network packet filtering framework)。Netfilters过滤并修改过往的网络包。包过滤器是一种防火墙。如果包满足了一定的条件,包不会被允许通过。
数据报拥塞控制协议(Datagram Congestion Control Protocol)可以启用(The DCCP Protocol)。DCCP允许双向单播连接。DCCP有助于流媒体、网络电话和在线游戏。
下一步,流控制传输协议(Stream Control Transmission Protocol)可以启用(The SCTP Protocol)。SCTP工作在IP顶层并且是一个稳定可靠的协议。
下面的协议是可靠数据报套接字(Reliable Datagram Sockets)协议(The RDS Protocol)。
RDS可以使用Infiniband和iWARP作为一种支持RDMA的传输方式(RDS over Infiniband and iWARP),Infiniband和iWARP都是协议。RDMA代表的是远程直接内存访问(remote direct memory access)。RDMA用于一台远程计算机访问另一台计算机的内存而无需本机计算机操作系统的辅助。这就像直接内存访问(DMA),但是这里远程代替了本地计算机。
RDS同样可以使用TCP传输(RDS over TCP)
接下来,"RDS debugging messages"应该禁用。
下面的网络协议用于集群(The TIPC Protocol)。集群就是一组计算机作为一台计算机。它们需要有一个方式去通信,所以他们使用透明内部进程间通信协议(Transparent Inter Process Communication (TIPC))。
这个高速协议使用固定大小的数据包(Asynchronous Transfer Mode (ATM))。
使用ATM的IP可以与连接到一个ATM网络的IP的系统通信(Classical IP over ATM)。
下一个特性禁用"ICMP host unreachable"(ICMP主机不可达)错误信息(Do NOT send ICMP if no neighbor)。这防止了由于重新校验而移除ATMARP表被移除的问题。ATMARP表管理地址解析。ICMP代表的是因特网控制消息协议(Internet Control Message Protocol)并被常用于通过网络发送错误消息。
LAN仿真(LANE)仿真了ATM网络上的LAN服务(LAN Emulation (LANE) support)。一台LANE计算机可以作为桥接Ethernet和ELAN的代理。
"Multi-Protocol Over ATM (MPOA) support"允许ATM设备通过子网边界发送连接。
在这个特性下,至少在kernel看来ATM PVCs的行为就像Ethernet(RFC1483/2684 Bridged protocols)。PVC代表的是永久虚电路(permanent virtual circuit)。虚拟连接是一种基于包的连接,它伴随着主/原始协议使用其他更高层的协议。
"Layer Two Tunneling Protocol (L2TP)"(二层隧道协议)是隧道对应用透明。虚拟私有网络(Virtual Private Networks (VPNs))使用L2TP
要想使用基于Linux的以太网桥,启用这个桥特性(802.1d Ethernet Bridging)。在网络中,一个桥同时连接两个或者更多的连接。以太网桥是使用以太网端口的硬件桥。
"IGMP/MLD snooping"(IGMP/MLD 探听)是一种以太网桥能够基于IGMP/MLD负载选择性地转发组播信号的能力。禁用这个特性能够明显减少内核的大小。IGMP代表的是因特网组管理协议(Internet Group Management Protocol),这是一种被用于设置组播组的协议。MLD代表多播监听发现(Multicast Listener Discovery)。
下一个过滤特性允许以太网桥选择性地管理在每个数据包中的基于VLAN的信息的流量。 ?用这个特性可以减小内核的大小。
通过启用这个特性(802.1Q VLAN Support),VLAN接口可以在以太网上创建。下面"GVRP (GARP VLAN Registration Protocol)"支持GVPR协议被用于在网络设备上注册某些vlan。
在这之后,"MVRP (Multiple VLAN Registration Protocol) support"(多重VLAN注册协议)可以启用。MVRP是GVRP更新的替代品。
"DECnet Support"是一种Digital公司发明的网络协议。这是一中既安全又稳定的协议。
"DECnet router support"允许用户制作基于Linux的支持DRCnet的路由。
注意:Linux可以用于服务器、工作站、路由器、集群、防火墙并支持其他许多用途。
下面的特性用于支持逻辑链路层2(Logical Link Layer type 2)(ANSI/IEEE 802.2 LLC type 2 Support)。这层允许在同一个网络设备上使用多个协议。强烈建议在网络很重要的环境中启用这个特性。最好所有内核都支持这个特性。
在下一篇文章中,我们将讨论更多的关于可以配置的网络设定。
Novell的网络协议IPX通常用于Windows系统和NetWare服务器(The IPX protocol)。IPX代表网间分组交换(Internetwork Packet Exchange)。这是一个网络层协议通常与传输层的SPX协议同时使用。
为了使NetWare服务器在服务的网络中有相同的IPX地址,启用下一个特性(IPX: Full internal IPX network)。不然,每个网络都会看到服务器一个不同的IPX地址。
注意:IPX协议使用IPX寻址,而不是IP寻址。IP地址不是计算机网络中唯一的网络地址。
对于在Apple网络中的Linux系统,需要启用Appletalk(Appletalk protocol support)。苹果计算机和苹果打印机通常使用Appletalk在网络间通信。Appletalk不需要一台中心路由器/服务器并且网络系统是即插即用的。
在Appletalk网络中Linux系统需要使用IP需要"Appletalk interfaces support"(AppleTalk接口支持)。
下一个特性允许用户在Appletalk中使用IP隧道(Appletalk-IP driver support)。
接下来,这个特性允许IP包被封装成Apppletalk帧(IP to Appletalk-IP Encapsulation support)。在网络中,帧是一种标记包的开始和结束的特殊序列位。这个特性会将IP包放在Appletalk包内部。
这个特性允许为先前的特性解包(Appletalk-IP to IP Decapsulation support)。解包器会将IP包从Appletalk包中拿出。
这是另外一个协议层称为"X.25" (CCITT X.25 Packet Layer)。这个协议层通常用于非常大的网络,就像国家公网。许多银行使用这个在他们的扩展网络系统里。X25(拼成"X25"或"X.25")网络拥有将进入数据包打包的包分组交换机。X25正在被更简单的IP协议代替。X25是一个不如TCP/IP有效率的旧协议,但是一些公司发现它在大型、复杂的网络中很有用。
LAPB是用于X.25的数据链路层(LAPB Data Link Driver)。如果上面的启用了,那么这也应该同时启用。LAPB代表的是"Link Access Procedure Balanced"(链路访问过程平衡)。LAPB同样也用于以太网和X.21网卡中(这里没有打错)。X.21是用于物理层(硬件),X.25用于网络层。LPAB会检查错误并确保包被放回正确的序列中。
Nokia调制解调器使用的电话网络协议通常称作"PhoNet"(Phonet protocols family)。Linux计算机远程控制Nokia电话机需要这个特性。
下一个网络通常是用于不同自动设备间的小型无线连接(IEEE Std 802.15.4 Low-Rate Wireless Personal Area Networks support)。802.15.4是一种需要很少电量的简单低数据率协议。这个无线协议最大可扩展到10米。这在通过无线网络连接机器人传感器时是很有用的。任何不该有线缆的机械可能都会从这个代替了绳子的本地无线网络中获益。
如果启用了上面的特性,那么最好明智地启用这个IPv6 压缩特性(6lowpan support over IEEE 802.15.4)。
支持物理层 IEEE 802.15.4协议的SoftMac设备可以启用这个特性(Generic IEEE 802.15.4 Soft Networking Stack (mac802154))。
当有许多包需要传输时,内核必须决定先发送哪一个(它们不能一次全部发送),所以这个特性帮助内核区分包的优先级(QoS and/or fair queuing)。如果不启用这个,那么内核会使用"first come, first serve approach"("谁先到,谁先服务")。这可能意味着紧急的网络消息需要等待才能轮到它们传输。
在有数据中心服务器的网络中,这个特性强烈建议启用(Data Center Bridging support)。这个特性增强了以太网对数据中心网络的连接。
DNS查询可以在下一个选项中启用(DNS Resolver support)。大多数存储DNS缓存的系统允许计算机无需DNS服务器的辅助下执行DNS查询。
接下来是另一个用于多跳专用网状网络(B.A.T.M.A.N. Advanced Meshing Protocol)。"B.A.T.M.A.N."代表"better approach to mobile ad-hoc networking"(更好接入移动专用网络)。这个工作与有线和无线网络。专用网络没有中心像路由器这类中心设置。每台网络上的设备就像个一台路由器。网状网络是一个简单的概念。每个节点必须路由发送给它的数据。在这个网状网络中,每台计算机连接到全部或几乎全部其他网络设备。当这样的网络画在纸上成为一张地图时,这个网络看上去就像一张网。
当许多网状节点连接到相同的LAN和网时,一些网络信号可能会回环(Bridge Loop Avoidance)(避免桥回环)。这个特性可以避免此类的回环。这些回环可能永远不会结束或者降低性能。避免这样的回环被称为"Bridge Loop Avoidance (BLA)"。
分布式ARP表(Distributed ARP Tables (DAT))被用于增强ARP在稀疏无线网状网络的可靠性(Distributed ARP Table)。
BATMAN协议有些开发者需要用到的调式特性(B.A.T.M.A.N. Debugging)。对于任何调试特性,通常最好禁用它来节省空间以及得到一个更好优化后的内核。
虚拟化环境可以从"Open vSwitch"中得益。这是一个多层以太网交换机。Open vSwitch支持大量的协议。
虚拟机、hypervisor、主机之间的网络连接需要"virtual socket protocol"。这个类似于TCP/IP.这些套接字就像其他网络套接字,但是它们针对虚拟机。这允许客户机系统拥有一个与主机的网络连接。
这是一个可以管理网络优先级的cgroup子系统(Network priority cgroup)。这允许控制组(cgroup)根据发送应用设置网络流量优先级。
BPF过滤器由解释器处理,但是内核可以执行原生BPF过滤通过这个(enable BPF Just In Time compiler)。BPF代表的是"Berkeley Packet Filter"(伯克利报过滤器)。这允许计算机系统支持原生链路层包。
下面,我们有两个网络测试工具。第一个是"Packet Generator"(包生成器),这用于测试网络时注射数据包(制造空包)。第二个,允许设置一个警报系统,当数据包丢失时警告用户/系统(Network packet drop alerting service)。
Linux内核可以用于无线电系统或者远程控制它们。"Amateur Radio AX.25 Level 2 protocol"用于计算机通过无线电通信。这个无线电协议可以在其他许多的协议中支持TCP/IP。
为了放置在AX.25网络中冲突,启用DAMA(AX.25 DAMA Slave support)。至今为止,Linux还不能作为DAMA的服务器,但是可以作为DAMA的客户端。DAMA代表"Demand Assigned Multiple Access"(按需分配多址访问)。DAMA分配网络流量到特定的信道中去。
NET/ROM是AX.25的路由层。(Amateur Radio NET/ROM protocol)。
NET/ROM的一个替代是"Packet Layer Protocol (PLP)"(包层协议),它可以运行在AX.25的顶端(Amateur Radio X.25 PLP (Rose))。
控制器局域网络(Controller Area Network (CAN))总线需要这个驱动(CAN bus subsystem support)。CAN总线是一种用于不同目的的串行协议。
使用这个特性(Raw CAN Protocol (raw access with CAN-ID filtering)),CAN总线可以通过BSD套接字API访问
内核中有用于CAN协议的广播管理(Broadcast Manager CAN Protocol (with content filtering))。这个管理提供了很多控制,包括内容过滤。
为了让Linux盒子成为一个CAN路由器和/或者网关,需要这个特性(CAN Gateway/Router (with netlink configuration))。
注意:网关是两个或者更多网络的接口设备,它提供不同的协议。一个简单的定义可以是"网关是一个协议转换器。"
注意:路由器转发网络流量和连接使用相同协议网络。
如果启用了(一些选项),Linux内核可以支持很多CAN设备(主要是控制器)和接口。所有的CAN驱动都是对于这些设备的不同品牌和型号。在配置工具中,它们有以下这些标题。
Virtual Local CAN Interface (vcan)
Serial / USB serial CAN Adaptors (slcan)
Platform CAN drivers with Netlink support
Enable LED triggers for Netlink based drivers
Microchip MCP251x SPI CAN controllers
Janz VMOD-ICAN3 Intelligent CAN controller
Intel EG20T PCH CAN controller
Philips/NXP SJA1000 devices
Bosch CCAN/DCAN devices
Bosch CC770 and Intel AN82527 devices
CAN USB interfaces
Softing Gmbh CAN generic support
Softing Gmbh CAN pcmcia cards
像Linux中的其他许多特性,CAN设备同样可以启用调试能力(CAN devices debugging messages)。再说一次,记住你内核的目的,你需要调试还是需要性能?
Linux内核同样支持红外线信号协议IrDA (infrared) subsystem support)。IrDa代表的是 "Infrared Data Associations"(红外数据协会);这是红外信号的标准。
许多人如今想要蓝牙特性(Bluetooth subsystem support)。
RxRPC会话套接字可以启用(RxRPC session sockets)。这些套接字使用RxRPC协议运载网络连接。RxRPC运行于UDP的顶部。
如果启用的话,Linux内核可以支持"RxRPC dynamic debugging"(RxRPC 动态调试)。
RxRPC拥有kerberos 4和AFS kaserver安全特性可以启用(RxRPC Kerberos security)。Kerberos是一种每个网络设备在传输任何数据前都被需要证明彼此的身份的验证协议。
对于电脑的无线网络设备像Wifi,配置工具需要启用无线局域网(802.11)设备(cfg80211 - wireless configuration API)。cfg80211代表"Configuration 802.11"(配置 802.11)。802.11是一种无线规范。
"nl80211 testmode command"是用于校准并且/或验证的实用工具,它无线设备芯片上执行这些任务。
下一个设置允许用户"enable developer warnings"(启用开发者警告)对于cfg80211设备。
下面,"cfg80211 regulatory debugging"(cfg80211调控调试)可以启用。
下面的设定是"cfg80211 certification onus"(cfg80211证书义务)。
应该为cfg80211兼容设备启用省电特性(enable powersave by default)。
cfg80211支持debugfs入口(cfg80211 DebugFS entries)。
无线设备有它们遵守的调整规则;这些被存储在数据库中(use statically compiled regulatory rules database)(使用静态编译的调整规则数据库)
一些使用基于cfg80211的驱动扩展可能需要使用一个老的用户空间。这个特性允许这个行为(cfg80211 wireless extensions compatibility)(cfg80211 无线扩展兼容)。
lib80211可以提供调试特性(lib80211 debugging messages)。
独立于硬件的IEEE 802.11标准可以启用(Generic IEEE 802.11 Networking Stack (mac80211))。mac80211是一种用于编写softMAC无线设备驱动的框架。SoftMac允许很好地控制和配置设备。
下一个特性允许mac80211使用PID控制器管理TX(发送)速率(PID controller based rate control algorithm)(PID控制器基于速率控制算法)。TX单位是BFS(Bits per minute)(位/秒)。特别地,这个特性是用于控制数据流速率的算法。
另外一个相同特性的算法叫做"Minstrel"。这是一个比TX速 管理算法更精确和有效的算法。
Minstrel同样支持802.11n(Minstrel 802.11n support)。
由于有两种TX速率控制算法,但只能使用一种。所哟必须设备一个默认的(Default rate control algorithm (Minstrel))。通常地,最好选择Minstrel作为默认。
802.11s网状网络草案可以在内核中启用(Enable mac80211 mesh networking (pre-802.11s) support)。802.11s草案是网状网络的无线标准。
对于支持这个特性的设备,对于不同包流量时间的LED除法器特性可以启用(Enable LED triggers)。在我的以太网设备商上,当端口是活跃时LED灯会点亮。这些驱动可以是这些LED在包流量时间下工作。
mac80211同样支持debugfs特性(Export mac80211 internals in DebugFS)。
这是一个独立于典型日志系统收集mac80211调试信息的特性(Trace all mac80211 debug messages)。
这是另外一组mac80211调试特性,但是这些使用的是典型日志系统(Select mac80211 debugging features --->)。在这个菜单,选择你需要的调试特性。
在下一篇文章中,我们还有更多的需要配置。
使用WiMAX协议的无线宽频设备可以启用这个(WiMAX Wireless Broadband support)。这个类型的无线连接通常需由服务供应商提供的连接服务才能工作(这与3G/4G的概念相同)。WiMAX代表"Worldwide Interoperability for Microwave Access"(微波存取全球互通)。WiMAX的目的是代替DSL。宽频指的是宽的带宽和大量信号的传输。
射频开关被用于许多Wifi和蓝牙卡中(RF switch subsystem support)。"RF"代表"Radio Frequency"。RF开关路由高频信号。
RF开关输入支持同样也在内核中支持(RF switch input support)。
内核可以控制并请求无线传输(Generic rfkill regulator driver)。启用这个生成一个设备文件(/dev/rfkill)。这个设备文件作为无线设备的接口。
Linux内核支持9P2000协议(Plan 9 Resource Sharing Support (9P2000))。这个网络协议有时称作Styx。Plan 9的窗口系统(Rio)的Styx和Linux的X11都使用Unix网络套接字。Linux系统可能使用Styx在Styx网络中。Plan 9和Linux可以在一个网络中使用Styx
"9P Virtio Transport"(9P 虚拟io传输)系统提供了在虚拟系统上客户机和主机分区间的传输。
内核同样支持RDMA传输(9P RDMA Transport (Experimental))。RDMA代表的是"Remote Direct Memory Access"(远程内存直接访问)。这个Plan9上访问远程计算机内存的协议。
9P系统与其他内核组件一样有调试特性(Debug information)。
"CAIF support"支持同样可以在内核中启用。CAIF代表" Communication CPU to Application CPU Interface"(通信CPU到应用CPU接口)。这是一个使用数据包的多路复用(MUX)协议并被用于ST-Ericsson(意法爱立信)调制解调器中。ST-Ericsson是开发这个协议的公司(是的,MeeGo和Android是Linux系统,并且我正在讨论Google的Andorid)。MUX协议就是多路复用(multiplexing)协议。多路复用在前面的文章中已经提到过。
下面,cephlib可以加入内核,它可以用于rados块设备(rbd)h和Ceph文件系统(Ceph核心库)(译注:Ceph是一种分布式文件系统)。cephlib是是Ceph的完整核心库。Ceph是存储平台。CephFs(Ceph文件系统)是运行在另外一个文件系统的顶部。通常,CephFs运行在EXT2、ZFS、XFS或者BTRFS上面。Rados设备是使用CephFs的块存储单元。
ceph的调试特性会损害内核性能,所以只在需要的时候启用(Include file:line in ceph debug output)。 当启用这个选项(Use in-kernel support for DNS lookup),CONFIGDNSRESOLVER设施会执行DNS查询。
近场通信(Near Field Communication (NFC))设备在Linux内核中也被支持(NFC subsystem support)。
如果上面的特性被启用,那么NFC控制器接口(NFC Controller Interface (NCI))也应该启用(NCI protocol support)。这允许主机和NFC控制器相互通信。
NFC要处理HCI帧需要启用下面一个特性(NFC HCI implementation)。
一些HCI驱动需要一个SHDLC链路层(SHDLC link layer)(SHDLC link layer for HCI based NFC drivers)。SHDLC是检测完整性和管理HCI帧顺序的协议。
如果NFC特性启用了,那么通常也启用"NFC LLCP support"(就像上面那样)。
接下来有一些为特别的NFC设备的驱动。第一个是"NXP PN533 USB driver"。
下一个NFC驱动支持TI的BT/FM/GPS/NFC设备(Texas Instruments NFC WiLink driver)。
下面的是"NXP PN544 NFC driver"。
对于Inside Secure(译注:法国一家非接触半导体芯片厂商)生产的microread NFC芯片驱动同样在内核中支持(Inside Secure microread NFC driver)。
现在,我们将继续配置与网络无关的驱动。首先我们可以选择uevent帮助程序的路径(path to uevent helper)。如今许多计算机不在需要这个特性因为一个uevent帮助程序会在每次执行时fork一个进程处理。这回很快地消耗资源。
在启动时,内核会创建一个tmpfs/ramfs 文件系统(Maintain a devtmpfs filesystem to mount at /dev)。这个提供了完整的/dev目录系统。在这两个文件系统中(tmpfs和ramfs),ramfs两者中最简单。"tmpfs"代表"temporary filesystem"(临时文件系统),而"ramfs"代表"ram filesystem"(内存文件系统)。
下一个设置是devtmpfs文件系统的代码,它同样挂载在/dev下(Automount devtmpfs at /dev, after the kernel mounted the rootfs)。
下面的特性允许模块加载到用户空间(Userspace firmware loading support)。
为了"Include in-kernel firmware blobs in kernel binary"(译注:将固件编译进内核)(这会增加专有固件到内核中),就启用这个特性。
一些二进制专有驱动需要在启动时使用。这个特性允许这类软件这么做(External firmware blobs to build into the kernel binary)。一些计算机有些引导设备需要只包含专有二进制文件的特殊固件。这个特性不启用,系统将无法引导。
启用"Fallback user-helper invocation for firmware loading",允许user-helper(用户助手) (udev)作为内核加载固件驱动失败的后备手段加载固件。udev可以加载驻留在非标准路径的固件。
管理驱动的不跟内核如果被允许就可以生成调试信息(Driver Core verbose debug messages)。
下一步,如果启用这个特性(Managed device resources verbose debug messages),devres.log文件就可以使用。这是一个用于设备资源的调试系统。
下面一个特性会通过netlink套接字生成一条用户空间和内核空间的连接(Connector - unified userspace <-> kernelspace linker)。这个套接字使用netlink协议。这是另外一个Linux系统即使在没有物理网络情况下仍需要网络特性的例子。
用户空间可以通过套接字得到进城时间的通知(Report process events to userspace)。一些报告事件包含了ID改变、fork、和退出状态。一些先前启用的内核特性可能需要这个。最好按配置工具建议的那样设置。
使用固态硬盘的系统需要MTD的支持(Memory Technology Device (MTD) support)。MTD设备是固态存储设备。典型的存储设备与固态硬盘(SSD)不同。用于磁盘单元的标准常规不适用于SSD(读、写、擦除)。
大多数会桌面电脑带有并口(一个有25个洞的连接器),所以他们需要这个特性(Parallel port support)。并口在其他许多鲜为人知的应用中通常用于打印机和ZIP驱动器。并口有25针。
对IBM兼容计算机启用这个特性(PC-style hardware)。它们是不同类型的计算机。除了IBM计算机(通常运行Windows),还有苹果计算机。Linxu可以运行在几乎所有类型的计算机上。
Linux同样支持Multi-IO PCI卡(Multi-IO cards (parallel and serial))。Multi-IO PCI卡同时拥有并口和串口。串口每次发送或接收1位数据。
下一个特性允许内核"Use FIFO/DMA if available"。这用于特定的并口卡来加速打印。FIFO代表"First In, First Out"(先入先出)。DMA是先前提过的直接内存访问(Direct Memory Access)。
下面一个特性用于探测Super-IO卡(SuperIO chipset support)。这些探针会发信中断号、DMA通道和其他类型设备的地址/数量。Super-IO是一种集成IO控制器类型。
PCMCIA的并口支持可以启用(Support for PCMCIA management for PC-style ports)。
注意:对于许多特性来说,你最好按照配置工具的建议除非你有特别的理由不这么做。通常地,如果你是交叉编译或者编译一个通用内核,那么你应该熟悉你想要支持的并做出相应的选择。
在AX88796网络控制器的并口需要这个支持(AX88796 Parallel Port)。
"IEEE 1284 transfer modes"在并口上支持增强型并口(Enhanced Parallel Port (EPP))和增强功能口(Enhanced Capability Port (ECP))并支持打印机状态回读。状态回读是检索打印机的状态。
即插即用("Plug and Play support" (PnP))应该启用。这允许用户在系统开机状态下插入设备并能马上使用它们。没有这个特性,用户不能使用USB设备、打印机或者其他没有执行特殊任务的设备。系统会自动管理复位(译注:原文是 "The system will manage the rest automatically")。
下面,用户可以启用块设备(Block devices)。这是一个应该启用的特性,因为块设备很常见。
软驱也是可以启用的块设备(Normal floppy disk support)。
连接到并口的IDE设备也同样支持(Parallel port IDE device support)。一些外部CD-ROM设备也能通过并口连接。
外部IDE存储设备单元同样可以连接到并口(Parallel port IDE disks)。
连接到并口的ATA包接口(ATA Packet Interface (ATAPI)) CD-ROM需要这个驱动(Parallel port ATAPI CD-ROMs)。ATAPI是用于并行ATA(PATA)设备的ATA协议扩展。
还有一个ATAPI磁盘设备可以插到并口中(Parallel port ATAPI disks)。这个驱动会除了支持CD-ROM外还支持其他类型的磁盘。
内核同样支持通过并口连接ATAPI磁带设备(Parallel port ATAPI tapes)。
还有许多其他的ATAPI设备可以连接到并口中。结果就是,一个通用驱动被用于管理前面提到过的驱动不支持的设备(Parallel port generic ATAPI devices)。
连接到并口上的IDE设备需要一个特殊的协议用于通信。有很多这样的协议,其中一个是"ATEN EH-100 protocol"。
一个可选的用于并行IDE设备的协议是"MicroSolutions backpack (Series 5) protocol"。
这里仍有另外一个并口IDE设备协议(DataStor Commuter protocol)和另一个(DataStor EP-2000 protocol)还有(FIT TD-2000 protocol)。
再提一次,这里有另外一个协议,但是这个强烈建议用在更新的插在并口上的CD-ROM和PD/CD设备(FIT TD-3000 protocol)。
下面的协议主要用于SyQuest、Avatar、Imation和HP生产的并口设备(Shuttle EPAT/EPEZ protocol)。
Imation SuperDisks需要Shuttle EP1284芯片的支持(Support c7/c8 chips)。
一些其他的并行IDE协议可以启用,包括:
Shuttle EPIA protocol
Freecom IQ ASIC-2 protocol - (用于Maxell Superdisks)
FreeCom power protocol
KingByte KBIC-951A/971A protocols
KT PHd protocol - (用于2.5英寸外置并口硬盘)
OnSpec 90c20 protocol
OnSpec 90c26 protocol
注意:这些协议以及支持的插入并口的设备意味着这些都类似于热插拔设备,就像USB设备插入USB端口一样。USB和火线人仍旧是使用最流行的端口,因为它们的大小和速度。一个并口设备单元大于USB闪存因为并口大于USB端口。
下一步,我们有一个对于Micron PCIe的SSD驱动(Block Device Driver for Micron PCIe SSDs)。
你可能已经猜到了- 下面的文章会讨论更多的配置.
准备好配置更多的驱动了么?还有很多要做。
Linux支持两种不同的康柏智能阵列控制器:(Compaq SMART2 support)和(Compaq Smart Array 5xxx support)。阵列控制器是将物理存储单元表现为逻辑单元的设备。这些控制可能同样实现了基于硬件的RAID。硬件和软件RIAD的不同是简单的。Linux管理并见到软件RIAD。Linux将硬件RAID视为另外的存储单元。这意味着Linux没有意识到设备就是RAID驱动器。硬件(阵列控制器)独立于内核管理着RAID系统。这对于系统的性能更好因为内核不必配置或者管理RAID。注意,不同的阵列控制器有不同的RAID能力。
上面提到的阵列控制器可以通过这个驱动访问SCSI磁带(SCSI tape drive support for Smart Array 5xxx)。SCSI磁带是使用SCSI协议的磁带机。
PCI RAID控制器Mylex DAC960、AcceleRAID和eXtremeRAID在这个驱动中支持(Mylex DAC960/DAC1100 PCI RAID Controller support)。PCI RAID控制器是一个连接到PCI卡的阵列控制器。RAID控制器是拥有RAID功能的阵列控制器。
带电源备份的MM5415内存芯片在这个驱动中支持(Micro Memory MM5415 Battery Backed RAM support)。带后备电源内存芯片允许数据在切断电源后继续保存在内存设备中。这有助于保护数据。不然,当电源断开后,当前的计算机会话就会丢失。
当启用这个特性后,可以将典型的文件(比如ISO文件)作为一个块设备并挂载它Loopback device support)。这对于从镜像文件中检索文件而不必把文件烧录到光盘或者解压出来。想像一下你从因特网上得到了一份包含了很多文件的ISO文件。如果你只需要包中的一个文件并且用户不希望烧写ISO到光盘上或者不想知道如何打开一个ISO文件。用户可以用挂载ISO来替代。
Linux内核在初始化阶段会创建一些回路设备,所以一些回环设备已经准备好并创建了(Number of loop devices to pre-create at init time)。当一个文件(像ISO)或者虚拟设备(就像虚拟磁盘驱动器[vhd])被作为回环设备挂载时会节约一些时间。这个设定允许开发者选择内核可以预 创建多少回环设备。
当"Cryptoloop Support"启用后就可以CryptoAPI创建密码。这个用于硬件驱动器加密。然而,并不是所有的文件系统都支持。
下面用户可以启用"DRBD Distributed Replicated Block Device support"(译注:Linux上的分布存储系统)。这个就像网络RAID1。这些设备拥有设备文件/dev/drbdx。这些设备通常被用于集群,这里集群中的每台计算机都有一个从主单元镜像过来的存储单元。这意味着每台计算机的硬盘是位于组中心计算机硬盘的镜像拷贝。集群是一组计算机扮演着一台大型强力单元的角色。然而,每个集群都有一台控制计算机称为主节点。余下的计算机是从节点。
DRBD支持用于测试IO错误处理的故障注射(DRBD fault injection)。记住,故障注射就是使设备/软件认为发生了一个错误,因此开发者可以测试硬件/软件如何处理错误
如果内核要成为网络块设备的客户端,那么启用这个特性(Network block device support)。第一个设备文件是/dev/nd0。网络块设备是通过网络访问的远程存储单元。
直接连接SSD到PCI或者PCIe需要这个驱动(NVM Express block device)。
用这个特性允许将单独的SCSI OSD(object-based storage,基于对象的存储)对象作为块设备(OSD object-as-blkdev support)。
下一个驱动是"Promise SATA SX8 support"。这个驱动用于Promise公司(Promise Technology Inc.)生产的SATA控制器。
Linux允许将一部分内存作为块设备(RAM block device support)。这通常见与完全运行于内存上的Linux的live发行版。Linux的live发行版会卸载光盘并接着加载到内存中,所以在尝试一个新的操作系统或者修复另一个系统时不会伤害到已安装的系统。
下一个选项允许用户输入"Default number of RAM disks"(默认RAM磁盘数量)。
"Default RAM disk size"(默认RAM磁盘大小)可以以KB设置大小。
内核可以支持在内存设备的XIP文件系统作为块设备(Support XIP filesystems on RAM block device)。这个特性会增大内核的大小。 XIP (eXecute In Place)文件系统是一个允许可执行文件在相同的文件系统上存储数据而不必像其他应用一样利用内存。在一个驻留在内存上的live版linux系统上运行可执行文件时需要这个文件系统。
下面,内核可以支持"Packet writing on CD/DVD media"。(CD/DVD刻录机支持.)
内核开发者可以设置最大活跃并发包数量(Free buffers for data gathering)。大的数字会以内存的消耗为代价加速写入性能。一个包会消耗大约64KB。
Linux内核可以使用可擦写光盘作为缓存空间(Enable write caching)。这个特性仍然是试验性质。
下面的特性允许通过以太网线缆使用ATA规范(ATA over Ethernet support)。
下面的驱动允许虚拟块设备创建为virtio(Virtio block driver)。virtio是IO虚拟化平台。
一些非常老的硬盘还要一个特殊的驱动(Very old hard disk (MFM/RLL/IDE) driver)。
这里有一个驱动用于先前提到的Rados设备(Rados block device (RBD))。
下面是一个特殊的设备驱动(IBM FlashSystem 70/80 PCIe SSD Device Driver)。
现在,我们可以进入杂项设备。第一个设定是启用/禁用电位器(Analog Devices Digital Potentiometers )。
如果电位器在I2C总线上,那么就启用这个(support I2C bus connection)。
如果电位器是连接到SPI总线,那么需要这个驱动(support SPI bus connection)。
注意:Linux内核支持很多传感器因为Linux内核经常用于天气设备和机器人。
这个驱动用于IBM RSA(Condor)服务处理器(Device driver for IBM RSA service processor)。
内核同样支持PCI Sensable PHANToM设备驱动(Sensable PHANToM (PCI))。
这个驱动指引不同来自并行追踪接口(Parallel Trace Interface (PTI))的追踪数据发往Intel Penwell PTI口 (Parallel Trace Interface for MIPI P1149.7 cJTAG standard)。这个被指领的数据用于调试目的。
一些带有IOC4芯片的SGI IO控制器需要这个驱动(SGI IOC4 Base IO support)。SGI IO是由SCI管理的输入/输出设备。IOC4芯片控制着许多由这些设备执行的任务。这是一个基础驱动。其他对这些设备的驱动依赖于这个驱动。
这里有很少的TI闪存媒体适配器驱动在Linux内核中,(TI Flash Media interface support) 和(TI Flash Media PCI74xx/PCI76xx host adapter support)。
这个驱动("Integrated Circuits ICS932S401")用于ICS932S401时钟控制芯片。
Atmel同步串行通信外设(Synchronized Serial Communication peripheral (SSC))有一个驱动在内核中(Device driver for Atmel SSC peripheral)。这个设备提供点对点的设备间的串行连接。
"Enclosure Services"特性支持硬盘托架。
这是对于CS5535/CS5536芯片的定时器驱动(CS5535/CS5536 Geode Multi-Function General Purpose Timer (MFGPT) support)。
这个驱动让应用可以与HP工业标准服务器中的iLO管理处理器通信(Channel interface driver for the HP iLO processor)。"iLO"代表的是"Integrity Integrated Lights-Out".iLO允许远程服务器管理。
Linux内核支持ALS APDS9802光敏传感器(Medfield Avago APDS9802 ALS Sensor module)。一些其他支持的传感器包括:
Intersil ISL29003 ambient light sensor
Intersil ISL29020 ambient light sensor
Taos TSL2550 ambient light sensor
ROHM BH1780GLI ambient light sensor
BH1770GLC / SFH7770 combined ALS - Proximity sensor
APDS990X combined als and proximity sensors
注意:如果内核是为广泛的计算机编译的话,大多数驱动应该以模块形式加入。
Linux甚至可以使用"Honeywell HMC6352 compass"(一种电子罗盘)。
内核同样支持"Dallas DS1682 Total Elapsed Time Recorder with Alarm"。(一种运行时间记录仪)
16位的数模转换器通过这个驱动支持(Texas Instruments DAC7512)。
"VMware Balloon Driver"将客户机操作系统不需要的物理内存页交给需要那些需要的。
这里有两个不同的压力传感器(BMP085 digital pressure sensor on I2C) 和 (BMP085 digital pressure sensor on SPI)。
Intel输入/输出集线器(Intel Input/Output Hub (IOH))同样在内核中支持(Intel EG20T PCH/LAPIS Semicon IOH(ML7213/ML7223/ML7831) PHUB)。具体地说,这个是Intel Topcliff芯片组的PCH PHUB(Platform Controller Hub Packet Hub)
"FSA9480 USB Switch"是检测设备何时插入的检测器。
下一个选项允许比特流配置(Lattice ECP3 FPGA bitstream configuration via SPI)。
Silicon微控制器使用Silicon实验室C2端口,这需要一个特殊的驱动(Silicon Labs C2 port support)。
再说一次,继续留意下一篇文章因为我们还有更多的要做。
欢迎来享受Linux内核配置系列下一部分。如你所猜到的那样,内核支持大量不同的硬件、协议和特性。
下一组我们要讨论的特性是"EEPROM support"。电可擦除可编程只读存储器(Electrically Erasable Programmable Read-Only Memory)是一种掉电或者意外关闭后不会擦除内容的存储器。
内核支持在I2C卡上的EEPROM芯片包括FRAMs、ROMs和SRAMs (I2C EEPROMs / RAMs / ROMs 来自多数供货商)。FRAM(同样也称作FeRAM是一种使用铁电原理而不是电介质存储数据的随机访问存储芯片)。ROM芯片是只读(Read Only Memory)芯片。SRAM是静态而不是动态存储器就像DRAM。DRAN必须被刷新以保留数据而SRAM不需要刷新。然而,两者都会在电源关闭或者丢失时失去数据。
内核支持SPI总线的EEPROM(SPI EEPROMs from most vendors)。串行外设接口总线(Serial Peripheral Interface Bus (SPI))是一个缺乏错误检测的全双工总线系统。
老式的I2C EEPROM芯片需要一个除了上面I2C驱动之外的驱动(Old I2C EEPROM reader)。I2C总线用于嵌入式系统和电话,由于它用的是低速总线协议。
这个特性用来防止Maxim的可编程EEPROM变成只读模式(Maxim MAX6874/5 power supply supervisor)。特别地,这驱动提供对这个芯片的更好的电源管理。
这里还有一个驱动"EEPROM 93CX6 support","Microwire EEPROM 93XX46 support"和"ENE CB710/720 Flash memory card reader support"。
和其他内核特性一样,这里有一个对于EEPROM的调试特性(Enable driver debugging)。再说一次,为了更好的性能,禁用调试特性。
下面,我们有一个TI特性(Shared transport core driver)。这个驱动提供对于BT/FM和GPS芯片的传输协议。
下面的驱动支持I2C LIS3LV02Dx加速度计(STMicroeletronics LIS3LV02Dx three-axis digital accelerometer (I2C))。设备提供的数据存储在/sys/devices/platform/lis3lv02d。
下一步, Linux提供了下载固件到Altera的FPGA的模块(Altera FPGA firmware download module)。FPGA就是现场可编辑逻辑门阵列(field-programmable gate array)。它们是可编程集成电路。
Intel Management Engine Interface提供Intel芯片的安全和其他服务。
"ME Enabled Intel Chipsets"可以支持MEI。MEI是"Management Engine Interface"(管理引擎接口)。这个驱动支持有MEI服务的芯片组。
"VMware VMCI Driver"是一种用于客户机和宿主机中继通信的高速虚拟设备。VMCI代表的是"Virtual Machine Communication Interface"(虚拟机通信接口)。
下面, "ATA/ATAPI/MFM/RLL support"可以启用/禁用。MFM (Modified Frequency Modulation)是一种特殊的编码软驱位的方法。然而,这并不工作在所有的软驱上。MFM使用RLL(Run-Length Limited)编码制式。RLL通过有带宽限制的系统通信转换数据。ATAPI是先前提过的"ATA Packet Interface",同时ATA也在讨论接口标准的时候讨论过。
现在我们将讨论SCSI支持。小型计算机接口(Small Computer System Interface (SCSI))是另外一种SATA的接口标准。USB和火线设备使用SCSI协议。
第一个SCSI设定关于"RAID Transport Class"。这允许RAID使用SCSI标准。
为了使用SCSI目标,启用这个特性(SCSI target support)。
如果系统会运行旧的Linux应用,系统可能需要"legacy /proc/scsi/ support"。这会在/proc/scsi创建SCSI文件。
为了支持SCSI磁盘,启用下一个特性(SCSI disk support)。这是一个通用驱动。
为了支持SCSI磁带,启用这个特性(SCSI tape support)。这是一个通用驱动。SCSI磁带驱动器在像磁带的磁性条上记录数据。
OnStream SCSI磁带需要这个驱动而不是前面提到SCSI通用驱动SCSI OnStream SC-x0 tape support)。
"对于SCSI CDROM support",一些CD-ROM使用SCSI协议。
下面, 用户可以启用"Enable vendor-specific extensions (for SCSI CDROM)"。
这是一个对于大量不同SCSI设备的通用驱动(SCSI generic support)。这主要用于SCSI扫描仪和其他不被上面提到的SCSI驱动支持的设备或者那些之后会讨论的设备。
一些SCSI点唱机需要这个SCSI驱动(SCSI media changer support)。
Linux内核提供"SCSI Enclosure Support"。SCSI附件是一种管理电源和制冷SCSI设备同时提供不关于数据的服务的设备。
Linux内核应该设置为每个SCSI设备搜索全部的逻辑单元号(Logical Unit Numbers (LUN))(Probe all LUNs on each SCSI device)。LUN是SCSI地址。
这有额外的对于SCSI的错误报告(Verbose SCSI error reporting (kernel size +=12K))。这会明显地增加内核的大小。
这里还有一个SCSI日志系统(SCSI logging facility)。
为了增强你的系统,启用这个特性会允许SCSI在系统启动时就被探测到而不是先启用再探测(Asynchronous SCSI scanning)。大多数系统可以一次执行这两个任务,因此为什么允许这项? 对于那些连接了很多SCSI设备的硬件,这个会明显加快启动速度。
下面,"Parallel SCSI (SPI) Transport Attributes"(传统的并行SCSI)允许每个SCSI设备发送传输信息给sysfs。一些系统需要这个特性。
下面的特性和上面提到的一样,但是发送光纤通道设备的传输信息(FiberChannel Transport Attributes)(光纤通道接口)。光线通道设备使用SCSI。
下面用户可以启用/禁用"SCSI target support for FiberChannel Transport Attributes"(为光纤通道添加"target"模式驱动)。
iSCSI设备和SAS设备的传输数据可以导出到sysfs(iSCSI Transport Attributes)和SAS Transport Attributes)。SAS代表的的是"Serial Attached SCSI"(串行链接SCSI)。
下面,ATA支持被加入libsas(ATA support for libsas (requires libata))。注意配置工具提示需要libata。为了满足这个需求,启用ATA支持。更多情况下,配置工具已经或者将会会你这么做,但是请无论再检查一下。libsas和libata是相应的支持SAS和ATA的库。
下面的特性允许SAS接口接收SMP帧(Support for SMP interpretation for SAS hosts)。这加入了一个SMP解释器到libsas中。然而,这不会增加内核的尺寸。SMP帧允许所有在多CPU系统上的处理器访问SAS设备。
SRP可以发送传输的数据给sysfs(SRP Transport Attributes)。SRP代表SCSI RDMA协议(SCSI RDMA Protocol)。RDMA代表远程直接内存访问(Remote Direct Memory Access)。这意味着SRP是一个用来访问连接到另外一台计算机的SCSI设备的数据的协议。
下一步,用户可以启用"SCSI target support for SRP Transport"。
可以启用底层SCSI驱动(SCSI low-level drivers)。这提供了很多基础驱动。
在这之后,用户可以启用/禁用"PCMCIA SCSI adapter support"。这个适配器允许SCSI设备连接到PC卡上。
这里有一些驱动用于特殊的适配器- (Future Domain PCMCIA support)、(Qlogic PCMCIA support) 、(Symbios 53c500 PCMCIA support)。
多路径安装的设备需要这个特性(SCSI Device Handlers)。这用在每个节点都需要一个到SCSI存储单元的直接路径的集群中。
下一步,"OSD-Initiator library"(OSD启动库)可以启用。这是一个提供了补丁、OSD协议、和针对SCSI设备的T10协议的SCSI驱动。 OSD代表的是基于对象的存储设备(Object-based Storage Device);下一段会讨论得更多。
这个特性生成一个SCSI上层用于测试和管理/dev/osdx设备(OSD Upper Level driver)。exofs使用这个驱动用于挂载基于OSD的文件系统。OSD设备不像其他存储单元一样使用块的存储设备。相反地,OSD设备存储数据在称之为对象的容器里。exofs曾经称作OSDFS。
如果启用了它,OSD特性提供了调试工具(Compile All OSD modules with lots of DEBUG prints)。
如今,我们可以讨论串行ATA和并行ATA特性和驱动了。首先启用/禁用用于调试的第一个特性(Verbose ATA error reporting)。
下一步,用户应该对于ATA设备启用高级配置及电源接口特性(ATA ACPI Support)。这允许内核在SATA设备上更有效地管理电源使用。
内核包含了对于"SATA Zero Power Optical Disc Drive (ZPODD) support"的驱动。这会在不使用时关闭SATA光盘驱动器(SATA optical disc drives (ODD))。这节约了能源以及减少损耗。
贴士:即使你在编译一个高性能的内核,尝试启用所有的电源管理特性。则减少了电源消耗、操作开销、热量产生(热量会降低性能),以及老化。
SATA端口复用器需要这个驱动(SATA Port Multiplier support)。端口复用器是一个拥有许多端口但是自己仅需插入一个端口的设备。举例来说,如果一个硬件有一个SATA口,但是还需要更多的口,在这个口上插入端口复用器。现在设备可以有许多SATA口了。
下一个驱动用于AHCI SATA(AHCI SATA support)。高级主机控制器接口(Advanced Host Controller Interface (AHCI))是一种SATA总线适配器的操作标准。
对于要在Soc硬件上支持AHCI SATA设备,必须启用这个驱动(Platform AHCI SATA support)。Soc代表片上系统(System-on-a-Chip)。
下面是一些特殊设备的驱动
Initio 162x SATA support
ACard AHCI variant (ATP 8620)
Silicon Image 3124/3132 SATA support
再说一次,等着下一篇精彩的文章。
你好!这是Linux内核系列的下一篇,我们仍将配置ATA设备并将进入逻辑卷/存储。
"ATA SFF support (for legacy IDE and PATA)"应该启用,因为这扩展了ATA的能力。
为了支持Pacific Digital的ADMA控制器,应该启用"Pacific Digital ADMA support"。
"Pacific Digital Serial ATA QStor support"(串口ATA支持)在下一个驱动中支持
Promise的SATA SX4设备在内核中支持(Promise SATA SX4 support (Experimental))。
可以BMDMA的SFF ATA控制器需要这个驱动(ATA BMDMA support)。BMDMA代表总线主控直接内存访问(BMDMA stands for Bus-Master Direct Memory Access)。
下面,这个驱动对不同的SATA和PATA控制器提供支持Intel ESB, ICH, PIIX3, PIIX4 PATA/SATA support)。
这里有其他的特定设备驱动(Calxeda Highbank SATA support)、(Marvell SATA support)、(NVIDIA SATA support)、(Promise SATA TX2/TX4 support)、(Silicon Image SATA support)还有(SiS 964/965/966/180 SATA support)、(ServerWorks Frodo / Apple K2 SATA support)、(ULi Electronics SATA support)、(VIA SATA support)。。。由于有很多SATA/PATA控制器设计不同,一个通用驱动无法使用在这些设备上。
接下来,这个驱动支持PC卡上的ATA设备除非有特定设备管理硬件的驱动(PCMCIA PATA support)。
在这之后,有一个通用PATA驱动用于管理其他不被先前驱动支持的PATA设备 (Generic platform device PATA support)。
PATA设备的电源消耗由这个ACPI驱动管理(ACPI firmware driver for PATA)。强烈建议对系统上所有的硬件启用ACPI。虽然这会增加内核的大小,但是ACPI会增强性能。
"Generic ATA support"(通用ATA支持)由这个驱动提供。
古老的ISA、VLB和PCI总线PATA设备可以通过这个驱动支持(Legacy ISA PATA support (Experimental))。这个古老支持使用新的ATA层。
这组特性包含了许多对于RAID和LVM能力,可见下面的特性选项(Multiple devices driver support (RAID and LVM))。
有趣的事实:内核是由C和汇编写成的。
这个驱动允许RAID和LVM组合在一起。这用于使几个LVM卷使用RAID。分区被组合成逻辑块设备,然后形成RAID设备。
许多用户会希望RAID可以在启动时侦测到(Autodetect RAID arrays during kernel boot)。如果你没有RAID,那么不要启用这个特性。不然,启动处理会比原先希望的慢上几秒。
注意:当配置Linux内核时,最好按照"use it or lose it"(非用即失)的原则。那就是,如果你不用它,那就禁用这个特性。
硬盘分区可以通过这个驱动加在一起(Linear (append) mode)。
下面的驱动加入RAID-0支持带逻辑块设备中(RAID-0 (striping) mode)。接着还有 (RAID-1 (mirroring) mode)、(RAID-10 (mirrored striping) mode)和(RAID-4/RAID-5/RAID-6 mode)。
MD框架需要多路径支持(Multipath I/O support)。MD框架就是多设备(Multi Device)框架,它将多台设备作为一个单元管理。举例来说,将许多存储单元的分区组合起来可以使多个设备就像一个那样。多路径支持是用于使用处理虚拟的有多个地址的"单个设备"。因为单存储单元物理上有多件物理设备,所以它有多个硬件地址。
使用这个调试驱动,可以测试更大的多磁盘存储单元的bug(Faulty test module for MD)。
"Device mapper support"是一个用来映射逻辑扇区的卷管理器。LVM使用扇区映射。
如果启用的话,设备映射器可以有调试特性(Device mapper debugging support)。
如果需要,逻辑设备可以设置加密数据(Crypt target support)。这个特性允许用户将来加密那些存储设备。
只有启用了这个特性,才能使用逻辑存储单元的快照功能(Snapshot target)。
"Thin provisioning"(自动精简配置)允许逻辑卷设置成比组成逻辑卷的物理设备拥有更大的存储容量(Thin provisioning target)。这个特性同样为这类设备提供了快照功能。这额外的虚拟数据空间无法马上使用。这个特性的意义是允许用户在将来增加物理存储单元并且节约了配置逻辑块设备的时间。
用这个可以调试"Thin provisioning" (Keep stack trace of thin provisioning block lock holders)。
块设备性能的提升可以通过移动更多的常用数据到更快的存储单元中(Cache target (EXPERIMENTAL))。
卷管理器可以制成镜像逻辑卷(Mirror target)。
设备映射器(Device-mapper (dm))单元支持映射RAID1、RAID10、 RAID4、RAID5和RAID6(RAID 1/4/5/6/10 target)。
设备映射器(device-mapper)日志可以镜像到用户空间(Mirror userspace logging)。
"Zero target"是一个忽视写入并返回读取为零的设备。
接下来,卷管理器应该对硬件有多路径支持(Multipath target)。
这个驱动会发现最有效的到存储设备的路径来读取和写入(I/O Path Selector based on the number of in-flight I/Os)。
下面的一个驱动和以上相同,但是会寻找最快路径(I/O Path Selector based on the service time)。
如果一个逻辑卷上的物理存储单元正忙,如果可能的话,这个特性会允许读取/写入到另一个物理卷上。
udev可以生成设备管理器操作事件DM uevents)。udev是/dev的设备管理器。
为了测试软件/硬件对偶尔失败的输入/输出任务的逻辑设备如何反映,启用这个调试特性(Flakey target)。
逻辑卷可以创建为一个用于验证另一个逻辑分区数据的只读存储单元(Verity target support)。
注意:如果你喜欢我的文章,并且如果你有的账号,请在我的文章上点击"Like"。同样,再次分享这篇文章在Google、Twitter和/或者Facebook上。
ConfigFS和TCM存储引擎可以通过这个设置启用(Generic Target Core Mod (TCM) and ConfigFS Infrastructure)。ConfigFS是一个基于内存的文件系统。
有趣的事实:Linux内核没有"main()"函数。在程序中,main()被依赖于kernel的libc调用。内核没有main()函数是因为libc将无法启动内核。如果内核的确有main()函数,那么我们就有一个"鸡或者蛋"的问题-谁先来?另外,内核的入口点用汇编写成,这并不使用main()函数。
下面,"TCM/IBLOCK Subsystem Plugin for Linux/BLOCK"可以禁用或者启用。
接着"TCM/FILEIO Subsystem Plugin for Linux/VFS"可以启用/禁用。
再次,还有两个TCM特性 - (TCM/pSCSI Subsystem Plugin for Linux/SCSI) 和 (TCM Virtual SAS target and Linux/SCSI LDD fabric loopback module)
对于ConfigFS的" iSCSI Target Mode Stack"在这个驱动中支持( iSCSI Target Mode Stack)。
下一步,可以启用/禁用"FireWire SBP-2 fabric module"。这允许一台计算机作为一个硬盘连接到另一台计算机上。
在这之后,我们可以配置"Fusion Message Passing Technology (MPT) device support"。
在那个标题下的第一个选项是一个用于并口适配器的SCSI支持的驱动(Fusion MPT ScsiHost drivers for SPI)。
SCSI同样也可以支持光纤通道主机适配器(Fusion MPT ScsiHost drivers for FC)和/或SAS适配器(Fusion MPT ScsiHost drivers for SAS)。
下一步,用户可以设置"Maximum number of scatter gather entries"。一个低的数值可以减少每个控制器实例的内存消耗。
下一个驱动提供了ioctl系统调用来管理MPT适配器(Fusion MPT misc device (ioctl) driver)。
光纤通道端口可以用这个驱动支持IP LAN的流量(Fusion MPT LAN driver)。
我可以读到你们的想法-你们会想到对于这个还有另外一篇文章。是的,你们想对了。请继续关注这个系列的下一篇文章。
如果你喜欢这个系列,请在和/或者Google+上发表评论告诉我你有多喜欢这个系列,并且告诉我你想在今后的文章中希望看到的方面。或者给我发邮件)。谢谢!
想要更多地了解作者,请检查下面的签名栏中的链接(译注:原文所在论坛有)
如果你已经完整地阅读了这篇文章,那么你应该已经看到单词"Facebook"三次了。如果没有,你没有阅读全部文章。
单词"Facebook"在这段中,上一段,和一个注解中。我打赌你阅读了上面的段落而没有通读文章来试图寻找第三个单词实例。
欢迎进入Linux内核系列文章的下一篇!我们正在接近配置过程的终点。在这篇文章中,我们将会讨论固件驱动和文件系统驱动。
这个分类中的第一个驱动是寻找启动盘(BIOS Enhanced Disk Drive calls determine boot disk)。有时,Linux不会知道哪个盘是启动盘。这个驱动允许内核询问BIOS。Linux接着在sysfs上存储信息。Linux需要知道这些来设置bootloader。
即使BIOS EDD服务被编译进了内核,这个选项可以设置这些服务不激活(Sets default behavior for EDD detection to off )。EDD代表的是"Enhanced Disk Drive"(增强磁盘驱动器)。
当使用kexec加载不同的内核时,性能可以通过固件提供的内存映射提升(Add firmware-provided memory map to sysfs)。
"Dell Systems Management Base Driver"通过sysfs接口提供了Linux内核对于Dell硬件的更好的控制。
启用这个驱动可以通过/sys/class/dmi/id/访问硬件的信息(Export DMI identification via sysfs to userspace)。DMI代表的是Desktop Management Interface(桌面管理接口)。DMI管理硬件的组件和访问硬件的数据。BIOS中数据的接口和硬件由SMBIOS(System Management BIOS)规范调节。
从DMI得到的原始数据表可以通过这个驱动访问(DMI table support in sysfs)。
为了从iSCSI驱动器中启动,启用这个驱动(DMI table support in sysfs)。
最后的驱动是一组"Google Firmware Drivers"。这些驱动用于Google特定的硬件。除非你为Google工作并且需要在硬件上使用Linux或者你在为一台从Google偷来的电脑编译内核,否则不要启用它。
下面,我们可以配置内核的文件系统支持。
"Second extended fs support"驱动用于EXT2文件系统。
"Ext2 extended attributes"提供了原生文件系统不支持的额外的元数据的使用。
"Ext2 POSIX Access Control Lists"增加了额外的非原生的权限模型。
"Ext2 Security Labels"增强了由SELinux提供的安全性。
启用"Ext2 execute in place support"允许可执行文件在当前的位置执行而不必在页缓存中执行。
这个驱动提供EXT3文件系统(Ext3 journaling file system support)。
"Default to 'data=ordered' in ext3"驱动设置数据的排序模式为"Ordered"。这种处理方式为日志和写入工作。数据排序在这篇文章中解释 -
"Ext3 extended attributes"提供了原生文件系统不支持的额外的元数据使用。再说一次,接下来的EXT3的驱动/特性与EXT2相同 - "Ext3 POSIX Access Control Lists" 和 "Ext3 Security Labels"。同样,对接下来的EXT4也是相同的 - "Ext4 POSIX Access Control Lists"、"Ext4 Security Labels" 和 "EXT4 debugging support"。
EXT3和EXT4支持日志块设备调试(JBD debugging support),(JBD2 debugging support)。
下面的驱动提供Reiser文件系统支持(Reiserfs support)。
Reiser文件系统也有调试(Enable reiserfs debug mode)。
内核可以存储ReiserFS统计在/proc/fs/reiserfs (Stats in /proc/fs/reiserfs)。
下面的Reiser驱动/特性与EXT2/3/4相同 - ReiserFS extended attributes", "ReiserFS POSIX Access Control Lists" 和 "ReiserFS Security Labels".
Linux内核同样支持JFS,同时也包含了不同的特性 "JFS filesystem support"、 "JFS POSIX Access Control Lists"、"JFS Security Labels"、"JFS debugging" 和 "JFS statistics".
再说一次,XFS可以通过启用这些驱动/特性支持 - "XFS filesystem support"、"XFS Quota support"、"XFS POSIX ACL support"、"XFS Realtime subvolume support" 和 "XFS Debugging support"。
"Global FileSystem 2"可以被内核支持(GFS2 file system support)。这个文件系统用于在集群中共享存储。
"GFS2 DLM locking"驱动提供了GFS2的分布式锁管理(DLM)
"Oracle Cluster FileSystem 2"被内核支持(OCFS2 file system support)。这个文件系统用于在集群中共享存储。
"O2CB Kernelspace Clustering"提供了OCFS2文件系统的不同服务。
"OCFS2 Userspace Clustering"允许集群栈在用户空间执行。
"OCFS2 statistics"驱动允许用户得到关于文件系统的统计信息。
像大多树Linux内核一样,OCFS2提供日志(OCFS2 logging support)。这可能被用来监视错误或者调试目的。
"OCFS2 expensive checks"驱动以性能为代价提供了存储一致性检测。一些Linux用户建议只有在调试目的在才启用它。
Linux内核同样包含了新的B树文件系统;这个驱动提供了磁盘格式化程序(Btrfs filesystem Unstable disk format)。BTRFS仍在开发中并被计划某天变的比EXT4更流行。
"Btrfs POSIX Access Control Lists"提供了额外的原生BTRFS没有提供的权限模型。
下面,是一个BTRFS检测工具(Btrfs with integrity check tool compiled in (DANGEROUS))。由于BTRFS是一个最新在开发中的文件系统,大多数相关软件还并不稳定。
Linux系统也支持NIL-FileSystem(NILFS2 file system support)。547/。
为了支持一些文件系统使用到的flock()系统调用,启用这个驱动(Enable POSIX file locking API)。禁用这个去的那个会减少11KB的内核大小。这个驱动提供了文件锁定。文件锁定是一个允许进程在某刻读取文件的过程。这通常用于网络文件系统,就像NFS。
"Dnotify support"驱动是一个古老的文件系统通知系统,它提醒文件系统上的事件的用户空间。它和它的继承者被用于监控应用的文件系统。某个应用告诉守护进程需要监视哪些事件。不然,每个用户空间应用需要它们自己完成这个任务。
记住,Dnotify是一个古老的系统,那么什么是新的通知系统?它就是由这个驱动提供的Inotify (Inotify support for userspace)。
一个可选的通知系统是fanotify (Filesystem wide access notification)。Fanotify与Inotify一样,但是fanotify比Inotify传递更多的信息到用户空间中。
用这个驱动Fanotify可以检测权限(fanotify permissions checking)。
对于用户想要划分存储空间的系统需要 "Quota support"。
接下来的驱动允许通过netlink报告磁盘配额警告和信息(Report quota messages through netlink interface)。netlink是一个用于与内核通信的用户空间的套接字接口。
配额信息同样可以发送到控制台(Print quota warnings to console (OBSOLETE))。
这个驱动允许配额系统执行额外的完整性检查(Additional quota sanity checks)。在计算机技术中,完整性检查是检测由于不良编程导致的错误。文件和输出都被检查来确保数据正确而不是以奇怪的方式构造。
一些旧的系统使用老的配额系统但希望在升级新内核时保留旧的配额系统。可以通过启用这个来容易解决(Old quota format support)。许多读者可能想要知道为什么一些人想要保留旧的配额系统而不是更新新的。好的,想想一下你是一家很大公司的IT部门的经理,公司有许多服务器运行着非常重要的任务。当你可以继续使用现在工作的很好的系统,你想要创建并配置一个新的(也可能很大)的文件系统么? 通常上,对于计算机,坚持下面的原则 - 如果它没有坏或者不会导致安全问题,不要去修复它。
用这个驱动,新的配额系统支持32位UID和GID(Quota format vfsv0 and vfsv1 support)。
为了自动挂载远程存储单元,启用这个驱动(Kernel automounter version 4 support)。
这个驱动支持FUSE文件系统(FUSE (Filesystem in Userspace) support)。用户空间文件系统(FUSE)支持任何用户创建他们自己的文件系统并在用户空间内使用。
一个特殊的FUSE扩展可以用于在用户空间使用字符设备Character device in Userspace support)。
下一篇文章中,我们会继续讨论缓存,光盘文件系统,Linux上的FAT32和其他有趣的文件系统话题。谢谢!
你好! 准备好读另一篇很酷的Linux内核文章了么?
接下来,在这个任务中,我们可以启用/禁用"Fusion MPT logging facility"。MPT代表"Message Passing Technology"(消息传递技术)。Fusion驱动是由LSI Logic公司开发。MPT一种进程间使用的特定消息策略。这个技术是同步的意味着进程将会等待所需的消息。
在这之后,如果计算机处理拥有火线端口就应该启用"FireWire driver stack"。如果没有,那么就没有必要去启动一个不会使用到的火线驱动。火线很像USB。不过在协议、速度、物理形状和端口布局上不同。通常上,苹果设备使用火线和USB。一些PC有火线端口,但是不像USB口那样普及。
一些火线控制器使用OHCI-1394规范(OHCI-1394 controllers)。如果是这样,启用这个驱动。
为了使用火线存储设备,启用下一个驱动(Storage devices (SBP-2 protocol))。这个驱动提供了火线存储单元与火线总线通信的协议(the card with the attached FireWire ports)。一些火线扫描仪同样需要这个驱动。
IPv4可以用在火线端口(IP networking over 1394)。IEEE 1394或者简单的"1394"就是火线。使用IPv4在火线多播有局限。
"Nosy"是"FireWire PCILynx"卡上的流量监控(Nosy - a FireWire traffic sniffer for PCILynx cards)。
下一步,可以支持I2O设备(I2O device support)。"Intelligent Input/Output (I2O)"(智能输入/输出)总线使用硬件和操作系统层的驱动。硬件驱动(hardware drivers (HDM))并不特定与任何操作系统而OS驱动(OS drivers (OSM))必须在目标操作系统上使用。OSM可以与任何HDM通信。I2O卡/总线有一个IOP- 输入/输出处理器(Input/Output Processor)。由于主CPU处理更少的数据,所以加速了系统。
只在缺乏SUN I2O控制器的系统上启用"Enable LCT notification"。I2C SUN固件不支持LCT通知。 如果目标是RAID,Adaptec I2O控制器需要下一个驱动(Enable Adaptec extensions)。
64位的直接内存访问可以在Adaptec I2O控制器上启用(Enable 64-bit DMA)。
如果允许,可以配置I2O设备(I2O Configuration support)。这个特性主要用在RAID设定中。
可以为I2O启用支持老的输入/输出控制(Enable ioctls (OBSOLETE))。
可以启用I2O总线适配器的OSM软件(I2O Bus Adapter OSM)。这组OSM被用来寻找新的在其他适配器末端的I2O设备。
下面,可以启用I2O块设备上的OSM(I2O Block OSM)。I2O硬件上的RAID控制器需要这个OSM。
下面的OSM用于I2O控制器上的SCSI或者光纤通道设备。
如果启用了(I2O /proc support),可以通过/proc读取I2O设备的信息。
在启用/禁用了I2O特性,我们可以继续其他的内核特性。下面,我们看到"Macintosh device drivers"。这只对苹果设备有用。PC的Linux内核不应该有任何这些驱动启用。然而,正如许多说法都有例外一样。一些PC用户可能会使用苹果鼠标、键盘和/或者一些其他的苹果设备。再说一次,最好彻底地理解需求和正在开发的内核。
下一步,我们有一个用于网络的驱动(Network device support)。X11和其他的Linux软件不依赖于这个驱动,所以如果内核不会连接到另一台计算机、因特网、内联网或者网络,那么这个特性可以安全地禁用。
下面的驱动就像上面,但是特定于核心驱动(Network core driver support)。
这个驱动支持Etherchannel(Bonding driver support)。"bonding"是两条或者更多的以太网通道的融合。这也成为中继。
使用这个驱动(Dummy net driver support),可以在Linux中设置一个虚拟网络。虚拟网络(dummy network)就像网络中的/dev/null。任何发送给虚拟网络的数据都会永久消失,因为它会发往/dev/null。IP地址没有设置。用户可以定义他们的网络相当于/dev/null。
下一步,可以支持和EQL(EQL (serial line load balancing) support)。这允许两台计算机使用SLIP或者PPP协议在两条串行连接上通信。
光纤通道是一种用于连接存储设备到计算机的快速串行协议(Fibre Channel driver support)。
TMII收发器需要这个驱动(Generic Media Independent Interface device support)。MII是一种用于最高速度为100Mbit/s以太网的接口。以太网线缆用于连接到PHYceiver,这是一种以太网收发器。
为了通过虚拟接口组织许多以太网设备,需要"Ethernet team driver support"。
"MAC-VLAN support"允许用户在特定的MAC地址和某个接口上映射数据包。
TAP字符设备可以由MAC-VLAN接口生成(MAC-VLAN based tap driver)。TAP设备从内核中获取数据包,这样它们就可以被送往其他地方。
下一个特性允许虚拟vxvlan接口在3层网络上创建2层网络(Virtual eXtensible Local Area Network (VXLAN))。这通常用于隧道虚拟网络。
内核发送给网络的消息可任意通过这个特性记录下来(Network console logging support)。除非记录网络信息对你很重要时才启用它。禁用这个特性会增强性能。
这个特性允许不同参数被改变(Dynamic reconfiguration of logging targets)。这些参数包括端口号、MAC地址、IP地址和其他一些设定。
如果用户空间程序希望使用TAP设备,那么启用这个特性可以允许这样的活动(Universal TUN/TAP device driver support)。
这个驱动用于本地以太网隧道(Virtual ethernet pair device)。
"Virtio network driver"用于QEMU、Xen、KVM和其他虚拟机。
下一步,可以启用"ARCnet support"。ARCnet是一种类似令牌环本地局域网络(Local-Area-Network (LAN)协议。ARCnet代表"Attached Resource Computer Network"(附加资源计算器网络)。
现在,我们进入到"ATM drivers"。ATM代表"Asynchronous Transfer Mode"(异步传输模式)。ATM用于电信。
Marevell以太网交换机芯片需要这个驱动(Marvell 88E6060 ethernet switch chip support)。同样,这类交换机的芯片同样需要依赖模型(Marvell 88E6085/6095/6095F/6131 ethernet switch chip support)和(Marvell 88E6123/6161/6165 ethernet switch chip support)。
现在,我们可以学习关于"Ethernet driver support"。
首先我们可以启用/禁用"3Com devices"。接下来允许内核开发者选择支持哪些3Com设备。
下一组选项是对于不同的"Adaptec devices"和接下来的"Alteon devices"。
这些只是特定设备/供应商驱动。通常地,这些驱动被作为模块加入。
在设置了这两组选项后,接下来还有"AMD devices"和"Atheros devices"。
注意:请记住内核会运行在哪类硬件上。对于大量不同的设备,或许最好把它们作为模块加入
这里有不同特定供货商的设备驱动-"Cadence devices"、"Broadcom devices"、"Brocade devices"、"Chelsio devices"、"Cisco devices"、"Digital Equipment devices"。一些其他的特定设备/供应商驱动遵循它们。
接下来的驱动并不是特定设备/供应商的 "SLIP (serial line) support"。这个驱动支持SLIP和CSLIP。SLIP(Serial Line Internet Protocol)是一种用于调制解调器和串口的因特网驱动。PPP现在用来代替SLIP。CSLIP是压缩的SLIP。
下面,"CSLIP compressed headers"可以启用用来压缩TCP/IP头。CSLIP快于SLIP,但是想要启用CSLIP,传输和接收的计算机都必须理解CSLIP。
当在恶劣的模拟线路上使用SLIP时,最好启用"Keepalive and linefill",这会帮助保持连接。
对于质量差的网络或者7bit网络中运行IP而言,最好启用"Six bit SLIP encapsulation"。
现在我们可以进入流行的USB系统,但是这些是用于网络的USB驱动。
第一个启用/禁用的USB网络设备是"USB CATC NetMate-based Ethernet device support"。这是用于10Mbps的USB以太网EL1210A芯片设备。USB设备将会扮演和成为一个以太网设备即使硬件是USB。
接下来,除了设备是KLSI KL5KUSB101B芯片组(USB KLSI KL5USB101-based ethernet device support),其他与上面的驱动一样。
Pegasus USB是USB转以太网的适配器/转换器(USB Pegasus/Pegasus-II based ethernet device support)。
接下来是另外一个USB转以太网驱动(USB RTL8150 based ethernet device support)。
下一篇文章中,我们将继续配置USB网络系统。
你好!在这篇Linux系列文章中,我们将继续配置USB网络驱动。接着我们将进入输入设备。
首先,我们可以启用/禁用"Multi-purpose USB Networking Framework",这允许连接笔记本到桌面系统上。
下面,可以启用/禁用ASIX USB-to-Ethernet适配器驱动(ASIX AX88xxx Based USB 2.0 Ethernet Adapters)。
那么,还有一个ASIX适配器驱动(ASIX AX88179/178A USB 3.0/2.0 to Gigabit Ethernet)。
注意:通常地,最好将适配器驱动作为模块加入。
通信设备类规范(Communication Device Class specification)在这个驱动中提供(CDC Ethernet support (smart devices such as cable modems))。这个规范用于USB调制解调器。Linux系统可以将USB网络接口识别为以太网网络接口并且指定为"ethX",这里的"X"是以太设备编号。
下面是一个与上面类似的规范(CDC EEM support)。CDC EEM代表的是"Communication Device Class Ethernet Emulation Model"(通信设备类以太网仿真模型)。
CDC网络控制模型(NCM)同样有一个驱动提供了规范(CDC NCM support)。
这个驱动提供了"CDC MBIM (Mobile Broadband Interface Model)"规范同样也在Linux内核中(CDC MBIM support)。
下面,有一些供货商/设备特定驱动用于不同的USB网络设备和芯片组。
在这之后,有一个用于USB网络设备的通用驱动,它不需要任何特殊的驱动(Simple USB Network Links (CDC Ethernet subset))。
再说一次,还有更多的驱动用于供货商特定设备。
有趣的事实:Linux被用于制作James Cameron的电影"泰坦尼克"的特效。
"CDC Phonet support"是用于使用Phonet的Nokia USB调制解调器。(译注:Phonet是Nokia开发的面向数据包的通信协议,仅用于Nokia maemo/meego产品)
现在,我们可以进入使用802.11规范的无线局域网驱动了。
主要地,这里有一个供货商/设备特定驱动列表。
"SoftLED Support"控制着关于Wifi卡/设备的LED灯。
一些芯片组支持的SDIO在这个驱动中(Atheros ath6kl SDIO support)。SDIO是用于无线SD卡的SD(Secure Digital)规范的扩展。SDIO代表的是"Secure Digital Input/Output"
内核开发者可能注意到一些无线设备可以支持QoS。QoS代表"Quality of Service"(服务质量)。这个特性给予网络传输优先级。假设需要通过网络传输两组数据。只有一个可以先发送。QoS会先发送最重要的数据。
有趣的事实:技术上来说,Linux并不是一个操作系统。Linux是一种内核而GNU/Linux才是操作系统。
WAN卡需要"Generic HDLC layer"。HDLC代表"High-Level Data Link Control"(高级数据链路控制)。这是一个数据链路层协议。
原生HDLC可以通过"Raw HDLC support"驱动启用。
"Raw HDLC Ethernet device support"驱动允许HDLC层模拟以太网。
cHDLC驱动提供了一个HDLC的扩展,同样也称作Cisco HDLC(Cisco HDLC support)。
Linux内核同样也提供了一个HDLC的"Frame Relay support"(帧中继)驱动。帧中继是2层协议。
HDLC同样支持PPP(Synchronous Point-to-Point Protocol (PPP) support)和X.25(X.25 protocol support)。
接下来,这个驱动提供了DLCI下的帧中继(Frame Relay DLCI support)。
"LAPB over Ethernet driver"创建一个允许用户在以太网上使用LAPB的点到点连接到另一台计算机的设备文件。这个设备文件对于第一个此类设备通常是/dev/lapb0。
用这个驱动,X.25帧可以通过电话线发送(X.25 async driver)。特别地,这个驱动允许X.25使用异步串行。
对于ISA SBNI12-xx有一种特殊的驱动(Granch SBNI12 Leased Line adapter support)。这种卡对于租用线路的调制解调器是一种便宜的替代。
下一个驱动允许使用并行连接携带已安排的流量(Multiple line feature support)。这允许Linux系统更加有效地在SBNI12适配器上管理并行连接。一些Linux用户声称这个驱动双倍加速了他们的速度。然而,这个我没有亲身测试了解。
接下来,可以配置"IEEE 802.15.4 drivers"。这个是对于慢速WAN设备。这是一个控制媒体和无线网络物理层的标准。这个规范在不同的大洲使用不同的频率。不如,在欧洲,这类无线设备会使用868.0-868.6MHz的频率。
这个目录中的第一个设定是fake LR-WPAN驱动(Fake LR-WPAN driver with several interconnected devices)。LR-WPAN代表"Low-Rate Wireless Personal Area Network"(低速无线个人网络)。
有趣的事实:目前内核中只有大约2%的代码是由Linus Torvalds写的。
VMware使用vmxnet3虚拟以太网需要这个驱动(VMware VMXNET3 ethernet driver)。当在为大量用户编译内核时,最好将这个启用为一个模块,因为一些人可能并不希望在VMware上使用以太网。
Hyper-V虚拟网络需要这个驱动(Microsoft Hyper-V virtual network driver)。你可能想知道这个是否与微软的Hyper-V相同?是的,Linux支持Hyper-V。
数字电话服务ISDN由这个驱动提供(ISDN support)。ISDN代表"Integrated Services Digital Network"(综合业务数字网)。在法国,ISDN被称为RNIS,代表" Réseau numérique à intégration de services"。有一台ISDN适配器,计算机可以开始并接收语音呼叫。这允许计算机用来做因待机或者其他一些电话服务设备。ISDN同样也可以携带视频信息。
现在,我们可以进入输入设备了(Input device support)。这些是给计算机信息的设备。鼠标和键盘是最常被使用和了解的输入设备。扫描仪是另外一种输入设备的例子。
首先是一个支持不同触觉反馈设备的驱动(Support for memoryless force-feedback devices)。比如,许多游戏控制器的震动就是一种触觉反馈。
一些输入设备会检测硬件的状态(Polled input device skeleton)。这类行为需要这个驱动。
使用稀疏键盘映射的输入设备需要这个驱动(Sparse keymap support library)。键盘映射是键盘的布局信息。
下面,是另外一种键盘映射(Matrix keymap support library)。
注意:当为广泛的用户组编译内核时,包含大多数或者全部输入设备作为模块,因为通常不知道用户可能插到计算机上的设备类型。
有趣的事实:Vanilla内核就是Linux自己的原始内核,是未改变的状态。
"Mouse interface"对于鼠标创建了两个不同的设备文件。这两个设备文件是/dev/input/mouseX 和 /dev/input/mice。
下一个驱动创建了一个psaux设备文件并且它是/dev/input/mice的别名 (Provide legacy /dev/psaux device)。psaux设备文件是/dev/psaux。
如果系统有一块数位板,那么需要设置水平分辨率(Horizontal screen resolution)和垂直分辨率(Vertical screen resolution)。数位板是一种支持允许用户绘画的触控笔的触摸屏。另外的触摸屏无法支持如此复杂的输入。
下一个驱动支持操纵杆和游戏手柄(Joystick interface)。这个驱动会创建/dev/input/jsX文件。
"Event interface"驱动允许输入设备通过dev/input/eventX访问。
"Event debugging"驱动会输出所有的输入事件到系统日志中。除了要调试系统否则不要以任何理由启用它。显然地,这么做为了性能原因,但是我这么建议禁用的主要原因是安全目的。所有的按键都会被明文记录下来包括密码。
下面,列出了不同的键盘(Keyboards)配置驱动,接下来是鼠标(Mice)驱动和操纵杆和游戏手柄(joystick/gamepad)驱动。
在这之后,列出了不同特定的平板硬件/供货商的不同驱动(Tablets)。在这之后是触摸屏的驱动列表。
最后一组输入设备驱动是对于特定硬件和供货商的杂项驱动列表(Miscellaneous devices)。
这个系列的下一篇文章会讨论输入端口。不要忘记阅读这个系列的其他文章和这个网站。谢谢!
输入/输出端口:
欢迎来到下一篇Linux内核文章。在本篇里,我们将讨论输入/输出端口。
首先,PS/2鼠标和AT键盘需要"i8042 PC Keyboard controller"驱动。在USB之前,鼠标和键盘使用圆形端口的PS/2端口。AT键盘是一种84键使用AT端口的IBM键盘。AT端口有5针而PS/2口有六针。
使用COM口(有时也称RS232串口)的输入设备需要这个驱动(Serial port line discipline)。COM是一种串口,意味着每次传输一位。
TravelMate笔记本需要这个特殊的驱动来使用连接到QuickPort的鼠标(ct82c710 Aux port controller)。
对于PS/2 mice、AT keyboards 和 XT keyboards的并口适配器使用这个驱动(Parallel port keyboard adapter)。
"PS/2 driver library"用于PS/2鼠标和AT键盘。
可以启用"Raw access to serio ports"来允许设备文件作为字符文件来使用。
下面,下面有一个用于"Altera UP PS/2 controller"的驱动。
PS/2复用同样需要一个驱动(TQC PS/2 multiplexer)。
ARC FPGA平台对于PS/2控制器需要特殊的驱动(ARC PS/2 support)。
注意:我想要说清楚这篇文章中讨论的PS/2控制器并不是Sony的PlayStation上的游戏控制器。这篇文章讨论的是6针鼠标/键盘端口。控制器是一种有PS/2端口的卡。
"Gameport support"提供对15针gameport的支持。gameport是一种曾经被很多游戏设备使用直到USB端口的发明的15针口。
下一个驱动是在ISA或者PnP总线卡上的gameport驱动(Classic ISA and PnP gameport support)。ISA代表"Industry Standard Architecture"(工业标准架构)并且它是一种在PCI之前的并行总线标准。PnP代表"Plug-and-Play"(即插即用)并且他是一种在ISA之前的通用标准。
"PDPI Lightning 4 gamecard support"提供了一个有gameport的游戏卡的专有驱动。
SoundBlaster Audigy卡是一种专有gameport卡(SB Live and Audigy gameport support)。
ForteMedia FM801 PCI音频控制器在卡上有一个音频控制器(ForteMedia FM801 gameport support)。这个驱动只支持gameport。
下一步,我们可以进入"Character devices"。字符设备以字符传输数据。
首先,可以启用/禁用TTY(Enable TTY)。移除TTY会节约很多空间,但是许多终端和这类设备需要TTY。除非你知道你在做什么,否则不要禁用TTY。
致我的粉丝:如果你知道一个禁用TTY的理由,你能在下面发表你的答案并与我们共享么?谢谢!
下一步,可以启用/禁用"Virtual terminals"(虚拟终端)。再说一次,这个可以节约很多空间,但是虚拟终端很重要。
下一个驱动支持字体映射和Unicode转换(Enable character translations in console)。这用于转换ASCII到Unicode。
虚拟终端可以用这个驱动作为系统控制台(Support for console on virtual terminal)。系统控制台管理着登陆和内核信息/警告。
虚拟终端必须通过控制台驱动与物理终端交互(Support for binding and unbinding console drivers)。在虚拟终端可用之前,控制台驱动必须被加载。当虚拟终端关闭后,控制台终端必须被卸载。
下一个驱动提供了对Unix98 PTY驱动的支持(Unix98 PTY support)。这是Unix98伪终端。
有趣的事实:Linux内核允许某个文件系统一次在很多地方被多次挂载。
接下来,可以支持"Support multiple instances of devpts"(译注:允许多个"devpts"文件系统实例)。devpts文件系统用于伪终端的slave。
过时的PTY同样可以启用(Legacy (BSD) PTY support)。
可以设置最大数量的使用中的过时PTS(Maximum number of legacy PTY in use)。
下面的驱动可以用于提供对其他驱动不支持的串口的支持 (Non-standard serial port support)。
下面有一些用于特定板和卡的驱动。
这个驱动支持GSM MUX协议(GSM多路复用)(GSM MUX line discipline support (EXPERIMENTAL))。
下一个驱动启用kmem设备文件(/dev/kmem virtual device support)。kmem通常用于内核调试。kmem可以用于读取某些内核变量和状态。
Stallion卡上面有许多串口Stallion multiport serial support)。这个驱动特别支持这块卡。
下面,我们可以进入到串行设备驱动了。如前所述,串行设备每次传输一位。
第一个驱动用于标准串口支持(8250/16550 and compatible serial support)。
在这个驱动下,即插即用(Plug-and-Play)同样存在于串口中(8250/16550 PNP device support)。
下面的驱动允许串口用于连接一个终端后作为控制台(Console on 8250/16550 and compatible serial port)。
一些UART控制器支持直接内存访问(DMA support for 16550 compatible UART controllers)。UART代表的是"Universal Asynchronous Receiver/Transmitter"(通用异步收发)。UART控制器转换串行到并行,反之亦然。
下一步,这个驱动提供了标准PCI串行设备支持(8250/16550 PCI device support)。
16位PCMCIA串行设备由这个驱动支持(8250/16550 PCMCIA device support)。记住,PCMCIA是一种通常使用于笔记本的PC卡。
可以设置最大数量支持的串口(Maximum number of 8250/16550 serial ports),接着是在启动中注册的最大数量(Number of 8250/16550 serial ports to register at runtime)。
为了扩展像HUB6的串行能力,启用这个驱动(Extended 8250/16550 serial driver options)。
一个特殊驱动用于支持多于4种的过时串口(Support more than 4 legacy serial ports)。
当启用这个驱动后,可以共享串口中断(Support for sharing serial interrupts)。
使用这个驱动可以自动检测串口中断请求(Autodetect IRQ on standard ports)。
RSA串口同样也在Linux内核中支持(Support RSA serial ports)。RSA代表的是"Remote Supervisor Adapter"(远程管理适配器)。RSA是一种IBM特定的硬件。
下面,有不同的供应商/设备特定驱动。
下面有一个使用printk输出用户信息的TTY驱动(TTY driver to output user messages via printk)。printk(print kernel)是一种通常打印启动信息的特殊软件。任何由printk显示的字符串通常在/var/log/messages文件里。shell命令"dmesg"显示所有被printk使用的字符串。
下面,我们可以启用/禁用并口打印机的支持(Parallel printer support)。
接下来的驱动允许打印机作为一个控制台(Parallel printer support)。这意味着内核消息会被逐字地由打印机打印。通常地在这个系列中使用"print"(打印)这个单词时,意味这将输出信息到屏幕上。而这次,字面上的意思是将数据输出在纸上。
以下的驱动使设备文件在/dev/parport/中(Support for user-space parallel port device drivers)。这使得一些进程可以访问。
再说一次,Linux内核有许多特性和驱动,所以我们还会在下一篇文章中继续讨论更多的驱动。谢谢!
致粉丝:我们正在接近配置过程的终点。我有一张你们很多人想知道的内核话题列表。这些话题包含了安装内核、管理模块、加入第三方驱动、还有许多其他有趣的建议和要求。
你好!这篇文章会覆盖不同的驱动。
首先"virtio console"是一种用于hypervisors的虚拟控制台驱动。
"IPMI top-level message handler"是用于IPMI系统的消息管理器。IPMI代表的是"Intelligent Platform Management Interface"(智能平台管理系统)。IPMI是一种不需要shell通过网络管理系统的接口。
"/dev/nvram support"允许系统读取和写入实时时钟的内存。通常上,这个特性用于在掉电时保存数据。
下面一个驱动支持Siemens R3964包驱动(Siemens R3964 line discipline)。这个是设备对设备协议
现在,我们可以进入PCMCIA字符设备驱动。然而,大多数这里的驱动是供货商/设备特定的。
原始块设备驱动允许块设备绑定到设备文件上/dev/raw/rawN(RAW driver (/dev/raw/rawN))。这么做的好处是高效的零拷贝。然而,大多数软件更偏好通过/dev/sd** 或者 /dev/hd**访问存储设备。
下面,可以设置支持的原始设备的最大数量。
下面的驱动可以生成设备文件/dev/hpet (HPET - High Precision Event Timer)。
注意:你们中很多人可能会想知道为什么要启用这些设备文件问题。好的,这些设备文件充当了一个软件和硬件之间的接口。
通过这个驱动可以映射HPET驱动(Allow mmap of HPET)。映射是一个生成设备和文件在内存中的地址列表。文件接着可以通过内存地址更快地找到并且接着指挥硬盘从地址中得到数据。
"Hangcheck timer"用于检测系统是否被锁定。这个定时器监视着锁定进程。当一个进程被冻结了,定时器就开启。当定时器停止后,如果进程还没有重启或者关闭,那么定时器会强迫进程关闭。
引用Linus Torvalds的话:可移植性是对于那些无法写新程序的人而言的。
使用Trusted Computing Group(可信赖计算组)规范的TPM安全芯片会需要这个驱动(TPM Hardware Support)。
现在,我们可以进入I2C设备。I2C代表的是"Inter-Integrated Circuit"(内部集成电路)并经常被成为"eye two see"。然而,一些人会说"eye squared see"。I2C是一种串行总线标准。
一些旧的软件将I2C适配器作为类设备,但是如今的软件不会这么做(Enable compatibility bits for old user-space)。所以,这个驱动会提供对旧软件的向后支持。
接下来,可以生成I2C设备文件(I2C device interface)。
I2C可以通过这个驱动提供复用支持(I2C bus multiplexing support)。
I2C可以通过这个驱动支持GPIO控制的复用(GPIO-based I2C multiplexer)。
对于开发者用这个驱动可以在I2C和SMBus上执行不同的测试(I2C/SMBus Test Stub)。
I2C系统启用这个特性可以生成调试信息(I2C Core debugging messages)。
下一个驱动生成额外的I2C调试信息(I2C Algorithm debugging messages)。
引用Linus Torvalds的话:Linux中没有原始设备的原因似乎我个人任何原始设备是一个愚蠢的注意。
下面的驱动会使I2C驱动生成调试信息(I2C Bus debugging messages)。
接下来,我们有串行外设接口(Serial Peripheral Interface)支持(SPI support)。SPi是一种用于SPI总线的同步串行协议。
在这之后,有一个驱动用于高速同步串行接口(High speed synchronous Serial Interface support)支持(HSI support)。HSI是一种同步串行协议。
PPS同样在Linux内核中支持(PPS support)。
"IP-over-InfiniBand"驱动支持IP包通过InfiniBand(译注:一种无限带宽技术)传输。
在这之后,有一个调试驱动用于IP-over-InfiniBand(IP-over-InfiniBand debugging)。
SCSI的RDMA协议同样可以通过InfiniBand传输(InfiniBand SCSI RDMA Protocol)。
这里同样有一种通过InfiniBand传输iSCSI协议的扩展(iSCSI Extensions for RDMA (iSER))。
有时候,错误发生在了整个系统必须知道的核心系统中(EDAC (Error Detection And Correction) reporting)。这个驱动发送核心给系统。通常地,这类底层错误由处理器中报告并接着由这个驱动让其他系统进程知道或者处理错误。
这个驱动提供了在老版本中的sysfs中使用的过时EDAC的支持(EDAC legacy sysfs)。
EDAC可以用来设置发送调试信息给Linux的日志系统(Debugging)。
引用Linus Torvalds的话:没有人可以第一次创造如此好的代码,除了我。
"Machine Check Exceptions"(机器检测异常)(MCEs)通过这个驱动被转化成可读的信息(Decode MCEs in human-readable form (only on AMD for now))。MCEs是由CPU检测到的硬件错误。MCEs通常触发内核错误。
将MCE解码成可读的形式的过程可以被注射用于测试错误处理(Simple MCE injection interface over /sysfs)。
下一个驱动允许错误在内存中被检测到并纠正(Main Memory EDAC (Error Detection And Correction) reporting)。
下面,还有很多用于特定设备组的检测和纠正错误的驱动。
引用Linus Torvalds的话:理论和实践有时会冲突。那这个发生时,理论输了。每次都是。
现在我们可以进入实时时钟("Real Time Clock")。这通常缩写为"RTC"。RTC一直跟随着时间。
下面的设定允许用户在Linux系统中使用RTC时间作为"挂钟"时间(Set system time from RTC on startup and resume)。这个挂钟是我们在桌面上或者通过"date"命令看到的时间。
另外,挂钟可以通过NTP服务器得到时间并与RTC同步(Set the RTC time based on NTP synchronization)。
一些系统有几个RTC,所以用户必须设置哪一个是默认 (RTC used to set the system time)。最好设置第一个(/dev/rtc0)为主时钟。
可以设置RTC系统的调试特性(RTC debug support)。
RTC可以使用不同的接口给予操作系统当前时间。使用sysfs会需要这个驱动(/sys/class/rtc/rtcN (sysfs)),而似乎用proc需要这个驱动 (/proc/driver/rtc (procfs for rtcN))。特殊的RTC字符设备可以生成并使用 (/dev/rtcN (character devices))。shell命令"hwclock"使用/dev/rtc,所以RTC字符设备。
下一个驱动允许在/dev接口上模拟RTC中断(RTC UIE emulation on dev interface)。这个驱动读取时钟时间并允许新的时间从/dev中检索。
RTC系统可以通过测试驱动测试(Test driver/device)。
下面,我们会讨论直接内存访问系统。DMA是硬件独立于处理器的内存访问过程。DMA增加的系统性能因为处理器将做得更少如果硬件自身做了更多的任务。不然,硬件会等待处理器完成任务。
这是调试DMA系统的调试引擎(DMA Engine debugging)。
接下来,有许多的供货商/设备特定驱动用于DMA支持。
一些DMA通过这个驱动支持大端读取和写入(Use big endian I/O register access)。
大端指的是二进制码的排列。英语国家的数字系统将数字的最大端放在左边。比如,数字17,最左的数字是放置十位的地方大于个位。在大端中,每字节最大的放在左边。字节有8位。比如:10110100。每一处都有相应的值128、64、32、16、8、4、2、1。所以提到的为被转换成十进制180。
DMA系统可以使用网络减小CPU使用(Network: TCP receive copy offload)。
"DMA Test Client"用于测试DMA系统。
下一篇文章中,我们会讨论显示/视频驱动。谢谢!
参考:Linus Torvalds的引用来自于:
你好!准备好阅读下一篇文章了么?在本篇中,我们将会讨论辅助显示。辅助显示是一些小的LCD屏幕;大多数小于或等于128x64。接着,我们会讨论用户空间IO驱动,一些虚拟驱动,Hyper-V,开发中驱动,IOMMU,和其他一些内核特性。
第一个配置辅助显示的驱动是"KS0108 LCD Controller"。KS0108 LCD Controller是由三星制造的图形控制器。
下面可以设置LCD并口地址(Parallel port where the LCD is connected)。第一个并口地址是0x378,下一个是0x278,第三个是0x3BC。这些不是地址唯一的选择。大多数人不需要改变这个。shell命令"cat /proc/ioports"会列出可用的并口和地址。
内核可以设置KS0108 LCD 控制器的写入延时到并口(Delay between each control writing (microseconds))。默认的值大部分是正确的,因此一般不需要更改。
"CFAG12864B LCD"屏幕是一块128x64,双色LCD屏幕。这块屏幕依赖于KS0108 LCD控制器。
可以改变这些LCD屏幕的刷新率(Refresh rate (hertz))。通常上,更高的刷新率会导致更多的CPU活动。这意味着一个缓慢的系统需要一个更低的刷新率。
设置完辅助显示后,接着设置"Userspace I/O drivers"。用户空间系统允许用户的应用和进程访问内核中断和内存地址。启用了它,一些驱动可以放在用户空间。
"generic Hilscher CIF Card driver"用于Profibus卡和Hilscher CIF卡。
"Userspace I/O platform driver"在用户空间创建通用驱动系统。
下一个驱动和上面的相同,但是增加IRQ处理(Userspace I/O platform driver with generic IRQ handling)。
下面的驱动又像前面的一个,但是增加了动态内存支持(Userspace platform driver with generic irq and dynamic memory)。
下面,是一些供应商/设备特性的驱动。
接着是一些通用PCI/PCIe卡驱动(Generic driver for PCI 2.3 and PCI Express cards)。
下面的驱动用于"VFIO support for PCI devices"。VFIO代表Virtual Function Input/Output(虚拟功能输入/输出)。VFIO允许设备直接以安全方式访问用户空间。
"VFIO PCI support for VGA devices"允许VGA通过VFIO被PCI支持。
接下来是virtio驱动。virtio是一个IO虚拟化平台。这个虚拟软件用于操作系统虚拟化。这在Linux系统上的虚拟机上运行一个操作系统时需要。
我们第一个可以配置的virtio驱动是"PCI driver for virtio devices"。这允许虚拟访问PCI
"Virtio balloon driver"允许虚拟系统的内存根据需要扩展或减少。通常上,没有人希望在需要内存的时候,虚拟系统保留它可能不会使用的内存。
下面的驱动允许内存映射到virtio设备(Platform bus driver for memory mapped virtio devices)。
如果Linux内核需要运行在微软的Hyper-V系统上,那么启用这个驱动(Microsoft Hyper-V client drivers)。这允许Linux能够成为Hyper的访客/客户端系统。
下面,我们会配置处于开发阶段的驱动。这些驱动正在开发当中,可能会变化很快,或者还没到Linux内核的质量标准。这个分类中的驱动只有Android驱动(在内核3.9.4中)。是的,Andorid使用Linux内核,这使得Andorid变成了一个Linux系统。然而,这仍然有争议。如果内核是用于Android,那么最好启用所有的驱动。
"Android Binder IPC Driver"提供了对于Binder的支持,它允许Andorid系统进程间相互通信。
下面可以启用ashmen驱动(Enable the Anonymous Shared Memory Subsystem)。Ashmem代表"Anonymous SHared MEMory"(虚拟内存共享)或者"Android SHared MEMory"(Andorid共享内存)。
"Android log driver"提供了完整的Andorid日志系统。
"Timed output class driver" 和 "Android timed gpio driver"允许Andorid系统操作GIP引脚并在超时后取消操作。
"Android Low Memory Killer"会在需要更多内存关闭进程。这个特性会杀死不再使用或活跃的任务。
"Android alarm driver"使内核在设定的间隔后唤醒。
在配置完开发阶段的驱动后,下面的驱动用于X86平台。这些驱动是 X86 (32-bit)的供应商/设备特定硬件。
下一个驱动是"Mailbox Hardware Support"。这个框架控制邮箱队列和硬件邮箱系统的中断信号。
"IOMMU Hardware Support"链接内存到能够使用DMA的设备上。IOMMU增强了DMA。IOMMU映射地址并阻止故障设备访问内存。IOMMU同样允许硬件访问比没有IOMMU更多内存。
"AMD IOMMU support"提供了对AMD设备更好的IOMMU支持。
对于AMD IOMMU支持存在调试特性(Export AMD IOMMU statistics to debugfs)。
存在一个对于AMD硬件的更新版本的IOMMU驱动(AMD IOMMU Version 2 driver)。
Linux内核同样支持对Intel设备的IOMMU驱动支持(Support for Intel IOMMU using DMA Remapping Devices)。
一些设备可能会接受不同的电压和时钟频率。这个驱动允许操作系统控制设备的电压输出和时钟频率(Generic Dynamic Voltage and Frequency Scaling (DVFS) support)。启用了这个驱动,可以启用下面的那些对于电源/性能管理特性。
"Simple Ondemand"就像上面的,但是只会基于设备活动改变时钟频率。通常上,更多的活动意味着设备需要更快的时钟速率来使用更多的资源需求。
"Performance"允许系统设置最高支持的时钟速度以满足最好的性能。这会增加电源消耗。
"Powersave"会设置时钟频率到最低以节约电源。
"Userspace"允许用户空间设置时钟频率。
"External Connector Class (extcon) support"使得用户空间可以监视外部连接器如USB和AC口。这允许应用了解是否插入了线缆。用户几乎都希望启用这个。如果任何人由于某个合理的理由禁用了它,请告诉我们为什么这么做。
"GPIO extcon support"驱动就像上面的驱动,但是它只对于GPIO管脚。
接下来是不同的供货商/设备特定的内存控制器(Memory Controller drivers)。内存芯片控制器可能是独立的设备或者内置在内存芯片上。这些控制器管理这输入和输出的数据流。
"Industrial I/O support"驱动提供了标准的传感器接口而不管总线的类型(像PCIe、spi、GPIO等等)。IIO是"Industrial I/O support"(工业IO)的通用缩写。
Linux内核提供了大量不同的加速器、放大器模数转换器、惯性测量单元、光敏传感器、磁场传感器和其他许多传感器和转换器的支持。
"Intel Non-Transparent Bridge support"驱动支持连接到系统的PCIe硬件桥。所有到映射内存的写入会镜像到两个系统中。
"VME bridge support"和上面的相同除了桥使用的是VME,这是一个不同的总线标准。
"Pulse-Width Modulation (PWM) Support"通过调节从这些设备收到的平均功率调节背光灯和风扇速度。
"IndustryPack bus support"提供了对IndustryPack总线标准的支持。
来源:https://blog.csdn.net/ffmxnjm/article/details/72933915