大数据ETL实践探索(1)---- python 与oracle数据库导入导出
文章大纲
- 大数据ETL 系列文章简介
- ETL 简介
- 1. oracle数据泵 导入导出实战
- 1.1 数据库创建
- 1.2. installs Oracle
- 1.3 export / import data from oracle
- 2. 将数据库表导出成 CSV, 并批量上传至 AWS
- 2.1 export all table to CSV
- 3. python 与oracle 交互
- 4. oracle table-视图 windows 批处理 导出
- 4.1 使用win32 脚本调用sqlplus 导出视图
- 4.2 使用python 执行视图导出
- 参考
大数据ETL 系列文章简介
本系列文章主要针对ETL大数据处理这一典型场景,基于python语言使用Oracle、aws、Elastic search 、Spark 相关组件进行一些基本的数据导入导出实战,如:
- oracle使用数据泵impdp进行导入操作。
- aws使用awscli进行上传下载操作。
- 本地文件上传至aws es
- spark dataframe录入ElasticSearch
等典型数据ETL功能的探索。
系列文章:
1.大数据ETL实践探索(1)---- python 与oracle数据库导入导出
2.大数据ETL实践探索(2)---- python 与aws 交互
3.大数据ETL实践探索(3)---- pyspark 之大数据ETL利器
4.大数据ETL实践探索(4)---- 之 搜索神器elastic search
5.使用python对数据库,云平台,oracle,aws,es导入导出实战
6.aws ec2 配置ftp----使用vsftp
7.浅谈pandas,pyspark 的大数据ETL实践经验
ETL 简介
ETL,是英文 Extract-Transform-Load 的缩写,用来描述将数据从来源端经过抽取(extract)、交互转换(transform)、加载(load)至目的端的过程。
之前有一段时间一直在使用python 与oracle 进行交互,具体内容参见:
windows下python3 使用cx_Oracle,xlrd插件进行excel数据清洗录入
可以说使用python 不但能够在后期的数据分析进行相当多的工作,而且可以针对前面大数据的相关组件进行一个有效的整合。在一个初创型的公司来讲,分析团队和数据团队可以有效结合,进行代码复用,并高效运转。
1. oracle数据泵 导入导出实战
1.1 数据库创建
本文主要使用最新版本的oracle 12c,如果创建oracle数据库时候使用了数据库容器(CDB)承载多个可插拔数据库(PDB)的模式,那么数据库的用户名需要用c##开头,使用数据泵进行操作 的时候也有一些不同:
在CDB中,只能创建以c##或C##开头的用户,如果不加c##,则会提示错误“ORA-65096:公用用户名或角色名无效”,只有在PDB数据库中才能创建我们习惯性命名的用户,oracle称之为Local User,前者称之为Common User。
创建的时候不要勾选:
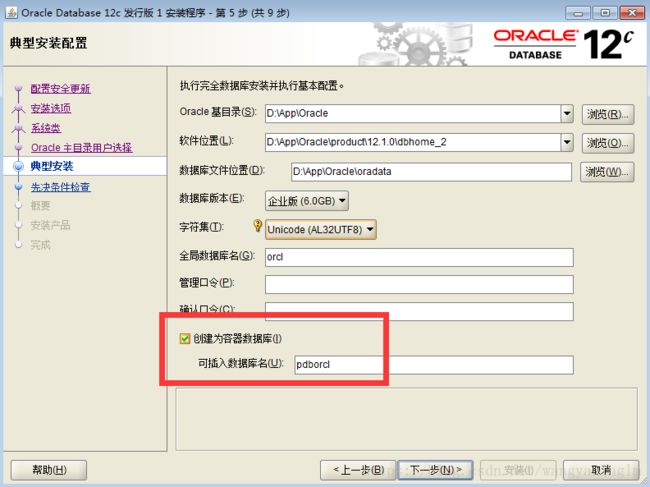
https://www.cnblogs.com/xqzt/p/5034261.html
https://www.cnblogs.com/fanyongbin/p/5699482.html
1.2. installs Oracle
Download and install Oracle 12C,
Http://www.oracle.com/technetwork/database/enterprise-edition/downloads/index.html
Under windows10, use sqlplus to log in
you should first
set oracle_sid=orcl
Sqlplus /nolog
conn /as SYSDBA
Creating a user
Syntax [creating the user]:
create user username identified by password [that is the password];
E.g.
Create user [username] identified by [password];
Default tablespace [tablespacename]
Temporary tablespace temp;
Grant DBA to username;
.
由于全库导入的时候oracle_home和之前的数据库发生了改变,所以原来数据库的表空间需要提前建立。可以根据导出日志或者导入日志的报错,查看原来数据库中到底有那些表空间。特别注意有关视图和索引的表空间和用户也需要提起建立好。当然如果你只要数据的话就不太影像了。基本上使用表空间就可以全部导入。
Create table space :
E.g
Create tablespace xxx datafile'f:\xxx.dbf'size 200M AUTOEXTEND on;
1.3 export / import data from oracle
从oracle库中导出 数据可以使用oracle数据泵程序,全库导出实例如下:
Expdp username/password FULL=y DUMPFILE=dpump_dir1:full1%U.dmp, dpump_dir2:full2%U.dmp
FILESIZE=2G PARALLEL=3 LOGFILE=dpump_dir1:expfull.log JOB_NAME=job
以下命令的导入并不是全库导入,如果需要全库导入的话,由于oracle_home 的改变,需要提前建立好用户和表空间,以及索引的表空间,视图的用户等
command as follow:
Impdp username/password@orcl full=y directory=dir_yiliao dumpfile=full1%U.dmp remap_schema=username_old:username_new exclude=GRANT remap_tablespace='(t1:tempt1, t2:tempt2) ' tablespaces=tempt1,temp2
以下两种导入方式只能二选一:
- full=y
- tablespaces=tempt1,temp2
整体说明
https://www.2cto.com/database/201605/508212.html
2. 将数据库表导出成 CSV, 并批量上传至 AWS
2.1 export all table to CSV
使用oracle函数 utl_file 进行快速导入导出(一分钟300万条的量级),这个比spool快多啦
CREATE OR REPLACE PROCEDURE SQL_TO_CSV
(
P_QUERY IN VARCHAR2, -- PLSQL文
P_DIR IN VARCHAR2, -- 导出的文件放置目录
P_FILENAME IN VARCHAR2 -- CSV名
)
IS
L_OUTPUT UTL_FILE.FILE_TYPE;
L_THECURSOR INTEGER DEFAULT DBMS_SQL.OPEN_CURSOR;
L_COLUMNVALUE VARCHAR2(4000);
L_STATUS INTEGER;
L_COLCNT NUMBER := 0;
L_SEPARATOR VARCHAR2(1);
L_DESCTBL DBMS_SQL.DESC_TAB;
P_MAX_LINESIZE NUMBER := 32000;
BEGIN
--OPEN FILE
L_OUTPUT := UTL_FILE.FOPEN(P_DIR, P_FILENAME, 'W', P_MAX_LINESIZE);
--DEFINE DATE FORMAT
EXECUTE IMMEDIATE 'ALTER SESSION SET NLS_DATE_FORMAT=''YYYY-MM-DD HH24:MI:SS''';
--OPEN CURSOR
DBMS_SQL.PARSE(L_THECURSOR, P_QUERY, DBMS_SQL.NATIVE);
DBMS_SQL.DESCRIBE_COLUMNS(L_THECURSOR, L_COLCNT, L_DESCTBL);
--DUMP TABLE COLUMN NAME
FOR I IN 1 .. L_COLCNT LOOP
UTL_FILE.PUT(L_OUTPUT,L_SEPARATOR || '"' || L_DESCTBL(I).COL_NAME || '"'); --输出表字段
DBMS_SQL.DEFINE_COLUMN(L_THECURSOR, I, L_COLUMNVALUE, 4000);
L_SEPARATOR := ',';
END LOOP;
UTL_FILE.NEW_LINE(L_OUTPUT); --输出表字段
--EXECUTE THE QUERY STATEMENT
L_STATUS := DBMS_SQL.EXECUTE(L_THECURSOR);
--DUMP TABLE COLUMN VALUE
WHILE (DBMS_SQL.FETCH_ROWS(L_THECURSOR) > 0) LOOP
L_SEPARATOR := '';
FOR I IN 1 .. L_COLCNT LOOP
DBMS_SQL.COLUMN_VALUE(L_THECURSOR, I, L_COLUMNVALUE);
UTL_FILE.PUT(L_OUTPUT,
L_SEPARATOR || '"' ||
TRIM(BOTH ' ' FROM REPLACE(L_COLUMNVALUE, '"', '""')) || '"');
L_SEPARATOR := ',';
END LOOP;
UTL_FILE.NEW_LINE(L_OUTPUT);
END LOOP;
--CLOSE CURSOR
DBMS_SQL.CLOSE_CURSOR(L_THECURSOR);
--CLOSE FILE
UTL_FILE.FCLOSE(L_OUTPUT);
EXCEPTION
WHEN OTHERS THEN
RAISE;
END;
/
创建数据库目录
sql>create or replace directory OUT_PATH as 'D:\';
运行以下sql
---- 导出单个表
SELECT 'EXEC sql_to_csv(''select * from ' ||T.TABLE_NAME ||''',''OUT_PATH''' || ',''ODS_MDS.' || T.TABLE_NAME ||'.csv'');' FROM user_TABLES T where t.TABLE_NAME='表名'
---- 导出行数大于0 的表
SELECT 'EXEC sql_to_csv(''select * from ' ||T.TABLE_NAME ||''',''OUT_PATH''' || ',''' || T.TABLE_NAME ||'.csv'');' FROM user_TABLES T where T.num_rows >1
得到以下的批量sql,导出来,生成.sql脚本,在命令行中执行即可.
EXEC sql_to_csv('select * from table1','OUT_PATH','table1.csv');
EXEC sql_to_csv('select * from table2','OUT_PATH','table2.csv');
For reference, the links are as follows
Https://blog.csdn.net/huangzhijie3918/article/details/72732816
3. python 与oracle 交互
cx_oracle 的安装
windows10,redhat6.5下python3.5.2使用cx_Oracle链接oracle
其实主要的要点是,不管是windows 平台还是linux 平台,首要任务是安装好oracle client
4. oracle table-视图 windows 批处理 导出
4.1 使用win32 脚本调用sqlplus 导出视图
输入年月等信息,拼接字符串导出表, 下面 的脚本可以循环接受输入
@echo off
:begin
::年份
set input_year=
set /p input_year=Please input year :
::月份
set input_month=
set /p input_month=Please input month :
::字符串前缀
set prefix=ex_vw_
::字符串拼接
set "table_name=%prefix%%input_year%%input_month%"
echo Your input table_name:%table_name%
echo Your input time:%input_year%-%input_month%
::sqlplus 执行sql脚本 后带参数
sqlplus username/password@ip/instanceNname @createtable.sql %table_name% %input_year%-%input_month%
rem pause>null
goto begin
以下sql脚本为createtable.sql,接受两个参数,写做:&1 ,&2 …如果多个参数可以依次写下去。
drop table &1;
create table &1 as select * from some_table_view where incur_date_from = to_date('&2-01','yyyy-mm-dd');
Insert into &1 select * from some_table_view where incur_date_from = to_date('&2-02','yyyy-mm-dd');
commit;
quit;
后来发现一个问题,比如上面的第2小节的存储过程 SQL_TO_CSV,死活没法成功执行,只好安装cx_oracle ,用python 导出了,代码如下。
4.2 使用python 执行视图导出
主要逻辑是,按照月份 ,执行视图生成这个月每天的数据插入到表中,当一个月的数据执行完毕,将这个月份表导出。
类似这种流程化的东西,python果然还是利器
# -*- coding:utf-8 -*-
"""@author:season@file:export_view.py@time:2018/5/211:19"""
import cx_Oracle
import calendar
########################链接数据库相关######################################
def getConnOracle(username,password,ip,service_name):
try:
conn = cx_Oracle.connect(username+'/'+password+'@'+ip+'/'+service_name) # 连接数据库
return conn
except Exception:
print(Exception)
#######################进行数据批量插入#######################
def insertOracle(conn,year,month,day):
yearandmonth = year + month
table_name ='ex_vw_'+ yearandmonth
cursor = conn.cursor()
##创建表之前先删除表
try:
str_drop_table = '''drop table ''' + table_name
cursor.execute(str_drop_table)
except cx_Oracle.DatabaseError as msg:
print(msg)
try:
#create table and insert
str_create_table = '''create table ''' + table_name+ ''' as select * from EXPORT where date_from = to_date(' '''+ year + '-'+ month + '''-01','yyyy-mm-dd')'''
print(str_create_table)
cursor.execute(str_create_table)
for i in range(2,day):
if i < 10:
str_incert = '''Insert into ''' + table_name +''' select * from EXPORT where date_from = to_date(' '''+ year+'-'+month+'-'+str(0)+str(i)+'''','yyyy-mm-dd')'''
else:
str_incert = '''Insert into ''' + table_name + ''' select * from EXPORT where date_from = to_date(' '''+ year+'-'+month+'-'+ str(i)+'''','yyyy-mm-dd')'''
print(str_incert)
cursor.execute(str_incert)
conn.commit()
conn.commit()
#export big_table
str_QUERY = 'select * from ex_vw_'+ yearandmonth
str_DIR = 'OUT_PATH'
str_FILENAME = 'EXPORT'+yearandmonth+'.csv'
cursor.callproc('SQL_TO_CSV', [str_QUERY,str_DIR, str_FILENAME])
except cx_Oracle.DatabaseError as msg:
print(msg)
#导出数据后drop table
try:
str_drop_table = '''drop table ''' + table_name
print(str_drop_table)
cursor.execute(str_drop_table)
except cx_Oracle.DatabaseError as msg:
print(msg)
cursor.close()
def main():
username = 'xxx'
password = 'xxx'
ip = '127.0.0.1'
service_name = 'orcl'
#获取数据库链接
conn = getConnOracle(username,password,ip,service_name)
monthlist = ['06','05','04','03','02','01']
daylist = [30,31,30,31,28,31]
for i in range(0,len(monthlist)):
insertOracle(conn,'2018',monthlist[i],daylist[i]+1)
conn.close()
if __name__ == '__main__':
main()
参考
OS.ENVIRON详解
python编码
再次强烈推荐,精通oracle+python系列:官方文档
http://www.oracle.com/technetwork/cn/articles/dsl/mastering-oracle-python-1391323-zhs.html
离线版本下载链接:
http://download.csdn.net/detail/wangyaninglm/9815726