导读
随着Hadoop出现以及与其相关的众多分布式计算软件的诞生,构筑了海量数据处理底层技术支持,海量数据计算才逐渐成为可能,并在近几年风靡全球,不管是已经拥有大量数据的成熟企业,还是以往对数据不够重视的企业,都开始追逐海量数据,挖掘数据中的价值,为己所用。企业对于数据价值高度重视和新的要求,加速了Hadoop生态圈进一步地衍生和发展。本文主要介绍Hadoop生态圈、海量数据计算应用以及目前面临的问题。
- Hadoop是什么
- 大数据批处理计算
- 大数据流式计算
- 大规模数据分析系统
Hadoop是什么
现在说起 Hadoop 这个名词,经过近几年的大热,广泛地宣传和应用,在IT圈里已经是家喻户晓,每个人都能从各自角度或多或少 地描述自己心里的Hadoop,“Hadoop 是分布式计算平台”、“大数据存储和计算”、“MapReduce计算框架”等。
一千个人心中,就有一千个哈姆雷特。那什么是 Hadoop?Hadoop 严格的定义:“The Apache Hadoop software library is a framework that allows for the distributed processing of large data sets across clusters of computers using simple programming models.”(拙译:Hadoop是一个使用简单编程模型分布式地处理在多个服务器集群上的海量数据的框架。),然而Hadoop经过多年的发展和使用,现在不单单代表上述的定义,广义上指的是 Hadoop 整个生态圈(例如 Hive,Hbase,Spark,Sqoop,Zookeeper,Mahout,Pig,Ambari 等),而并不仅是特指 Hadoop。
Hadoop 包括以下模块:
- Hadoop Common:支持其他 Hadoop 模块的公用工具。
- Hadoop Distributed File System:一个提供访问应用数据的高吞吐能力的分布式文件系统。
- Hadoop YARN:一个为作用调度和集群资源管理的框架。
- Hadoop MapReduce:一个基于YARN的海量数据集并行处理系统。
Hadoop Ecosystem(Hadoop 生态圈)

大数据批处理计算
上面我们介绍了 MapReduce 是 Hadoop 的主要并行计算模块(编程模型)。MapReduce设计之初的主要任务和目标是完成大数据的批处理模式,MapReduce是一个单输入、分两个阶段(Map和Reduce)的数据处理流程,因此在处理一个复杂的任务,在编程模型上就会受限,无法通过一次任务或作业的提交完成整个工作流程,复杂的数据处理任务,需要多个 MapReduce 完成,在这个过程中,数据会多次的从 HDFS 上读取,写入中间数据,之后的 MapReduce 再从 HDFS 上读取数据,这也是为什么 Hadoop 运行慢的一部分原因。因此对于实时性要求不高的数据处理需求,通过 Hadoop 的 MapReduce 框架可以很好的支持。但对于事件驱动或近实时的数据处理需求,则需要采用流式计算框架。Hadoop主要的两个核心模块是HDFS和MapReduce,下面分别介绍一下这两个模块的工作原理。
HDFS(Hadoop Distributed File System)工作过程
HDFS 是 Google 的 GFS 的开源版本,与其他分布式文件系统有许多相似之处,然而也有很明显的差别。HDFS 被设计可以运行在低成本硬件上,拥有高度的容错能力。HDFS 对于海量应用数据有很高的吞吐能力。HDFS 采用 master/slave 架构,一个 HDFS 集群包含一个 NameNode,多个 DataNodes。NameNode 做为 master 管理文件系统的命名空间和调控客户端对文件的访问;在集群上的每个物理节点通常有一个DataNode,其负责在这个物理节点上的存储。通过 HDFS API 用户可以访问一个文件系统的命名空间,并且允许用户把数据存储在集群上。在内部,一个文件被分割成多个数据块,这些块被存储在一组 DataNode 上。NameNode 负责执行文件操作,例如文件的打开、关闭和重命名等,也决策数据块和许多 DataNodes 之间的映射关系。DataNode 负责来自于文件系统客户端的读和写的请求。DataNode 负责执行来自 NameNode 的指令,担负着数据块的创建、删除和副本创建工作。
HDFS 架构图:

MapReduce 工作过程
MapReduce 在计算和处理任务时采用分而治之的策略,把一个工作分成两个阶段,Mapping(映射)和 Reducing (化简),有些工作并不需要Reducing阶段,但至少要有Mapping阶段。举一个简单的例子来理解 MapReduce 工作过程,上学的时候经常要考试,老师对一个100人的班的考试卷进行打分,最终要计算出全班的平均分,这里面有两个任务,一个是对考试卷进行打分,另一个任务是计算平均分。我们先来看第一个任务,假设给一个考试卷打分的平均时间是5分钟,需要500分钟完成这个工作,那如何快速的完成这项工作?多找几个小伙伴一起来打分,把100份卷子分给到5个老师,假设是平均分配,并且打分的平均时间还是5分钟,那么需要100分钟就可以完成这项工作,打分工作就是Mapping要做的事情,之后计算全班的平均分工作,每个老师只需要数一下自己手里的卷子的总分和份数,并给某一个老师进行汇总计算,最终完成这两项工作。
MapReduce 大概过程:
- 给5个老师分配卷子
- 让每个老师进行打分,并各自数一下卷子的份数和总分
- 把所有老师的结果汇总在一起,计算最终结果
Hadoop MapReduce 数据处理过程

大数据流式计算
随着分布式计算技术发展和演进,企业或组织不单单仅关注分布式技术的稳定性和扩展性,对高吞吐和实时性有了进一步的要求,尤其是在已有的事件或消息驱动的业务场景上,目前已有许多实时或接近实时地处理大数据的分布式框架,本文主要介绍 Apache 体系内的三款产品:Storm、Spark和Samza。
Apache Storm
一个 Storm 集群表面上与 Hadoop 集群非常相似。例如你在 Hadoop 运行 MapReduce jobs,在 Storm 你运行的是 “topologies”。“Jobs”与“topologies”有一个主要的区别,MapReduce job 最终会结束,然而一个 topology 一直运行处理到来的消息,除非你手动终止它。
一个 Storm 集群有两种节点,一个 master 节点和一些 worker 节点,主节点运行一个守护进程称为“Nimbus”,类似 Hadoop 的“JobTracker”。Nimbus 是负责在集群上分发代码,分配任务和监控失效。每个工作节点运行一个守护进程称为“Supervisor”。Supervisor 监听 Nimbus 分配给它的工作任务,并启动和停止工作进程处理任务。每个 worker 进程执行 topology 的一个子集。
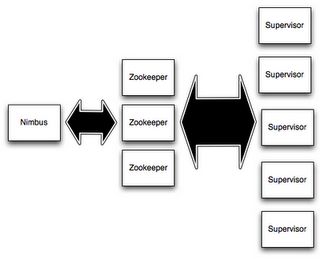
在 Nimbus 与 Supervisors 之间的所有协作通过一个 Zookeeper 集群完成,他们的状态信息保存在 Zookeeper 或本地文件中。这一机制保证了 Storm 集群的稳定性。
一个 Topology 有许多 spout 和 bolt 构成,一个 spout 是一个消息流的源,例如一个 spout 可以从 kafka 中消费某个主题的消息,然后把消息当做 stream 发送。一个 bolt 消费任意数量的输入流,做一些处理之后,发送到下一个环节。下面是一个简单 Topology 图:

Apache Spark
Apache Spark 是一个快速和多种用途的计算集群系统。提供了一组高级的工具,包括支持 SQL 和结构化数据处理的 Spark SQL、支持机器学习的 MLLib、支持图处理的 GraphX 和 支持流式计算的Spark Streaming 组件。本文主要介绍 Spark Streaming,一种支持可扩展、高吞吐和高可用的流式处理系统。Spark Streaming 可以与多种系统结合。包括 Kafka、Flume、Twitter、ZeroMQ、HDFS 和 Databases 等。

在 Spark Streaming 内部,按照下图工作。接收在线输入数据流,然后将数据分割成许多批,每批的数据被 Spark engine 处理产生成批的结果数据流。

Apache Samza
Apache Samza 一个分布式流式处理框架。使用 Apache Kakfa 为其提供消息处理,并且使用 Apache Hadoop YARN 为其提供容错、处理器隔离、安全性和资源管理功能。Apache Samza 相对上面两款产品还是比较陌生,不为人们所熟知的,下面介绍一下 Samza 主要概念。
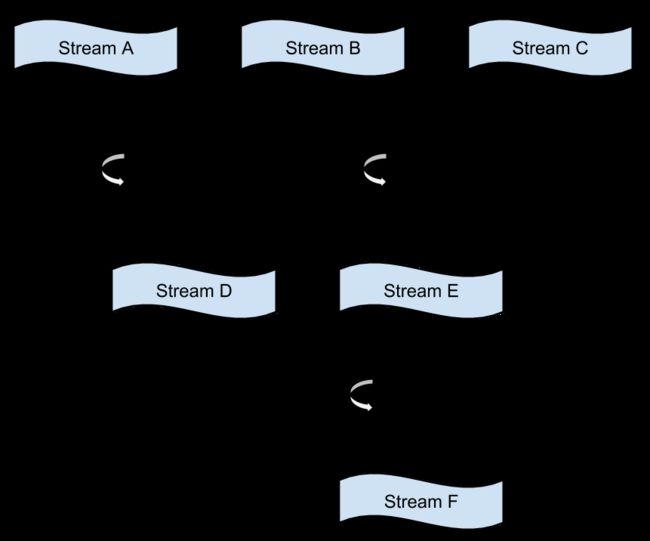
Samza 处理数据流(streams),一个 stream 由许多不可改变的相同类型或类别的消息组成。例如,一个 stream 可以定义为一个网站上的所有点击行为,或者一个数据库表的所有更新操作,或者服务端产生的日志,或者其他类型的事件数据。消息能被加入到 stream ,或者从一个 stream 中读取.一个 stream 可以有任意数量的消费者,并且可以从 stream 中读取消息而无需删除消息。Samza 支持实现 stream 抽象概念的插入式系统:在 Kafka 内,一个 stream 是一个 topic,在一个数据库内,我们能读取一个 stream 通过消费来源一个表的更新,在 Hadoop 上,我们可以 tail HDFS上的某一个文件目录。
大规模数据分析系统建设
企业数据每天在以T级别数量增长,并且随着业务的拓展,数据量加速增长趋势尤为明显,数据主要由用户在网站上行为过程产生,包括用户页面浏览、搜索、查看详情页、预约和状态变更等数据,以及业务系统中邀约、客服沟通记录、企业信息等数据。涉及到多种异构数据源和大规模的数据量,如何在这个背景下建立准确、稳定和快速的数据分析系统,及时反馈线上和下线各系统数据指标,尤为重要和富有挑战,因此在搭建数据分析系统,在系统设计初期,尽可能考虑和论证系统技术架构和选型。
系统目标:
- 支撑目前每日T级数据处理能力,并且能快速扩展。
- 支持海量数据的实时或准实时统计和分析。
- 适应多种大规模计算场景。
- 可视化报表系统。
- 提供通用数据API。
目前数据分析系统架构:
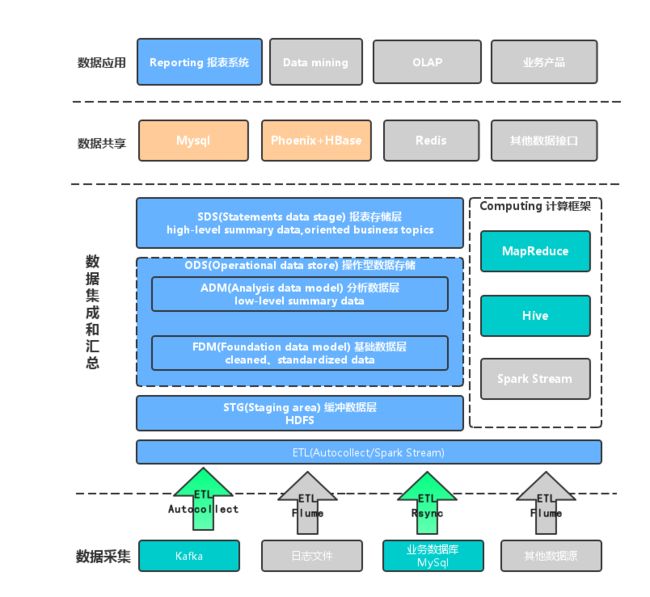
整个系统架构分为4个层次,包括数据采集层、数据集成与汇总层、数据共享层和数据应用层:
- 数据采集层:数据可以来源于多种异构数据源,例如消息队列Kafka、日志文件和数据库等。
- 数据集成和汇总层:不同应用场景和数据实时性要求,数据集成和处理分成两条线,一条是批处理计算,基于数据仓库概念建立数据模型,另一条是采用流式计算框架,满足准实时数据分析的需求。
- 数据共享层:最终的结果数据可以存储在传统的DB,也可以是NOSQL存储产品,例如HBase和Redis,数据的访问依赖于通用API。
- 数据应用层:多种维度和指标通过报表系统可视化查询和展现;支持在线数据数据操作和分析,并可以对底层数据进行数据挖掘操作。