Redis教程(五)——RedisCluster配置
终于到了Redis实际生产过程中的重头戏——Redis Cluster,之前介绍的都是Redis的基础知识和提供的功能,我们可以基于之前学习到的功能搭建一个简单的基于Redis的缓存方案,并且具有10w+左右的并发量,但是在大型的电商活动中,这样的缓存并不能解决我们的实际需要,并且自行搭建的Redis支持的并发可能会出现一些意料不到的问题,去维护也是需要很高的人力成本。对此,Redis官方提供了Redis的集群方案——Redis Cluster,今天我们就来了解下Redis Cluster。
Redis Cluster
按照惯例,我们还是先整理下Redis Cluster的一些基本情况,带着问题去学习Redis Cluster
- 什么是Redis Cluster? 主要是为了解决什么样的问题?
- Redis Cluster该如何搭建?
- Redis Cluster的优缺点
- Redis Cluster怎么去扩容支持更高的QPS
- Redis Cluster的原理
- Redis Cluster出现的一些问题和解决方案
Redis Cluster介绍
Redis Cluster是Redis官方在3.0以后的版本中对于Redis高可用,高并发的一种解决方案。
该方案集成了一下几个特点
- 自动集成了Master和Slave赋值和读写分离
- 自动支持master+slave的高可用(主备切换)
- 支持多个master的hashslot,支持数据分布式存储
在讲解Redis Cluster前我们首先需要了解几个基础性的概念
Redis的hash值
Redis的集群没有使用跟数据库分库分表同样的一致性hash,而是引入了hashslot的概念。
Redis 集群有16384个哈希槽,每个key通过CRC16校验后对16384取模来决定放置哪个槽.集群的每个节点负责一部分hash槽,举个例子,比如当前集群有3个节点,那么:
节点 A 包含 0 到 5500号哈希槽.
节点 B 包含5501 到 11000 号哈希槽.
节点 C 包含11001 到 16384号哈希槽.
这种结构很容易添加或者删除节点. 比如如果我想新添加个节点D, 我需要从节点 A, B, C中得部分槽到D上. 如果我想移除节点A,需要将A中的槽移到B和C节点上,然后将没有任何槽的A节点从集群中移除即可. 由于从一个节点将哈希槽移动到另一个节点并不会停止服务,所以无论添加删除或者改变某个节点的哈希槽的数量都不会造成集群不可用的状态.
Redis一致性保证
Redis不能保证数据的强一致性,这意味着在实际中可能存在丢失写操作的问题。
Redis搭建集群
根据我们之前的《Redis安装》,然后搭建三个master的Redis的运行环境和三个slave的redis运行环境。
Redis创建实例并启动
规划操作环境和角色分配
| IP | PORT |
|---|---|
| 192.168.56.105 | 7001 |
| 192.168.56.105 | 7002 |
| 192.168.56.106 | 7003 |
| 192.168.56.106 | 7004 |
| 192.168.56.107 | 7005 |
| 192.168.56.107 | 7006 |
文件夹创建
## 存放 redis-cluster的配置文件(由系统自主维护)
mkdir -p /etc/redis-cluster
## 存放 redis的日志
mkdir -p /var/log/redis
## 存放 redis的pid文件(由系统自主维护) 按照规划对应的端口号进行创建
mkdir -p /var/redis/7001
由于多个redis的配置文件都是大同小异的,我们将所有需要更改的配置项提取出来,可以从redis的安装目录获取原生的redis.conf来进行修改,以免出现以前配置过的脏配置
## redis实例的端口号 按照规划对应的端口号进行修改
port 7001
## 支持cluster
cluster-enabled yes
## cluster的配置文件 按照规划对应的端口号进行修改
cluster-config-file /etc/redis-cluster/node-7001.conf
## cluster节点失效时间
cluster-node-timeout 15000
## 是否后台启动
daemonize yes
## redis实例的pid文件 按照规划对应的端口号进行修改
pidfile /var/run/redis_7001.pid
## redis目录 按照规划对应的端口号进行修改
dir /var/redis/7001
## redis的日志 按照规划对应的端口号进行修改
logfile /var/log/redis/7001.log
# 非保护模式
protected-mode no
## 开启AOF持久化
appendonly yes
说明:在每个ip上分别创建 上述的文件夹,注意按照规划对应的端口号进行创建,在本机中维护7001、7002、7003、7004、7005、7006对应的redis的配置文件:
- 上传到每台机器上的
/etc/redis文件夹下,- 然后分别
cp /usr/local/redis-5.0.5/utils/redis_init_script /etc/init.d/redis_7001,注意按照规划来修改文件名- 修改
redis_7001中的REDISPORT对应的值为7001,注意按照规划来修改端口号- 注意给创建的配置文件和启动文件授权
chmod -R 777 redis_7001
注意检查文件夹和配置文件以及启动文件是否存在并且配置正确
配置文件中 protected-mode为no,并且一定要注释掉 bind,亲测这两个添加上,集群不成功
创建好了 我们来启动所有的redis的实例,并且检查是否启动成功
## 启动
cd /etc/init.d
## 按照规划的端口,依次启动redis
./redis_7001 start
## 启动完成之后 看看日志是否成功启动,该路径下依次查看是否都是已经成功
cd /var/log/redis
cat 7001.log
以上我们就完成了六个redis实例的安装和启动,接下来我们将构建redis集群
Redis搭建集群
现在我们已经有了六个正在运行中的 Redis 实例, 接下来我们需要使用这些实例来创建集群, 并为每个节点编写配置文件。
通过使用 Redis 集群命令行工具 redis-trib , 编写节点配置文件的工作可以非常容易地完成: redis-trib 位于 Redis 源码的 src 文件夹中, 它是一个 Ruby 程序, 这个程序通过向实例发送特殊命令来完成创建新集群, 检查集群, 或者对集群进行重新分片(reshared)等工作。
Redis5.x版本已经不需要了对ruby的依赖,并且搭建集群的语法也有了改变,采用了redis-cli --cluster create…
## 进入到src目录下
cd /usr/local/redis-5.0.0/src
## 搭建集群
redis-cli --cluster create 192.168.56.105:7001 192.168.56.105:7002 192.168.56.106:7003 192.168.56.106:7004 192.168.56.107:7005 192.168.56.107:7006 --cluster-replicas 1
上述这个命令在这里用于创建一个新的集群, 选项--cluster-replicas 1 表示我们希望为集群中的每个主节点创建一个从节点。
之后跟着的其他参数则是这个集群实例的地址列表,3个master3个slave redis-trib 会打印出一份预想中的配置给你看, 如果你觉得没问题的话, 就可以输入 yes , redis-trib 就会将这份配置应用到集群当中,让各个节点开始互相通讯,最后可以得到如
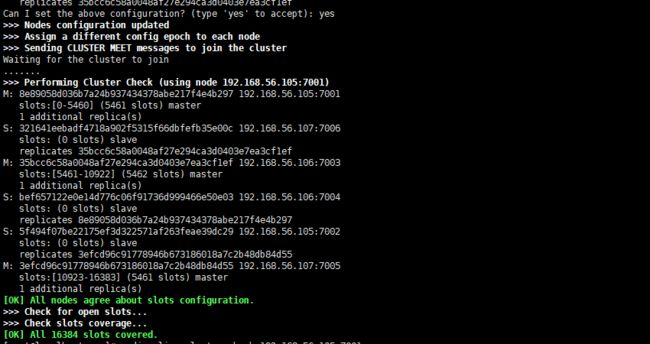
分配之后的主从配置如下:
| 角色 | IP | PORT | Master |
|---|---|---|---|
| Master | 192.168.56.105 | 7001 | |
| Slave | 192.168.56.105 | 7002 | 107:7005 |
| Master | 192.168.56.106 | 7003 | |
| Slave | 192.168.56.106 | 7004 | 105:7001 |
| Master | 192.168.56.107 | 7005 | |
| Slave | 192.168.56.107 | 7006 | 106:7003 |
安装完成之后,我们检查
redis-cli --cluster check 192.168.56.105:7001
Redis cluster操作
- 实验多master写入 -> 海量数据的分布式存储
你在redis cluster写入数据的时候,其实是你可以将请求发送到任意一个master上去执行,但是,每个master都会计算这个key对应的CRC16值,然后对16384个hashslot取模,找到key对应的hashslot,找到hashslot对应的master, 如果对应的master就在自己本地的话,set mykey1 v1,mykey1这个key对应的hashslot就在自己本地,那么自己就处理掉了,但是如果计算出来的hashslot在其他master上,那么就会给客户端返回一个moved error,告诉你,你得到哪个master上去执行这条写入的命令
什么叫做多master的写入,就是每条数据只能存在于一个master上,不同的master负责存储不同的数据,分布式的数据存储
- 实验不同master各自的slave读取 -> 读写分离
- 在这个redis cluster中,如果你要在slave读取数据,那么需要带上readonly指令,get mykey1
- redis-cli -c启动,就会自动进行各种底层的重定向的操作
- 实验自动故障切换 -> 高可用性
redis-cli --cluster check 192.168.56.105:7001
比如把master1,105:7001,杀掉,看看它对应的106:7004能不能自动切换成master,可以自动切换
切换成master后的106:7004,可以直接读取数据
再试着把105:7001给重新启动,恢复过来,自动作为slave挂载到了106:7004上面去
- 手动添加节点
- 按照上述redis创建实例,并且启动的方法添加7007端口
- 创建配置文件7007.conf和启动文件redis_7007,并且启动
## 执行添加节点的命令 作为slave节点添加
redis-cli --cluster add-node 192.168.56.107:7007 -- cluster-slave
- 通过
redis-cli --cluster check 192.168.56.105:7001查看对应的集群情况
- 手动删除节点
## 删除节点
redis-cli --cluster del-node 192.168.56.107:7006 118dbb0827daa62ae93b85d06690f01cf0449d9d