一、boston房价预测
1. 读取数据集
2. 训练集与测试集划分
3. 线性回归模型:建立13个变量与房价之间的预测模型,并检测模型好坏。
4. 多项式回归模型:建立13个变量与房价之间的预测模型,并检测模型好坏。
5. 比较线性模型与非线性模型的性能,并说明原因。
#线性回归模型:建立13个变量与房价之间的预测模型,并检测模型好坏。
from sklearn.datasets import load_boston
import matplotlib.pyplot as plt
from sklearn.linear_model import LinearRegression
from sklearn.model_selection import train_test_split
boston=load_boston()#导入数据集
x = boston.data
y = boston.target
x_train,x_test,y_train,y_test=train_test_split(x,y,test_size=0.3)#划分训练集和测试集
lineR=LinearRegression()#线性模型
lineR.fit(x_train,y_train)
#判断模型的好坏
print('线性回归模型预测的准确率:',lineR.score(x_test,y_test))
#4. 多项式回归模型:建立13个变量与房价之间的预测模型,并检测模型好坏。
from sklearn.preprocessing import PolynomialFeatures
poly=PolynomialFeatures(degree=2)
from sklearn.linear_model import LinearRegression
lineR=LinearRegression()
x= boston.data
y = boston.target
x_train,x_test,y_train,y_test=train_test_split(x,y,test_size=0.3)#划分训练集和测试集
#多项式操作
x_train_poly=poly.fit_transform(x_train)
x_test_poly=poly.transform(x_test)
lineR.fit(x_train_poly,y_train)#建立模型
print('多项式回归模型预测的准确率:',lineR.score(x_test_poly,y_test))
#图形化
from sklearn.linear_model import LinearRegression
import matplotlib.pyplot as plt
lineR=LinearRegression()
lineR.fit(x_train_poly,y_train)
y_poly_pred=lineR.predict(x_test_poly)
plt.plot(y,y,'r')
plt.scatter(y_test,y_poly_pred)
plt.show()

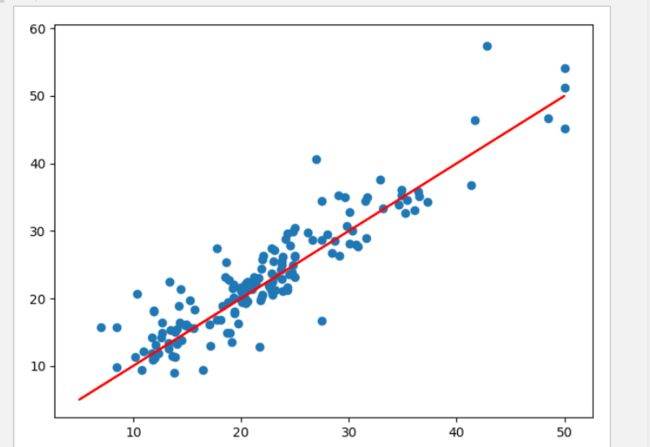
线性模型与非线性模型性能的区别:
一个模型如果是线性的,就意味着它的参数项要么是常数,要么是原参数和要预测的特征之间的乘积的和就是我们要预测的值。
线性模型计算复杂度较低,不足之处是模型拟合效果相对弱些。非线性模型拟合能力较强,不足之处是数据量不足容易过拟合,计算复杂度高,可解释性不好。
二、中文文本分类
按学号未位下载相应数据集。
147:财经、彩票、房产、股票、
258:家居、教育、科技、社会、时尚、
0369:时政、体育、星座、游戏、娱乐
分别建立中文文本分类模型,实现对文本的分类。基本步骤如下:
1.各种获取文件,写文件
2.除去噪声,如:格式转换,去掉符号,整体规范化
3.遍历每个个文件夹下的每个文本文件。
4.使用jieba分词将中文文本切割。
中文分词就是将一句话拆分为各个词语,因为中文分词在不同的语境中歧义较大,所以分词极其重要。
可以用jieba.add_word('word')增加词,用jieba.load_userdict('wordDict.txt')导入词库。
维护自定义词库
5.去掉停用词。
维护停用词表
6.对处理之后的文本开始用TF-IDF算法进行单词权值的计算
7.贝叶斯预测种类
8.模型评价
9.新文本类别预测
#导包
import jieba
import os
# 导入停用词
stopword=open('D:\大学作业\大三\数据挖掘基础算法(杜云梅)\stopsCN.txt','r',encoding="utf-8").read()
#数据处理
def processing(tokens):
# 去掉非字母汉字的字符
tokens = "".join([char for char in tokens if char.isalpha()])
# 结巴分词
tokens = [token for token in jieba.cut(tokens,cut_all=True) if len(token) >=2]
# 去掉停用词
tokens = " ".join([token for token in tokens if token not in stopword])
return tokens
#词频统计
def count(tokens):
lifedict = {}
for word in tokens:
if len(word) == 1:
continue
else:
lifedict[word] = lifedict.get(word, 0) + 1
wordlist = list(lifedict.items())
wordlist.sort(key=lambda x: x[1], reverse=True)#降序排序
#读取文件
all_txt=[]
all_target=[]
path = r'D:\大学作业\大三\数据挖掘基础算法(杜云梅)\0369'
files = os.listdir(path)
for root,dirs,files in os.walk(path):
for file in files:
filepath = os.path.join(root, file) # 文件路径
tokens=open(filepath,'r',encoding='utf-8').read()
tokens=processing(tokens)
all_txt.append(tokens)
target = filepath.split('\\')[-2]#按文件夹获取特征名
all_target.append(target)
#按6:4比例分为训练集和测试集
from sklearn.model_selection import train_test_split
x_train,x_test,y_train,y_test=train_test_split(all_txt,all_target,test_size=0.4,stratify=all_target)
#将其向量化
from sklearn.feature_extraction.text import TfidfVectorizer
vectorizer=TfidfVectorizer()
X_train=vectorizer.fit_transform(x_train)
X_test=vectorizer.transform(x_test)
#分类结果显示
from sklearn.naive_bayes import MultinomialNB
mnb=MultinomialNB()
clf=mnb.fit(X_train,y_train)
#进行预测
y_predict = clf.predict(X_test)
# 输出模型精确度
from sklearn.model_selection import cross_val_score
from sklearn.metrics import classification_report
scores=cross_val_score(mnb,X_test,y_test,cv=4)
print("精确度:%.3f"%scores.mean())
# 输出模型评估报告
print("classification_report:\n",classification_report(y_predict,y_test))y_nb_pred = clf.predict(X_test)
# 将预测结果和实际结果进行对比
import collections
# 统计测试集和预测集的各类新闻个数
testCount = collections.Counter(y_test)
predCount = collections.Counter(y_predict)
print('实际:',testCount,'\n', '预测', predCount)
# 建立标签列表,实际结果列表,预测结果列表,
nameList = list(testCount.keys())
testList = list(testCount.values())
predictList = list(predCount.values())
print("新闻类别:",nameList,'\n',"实际:",testList,'\n',"预测:",predictList)
