写在前边
昨天晚上就已经完成这篇博客了,就是在测试这块是否正常跑起来,晚上没搞完,上班前把电脑关机带着,结果没保存!基本上昨天写的东西都丢了,好在博客园的图片url还在。
为了让大家都轻松些,我轻松写,你轻松看。打算把文章的篇幅缩小,拆分成多个部分,这样更新频率会提高,写起来看起来也不会那么累,也不会再出现一次性丢那么多稿的问题……
本文记述Elasticsearch集群部分,下边会有说明具体的结构
部署架构
整体图
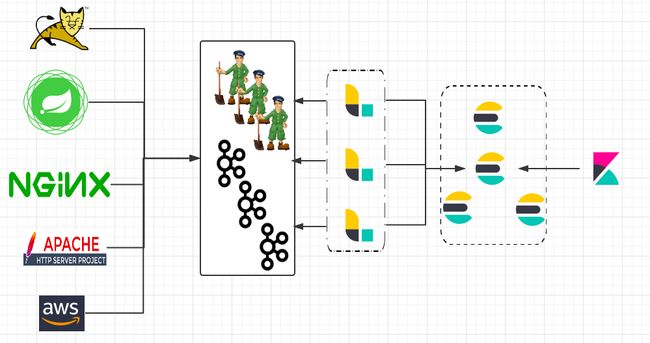
本文部分结构图
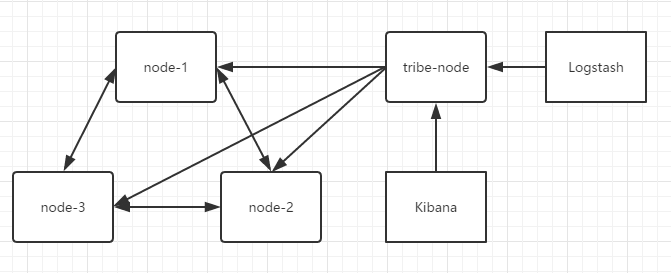
node 1~3为集群的数据节点,同时竞争master,tribe-node为部落节点,负责Logstash与Kibana的连接
好处是无需指明master节点,不用多启动一个只负责协调的节点,减少资源浪费。
环境准备
- GNU/Debian Stretch 9.9 linux-4.19
- elasticsearch-7.1.1-linux-x86_64.tar.gz
本文为了模拟,使用Docker的centos7,文中不会出现Docker操作部分,与正常主机无异
开始搭建
1.root权限编辑/etc/security/limits.conf sudo vim /etc/security/limits.conf
添加如下内容:
* soft memlock unlimited
* hard memlock unlimited其中
*可替换为启动es的linux用户名
保存退出. 生效需要重启
2.[可选] 禁用swap分区 # echo "vm.swappiness=1" >> /etc/sysctl.conf,配置性能大大提高
3.重启系统
不重启有些配置无法生效,启动es后报错依旧
4.为各主机添加用户和组
sudo groupadd elasticsearch #添加elasticsearch组
sudo usermod -aG elasticsearch 用户名 #添加elasticsearch用户5.解压elasticsearch-7.1.1-linux-x86_64.tar.gz,复制到各主机/home/elasticsearch下
6.分别为每个主机的/home/elasticsearch/elasticsearch-7.1.1/config/elasticsearch.yml内容最后追加配置
es-node-1
# ======================== Elasticsearch Configuration =========================
cluster.name: es-cluster
node.name: node-1
node.attr.rack: r1
bootstrap.memory_lock: true
http.port: 9200
network.host: 172.17.0.2
transport.tcp.port: 9300
discovery.seed_hosts: ["172.17.0.3:9300","172.17.0.4:9300","172.17.0.5:9300"]
cluster.initial_master_nodes: ["node-1", "node-2", "node-3"]
gateway.recover_after_nodes: 2es-node-2
# ======================== Elasticsearch Configuration =========================
cluster.name: es-cluster
node.name: node-2
node.attr.rack: r1
bootstrap.memory_lock: true
http.port: 9200
network.host: 172.17.0.3
transport.tcp.port: 9300
discovery.seed_hosts: ["172.17.0.2:9300","172.17.0.4:9300","172.17.0.5:9300"]
cluster.initial_master_nodes: ["node-1", "node-2", "node-3"]
gateway.recover_after_nodes: 2es-node-3
# ======================== Elasticsearch Configuration =========================
cluster.name: es-cluster
node.name: node-3
node.attr.rack: r1
bootstrap.memory_lock: true
http.port: 9200
network.host: 172.17.0.4
transport.tcp.port: 9300
discovery.seed_hosts: ["172.17.0.3:9300","172.17.0.2:9300","172.17.0.5:9300"]
cluster.initial_master_nodes: ["node-1", "node-2", "node-3"]
gateway.recover_after_nodes: 2es-tribe-node
# ======================== Elasticsearch Configuration =========================
cluster.name: es-cluster
node.name: tribe-node
node.master: false
node.data: false
node.attr.rack: r1
bootstrap.memory_lock: true
http.port: 9200
network.host: 172.17.0.5
transport.tcp.port: 9300
discovery.seed_hosts: ["172.17.0.3:9300","172.17.0.4:9300","172.17.0.2:9300"]
cluster.initial_master_nodes: ["node-1", "node-2", "node-3"]
gateway.recover_after_nodes: 2各参数说明放到文末,请自行参考
7.使用命令启动各节点ES_JAVA_OPTS="-Xms512m -Xmx512m" bin/elasticsearch
注意:
- 这里只能用非root用户,即文章最开始部分的创建的账号
- 本命令相对es的解压目录的路径
- JVM参数堆大小可自行调节
查看效果
这里使用浏览器查看
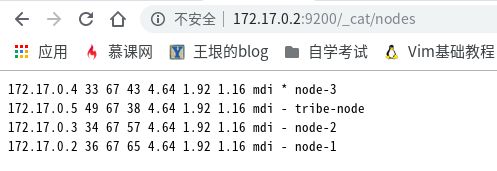
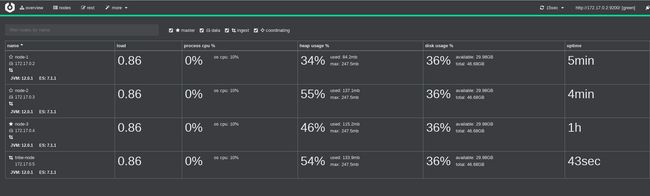
此图中的tribe-node节点不是mdi,是我之前忘加
node.data: false的图,现在是i
可以看出node-3是master节点,最近发现了个好用的elasticsearch查看工具cerebro
使用cerebro查看 cerebro github
图片看不清可以右键新标签页打开看大图

点nodes,查看各节点状态
还可以通过more来修改集群设置,功能好强大
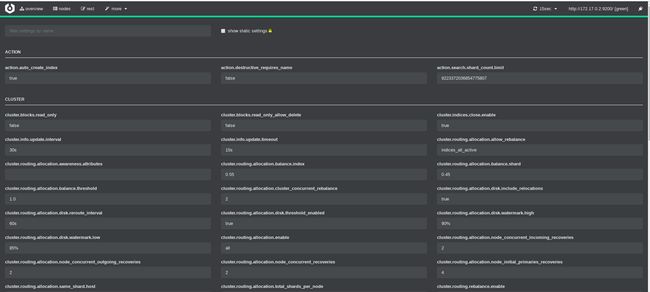
elasticsearch.yml参数配置的解释
cluster.name: es-cluster #指定es集群名
node.name: xxxx #指定当前es节点名
node.data: false #非数据节点
node.master: false #非master节点
node.attr.rack: r1 #自定义的属性,这是官方文档中自带的
bootstrap.memory_lock: true #开启启动es时锁定内存
network.host: 172.17.0.5 #当前节点的ip地址
http.port: 9200 #设置当前节点占用的端口号,默认9200
discovery.seed_hosts: ["172.17.0.3:9300","172.17.0.4:9300","172.17.0.2:9300"] #启动当前es节点时会去这个ip列表中去发现其他节点,此处不需配置自己节点的ip,这里支持ip和ip:port形式,不加端口号默认使用ip:9300去发现节点
cluster.initial_master_nodes: ["node-1", "node-2", "node-3"] #可作为master节点初始的节点名称,tribe-node不在此列
gateway.recover_after_nodes: 2 #设置集群中N个节点启动时进行数据恢复,默认为1。可选
path.data: /path/to/path #数据保存目录
path.logs: /path/to/path #日志保存目录
transport.tcp.port: 9300 #设置集群节点发现的端口这里的
discovery.seed_hosts在之前几个版本中叫discovery.zen.ping.unicast.hosts
配置我发现个比较全的,只是有些现在已经不用了,还是很有借鉴价值, elasticsearch配置文件详解
遗留问题
- 最后就是本次测试的时候,没有考虑脑裂问题,如有需要请自行添加修改,比如用tribe-node当master,不存数据;又比如加一个
node.master: true的节点,修改cluster.initial_master_nodes只有这一个master节点 - 文中为了简单,没有的把数据存储目录挂载出去,生产环境请勿必挂载出去
本文系原创文章,禁止转载