一、场景
豆瓣图书、时光电影等索引类站点的不考虑时间因素的产品评分,其核心是通过用户的评价计算出可量化的分数来衡量产品的受欢迎程度。使用威尔逊区间法进行评分,并使用贝叶斯平均法修正评分。
二、威尔逊区间法
威尔逊区间法是基于二项分布的一种计算方法,其结果与好评率和评价次数相关。其假设只有“喜欢”和“不喜欢”两个可选项,使其符合二项分布,并根据置信水平得到结果。
计算公式如下:
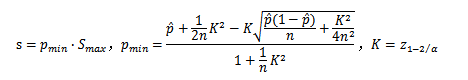
其中Smax是最大评分,pmin是威尔逊区间下限值,p是好评率(通常为平均值/总分值),n是评价总数,K是统计量常数(表示某个置信水平下z的统计量,在90%的置信水平下,值为1.64,在95%的置信水平下,值为1.96,在99%的置信水平下,值为2.58)。
以豆瓣的评分机制为例,其评价选项为一星至五星,评分十分制。若存在产品ABCD,其评价如下表所示,那么其在95%置信水平下的评分为:
| 产品 |
一星 |
二星 |
三星 |
四星 |
五星 |
平均值 |
评分 |
| A |
32 |
32 |
32 |
32 |
32 |
5.00 |
4.23 |
| B |
50 |
25 |
10 |
25 |
50 |
5.00 |
4.23 |
| C |
320 |
320 |
320 |
320 |
320 |
5.00 |
4.76 |
| D |
500 |
250 |
100 |
250 |
500 |
5.00 |
4.76 |
可以看出,相对于常用的平均值法,威尔逊区间法更准确的反映除了评价差异。
三、贝叶斯平均法
严格来说,贝叶斯平均法并不是一个评分模型,而是平衡模型。其核心是为冷门题目提供一个补偿值使其不至于因为少量评价而产生不可靠的评分,而在评价数量多后减小补偿值的比例,最终使得随着评价数量的增加而评分逐渐逼近实际值。
计算公式如下:
![]()
其中C是补偿评价数,M是补偿评分,n是评价数量,s是已计算评分。通常C、M应为常量,使最终评分只与评价数量和已计算评分相关。
以豆瓣的评分机制为例,其评价选项为一星至五星,评分十分制。若存在产品EFGH,其评价如下表所示,那么其在95%置信水平,C=64、M=4.0368的补偿条件下的修正评分为:
| 产品 |
一星 |
二星 |
三星 |
四星 |
五星 |
平均值 |
评分 |
修正 |
| E |
0 |
0 |
1 |
0 |
0 |
5.00 |
0.55 |
3.98 |
| F |
10 |
0 |
5 |
0 |
10 |
5.00 |
3.18 |
3.79 |
| G |
10 |
10 |
10 |
10 |
10 |
5.00 |
3.66 |
3.87 |
| H |
100 |
50 |
20 |
50 |
100 |
5.00 |
4.46 |
4.39 |
显然,对评价数量少的产品评分进行了大幅修正。
四、总结
需要明确威尔逊区间法用于对单个产品评分,贝叶斯平均法用于对多个产品平衡评分。对于威尔逊区间法,需要确保好评率的正确性及选择合适的置信水平。对于贝叶斯平均法,需要使补偿评价数和补偿评分为常量,以使得单个产品的评分仅与自身的评价相关。
五、更多
更为细致的评分,需要考虑评分的用户的权重性(资深用户和普通用户)、倾向性评分(用户的评分习惯),二者都可以在上述方法上扩充修改。
参考
阮一峰,《基于用户投票的排名算法(五):威尔逊区间》
阮一峰,《基于用户投票的排名算法(六):贝叶斯平均》
实现代码-Python
import sys def Avg(data,scoreMap): totalScore = float(sum(map(lambda t:t[0]*t[1], map(None,data,scoreMap)))) totalN = sum(data) return totalScore / totalN def Wilson(p, n, maxScore): p = float(p) K = 1.96 # 95% confidence level _K2_div_n = (K ** 2) / n pmin = (p + _K2_div_n / 2.0 - K*((p*(1-p)/n + _K2_div_n/n/4.0)**0.5)) / (1 + _K2_div_n) return pmin * maxScore def WilsonAvgP(n): totalP = 0.0; totalN = 0 p = 0.01 while True: totalP += Wilson(p, n, 1); totalN += 1 p += 0.01 if p >= 1: break return totalP / totalN def Bayesian(C, M, n, s): return (C*M + n*s) / (n + C) DATA = { "A" : (32,32,32,32,32), "B" : (50,25,10,25,50), "C" : (320,320,320,320,320), "D" : (500,250,100,250,500), "E" : (0,0,1,0,0), "F" : (10,0,5,0,10), "G" : (10,10,10,10,10), "H" : (100,50,20,50,100), } SCORE_MAP = (0,2.5,5,7.5,10) MAX_SCORE = 10 result = {} # key : avgScore, wilsonScore, wilsonRank C = 64; M = WilsonAvgP(C) * MAX_SCORE for k,v in DATA.items(): n = sum(v) avgScore = Avg(v,SCORE_MAP) wilsonScore = Wilson(avgScore / MAX_SCORE, n, MAX_SCORE) wilsonRank = Bayesian(C, M, n, wilsonScore) result[k] = (avgScore, wilsonScore, wilsonRank) for k in sorted(result.keys()): v = result[k] print k,":","%.2f" % v[0]," ","%.2f" % v[1]," ","%.2f" % v[2]