1.什么是Redis?
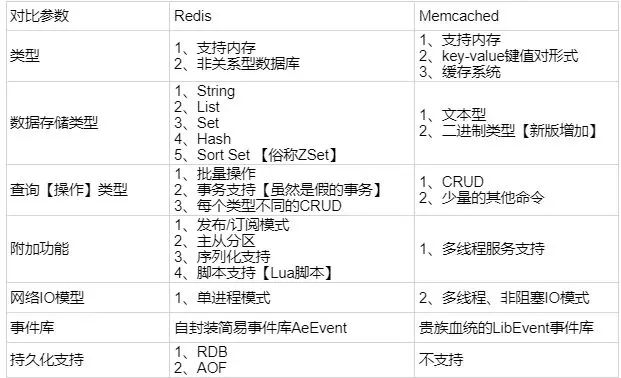
2.Redis与Memcached的区别与比较
3.Redis与Memcached的选择
4.使用redis有哪些好处?
6.MySQL里有2000w数据,Redis中只存20w的数据,如何保证Redis中的数据都是热点数据(redis有哪些数据淘汰策略???)
7.Redis的并发竞争问题如何解决?
8.Redis回收进程如何工作的? Redis回收使用的是什么算法?
9.Redis 大量数据插入
10.Redis 分区的优势、不足以及分区类型
11.Redis常见性能问题和解决方案:
12.Redis与消息队列
1.什么是Redis?
C 语言写,开源 key-value 数据库。。和Memcached类似,支持存储类型string(字符串)、list(链表)、set(集合)、zset(sorted set --有序集合)和hash(哈希类型)。push/pop、add/remove操作,且原子性。不同方式排序。
保证效率,缓存在内存中(与memcached一样)。区别redis会周期性:更新数据写磁盘、修改操作写入文件,实现master-slave(主从)同步。
2.Redis与Memcached的区别与比较
1 、Redis不仅仅支持简单的k/v类型的数据,同时还提供list,set,zset,hash等数据结构的存储。memcache支持简单的数据类型,String。
2 、Redis支持数据的备份,即master-slave模式的数据备份。
3 、Redis支持数据的持久化,可以将内存中的数据保持在磁盘中,重启的时候可以再次加载进行使用,而Memecache把数据全部存在内存之中
4、 redis的速度比memcached快很多
5、Memcached是多线程,非阻塞IO复用的网络模型;Redis使用单线程的IO复用模型。
3.Redis与Memcached的选择
终极策略:用Redis的String做的事,都可用Memcached替换,换更好性能提升; 除此以外,优先考虑Redis;
4.使用redis有哪些好处?
(1)速度快,数据内存中,类似于HashMap,O(1)
(2)支持丰富数据类型,支持string,list,set,sorted set,hash
(3)支持事务:redis对事务是部分支持的,如果是在入队时报错,那么都不会执行;在非入队时报错,那么成功的就会成功执行。详细了解请参考:《Redis事务介绍(四)》:blog.csdn.net/cuipeng0916…
redis监控:锁的介绍
(4)丰富的特性:可用于缓存,消息,按key设置过期时间,过期后将会自动删除
6.MySQL里有2000w数据,Redis中只存20w的数据,如何保证Redis中的数据都是热点数据(redis有哪些数据淘汰策略???)
相关知识:redis 内存数据集大小上升到一定大小的时候,就会施行数据淘汰策略(回收策略)。redis 提供 6种数据淘汰策略:
volatile-lru:从已设置过期时间的数据集(server.db[i].expires)中挑选最近最少使用的数据淘汰
volatile-ttl:从已设置过期时间的数据集(server.db[i].expires)中挑选将要过期的数据淘汰
volatile-random:从已设置过期时间的数据集(server.db[i].expires)中任意选择数据淘汰
allkeys-lru:从数据集(server.db[i].dict)中挑选最近最少使用的数据淘汰
allkeys-random:从数据集(server.db[i].dict)中任意选择数据淘汰
no-enviction(驱逐):禁止驱逐数据
7.Redis的并发竞争问题如何解决?
Redis为单进程单线程模式,采用队列模式将并发访问变为串行访问。Redis本身没有锁的概念,Redis对于多个客户端连接并不存在竞争,但是在Jedis客户端对Redis进行并发访问时会发生连接超时、数据转换错误、阻塞、客户端关闭连接等问题,这些问题均是由于客户端连接混乱造成。对此有2种解决方法:
(1)客户端角度,为保证每个客户端间正常有序与Redis进行通信,对连接进行池化,同时对客户端读写Redis操作采用内部锁synchronized。
(2)服务器角度,利用setnx实现锁。
注:对于第一种,需要应用程序自己处理资源的同步,可以使用的方法比较通俗,可以使用synchronized也可以使用lock;第二种需要用到Redis的setnx命令,但是需要注意一些问题。
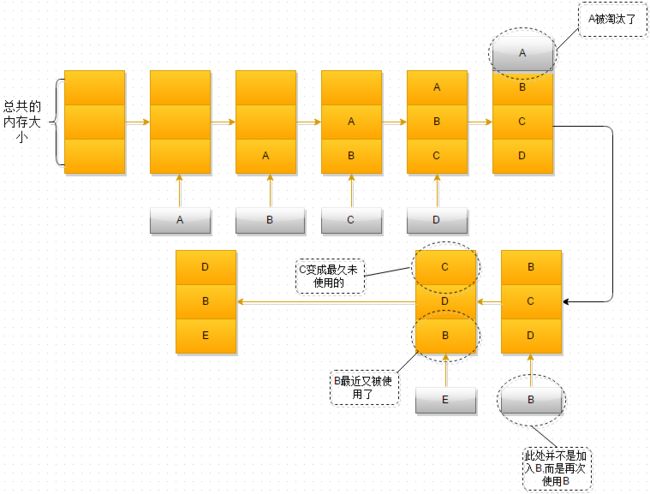
8.Redis回收进程如何工作的? Redis回收使用的是什么算法?
Redis内存回收:LRU算法(写的很不错,推荐):www.cnblogs.com/WJ5888/p/43…
最近最久未使用算法
9.Redis 大量数据插入
(1)使用Luke协议
使用正常模式的Redis 客户端执行大量数据插入不是一个好主意:因为一个个的插入会有大量的时间浪费在每一个命令往返时间上。使用管道(pipelining)是一种可行的办法,但是在大量插入数据的同时又需要执行其他新命令时,这时读取数据的同时需要确保请可能快的的写入数据。
只有一小部分的客户端支持非阻塞输入/输出(non-blocking I/O),并且并不是所有客户端能以最大限度的提高吞吐量的高效的方式来分析答复。
例如,如果我们需要生成一个10亿的`keyN -> ValueN’的大数据集,我们会创建一个如下的redis命令集的文件:

让Redis尽可能快的执行
使用pipe mode模式的执行命令如下:cat data.txt | redis-cli --pipe
(2)生成Redis协议
http://www.redis.cn/topics/mass-insert.html
10.Redis 分区的优势、不足以及分区类型
优势:
通过利用多台计算机内存的和值,允许我们构造更大的数据库。
通过多核和多台计算机,允许我们扩展计算能力;通过多台计算机和网络适配器,允许我们扩展网络带宽。
不足:
redis的一些特性在分区方面表现的不是很好:
涉及多个key的操作通常是不被支持的。举例来说,当两个set映射到不同的redis实例上时,你就不能对这两个set执行交集操作。
涉及多个key的redis事务不能使用。
当使用分区时,数据处理较为复杂,比如你需要处理多个rdb/aof文件,并且从多个实例和主机备份持久化文件。
增加或删除容量也比较复杂。redis集群大多数支持在运行时增加、删除节点的透明数据平衡的能力,但是类似于客户端分区、代理等其他系统则不支持这项特性。然而,一种叫做presharding的技术对此是有帮助的。
分区类型
Redis 有两种类型分区。 假设有4个Redis实例 R0,R1,R2,R3,和类似user:1,user:2这样的表示用户的多个key,对既定的key有多种不同方式来选择这个key存放在哪个实例中。也就是说,有不同的系统来映射某个key到某个Redis服务。
(1)范围分区
最简单的分区方式是按范围分区,就是映射一定范围的对象到特定的Redis实例。
比如,ID从0到10000的用户会保存到实例R0,ID从10001到 20000的用户会保存到R1,以此类推。
这种方式是可行的,并且在实际中使用,不足就是要有一个区间范围到实例的映射表。这个表要被管理,同时还需要各 种对象的映射表,通常对Redis来说并非是好的方法。
(2)哈希分区
另外一种分区方法是hash分区。这对任何key都适用,也无需是object_name:这种形式,像下面描述的一样简单:
用一个hash函数将key转换为一个数字,比如使用crc32 hash函数。对key foobar执行crc32(foobar)会输出类似93024922的整数。
对这个整数取模,将其转化为0-3之间的数字,就可以将这个整数映射到4个Redis实例中的一个了。93024922 % 4 = 2,就是说key foobar应该被存到R2实例中。注意:取模操作是取除的余数,通常在多种编程语言中用%操作符实现。
11.Redis常见性能问题和解决方案:
Master不做持久化工作,如RDB内存快照和AOF日志文件
数据重要,某Slave开启AOF备份数据,设置每秒同步
为主从复制速度和连接稳定,Master和Slave同一局域网
避免在压力很大的主库上增加从库
12.Redis与消息队列
不用redis做消息队列,不是设计目标。作者基于redis的核心代码,实现消息队列disque: antirez/disque:github.com/antirez/dis…部署、协议等方面都跟redis非常类似,并且支持集群,延迟消息等等。