flume 拦截器(interceptor)
1、flume拦截器介绍
拦截器是简单的插件式组件,设置在source和channel之间。source接收到的事件event,在写入channel之前,拦截器都可以进行转换或者删除这些事件。每个拦截器只处理同一个source接收到的事件。可以自定义拦截器。
2、flume内置的拦截器
2.1 时间戳拦截器
flume中一个最经常使用的拦截器 ,该拦截器的作用是将时间戳插入到flume的事件报头中。如果不使用任何拦截器,flume接受到的只有message。时间戳拦截器的配置:
| 参数 |
默认值 |
描述 |
| type |
timestamp |
类型名称timestamp,也可以使用类名的全路径org.apache.flume.interceptor.TimestampInterceptor$Builder |
| preserveExisting |
false |
如果设置为true,若事件中报头已经存在,不会替换时间戳报头的值 |
参数 默认值 描述
type timestamp 类型名称timestamp,也可以使用类名的全路径org.apache.flume.interceptor.TimestampInterceptor$Builder
preserveExisting false 如果设置为true,若事件中报头已经存在,不会替换时间戳报头的值
source连接到时间戳拦截器的配置:
a1.sources.r1.interceptors=i1
a1.sources.r1.interceptors.i1.type=timestamp a1.sources.r1.interceptors.i1.preserveExisting=false
| a1.sources.r1.interceptors=i1 a1.sources.r1.interceptors.i1.type=timestamp a1.sources.r1.interceptors.i1.preserveExisting=false |
2.2 主机拦截器
主机拦截器插入服务器的ip地址或者主机名,agent将这些内容插入到事件的报头中。事件报头中的key使用hostHeader配置,默认是host。主机拦截器的配置:
参数 默认值 描述
type host 类型名称host,也可以使用类名的全路径org.apache.flume.interceptor.HostInterceptor$Builder
hostHeader host 事件头的key
useIP true 如果设置为false,host键插入主机名
preserveExisting false 如果设置为true,若事件中报头已经存在,不会替换时间戳报头的值
| 参数 |
默认值 |
描述 |
| type |
host |
类型名称host,也可以使用类名的全路径org.apache.flume.interceptor.HostInterceptor$Builder |
| hostHeader |
host |
事件头的key |
| useIP |
true |
如果设置为false,host键插入主机名 |
| preserveExisting |
false |
如果设置为true,若事件中报头已经存在,不会替换时间戳报头的值 |
source连接到主机拦截器的配置:
a1.sources.r1.interceptors=i2
a1.sources.r1.interceptors.i2.type=host
a1.sources.r1.interceptors.i2.useIP=false
a1.sources.r1.interceptors.i2.preserveExisting=false
| a1.sources.r1.interceptors=i2 a1.sources.r1.interceptors.i2.type=host a1.sources.r1.interceptors.i2.useIP=false a1.sources.r1.interceptors.i2.preserveExisting=false |
2.3 静态拦截器
静态拦截器的作用是将k/v插入到事件的报头中。配置如下
| 参数 |
默认值 |
描述 |
| type |
static |
类型名称static,也可以使用类全路径名称org.apache.flume.interceptor.StaticInterceptor$Builder |
| key |
key |
事件头的key |
| value |
value |
key对应的value值 |
| preserveExisting |
true |
如果设置为true,若事件中报头已经存在该key,不会替换value的值 |
参数 默认值 描述
type static 类型名称static,也可以使用类全路径名称org.apache.flume.interceptor.StaticInterceptor$Builder
key key 事件头的key
value value key对应的value值
preserveExisting true 如果设置为true,若事件中报头已经存在该key,不会替换value的值
source连接到静态拦截器的配置:
a1.sources.r1.interceptors= i3
a1.sources.r1.interceptors.static.type=static a1.sources.r1.interceptors.static.key=logs a1.sources.r1.interceptors.static.value=logFlume a1.sources.r1.interceptors.static.preserveExisting=false
a1.sources.r1.interceptors= i3
a1.sources.r1.interceptors.static.type=static a1.sources.r1.interceptors.static.key=logs a1.sources.r1.interceptors.static.value=logFlume a1.sources.r1.interceptors.static.preserveExisting=false
2.4 正则过滤拦截器
在日志采集的时候,可能有一些数据是我们不需要的,这样添加过滤拦截器,可以过滤掉不需要的日志,也可以根据需要收集满足正则条件的日志。配置如下
| 参数 |
默认值 |
描述 |
| type |
REGEX_FILTER |
类型名称REGEX_FILTER,也可以使用类全路径名称org.apache.flume.interceptor.RegexFilteringInterceptor$Builder |
| regex |
.* |
匹配除“\n”之外的任何个字符 |
| excludeEvents |
false |
默认收集匹配到的事件。如果为true,则会删除匹配到的event,收集未匹配到的 |
参数 默认值 描述
type REGEX_FILTER 类型名称REGEX_FILTER,也可以使用类全路径名称org.apache.flume.interceptor.RegexFilteringInterceptor$Builder
regex .* 匹配除“\n”之外的任何个字符
excludeEvents false 默认收集匹配到的事件。如果为true,则会删除匹配到的event,收集未匹配到的
source连接到正则过滤拦截器的配置:
| a1.sources.r1.interceptors=i4 a1.sources.r1.interceptors.i4.type=REGEX_FILTER a1.sources.r1.interceptors.i4.regex=(rm)|(kill) a1.sources.r1.interceptors.i4.excludeEvents=false |
这样配置的拦截器就只会接收日志消息中带有rm 或者kill的日志。
测试案例:
test_regex.conf
| # 定义这个agent中各组件的名字 a1.sources = r1 a1.sinks = k1 a1.channels = c1
# 描述和配置source组件:r1 a1.sources.r1.type = netcat a1.sources.r1.bind = itcast01 a1.sources.r1.port = 44444 a1.sources.r1. a1.sources.r1.interceptors=i4 a1.sources.r1.interceptors.i4.type=REGEX_FILTER #保留内容中出现hadoop或者是spark的字符串的记录 a1.sources.r1.interceptors.i4.regex=(hadoop)|(spark) a1.sources.r1.interceptors.i4.excludeEvents=false
# 描述和配置sink组件:k1 a1.sinks.k1.type = logger
# 描述和配置channel组件,此处使用是内存缓存的方式 a1.channels.c1.type = memory a1.channels.c1.capacity = 1000 a1.channels.c1.transactionCapacity = 100
# 描述和配置source channel sink之间的连接关系 a1.sources.r1.channels = c1 a1.sinks.k1.channel = c1 |
发送数据测试:
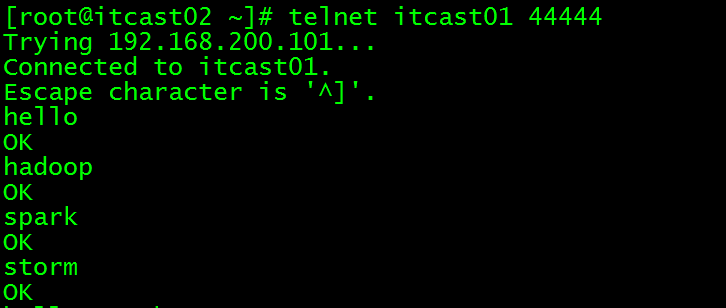
打印到控制台信息:

只接受到存在hadoop或者spark的记录,验证成功!
自定义拦截器
1. 背景介绍
Flume是Cloudera提供的一个高可用的,高可靠的,分布式的海量日志采集、聚合和传输的系统,Flume支持在日志系统中定制各类数据发送方,用于收集数据;同时,Flume提供对数据进行简单处理,并写到各种数据接受方(可定制)的能力。Flume有各种自带的拦截器,比如:TimestampInterceptor、HostInterceptor、RegexExtractorInterceptor等,通过使用不同的拦截器,实现不同的功能。但是以上的这些拦截器,不能改变原有日志数据的内容或者对日志信息添加一定的处理逻辑,当一条日志信息有几十个甚至上百个字段的时候,在传统的Flume处理下,收集到的日志还是会有对应这么多的字段,也不能对你想要的字段进行对应的处理。
2. 自定义拦截器
根据实际业务的需求,为了更好的满足数据在应用层的处理,通过自定义Flume拦截器,过滤掉不需要的字段,并对指定字段加密处理,将源数据进行预处理。减少了数据的传输量,降低了存储的开销。
3. 实现
本技术方案核心包括二部分:
① 编写java代码,自定义拦截器;
内容包括:
1. 定义一个类CustomParameterInterceptor实现Interceptor接口。
2. 在CustomParameterInterceptor类中定义变量,这些变量是需要到 Flume的配置文件中进行配置使用的。每一行字段间的分隔符(fields_separator)、通过分隔符分隔后,所需要列字段的下标(indexs)、多个下标使用的分隔符(indexs_separator)、多个下标使用的分隔符(indexs_separator)。
3. 添加CustomParameterInterceptor的有参构造方法。并对相应的变量进行处理。将配置文件中传过来的unicode编码进行转换为字符串。
4. 写具体的要处理的逻辑intercept()方法,一个是单个处理的,一个是批量处理。
5. 接口中定义了一个内部接口Builder,在configure方法中,进行一些参数配置。并给出,在flume的conf中没配置一些参数时,给出其默认值。通过其builder方法,返回一个CustomParameterInterceptor对象。
6. 定义一个静态类,类中封装MD5加密方法
7. 通过以上步骤,自定义拦截器的代码开发已完成,然后打包成jar, 放到Flume的根目录下的lib中

② 修改Flume的配置信息
新增配置文件spool-interceptor-hdfs.conf,内容为:
a1.channels = c1
a1.sources = r1
a1.sinks = s1
#channel
a1.channels.c1.type = memory
a1.channels.c1.capacity=100000
a1.channels.c1.transactionCapacity=50000
#source
a1.sources.r1.channels = c1
a1.sources.r1.type = spooldir
a1.sources.r1.spoolDir = /root/data/
a1.sources.r1.batchSize= 50
a1.sources.r1.inputCharset = UTF-8
a1.sources.r1.interceptors =i1 i2
a1.sources.r1.interceptors.i1.type =cn.itcast.interceptor.CustomParameterInterceptor$Builder
a1.sources.r1.interceptors.i1.fields_separator=\\u0009
a1.sources.r1.interceptors.i1.indexs =0,1,3,5,6
a1.sources.r1.interceptors.i1.indexs_separator =\\u002c
a1.sources.r1.interceptors.i1.encrypted_field_index =0
a1.sources.r1.interceptors.i2.type = timestamp
#sink
a1.sinks.s1.channel = c1
a1.sinks.s1.type = hdfs
a1.sinks.s1.hdfs.path =hdfs://192.168.200.101:9000/flume/%Y%m%d
a1.sinks.s1.hdfs.filePrefix = event
a1.sinks.s1.hdfs.fileSuffix = .log
a1.sinks.s1.hdfs.rollSize = 10485760
a1.sinks.s1.hdfs.rollInterval =20
a1.sinks.s1.hdfs.rollCount = 0
a1.sinks.s1.hdfs.batchSize = 1500
a1.sinks.s1.hdfs.round = true
a1.sinks.s1.hdfs.roundUnit = minute
a1.sinks.s1.hdfs.threadsPoolSize = 25
a1.sinks.s1.hdfs.useLocalTimeStamp = true
a1.sinks.s1.hdfs.minBlockReplicas = 1
a1.sinks.s1.hdfs.fileType =DataStream
a1.sinks.s1.hdfs.writeFormat = Text
a1.sinks.s1.hdfs.callTimeout = 60000
a1.sinks.s1.hdfs.idleTimeout =60
启动:
bin/flume-ng agent -c conf -f conf/spool-interceptor-hdfs.conf -name a1 -Dflume.root.logger=DEBUG,console
5. 项目实现截图:

图一 原始文件内容

图二 HDFS上产生收集到的处理数据