Django——一个封装好的神奇框架
若本文有任何内容错误,望各位大佬指出批评,并请直接联系作者修改,谢谢!小白学习不易。
一、简要模型
模型类操作数据表:
python manage.py shell
制作迁移文件:
python manage.py makemigrations
执行迁移文件:
python manage.py migrate
from booktest.models import BookInfo
实例化对象,设置对象实例属性值,调用对象.save()方法
查询:
b = BookInfo.objects.get #要查询的条件,如id=1
b是根据条件查询到的内容,类型为BookInfo对象
实体类之间的主外键:主类:
hbook = models.ForeignKey('BookInfo')
h2.hbook = b #h2为实例化对象,b为bookInfo的实例化对象,主外键对应
b.heroinfo_set.all()查询与外键相关联的主键集合
1、models模型类:
class AreaInfo(models.Model): atitle = models.CharField(verbose_name='地区',max_length=20) # verbose_name指定属性列列名称 def title(self): return self.atitle title.admin_order_field = 'atitle' #指定该列点击列标题根据atitle进行排序 title.short_description = '地区名称' #指定该列列标题为地区名称
重写str方法可让管理页面显示正确的中文内容
在admin中注册实体类信息,管理员可进行后台管理,实行数据的CRUD,此外,在admin中建立自定义模型管理类class,继承admin.ModelAdmin可以设置页面显示内容:
class AreaInfoAdmin(admin.ModelAdmin): list_display = ['id','btitle','bpub_date'] #页面数据显示格式 list_per_page=['10'] #可以设置每页显示数据条数, list_filter=['atitle'] #列表右侧过滤栏,一标题进行过滤,可进行快速查找 actions_on_bottom = True # 操作栏显示在下面 search_fields=['atitle'] #列表页上方的搜索框,以标题进行搜索 fields=['字段1','字段2'] #指定编辑页的上下顺序 admin.site.register(AreaInfo, AreaInfoAdmin)
2、关联对象:
一对多的关系中,在一端的编辑页面中编辑多端的对象,可嵌入表格或块两种,InlineModelAdmin:在编辑页面嵌入关联的模型;TabularInline:以表格形式嵌入;StackedInline:以块形式嵌入:
booktest/admin.py:
class AreaStackedInline(admin.StatickedInline): model = AreaInfo # 关联子对象 extra = 2 # 增加两个额外的子对象
在booktest/admin.py中,AreaAdmin类:
class AreaAdmin(admin.ModelAdmin): ...... inlines = [AreaStackedInline]
二、简要视图与模板
from django.http import HttpResponse
函数,参数为request,返回 HttpResponse()
在新建urls里配置url,
from django.conf.urls import url from booktest import views url(r'^index$',views.index) #建立index和视图index之间的关系,严格匹配开头和结尾
在系统urls中添加配置项
url(r'^', include('booktest.urls')) # 包含booktest应用中的应用文件
settings里TRMPLATES的DIRS设置模板路径:
'DIRS':[os.path.join(BASE_DIR,,'templates')]
2.1、数据库配置:
DATABASES: 'NAME':'数据库名', 'USER':'用户名', 'PASSWORD':'密码', 'HOST':'IP', 'PORT':3306,
__init__.py里:
import pymysql pymysql.install_as_MySQLdb()
2.2、示例过程
在views里写index方法:
from django.template import loader def index(request): temp = loader.get_template('booktest/index.html') # 加载模板文件 context = RequestContext(request,{ }) # 定义模板上下文,给模板传数据 res_html = temp.render(context) # 模板渲染:产生标准的HTML内容 return HttpResponse(res_html) # 返回给浏览器
简化方法一:*******将此函数封装成固定函数
def my_render(request,template_path,context_dict): temp = loader.get_template(template_path) # 加载模板文件 context = RequestCOntext(request,context_dict) # 定义模板上下文,给模板传数据 res_html = temp.render(context) # 模板渲染:产生标准的HTML内容 return HttpResponse(res_html) # 返回给浏览器
简化方法二:*******直接调用系统方法
return render(request,'booktest/index.html',{'grent':'hello django!'})
HTML页面用{{ content }}显示传输的数据
传输列表:
render(request,'booktest/index.html',{'list':list(range(1,10))})
HTML页面用{{ list }}直接显示内容
遍历:
{% for i in list %}
关系比较符:> < >= <= == !=(进行比较操作时,操作符两边必须有空格!)
逻辑运算:not and or
链接传值时的urls设置
url(r'^books/(\d+)$' , views.detail)
(\d+需要加括号),分组。
三、模型
3.1、mysql查询:
get 返回的事查询到的对象,其余返回的是查询集的对象
等值查询:
BookInfo.objects.get(id=1) == BookInfo.objects.get(id__exact=1)
模糊查询: **所有下划线均为双下划线**
BookInfo.objects.filter(btitle__contains='传') #包含 BookInfo.objects.filter(btitle__endswith='部') #以关键字结尾
空查询:
BookInfo.objects.filter(btitle__isnull=False) #不为空
范围查询:
BookInfo.objects.filter(id__in=[1,3,5]) #查询id为1或3或5的书籍
比较查询:gt(greatr than)、lt(less than) gte(equals) lte(<=)
BookInfo.objects.filter(id__gt=3) #查询编号大于3的图书
日期查询:
BookInfo.objects.filter(bpub_date__year=1990) #查询日期为1990年发表的图书 BookInfo.objects.filter(bpub_date__gt=date(1990,1,1)) #查询1990年1月1日后发表的书
3.2、exclude方法与排序:
BookInfo.objects.exclude(id=3) #查询id不为3的书籍
order_by:
BookInfo.objects.all().order_by('id') #根据id从小到大排序 BookInfo.objects.all().order_by('-id') #从大到小
3.3、Q对象:
from django.db import Q
或:
BookInfo.objects.filter(Q(id__gt=3)|Q(bread__gt=30))
且:
BookInfo.objects.filter(id__gt=3,bread__gt=30) == BookInfo.objects.filter(Q(id__gt=3)&Q(bread__gt=30))
非:
BookInfo.objects.filter(~Q(id=3))
3.4、F对象:
(类属性之间的比较)
from django.db import F BookInfo.objects.filter(bread__gt = F('bcomment')) #查询图书阅读量大于2倍评论量图书信息
3.5聚合函数:
aggregate进行聚合操作,返回值是一个字典
sum count avg max min
from django.db.models import Sum,Count,Max,Min,Avg BookInfo.objects.all().aggregate(Count('id')) #返回字典 BookInfo.objects.all().count() #返回数值
3.6、查询集特性:
只有在真正使用查询集中的数据的时候才会真正发生对数据库的真正查询;
当使用的是同一个查询集时,第一次的查询会将结果缓存,之后使用的是缓存中的结果;
可对查询集进行切片,但是下标不能为负数;
3.7模型类关系:
一对多:models.ForeignKey() ——必须定义在多的类中
多对多:models.ManyToManyField()
一对一:models.OneToOneField()
3.8、模型关联查询:
id为1的图书关联英雄信息:
b = BookInfo.objects.get(id=1)
b.heroinfo_set.all()
BoojInfo图书类 —— 一类 HeroInfo英雄人物类 —— 多类
b.heroinfo_set.all() —— 一查多
h.hbook —— 多查一
3.9、管理器:
objects为models。Manager类对象,每个类都有
一般自定义模型管理类,继承自models.Manager,可自定义函数改变查询的结果集
类中使用self.model()可以创建跟自定义管理器对应的模型类对象。
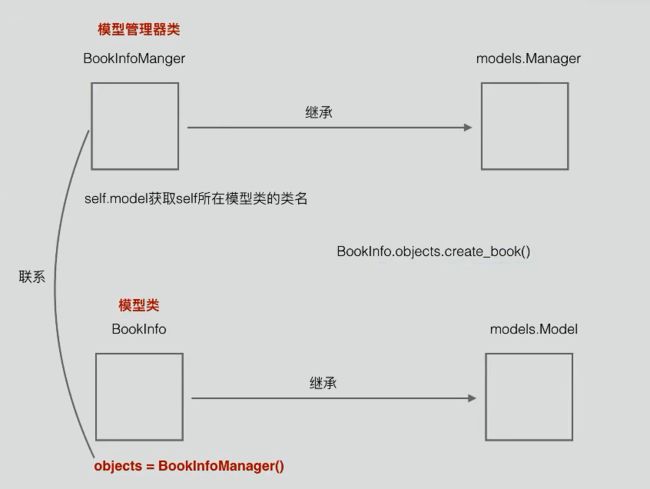
图一:管理器流程图
3.10、元选项:
在项目中遇到中途需要修改项目名等情况时,可以指定元类,让模型表名不依赖于对应的表名:
class Meta: db_table = 'bookinfo'
四、视图
视图函数:
request参数必须有,参数名可以变化,是一个HttpRequest类型的对象。
4.1、错误页面
找不到页面,关闭settings里的调试模式后,默认会显示一个标准的错误页面,自定义错误页面,需要在templates目录下自定义一个404.html文件。
错误:404——url没有配置/url配置错误
500——视图出错
网站开发完成需要关闭调试模式:
DEBUG = False ALLOWED_HOST = [ '*' ]
4.2、捕获url参数:
将所要捕获的部分设置成正则表达式组,django会自动将匹配成功的相应组内容作为参数传递给视图参数。
4.3、请求方法
页面表单的POST和GET:
POST——数据在请求头中,多出现在表单
GET——数据在url中,不安全,多出现在超链接
后台通过request去获取数据,是一个QueryDict对象,里面的键可重复,取到的是后面的值,用getlist('键')可取到某名的所有值,用类字典方式提取,最好用get方法,不存在不会报错。
4.4、Ajax
重要两点:访问地址时需要携带的参数;试图处理完成后返回的json格式。
应用文件下创建static文件夹,在settings里配置
STATIC_URL = '/static/' #HTML页面访问静态文件对应的url地址 STATICFILES_DIRS = [os.path.join(BASE_DIR, 'static')]
需要先导入jquery文件,并在HTML文件里引用,随后:
'button' id='btnAjax' value='ajax请求'/>
Django返回: return JsonResponse({'res':1})
异步:alert顺序1-3-2,也就是在按钮事件后,会继续执行ajax中的代码,而不会等服务器把结果发来之后再执行回调函数success。
同步:在ajax请求里加上 'async':false, 就会是同步的ajax请求。
4.5、Cookie缓存:
添加cookie缓存需要HttpResponse对象的一个实例调用.set_cookie()方法,参数为键值对,取出cookie为request.COOKIES()参数为键名
4.6、session:
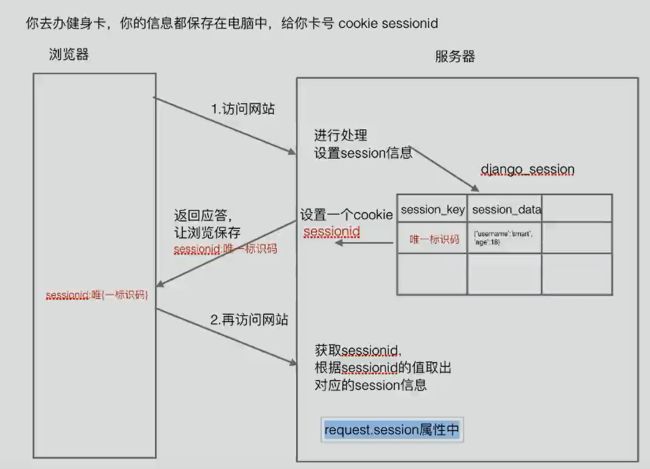
图二:session流程图
以键值对存储,依赖于cookie,默认两周过期。
设置:
request.session['username']='jery'
取值:
request.session['username']
4.7、比较:
cookie:记住用户名,安全性要求不高,
session:安全性比较高,账户,密码,余额等。
五、模板
两部分:静态内容(css,js,html);动态内容(模板语言:编程语言)
5.1、模板文件的加载顺序:
去配置的模板目录下找模板文件;
去INSTALLED_APPS下每个应用找模板文件,前提是应用中必须有templates文件夹(templates——>admin——>auth)
模板语言(DTL Django Template Language):
模板变量:
{{ book.btitle }}解析顺序:
book当成字典,btitle当成键名,取值book['btitle'];
book当成对象,btitle当成属性,取值book.btitle;
book当成对象,btitle当成对象的方法,取值book.btitle;
{{ book.0 }}解析顺序:
book当成字典,0当成键名,取值book['0']
book当成列表,0当成下标,取值book[ 0 ]
若解析失败,产生内容时Django框架会自动用空字符串填充模板变量。
5.2、过滤器:
模板变量|过滤器:参数
如:
{{ book.bpub_date|date:'Y年-m月-d日' }}
{{ book.btitle|length }}
{{ content|default:'为空' }}
自定义过滤器:应用下新建templatetags
新建自定义名filters.py文件:
from django.template import Library register = Library() @register.filter def mod(num): return num%2 == 0 #判断num是否为偶数
HTML引用过滤器:
{% load filters %}
{% if book.id|mod %}
5.3、模板注释
(网页源代码不会显示注释的内容):
单行注释:{# 注释内容 #}
多行注释:{% comment %} 注释内容 {% endcomment %}
5.4、模板继承:
父文件:
{% block 块名 %} 中间内容可为空 {% endblock 块名 %}
子文件:
{% extends 'booktest:/base.html' %}
{% block 块名 %} 覆盖子模板内容,也可调用父模板内容{{ block.super }} {% endblock 块名 %}
5.5、HTML转义:
模板上下文中的html标签默认会被转义,关闭转义可用:
safe过滤器:{{ 模板变量|safe }}
autoescape标签:{{% autoescape off %}}被取消转义的内容 {{% endautoescape %}}
5.6、csrf攻击:
登录装饰器:
有些页面是用户登录之后才能访问的,访问某些抵制需要先进性登录的判断,即拦截器,此过程可定义为一个装饰器:
def login_required(view_func): def wrapper(request, *view_args, **view_kwargs): if request.session.has_key('isLogin') return view_func(request, *view_args, **view_kwargs) else: return redirect('/login') return wrapper
view函数前引用@login_required
在已经登录某网站后,其他网站或网页利用缓存数据模拟向网站发出一些请求,即跨站请求。
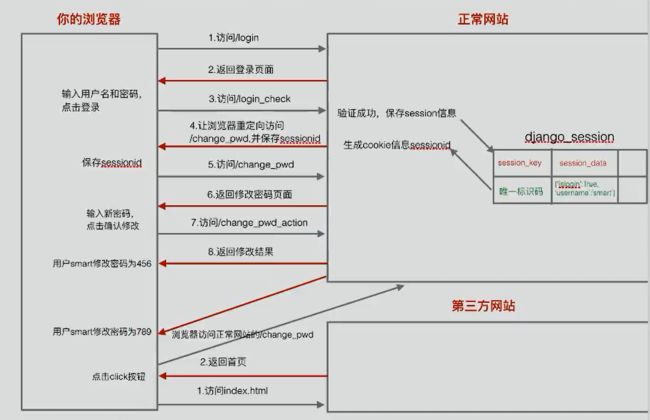
图三:csrf攻击模式
方法:
Django默认启用csrf防护,只针对post请求生效;
在表单post提交数据时附加上 {% csrf token %} 标签可禁止csrf伪造。
防御原理:
1)渲染模板文件时在页面生成一个名字叫做csrfmiddlewaretoken的隐藏域。
2)服务器交给浏览器保存一个名字为csrftoken的cookie信息。
3)提交表单时两个值都会发给服务器,服务器进行比对,如果一样,则csrf验证通过,否则失败。
5.7、反向解析:
避免网页名的改变而导致大规模改动名称,动态生成url地址:首页
若urls中的url带name捕获的位置参数,则在动态生成地址时需要明确指定。
eg:
urls:
url(r'^show_args/(\d+)/(\d+)$', views.show_args, name='show_args')
views:
def show_args(request,a,b): return HttpResponse(a+':'+b)
html:动态产生/show_args/1/2:
在重定向时使用反向解析:
from django.core.urlresolvers import reverse
无参数:reverse('namespace 名字: name 名字')
有位置参数:reverse('namespace 名字: name 名字',args=位置参数元组)
六、其他
6.1、静态文件:
应用文件下创建static文件夹,在settings里配置
STATIC_URL = '/static/' # HTML页面访问静态文件对应的url地址 STATICFILES_DIRS = [os.path.join(BASE_DIR, 'static')]
HTML页面顶部{% load staticfiles %}

6.2、中间件:
干预和请求问答过程:
使用request对象META属性在view视图里获取浏览器端ip地址:request.META[' REMOTE_ADDR ']
新建middleware.py中间件(在视图函数调用之前被调用,装饰器写法):
class BlockedIPSMiddleware(boject): EXCLUDE_IPS = ['10.10.66.110'] #被禁止访问的ip地址 def process_view(request, view_func, *view_args, **view_kwargs): user_ip = request.META[' REMOTE_ADDR '] if user_ip in BlockedIPSMiddleware.EXCLUDE_IPS: return HttpResponse('Forbidden
')
需要在settings里的MIDDLEWARE_CLASSES里注册此类:'booktest.middleware.BlockedIPSMiddleware',
中间件处理流程:
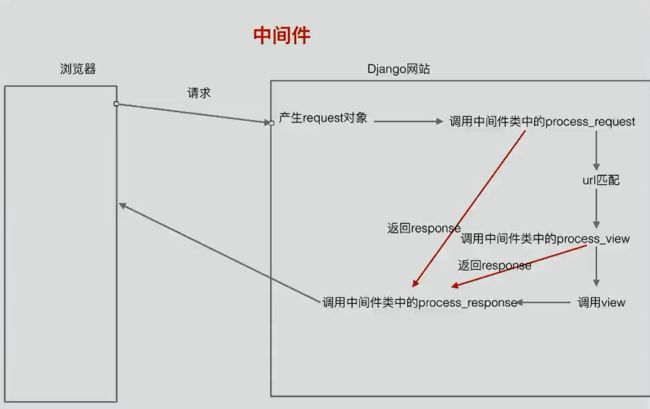
图四:中间件处理流程图
middleware.py:
class TestMiddleware(object):
__init__:服务器响应第一个请求时调用;
process_request:产生request对象
process_view:url匹配后,调用视图函数之前;
process_response(self, request, response):视图函数调用之后,内容返回给浏览器之前;
process_exception:视图哈数出现异常,会调用此函数。
如果注册的多个中间件类中包含process_exception函数时,调用的顺序和注册的顺序相反,从下往上,所有异常都是从下往上回找。
6.3、上传文件:
settings配置保存文件目录:MEDIA_ROOT = os.path.join(BASE_DIR, 'static/media')
后台管理上传图片:
设计models模型类:
class PicTest(models.Model): goods_pic = models.ImageField(upload_to = 'booktest')
迁移类文件,注册模型类即完成
用户自定义页面上传:
表单上传,HTML页面:
views.py接收:使用reqeust对象的FILES属性,类似于字典,上传文件不大于2.5M,文件存放在内存中,上传文件大于2.5M,文件内容写到一个临时文件中。request.FILES只有在请求方法为POST,且发送请求的form拥有enctype="multipart/form-data" 属性,才会包含数据。
def upload_handle(request): pic = request.FILES['pic'] # 获取处理对象 save_path = '%s/booktest/%s'%(settings.MEDIA_ROOT, pic.name) #保存路径 with open(save_path, 'wb') as f: for content in pic.chunks(): #一次返回文件的一块内容 f.write(content) PicTest.objects.create(goods_pic='booktest%s'.pic.name) return HttpResponse("上传成功!")
6.4、分页:
from django.core.paginator import Paginator paginator=Paginator(areas, 10) #按每页10条数据进行分页
Paginator类对象的属性:
| 属性名 |
说明 |
| num_pages |
返回分页之后的总页数 |
| page_range |
返回分页后页码的列表 |
Paginator类对象的方法:
| 方法名 |
说明 |
| page(self, number) |
返回第number也的Page类实例对象 |
Page类对象的方法:
| 属性名 |
说明 |
| has_previous |
判断当前页是否有前一页 |
| has_next |
判断当前页是否有下一页 |
| previous_page_number |
返回前一页的页码 |
| next_page_number |
返回下一页的页码 |
booktest/urls.py:
url(r'^show_area(?P\d*)$ ', view.show_area), #分页,接收页面传来的页码
views.py:
from django.core.paginator import Paginator def show_area(request, pindex): ares = AreaInfo.objects.filter(aParent__isnull=True) #查询信息 paginator = Paginator(ares, 10) if pindex =='': pindex = 1 #默认取第一页内容 else: pindex = int(pindex) page = paginator.page(pindex) #获取第i页内容 return render(request, 'booktest/show_area.html', {'page': page})
HTML:
-
{% for area in page.object_list %}或者{% for area in page %}
- {{ area.atitle }} {% endfor %}
Word文档笔记看起更爽更全面:可联系作者