kubernetes与kubeflow一站式搭建
欢迎观看,有什么问题可以在源仓库提下issue,可以一起学习讨论
https://github.com/JK-97/my_note
一、前期准备
k8s有很多种搭建方式,google上查找的大部分教程都是基于AWS和GCP的,而网上搭建本地的集群的教程极为零散。
那么接下就开始搭建之路吧!
示例环境
master 192.168.0.105
node 192.168.0.115
已经适配的版本:
- kubernets
kubeadm kubelet kubectl 全部要统一版本v1.12.8
- docker :
Client:
Version: 17.12.1-ce
API version: 1.35
Go version: go1.9.4
Git commit: 7390fc6
Built: Tue Feb 27 22:17:40 2018
OS/Arch: linux/amd64
Server:
Engine:
Version: 17.12.1-ce
API version: 1.35 (minimum version 1.12)
Go version: go1.9.4
Git commit: 7390fc6
Built: Tue Feb 27 22:16:13 2018
OS/Arch: linux/amd64
Experimental: false- nvidia-docker
NVIDIA Docker: 2.0.3
Client:
Version: 17.12.1-ce
API version: 1.35
Go version: go1.9.4
Git commit: 7390fc6
Built: Tue Feb 27 22:17:40 2018
OS/Arch: linux/amd64
Server:
Engine:
Version: 17.12.1-ce
API version: 1.35 (minimum version 1.12)
Go version: go1.9.4
Git commit: 7390fc6
Built: Tue Feb 27 22:16:13 2018
OS/Arch: linux/amd64
Experimental: false相关命令
$ kubeadm version
$ docker version
$ nvidia-docker version
第一步:安装docker
# 安装最新版本
$ sudo apt-get update
$ sudo apt-get install \
apt-transport-https \
ca-certificates \
curl \
gnupg-agent \
software-properties-common
$ curl -fsSL https://download.docker.com/linux/ubuntu/gpg | sudo apt-key add -
$ sudo apt-key fingerprint 0EBFCD88
$ sudo add-apt-repository \
"deb [arch=amd64] https://download.docker.com/linux/ubuntu \
$(lsb_release -cs) \
stable"
# 获取docker的repo
$ sudo apt-get update
$ sudo apt-get install docker-ce docker-ce-cli containerd.io
# 直接安装是安装最新版本的,这里需要安装指定版本,我们跳过# 该教程使用的就是 17.12.1~ce-0~ubuntu 版本
# 安装指定版本,紧接上一段倒数第二句命令
$ apt-cache madison docker-ce
docker-ce | 5:18.09.1~3-0~ubuntu-xenial | https://download.docker.com/linux/ubuntu xenial/stable amd64 Packages
docker-ce | 5:18.09.0~3-0~ubuntu-xenial | https://download.docker.com/linux/ubuntu xenial/stable amd64 Packages
docker-ce | 18.06.1~ce~3-0~ubuntu | https://download.docker.com/linux/ubuntu xenial/stable amd64 Packages
docker-ce | 18.06.0~ce~3-0~ubuntu | https://download.docker.com/linux/ubuntu xenial/stable amd64 Packages
·····
# 查看有什么版本
$ sudo apt-get install docker-ce= containerd.io
# eg. sudo apt-get install docker-ce=17.12.1~ce-0~ubuntu containerd.io
#这样就完成了docker的安装 第二步:安装nvidia-docker
$ docker volume ls -q -f driver=nvidia-docker | xargs -r -I{} -n1 docker ps -q -a -f volume={} | xargs -r docker rm -f
$ sudo apt-get purge -y nvidia-docker
# 卸载旧版的nvidia-docker,之前没安装就跳过
$ curl -s -L https://nvidia.github.io/nvidia-docker/gpgkey | sudo apt-key add -
$ distribution=$(. /etc/os-release;echo $ID$VERSION_ID)
$ curl -s -L https://nvidia.github.io/nvidia-docker/$distribution/nvidia-docker.list | sudo tee /etc/apt/sources.list.d/nvidia-docker.list
deb https://nvidia.github.io/libnvidia-container/ubuntu18.04/$(ARCH) /
deb https://nvidia.github.io/nvidia-container-runtime/ubuntu18.04/$(ARCH) /
deb https://nvidia.github.io/nvidia-docker/ubuntu18.04/$(ARCH) /
$ sudo apt-get update
$ sudo apt-get install -y nvidia-docker2
# 直接装是最新版本,会自动升级docker到最新版本,一般情况下我们不这么做,我们这里不适用
# 安装指定版本
$ apt-cache madison nvidia-docker2
nvidia-docker2 | 2.0.3+docker18.09.5-3 | https://nvidia.github.io/nvidia-docker/ubuntu16.04/amd64 Packages
nvidia-docker2 | 2.0.3+docker18.09.5-2 | https://nvidia.github.io/nvidia-docker/ubuntu16.04/amd64 Packages
nvidia-docker2 | 2.0.3+docker18.09.4-1 | https://nvidia.github.io/nvidia-docker/ubuntu16.04/amd64 Packages
nvidia-docker2 | 2.0.3+docker18.09.3-1 | https://nvidia.github.io/nvidia-docker/ubuntu16.04/amd64 Packages
nvidia-docker2 | 2.0.3+docker18.09.2-1 | https://nvidia.github.io/nvidia-docker/ubuntu16.04/amd64 Packages
nvidia-docker2 | 2.0.3+docker18.09.1-1 | https://nvidia.github.io/nvidia-docker/ubuntu16.04/amd64 Packages
nvidia-docker2 | 2.0.3+docker18.09.0-1 | https://nvidia.github.io/nvidia-docker/ubuntu16.04/amd64 Packages
nvidia-docker2 | 2.0.3+docker18.06.2-2 | https://nvidia.github.io/nvidia-docker/ubuntu16.04/amd64 Packages
nvidia-docker2 | 2.0.3+docker18.06.2-1 | https://nvidia.github.io/
····
# 获取到版本号后,直接装也是不行的
# 他会提示你要有新的依赖,需要安装最新的nvidia-container-runtime,实际是不需要的
# 所以安装还要带上nvidia-container-runtime并且指定一个版本
$ apt-cache madison nvidia-container-runtime
nvidia-container-runtime | 2.0.0+docker18.09.5-3 | https://nvidia.github.io/nvidia-container-runtime/ubuntu16.04/amd64 Packages
nvidia-container-runtime | 2.0.0+docker18.09.5-1 | https://nvidia.github.io/nvidia-container-runtime/ubuntu16.04/amd64 Packages
nvidia-container-runtime | 2.0.0+docker18.09.4-1 | https://nvidia.github.io/nvidia-container-runtime/ubuntu16.04/amd64 Packages
nvidia-container-runtime | 2.0.0+docker18.09.3-1 | https://nvidia.github.io/nvidia-container-runtime/ubuntu16.04/amd64 Packages
nvidia-container-runtime | 2.0.0+docker18.09.2-1 | https://nvidia.github.io/nvidia-container-runtime/ubuntu16.04/amd64 Packages
nvidia-container-runtime | 2.0.0+docker18.09.1-1 | https://nvidia.github.io/nvidia-container-runtime/ubuntu16.04/amd64 Packages
····
# 查看版本对应的docker版本
$ sudo apt-get install -y nvidia-docker2=2.0.3+docker17.12.1-1 nvidia-container-runtime=2.0.0+docker17.12.1-1
# 最终选择这样匹配的版本
# 卸载docker
$ apt autoremove docker-ce containerd.io
第三步:配置显卡
# 需要修改docker 的daemon
$ vim /etc/docker/daemon.json
# 写入以下内容
{
"registry-mirrors": ["https://registry.docker-cn.com"],
"default-runtime": "nvidia",
"runtimes": {
"nvidia": {
"path": "nvidia-container-runtime",
"runtimeArgs": []
}
}
}
$ sudo pkill -SIGHUP dockerd
$ docker run --runtime=nvidia --rm nvidia/cuda:9.0-base nvidia-smi
+-----------------------------------------------------------------------------+
| NVIDIA-SMI 418.39 Driver Version: 418.39 CUDA Version: 10.1 |
|-------------------------------+----------------------+----------------------+
| GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. |
|===============================+======================+======================|
| 0 GeForce RTX 208... Off | 00000000:19:00.0 Off | N/A |
| 22% 33C P8 1W / 250W | 1MiB / 10989MiB | 0% Default |
+-------------------------------+----------------------+----------------------+
| 1 GeForce RTX 208... Off | 00000000:1A:00.0 Off | N/A |
| 22% 36C P8 17W / 250W | 1MiB / 10989MiB | 0% Default |
+-------------------------------+----------------------+----------------------+
| 2 GeForce RTX 208... Off | 00000000:67:00.0 Off | N/A |
| 22% 37C P8 7W / 250W | 1MiB / 10989MiB | 0% Default |
+-------------------------------+----------------------+----------------------+
| 3 GeForce RTX 208... Off | 00000000:68:00.0 On | N/A |
| 23% 42C P8 10W / 250W | 282MiB / 10981MiB | 0% Default |
+-------------------------------+----------------------+----------------------+
+-----------------------------------------------------------------------------+
| Processes: GPU Memory |
| GPU PID Type Process name Usage |
|=============================================================================|
+-----------------------------------------------------------------------------+
# 出现结果说明docker可以调用GPU了
第四步:装kubeadm kubelet kubectl
# 安装最新版本kubernet管理套件
$ apt-get update && apt-get install -y apt-transport-https
$ curl https://mirrors.aliyun.com/kubernetes/apt/doc/apt-key.gpg | apt-key add -
$ cat </etc/apt/sources.list.d/kubernetes.list
deb https://mirrors.aliyun.com/kubernetes/apt/ kubernetes-xenial main
EOF
$ apt-get update
$ apt-get install -y kubelet kubeadm kubectl
# 直接安装是获取最新版本,我们不使用 # 获取指定的版本
# 接上面倒数第二条命令
$ apt-cache madison kubeadm
kubeadm | 1.14.1-00 | https://mirrors.aliyun.com/kubernetes/apt kubernetes-xenial/main amd64 Packages
kubeadm | 1.14.0-00 | https://mirrors.aliyun.com/kubernetes/apt kubernetes-xenial/main amd64 Packages
kubeadm | 1.13.5-00 | https://mirrors.aliyun.com/kubernetes/apt kubernetes-xenial/main amd64 Packages
kubeadm | 1.13.4-00 | https://mirrors.aliyun.com/kubernetes/apt kubernetes-xenial/main amd64 Packages
kubeadm | 1.13.3-00 | https://mirrors.aliyun.com/kubernetes/apt kubernetes-xenial/main amd64 Packages
kubeadm | 1.13.2-00 | https://mirrors.aliyun.com/kubernetes/apt kubernetes-xenial/main amd64 Packages
kubeadm | 1.13.1-00 | https://mirrors.aliyun.com/kubernetes/apt kubernetes-xenial/main amd64 Packages
····
apt-get install -y kubelet=1.12.8-00 kubeadm=1.12.8-00 kubectl=1.12.8-00# 卸载
apt autoremove kubeadm kubelet kubectl kubernetes-cni二、k8s搭建
第一步:将子节点录入
# 以下操作除开特别说明处都在master 192.168.0.105上执行
$ kubeadm init --pod-network-cidr=10.244.0.0/16
# 同kubeadm管理工具搭建kubernets,拉取与kubeadm版本一致的的kubernets镜像创建
# --pod-network-cidr=10.244.0.0/16 集群内部网段
kubeadm join 192.168.0.105:6443 --token aoanr5.geidnr74gvp5xrlc --discovery-token-ca-cert-hash sha256:beb198cf8a70ff17c96b387b06de16d6973f9b8cacb1a8e1586b52ff5f84db0c
# 会在最后生成这个tocken
$ mkdir -p $HOME/.kube
$ sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
$ sudo chown $(id -u):$(id -g) $HOME/.kube/config
# 这3句命令使kubectl获取权限。用户配置,hash验证等信息,都在 $HOME/.kube/config 文件中
----------------------
# 这时在ndoe 192.168.0.115 操作,复制master上的tocken
$ kubeadm join 192.168.0.105:6443 --token aoanr5.geidnr74gvp5xrlc --discovery-token-ca-cert-hash sha256:beb198cf8a70ff17c96b387b06de16d6973f9b8cacb1a8e1586b52ff5f84db0c
---------------------
$ kubectl get nodes
NAME STATUS ROLES AGE VERSION
jiang-pc NoReady 21h v1.12.8
jiangxing-pc NoReady master 21h v1.12.8
# 就可以在master上看到所有的node机子了,但是还是noready状态。
# 因为他们还不具备网段通讯的基础,所以需要安装网段策略。晚上 第二步:安装网段策略
$ kubectl apply -f https://docs.projectcalico.org/v3.1/getting-started/kubernetes/installation/hosted/canal/rbac.yaml
clusterrole.rbac.authorization.k8s.io "calico" created
clusterrole.rbac.authorization.k8s.io "flannel" created
clusterrolebinding.rbac.authorization.k8s.io "canal-flannel" created
clusterrolebinding.rbac.authorization.k8s.io "canal-calico" create
$ kubectl apply -f https://docs.projectcalico.org/v3.1/getting-started/kubernetes/installation/hosted/canal/canal.yaml
configmap "canal-config" created
daemonset.extensions "canal" created
customresourcedefinition.apiextensions.k8s.io "felixconfigurations.crd.projectcalico.org" created
customresourcedefinition.apiextensions.k8s.io "bgpconfigurations.crd.projectcalico.org" created
customresourcedefinition.apiextensions.k8s.io "ippools.crd.projectcalico.org" created
customresourcedefinition.apiextensions.k8s.io "clusterinformations.crd.projectcalico.org" created
customresourcedefinition.apiextensions.k8s.io "globalnetworkpolicies.crd.projectcalico.org" created
customresourcedefinition.apiextensions.k8s.io "networkpolicies.crd.projectcalico.org" created
serviceaccount "canal" created
# 配置内部网段的策略
$ kubectl get pod -n kube-system -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE
canal-hnbdf 3/3 Running 0 20h 192.168.0.105 jiangxing-pc
canal-p9t59 3/3 Running 0 20h 192.168.0.115 jiang-pc
coredns-576cbf47c7-6d58x 1/1 CrashLoopBackOff 45 21h 10.244.0.2 jiangxing-pc
coredns-576cbf47c7-q6629 1/1 CrashLoopBackOff 46 21h 10.244.0.3 jiangxing-pc
etcd-jiangxing-pc 1/1 Running 2 21h 192.168.0.105 jiangxing-pc
kube-apiserver-jiangxing-pc 1/1 Running 4 21h 192.168.0.105 jiangxing-pc
kube-controller-manager-jiangxing-pc 1/1 Running 2 21h 192.168.0.105 jiangxing-pc
kube-proxy-bqms2 1/1 Running 2 21h 192.168.0.105 jiangxing-pc
kube-proxy-vz9f8 1/1 Running 2 21h 192.168.0.115 jiang-pc
kube-scheduler-jiangxing-pc 1/1 Running 2 21h 192.168.0.105 jiangxing-pc
# 大概等待2分钟,需抓取镜像,时间看网速,一般1min,查看canal的安装状态
# 我们看到coredns是启动不起来的,这个东西很重要,先吧不用着急,后面会讲解
$ kubectl get nodes
NAME STATUS ROLES AGE VERSION
jiang-pc Ready 21h v1.12.8
jiangxing-pc Ready master 21h v1.12.8
# 然后你就可以看到节点都在Ready状态 第三步:解决coredns pod CrashLoopBackOff
$ kubectl -n kube-system edit configmap coredns
# 在所有的节点都要操作
# 然后删除显示 loop 的行,并保存配置。
# k8s可能需要几分钟才能将配置更改传播到coredns pod
#下面是删除后的样子,保存退出
# Please edit the object below. Lines beginning with a '#' will be ignored,
# and an empty file will abort the edit. If an error occurs while saving this file will be
# reopened with the relevant failures.
#
apiVersion: v1
data:
Corefile: |
.:53 {
errors
health
kubernetes cluster.local in-addr.arpa ip6.arpa {
pods insecure
upstream
fallthrough in-addr.arpa ip6.arpa
}
prometheus :9153
proxy . /etc/resolv.conf
cache 30
reload
loadbalance
}
kind: ConfigMap
metadata:
creationTimestamp: 2019-05-05T08:22:27Z
name: coredns
namespace: kube-system
resourceVersion: "9385"
selfLink: /api/v1/namespaces/kube-system/configmaps/coredns
uid: eb157cfb-6f0e-11e9-92a9-0492264b2d9d三、kubeflow搭建
第一步:安装NVIDIA GPU device plugin
# 自从k8s 1.8版本开始,官方开始推荐使用device plugin的方式来调用GPU使用。截至目前,Nvidia和AMD都推出了相#应的设备插件,使得k8s调用GPU变得容易起来。因为我们是Nvidia的显卡,所以需要安装NVIDIA GPU device plugin
# 前面我们已经设置好了/etc/docker/daemon.json配置
# 通过kubeadm部署的Kubernetes cluster,需要打开kubeadm 的systemd unit文件,位于 /etc/systemd/system/kubelet.service.d/10-kubeadm.conf 然后添加下面的参数作为环境变量
# 同样在所有节点都需要配置
$ vim /etc/systemd/system/kubelet.service.d/10-kubeadm.conf
# 添加下面所示的行
Environment="KUBELET_GPU_ARGS=--feature-gates=DevicePlugins=true"
# 完整文件如下
# Note: This dropin only works with kubeadm and kubelet v1.11+
[Service]
Environment="KUBELET_KUBECONFIG_ARGS=--bootstrap-kubeconfig=/etc/kubernetes/bootstrap-kubelet.conf --kubeconfig=/etc/kubernetes/kubelet.conf"
Environment="KUBELET_CONFIG_ARGS=--config=/var/lib/kubelet/config.yaml"
Environment="KUBELET_GPU_ARGS=--feature-gates=DevicePlugins=true"
# This is a file that "kubeadm init" and "kubeadm join" generates at runtime, populating the KUBELET_KUBEADM_ARGS variable dynamically
EnvironmentFile=-/var/lib/kubelet/kubeadm-flags.env
# This is a file that the user can use for overrides of the kubelet args as a last resort. Preferably, the user should use
# the .NodeRegistration.KubeletExtraArgs object in the configuration files instead. KUBELET_EXTRA_ARGS should be sourced from this file.
EnvironmentFile=-/etc/default/kubelet
ExecStart=
ExecStart=/usr/bin/kubelet $KUBELET_KUBECONFIG_ARGS $KUBELET_CONFIG_ARGS $KUBELET_KUBEADM_ARGS $KUBELET_EXTRA_ARGS
$ sudo systemctl daemon-reload
$ sudo systemctl restart kubelet
# 重新载入配置文件,然后重新启动服务
# 完成所有的GPU节点的选项启用,然后就可以在在Kubernetes中启用GPU支持,通过安装Nvidia提供的Daemonset服务来实现,方法如下(2选1,推荐使用v1.11):
$ kubectl create -f https://raw.githubusercontent.com/NVIDIA/k8s-device-plugin/v1.11/nvidia-device-plugin.yml
$ kubectl create -f https://raw.githubusercontent.com/NVIDIA/k8s-device-plugin/v1.10/nvidia-device-plugin.yml
# 查看nvidia-device-plugin 的 pod是否启动,会拉取镜像,时间看网速
$ kubectl get pod -n kube-system -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE
canal-hnbdf 3/3 Running 0 21h 192.168.0.105 jiangxing-pc
canal-p9t59 3/3 Running 0 21h 192.168.0.115 jiang-pc
coredns-576cbf47c7-6d58x 1/1 Running 45 22h 10.244.0.2 jiangxing-pc
coredns-576cbf47c7-q6629 1/1 Running 46 22h 10.244.0.3 jiangxing-pc
etcd-jiangxing-pc 1/1 Running 2 22h 192.168.0.105 jiangxing-pc
kube-apiserver-jiangxing-pc 1/1 Running 4 22h 192.168.0.105 jiangxing-pc
kube-controller-manager-jiangxing-pc 1/1 Running 2 22h 192.168.0.105 jiangxing-pc
kube-proxy-bqms2 1/1 Running 2 22h 192.168.0.105 jiangxing-pc
kube-proxy-vz9f8 1/1 Running 2 22h 192.168.0.115 jiang-pc
kube-scheduler-jiangxing-pc 1/1 Running 2 22h 192.168.0.105 jiangxing-pc
nvidia-device-plugin-daemonset-1.12-8s2vt 1/1 Running 0 21h 10.244.1.3 jiang-pc
nvidia-device-plugin-daemonset-99w5k 1/1 Running 0 21h 10.244.1.2 jiang-pc
# 可以用以下命令测试device-plugin在节点上是否生效
$ docker run --security-opt=no-new-privileges --cap-drop=ALL --network=none -it -v /var/lib/kubelet/device-plugins:/var/lib/kubelet/device-plugins nvidia/k8s-device-plugin:1.11
# 出现以下信息代表没生效
2018/11/08 02:58:17 Loading NVML
2018/11/08 02:58:17 Failed to initialize NVML: could not load NVML library.
2018/11/08 02:58:17 If this is a GPU node, did you set the docker default runtime to nvidia?
2018/11/08 02:58:17 You can check the prerequisites at: https://github.com/NVIDIA/k8s-device-plugin#prerequisites
2018/11/08 02:58:17 You can learn how to set the runtime at: https://github.com/NVIDIA/k8s-device-plugin#quick-start
# 出现以下信息代表生效了
2018/11/08 02:58:46 Loading NVML
2018/11/08 02:58:46 Fetching devices.
2018/11/08 02:58:46 Starting FS watcher.
2018/11/08 02:58:46 Starting OS watcher.
2018/11/08 02:58:46 Starting to serve on /var/lib/kubelet/device-plugins/nvidia.sock
2018/11/08 02:58:46 Registered device plugin with Kubelet
# 安装了device-plugin后,device-plugin Pod正常启动,但是依旧无法调用GPU资源,查看Node节点信息发现GPU处数量为0
# 当时遇见该问题的过程为:修改Docker配置,安装device-plugin,无法启动,重启Docker,device-plugin启动正常,但GPU无法调用
# 原因就在于启动device-plugin的时候Docker配置没有生效,虽然后续重启Docker了,但是device-plugin的Pod没有更新,所以依旧捕获不到GPU信息。解决办法是杀掉device-plugin的Pod,让其重新生成
$ kubectl describe nodes
# 查看节点的信息,就会看到节点信息中存在 nvidia.com/gpu
···
Addresses:
InternalIP: 192.168.0.115
Hostname: jiang-pc
Capacity:
cpu: 20
ephemeral-storage: 245016792Ki
hugepages-1Gi: 0
hugepages-2Mi: 0
memory: 32600796Ki
nvidia.com/gpu: 4
pods: 110
Allocatable:
cpu: 20
ephemeral-storage: 225807475134
hugepages-1Gi: 0
hugepages-2Mi: 0
memory: 32498396Ki
nvidia.com/gpu: 4
pods: 110
···
第二步:安装ksonet与kfctl
# 什么是ksonnet?
# 他是一个kubernet的快速部署应用的一个工具,迁移一个应用时就会用到他,所以安装kubeflow时就会用到他,因为kubeflow其实是多个子应用组成的综合性服务
# 先下载ksonnet安装包,下载地址 https://github.com/ksonnet/ksonnet/releases,拿到最新版本的链接
# 教程使用的版本是ks_0.13.1_linux_amd64.tar.gz
$ wget https://github.com/ksonnet/ksonnet/releases/download/v0.13.1/ks_0.13.1_linux_amd64.tar.gz
$ tar -xvf ks_0.13.1_linux_amd64.tar.gz
$ cp ks_0.13.1_linux_amd64/* /usr/local/bin/
# 什么是kfctl?
# 他是一个部署kubeflow的脚本工具
# 下载地址https://github.com/kubeflow/kubeflow/releases/
# 教程使用的版本时kfctl_v0.5.0_linux.tar.gz
$ wget https://github.com/kubeflow/kubeflow/releases/download/v0.5.0/kfctl_v0.5.0_linux.tar.gz
$ tar -zxvf kfctl_v0.5.0_linux.tar.gz
$ cp kfctl /usr/bin/第三步:部署kubeflow
$ export KFAPP=mykfapp
# export KFAPP=<你的kubeflow app 名字>
$ kfctl init ${KFAPP}
# 初始化
$ cd ${KFAPP}
# 进入生成的mykfapp命令
# 有文件app.yaml
$ kfctl generate k8s -V
$ kfctl apply k8s -V
# 有文件app.yaml ks_app第四步:安装seldon
# 目前Kubeflow使用ksonnet管理包
# kfctl在kubeflow应用程序中创建一个名为ks_app的ksonnet应用程序。随附kubeflow的Ksonnet软件包可以通过运行ks pkg install kubeflow / [package_name]进入ks_app目录来安装。
$ cd ks_app
$ ks pkg install kubeflow/seldon
$ ks pkg list
# ks_app目录下执行
# 观看安装的包
REGISTRY NAME VERSION INSTALLED ENVIRONMENTS
======== ==== ======= ========= ============
kubeflow application master
kubeflow argo *
kubeflow argo master
kubeflow automation master
kubeflow chainer-job master
kubeflow common *
kubeflow common master
kubeflow examples *
kubeflow examples master
kubeflow gcp *
kubeflow gcp master
kubeflow jupyter *
kubeflow jupyter master
kubeflow katib *
kubeflow katib master
kubeflow kubebench master
kubeflow metacontroller *
kubeflow metacontroller master
kubeflow modeldb *
kubeflow modeldb master
kubeflow mpi-job *
kubeflow mpi-job master
kubeflow mxnet-job master
kubeflow new-package-stub master
kubeflow nvidia-inference-server master
kubeflow openvino master
kubeflow pachyderm master
kubeflow pipeline *
kubeflow pipeline master
kubeflow profiles master
kubeflow pytorch-job *
kubeflow pytorch-job master
kubeflow seldon *
kubeflow seldon master
kubeflow tensorboard *
kubeflow tensorboard master
kubeflow tf-batch-predict master
kubeflow tf-serving *
kubeflow tf-serving master
kubeflow tf-training *
kubeflow tf-training master
$ ks generate seldon seldon
$ ks component list
# 您应该在此列表中看到seldon,如果不是,请仔细检查您的生成是否成功。
COMPONENT
=========
ambassador
application
argo
centraldashboard
cert-manager
cloud-endpoints
iap-ingress
jupyter
katib
metacontroller
notebooks
openvino
pipeline
profiles
pytorch-operator
seldon
spartakus
tf-job-operator
$ ks apply default -c seldon第五步:观察kubeflow是否成功部署
$ kubectl get pod --all-namespaces
# 通过观看pod节点的的运行状态
# 刚开始时会有很多pod节点都在CrashLoopBackOff状态,是因为都需要拿去镜像建立
# 大概等待30分钟,就可以进入running
# 一定要进入running状态的是
# 下面是pod信息
NAMESPACE NAME READY STATUS RESTARTS AGE
kube-system pod/canal-hnbdf 3/3 Running 0 22h
kube-system pod/canal-p9t59 3/3 Running 0 22h
kube-system pod/coredns-576cbf47c7-6d58x 1/1 Running 45 23h
kube-system pod/coredns-576cbf47c7-q6629 1/1 Running 46 23h
kube-system pod/etcd-jiangxing-pc 1/1 Running 2 23h
kube-system pod/kube-apiserver-jiangxing-pc 1/1 Running 4 23h
kube-system pod/kube-controller-manager-jiangxing-pc 1/1 Running 2 23h
kube-system pod/kube-proxy-bqms2 1/1 Running 2 23h
kube-system pod/kube-proxy-vz9f8 1/1 Running 2 23h
kube-system pod/kube-scheduler-jiangxing-pc 1/1 Running 2 23h
kube-system pod/nvidia-device-plugin-daemonset-1.12-8s2vt 1/1 Running 0 22h
kube-system pod/nvidia-device-plugin-daemonset-99w5k 1/1 Running 0 22h
kubeflow pod/ambassador-7b8477f667-4bjbq 1/1 Running 34 22h
kubeflow pod/ambassador-7b8477f667-kzn8g 1/1 Running 15 22h
kubeflow pod/ambassador-7b8477f667-x2l6p 1/1 Running 23 22h
kubeflow pod/argo-ui-9cbd45fdf-vd4xp 1/1 Running 0 22h
kubeflow pod/centraldashboard-796c755dcf-cqmcn 1/1 Running 0 22h
kubeflow pod/jupyter-web-app-6866fc55f9-d9rjb 1/1 Running 0 22h
kubeflow pod/katib-ui-7c6997fd96-zzwkr 1/1 Running 0 22h
kubeflow pod/metacontroller-0 1/1 Running 0 22h
kubeflow pod/minio-594df758b9-p2wp7 0/1 Pending 0 22h
kubeflow pod/ml-pipeline-59bc76b9cf-nvwr4 1/1 Running 163 22h
kubeflow pod/ml-pipeline-persistenceagent-6b47685656-8mt5c 0/1 CrashLoopBackOff 178 22h
kubeflow pod/ml-pipeline-scheduledworkflow-75bf95745d-77xkm 1/1 Running 0 22h
kubeflow pod/ml-pipeline-ui-7f7bb7df6d-gzb66 1/1 Running 0 22h
kubeflow pod/ml-pipeline-viewer-controller-deployment-5bd64877d8-b778r 1/1 Running 0 22h
kubeflow pod/mysql-5d5b5475c4-mhz8l 0/1 Pending 0 22h
kubeflow pod/notebooks-controller-685db44f8c-5kz5g 1/1 Running 0 22h
kubeflow pod/pytorch-operator-9996bcb49-6c6l8 1/1 Running 0 22h
kubeflow pod/seldon-redis-6c867f7c9d-n7cqm 1/1 Running 0 22h
kubeflow pod/seldon-seldon-cluster-manager-7fd685c95-h6kwm 1/1 Running 0 22h
kubeflow pod/sencond-0 1/1 Running 0 6h13m
kubeflow pod/shenmingjie-0 1/1 Running 0 5h9m
kubeflow pod/studyjob-controller-57cb6746ff-jvcv5 1/1 Running 0 22h
kubeflow pod/tensorboard-76dffc9ffc-kcjbs 1/1 Running 0 22h
kubeflow pod/tf-job-dashboard-84bdddd5cc-rlqd5 1/1 Running 0 22h
kubeflow pod/tf-job-operator-8486555578-hjmft 1/1 Running 0 22h
kubeflow pod/vizier-core-bcc86677d-mn786 0/1 CrashLoopBackOff 417 22h
kubeflow pod/vizier-core-rest-68c7577f84-dqc7j 1/1 Running 0 22h
kubeflow pod/vizier-db-54f46c46c6-bbzn6 0/1 Pending 0 22h
kubeflow pod/vizier-suggestion-bayesianoptimization-97f4f76dd-7mng6 1/1 Running 0 22h
kubeflow pod/vizier-suggestion-grid-6f94f98f9d-56ch7 1/1 Running 0 22h
kubeflow pod/vizier-suggestion-hyperband-68f4cc7f5d-8g66j 1/1 Running 0 22h
kubeflow pod/vizier-suggestion-random-6ff5b8f6d8-9sw6z 1/1 Running 0 22h
kubeflow pod/workflow-controller-d5cb6468d-gxsct 1/1 Running 0 22h第六步:kubeflow web ui
# 在master上配置ambassador映射ip
$ kubectl -n kubeflow edit svc ambassador
# 文中加入externalIPs + 你master的ip,譬如:
spec:
clusterIP: 10.107.127.1
externalIPs: # Newly added
- 192.168.0.105 # Newly added
externalTrafficPolicy: Cluster
$ export NAMESPACE=kubeflow
$ kubectl port-forward svc/ambassador -n ${NAMESPACE} 8080:80
# 映射到80端口
# 就可以访问了http://localhost:8080/五、使用方法
1. 登录到网站
2. 左侧栏选择notebooks

3. 点击newserver
4. 创建名字,选镜像
5. 配置CPU与MEM
6. 配置Volume(暂时不可以使用,不然server会创建不了)
7. 选择GPU数量
资源是独占的 所以最多4个服务可以用显卡, 暂时不知道什么原因 2张1080ti没显示出来,4张2080ti可以用。
六、其他
GPU驱动cuda与cudnn
本教程主要针对-新装机-进行配置,使用过一段时间的机子可能会在 步骤4安装***.run 报错误
- 步骤1:
首先先安装ubuntu16.04
tips:在选择是否安装第三方驱动和更新时,不选择,直接跳过。
- 步骤2:
进入系统,打开浏览器先下载cuda,选择.run格式的驱动(cuda_10.1.105_418.39_linux.run),将文件复制到home目录下
tips:由于cuda里自带了驱动,所以我们可以跳过安装驱动的步骤

- 步骤3:
打开终端(vim没安装的 需要先安装)
$ sudo apt-get install vim将nouveau禁用
$ sudo vim /etc/modprobe.d/blacklist.conf在vim中进入编辑状态,下拉到文件末尾,添加下面内容:
blacklist nouveau
options nouveau modeset=0
保存退出
更新刚才的配置
$ sudo update-initramfs -u* 重启
sudo reboot- 步骤4
打开终端,关闭图形界面
$ sudo service lightdm stoptips:会进入黑屏,正常情况
键入Ctrl +Alt+F1,输入用户名,输入密码。发现进入home目录
修改文件的读写权限
$ sudo chmod 777 *.run安装驱动与cuda
$ sudo ./cuda_10.1.105_418.39_linux.run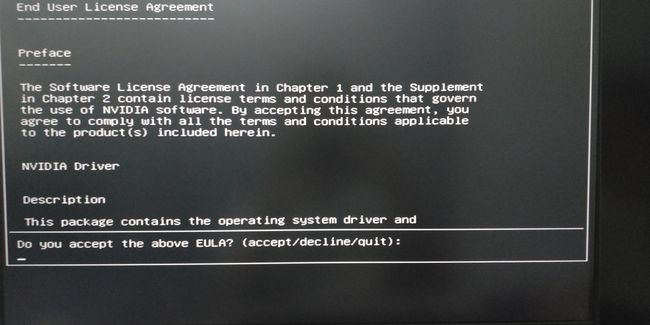

- 步骤5
- 等待30s左右出现选择界面
- 只需全部选择即可
- 安装完成后重启
- 进入终端输入,出现显卡信息和cuda的版本信息就说明驱动已经安装完成
nvidia-smi- 步骤6
在终端输入
$ sudo gedit ~/.bashrc在末尾添加
tips:若安装不一样的版本,请更改好对应的路径名
export PATH=/usr/local/cuda-10.1/bin:$PATH
export LD_LIBRARY_PATH=/usr/local/cuda-10.1/lib64:$LD_LIBRARY_PATH终端输入,出现cuda的信息说明cuda安装完成
$ source ~/.bashrc
$ nvcc --version- 步骤7
cuda安装好,还需要配置cudnn
到官网下载cudnn,点击download,会让你先登录账号,先注册
注册勾选同意协议会出现如下界面
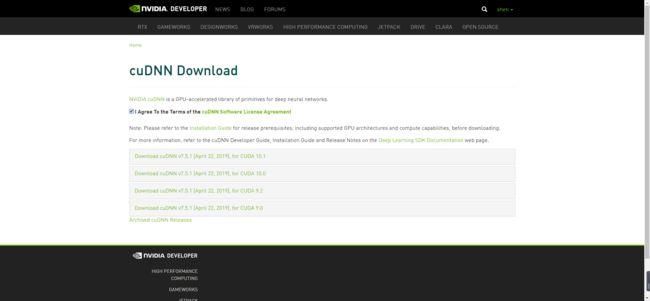
选择对应cuda版本的cudnn,本教程使用的时cuda10.1,所以选择第一个,在选择cuDNN Library for Linux

解压到当前目录,会有cuda这个文件夹
在终端执行以下命令
tips:若安装不一样的版本,请更改好对应的路径名
$ sudo cp cuda/include/cudnn.h /usr/local/cuda-10.1/include
$ sudo cp cuda/lib64/libcudnn* /usr/local/cuda-10.1/lib64
$ sudo chmod a+r /usr/local/cuda/include/cudnn.h /usr/local/cuda-10.1/lib64/libcudnn*
$ source ~/.bashrc检查cudnn是否配置完成
$ nvcc --version
$ cd /usr/local/cuda-10.0/samples/1_Utilities/deviceQuery
$ sudo make
$ ./deviceQuery* 出现pass说明环境搭建好了