TF官网上给出了三种读取数据的方式:
- Preloaded data: 预加载数据
- Feeding: Python 产生数据,再把数据喂给后端
- Reading from file:从文件中直接读取
(Ps: 此处参考博客 详解TF数据读取有三种方式(next_batch))
(Pps: 文中的代码均基于Python3.6版本)
TF的核心是用C++写的,运行快,但是调用不灵活。结合Python和TF,将计算的核心算子和运行框架用C++写,然后以API的形式提供给Python调用。Python的主要工作是设计计算图(模型及数据),将设计好的Graph提供给后端执行。简而言之,TF是Run,Pyhton的角色是Design。
一. Preloaded Data
- constant,常量
- variable,初始化或者后面更新均可
这种数据读取方式只适合小数据,通常在程序中定义某固定值,如循环次数等,而很少用来读取训练数据。
import tensorflow as tf
# 设计Graph
a = tf.constant([1, 2, 3])
b = tf.Variable([1, 2, 4])
c = tf.add(a, b)
二. Feeding
Feeding的方式在设计Graph的时候留占位符,在真正Run的时候向占位符中传递数据,喂给后端训练。
#!/usr/bin/env python3
# _*_coding:utf-8 _*_
import tensorflow as tf
# 设计Graph
a = tf.placeholder(tf.int16)
b = tf.placeholder(tf.int16)
c = tf.add(a, b)
# 用Python产生数据
li1 = [2, 3, 4] # li1:: [2, 3, 4]
li2 = [4, 0, 1]
# 打开一个session --> 喂数据 --> 计算y
with tf.Session() as sess:
print(sess.run(c, feed_dict={a: li1, b: li2})) # [6, 3, 5]
这里tf.placeholder代表占位符,先定一下变量a的类型。在实际运行的时候,通过feed_dict来指定a在计算中的实际值。
这种数据读取方式非常灵活,而且易于理解,但是在读取大数据时会非常吃力。
三. Read from file
官网上给出的例子是从csv等文件中读取数据,这里都会涉及到队列的概念, 我们首先简单介绍一下Queue读取数据的原理,便于后面代码的理解。(参考 Blog)
读取数据其实是为了后续的计算,以图片为例,假设我们的硬盘中有一个图片数据集0001.jpg,0002.jpg,0003.jpg……我们只需要把它们读取到内存中,然后提供给GPU或是CPU进行计算就可以了。这听起来很容易,但事实远没有那么简单。事实上,我们必须要把数据先读入后才能进行计算,假设读入用时0.1s,计算用时0.9s,那么就意味着每过1s,GPU都会有0.1s无事可做,这就大大降低了运算的效率。
队列的存在就是为了使计算的速度不完全受限于数据读取的速度,保证有足够多的数据喂给计算。如图所示,将数据的读入和计算分别放在两个线程中,读入的数据保存为内存中的一个队列,负责计算的线程可以源源不断地从内存队列中读取数据。这样就解决了GPU因为IO而空闲的问题。

文件名队列,我们用tf.train.string_input_producer()函数创建文件名队列。
tf.train.string_input_producer(
string_tensor, # 文件名列表
num_epochs=None, # epoch的个数,None代表无限循环
shuffle=True, # 一个epoch内的样本(文件)顺序是否打乱
seed=None, # 当shuffle=True时才用,应该是指定一个打乱顺序的入口
capacity=32, # 设置队列的容量
shared_name=None,
name=None,
cancel_op=None)
ps: 在Tensorflow中,内存队列不需要我们自己建立,后续只需要使用reader从文件名队列中读取数据就可以。
tf.train.string_input_produecer()会将一个隐含的QueueRunner添加到全局图中(类似的操作还有tf.train.shuffle_batch()等)。由于没有显式地返回QueueRunner()来调用create_threads()启动线程,这里使用了tf.train.start_queue_runners()方法直接启动tf.GraphKeys.QUEUE_RUNNERS集合中的所有队列线程。
在我们使用tf.train.string_input_producer创建文件名队列后,整个系统其实还是处于“停滞状态”的,也就是说,我们文件名并没有真正被加入到队列中(如下图所示)。此时如果我们开始计算,因为内存队列中什么也没有,计算单元就会一直等待,导致整个系统被阻塞。
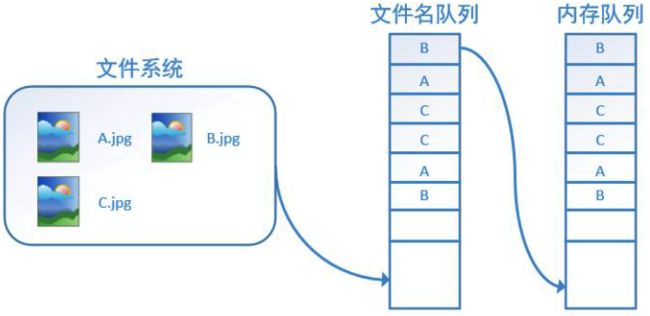
在读取文件的整个过程中会涉及到:
- 文件名队列创建: tf.train.string_input_producer()
- 文件阅读器: tf.TFRecordReader()
- 文件解析器:tf.parse_single_example() 或者decode_csv()
- Batch_size:tf.train.shuffle_batch()
- 填充进程:tf.train.start_queue_runners()
下面我们用python生成数据,并将数据转换成tfrecord格式,然后读取tfrecord文件。在这过程中,我们会介绍几种不同的从文件读取数据的方法。
生成数据:
#!/usr/bin/env python3
# _*_coding:utf-8 _*_
import os
import numpy as np
'''
二分类问题,样本数据是形如1,2,5,8,9(1*5)的随机数,对应标签是0或1
arg:
data_filename: 路径下的文件名 'data/data_train.txt'
size: 设定生成样本数据的size=(10000, 5),其中10000是样本个数,5是单个样本的特征。
'''
gene_data = 'data/data_train.txt'
size = (100000, 5)
def generate_data(gene_data, size):
if not os.path.exists(gene_data):
np.random.seed(9)
x_data = np.random.randint(0, 10, size=size)
# 这里设置标签值一半样本是0,一半样本是1
y1_data = np.ones((size[0]//2, 1), int) # 这里需要注意python3和python2的区别。
y2_data = np.zeros((size[0]//2, 1), int) # python2用/得到整数,python3要用//。否则会报错“'float' object cannot be interpreted as an integer”
y_data = np.append(y1_data, y2_data)
np.random.shuffle(y_data)
# 将样本和标签以1 2 3 6 8/1的形式来保存
xy_data = str('')
for xy_row in range(len(x_data)):
x_str = str('')
for xy_col in range(len(x_data[0])):
if not xy_col == (len(x_data[0])-1):
x_str =x_str+str(x_data[xy_row, xy_col])+' '
else:
x_str = x_str + str(x_data[xy_row, xy_col])
y_str = str(y_data[xy_row])
xy_data = xy_data+(x_str+'/'+y_str + '\n')
#print(xy_data[1])
# write to txt 保存成txt格式
write_txt = open(gene_data, 'w')
write_txt.write(xy_data)
write_txt.close()
return
# generate_data(gene_data=gene_data, size=size) # 取消注释后可以直接生成数据
从txt文件中读取数据,并转换成TFrecord格式
tfrecord数据文件是一种将数据和标签统一存储的二进制文件,能更好的利用内存,在tensorflow中快速的复制,移动,读取,存储等。
TFRecord 文件中的数据是通过 tf.train.Example() 以 Protocol Buffer(协议缓冲区) 的格式存储。Protocol Buffer是Google的一种数据交换的格式,他独立于语言,独立于平台,以二进制的形式存在,能更好的利用内存,方便复制和移动。
tf.train.Example()包含Features字段,通过feature将数据和label进行统一封装, 然后将example协议内存块转化为字符串。tf.train.Features()是字典结构,包括字符串格式的key,可以自己定义key。与key对应的是value值,这里需要注意的是,feature的value值只支持列表,可以是字符串(Byteslist),浮点数列表(Floatlist)和整型数列表(int64list),所以,在给value赋值时一定要注意类型将数据转换为这三种类型的列表。
- 类型为标量:如0,1标签,转为列表。 tf.train.Int64List(value=[label])
- 类型为数组:sample = [1, 2, 3],tf.train.Int64List(value=sample)
- 类型为矩阵:sample = [[1, 2, 3], [1, 2 ,3]],
两种方式:
转成list类型:将张量fatten成list(向量)
转成string类型:将张量用.tostring()转换成string类型。
同时要记得保存形状信息,在读取后恢复shape。
'''
读取txt中的数据,并将数据保存成tfrecord文件
arg:
txt_filename: 是txt保存的路径+文件名 'data/data_train.txt'
tfrecord_path:tfrecord文件将要保存的路径及名称 'data/test_data.tfrecord'
'''
def txt_to_tfrecord(txt_filename=gene_data, tfrecord_path=tfrecord_path):
# 第一步:生成TFRecord Writer
writer = tf.python_io.TFRecordWriter(tfrecord_path)
# 第二步:读取TXT数据,并分割出样本数据和标签
file = open(txt_filename)
for data_line in file.readlines(): # 每一行
data_line = data_line.strip('\n') # 去掉换行符
sample = []
spls = data_line.split('/', 1)[0]# 样本
for m in spls.split(' '):
sample.append(int(m))
label = data_line.split('/', 1)[1]# 标签
label = int(label)
# print('sample:', sample, 'labels:', label)
# 第三步: 建立feature字典,tf.train.Feature()对单一数据编码成feature
feature = {'sample': tf.train.Feature(int64_list=tf.train.Int64List(value=sample)),
'label': tf.train.Feature(int64_list=tf.train.Int64List(value=[label]))}
# 第四步:可以理解为将内层多个feature的字典数据再编码,集成为features
features = tf.train.Features(feature = feature)
# 第五步:将features数据封装成特定的协议格式
example = tf.train.Example(features=features)
# 第六步:将example数据序列化为字符串
Serialized = example.SerializeToString()
# 第七步:将序列化的字符串数据写入协议缓冲区
writer.write(Serialized)
# 记得关闭writer和open file的操作
writer.close()
file.close()
return
# txt_to_tfrecord(txt_filename=gene_data, tfrecord_path=tfrecord_path)
所以在上面的程序中我们涉及到了读取txt文本数据,并将数据写成tfrecord文件。在网络训练过程中数据的读取通常是对tfrecord文件的操作。
TF读取tfrecord文件有两种方式:一种是Queue方式,就是上面介绍的队列,另外一种是用dataset来读取。先介绍Queue读取文件数据的方法
1. Queue方式
Queue读取数据可以分为两种:tf.parse_single_example()和tf.parse_example()
(1). tf.parse_single_example()读取数据
tf.parse_single_example(
serialized, # 张量
features, # 对应写入的features
name=None,
example_names=None)
'''
用tf.parse_single_example()读取并解析tfrecord文件
args:
filename_queue: 文件名队列
shuffle_batch: 判断在batch的时候是否要打乱顺序
if_enq_many: 设定batch中的参数enqueue_many,评估该参数的作用
'''
# 第一步: 建立文件名队列,可设置Epoch次数
filename_queue = tf.train.string_input_producer([tfrecord_path], num_epochs=3)
def read_single(filename_queue, shuffle_batch, if_enq_many):
# 第二步: 建立阅读器
reader = tf.TFRecordReader()
_, serialized_example = reader.read(filename_queue)
# 第三步:根据写入时的格式建立相对应的读取features
features = {
'sample': tf.FixedLenFeature([5], tf.int64),# 如果不是标量,一定要在这里说明数组的长度
'label': tf.FixedLenFeature([], tf.int64)
}
# 第四步: 用tf.parse_single_example()解析单个EXAMPLE PROTO
Features = tf.parse_single_example(serialized_example, features)
# 第五步:对数据进行后处理
sample = tf.cast(Features['sample'], tf.float32)
label = tf.cast(Features['label'], tf.float32)
# 第六步:生成Batch数据 generate batch
if shuffle_batch: # 打乱数据顺序,随机取样
sample_single, label_single = tf.train.shuffle_batch([sample, label],
batch_size=2,
capacity=200000,
min_after_dequeue=10000,
num_threads=1,
enqueue_many=if_enq_many)# 主要是为了评估enqueue_many的作用
else: # # 如果不打乱顺序则用tf.train.batch(), 输出队列按顺序组成Batch输出
sample_single, label_single = tf.train.batch([sample, label],
batch_size=2,
capacity=200000,
min_after_dequeue=10000,
num_threads=1,
enqueue_many = if_enq_many)
return sample_single, label_single
x1_samples, y1_labels = read_single(filename_queue=filename_queue,
shuffle_batch=False, if_enq_many=False)
x2_samples, y2_labels = read_single(filename_queue=filename_queue,
shuffle_batch=True, if_enq_many=False)
print(x1_samples, y1_labels) # 因为是tensor,这里还处于构造tensorflow计算图的过程,输出仅仅是shape等,不会是具体的数值。
# 如果想得到具体的数值,必须建立session,是tensor在计算图中流动起来,也就是用session.run()的方式得到具体的数值。
# 定义初始化变量范围
init = tf.global_variables_initializer()
with tf.Session() as sess:
sess.run(init) # 初始化
# 如果tf.train.string_input_producer([tfrecord_path], num_epochs=3)中num_epochs不为空的化,必须要初始化local变量
sess.run(tf.local_variables_initializer())
coord = tf.train.Coordinator() # 管理线程
threads = tf.train.start_queue_runners(coord=coord) # 文件名开始进入文件名队列和内存
for i in range(1):
# Queue + tf.parse_single_example()读取tfrecord文件
X1, Y1 = sess.run([x1_samples, y1_labels])
print('X1: ', X1, 'Y1: ', Y1) # 这里就可以得到tensor具体的数值
X2, Y2 = sess.run([x2_samples, y2_labels])
print('X2: ', X2, 'Y2: ', Y2) # 这里就可以得到tensor具体的数值
coord.request_stop()
coord.join(threads)
Ps: 如果建立文件名tf.train.string_input_producer([tfrecord_path], num_epochs=3)时, 设置num_epochs为具体的值(不是None)。在初始化的时候必须对local_variables进行初始化sess.run(tf.local_variables_initializer())。否则会报错:
OutOfRangeError (see above for traceback): RandomShuffleQueue '_1_shuffle_batch/random_shuffle_queue' is closed and has insufficient elements (requested 2, current size 0)
上面第六步batch前取到的是单个样本数据,在实际训练中通常用批量数据来更新参数,设置批量读取数据的时候有按顺序读取数据的tf.train.batch()和打乱数据出列顺序的tf.train.shuffle_batch()。假设文本中的数据如图所示:

X11: [[5. 6. 8. 6. 1.] [6. 4. 8. 1. 8.]] Y11: [1. 1.] #用tf.train.batch()
X21: [[0. 4. 3. 7. 8.] [5. 0. 2. 8. 7.]] Y21: [0. 1.] # 用tf.train.shuffle_batch()
这里需要对tf.train.shuffle_batch()和tf.train.batch()的参数进行说明
tf.train.shuffle_batch(
tensors,
batch_size, # 设置batch_size的大小
capacity, # 设置队列中最大的数据量,容量。一般要求capacity > min_after_dequeue + num_threads*batch_size
min_after_dequeue, # 队列中最小的数据量作为随机取样的缓冲区。越大,数据混合越充分,认为采样到的数据更具有随机性。
# 但是这个值设置太大在初始启动时,需要给队列喂足够多的数据,启动慢,而且占用内存。
num_threads=1, # 设置线程数
seed=None,
enqueue_many=False, # Whether each tensor in tensor_list is a single example. 在下面单独说明
shapes=None,
allow_smaller_final_batch=False, # (Optional) Boolean. If True, allow the final batch to be smaller if there are insufficient items left in the queue.
shared_name=None,
name=None)
tf.train.batch(
tensors,
batch_size,
num_threads=1,
capacity=32,
enqueue_many=False,
shapes=None,
dynamic_pad=False,
allow_smaller_final_batch=False,
shared_name=None,
name=None) # 注意:这里没有min_after_dequeue这个参数
读取数据的目的是为了训练网络,而使用Batch训练网络的原因可以解释为:
深度学习的优化说白了就是梯度下降。每次的参数更新有两种方式。
- 第一种,遍历全部数据集算一次损失函数,然后算函数对各个参数的梯度,更新梯度。这种方法每更新一次参数都要把数据集里的所有样本都看一遍,计算量开销大,计算速度慢,不支持在线学习,这称为Batch gradient descent,批梯度下降。
- 另一种,每看一个数据就算一下损失函数,然后求梯度更新参数,这个称为随机梯度下降,stochastic gradient descent。这个方法速度比较快,但是收敛性能不太好,可能在最优点附近晃来晃去,hit不到最优点。两次参数的更新也有可能互相抵消掉,造成目标函数震荡的比较剧烈。
为了克服两种方法的缺点,现在一般采用的是一种折中手段,mini-batch gradient decent,小批的梯度下降,这种方法把数据分为若干个批,按批来更新参数,这样,一个批中的一组数据共同决定了本次梯度的方向,下降起来就不容易跑偏,减少了随机性。另一方面因为批的样本数与整个数据集相比小了很多,计算量也不是很大。
个人理解:大Batch_size一是会受限于计算机硬件,另一方面将会降低梯度下降的随机性。 而小Batch_size收敛速度慢
这里用代码对enqueue_many这个参数进行理解
# -*- coding: utf-8 -*-
import tensorflow as tf
import numpy as np
tensor_list = [[1, 2, 3, 4], [5, 6, 7, 8], [9, 10, 11, 12]]
with tf.Session() as sess:
x1 = tf.train.batch(tensor_list, batch_size=3, enqueue_many=False)
x2 = tf.train.batch(tensor_list, batch_size=3, enqueue_many=True)
x3 = tf.train.shuffle_batch(tensor_list, batch_size=3, capacity = 1000, min_after_dequeue=100, num_threads=1, enqueue_many=False)
x4 = tf.train.shuffle_batch(tensor_list, batch_size=3, capacity = 1000, min_after_dequeue=100, num_threads=1, enqueue_many=True)
coord = tf.train.Coordinator()
threads = tf.train.start_queue_runners(sess=sess, coord=coord)
print("x1 batch:" + "-" * 10)
print(sess.run(x1))
print("x2 batch:" + "-" * 10)
print(sess.run(x2))
print("x2 batch:" + "-" * 10)
print(sess.run(x2))
print("x3 batch:" + "-" * 10)
print(sess.run(x3))
print("x4 batch:" + "-" * 10)
print(sess.run(x4))
coord.request_stop()
coord.join(threads)

由以上输出可以看出,当enqueue_many=False(默认值)时,输出为batch_size*tensor.shape,把输入tensors看作一个样本,Batch就是对第一个维度的数据进行重复采样,将tensor扩展一个维度。
当enqueue_many=True时,tensor是一个样本,batch_size只是调整样本中的维度。这里tensor的维度保持不变,只是在最后一个维度上根据batch_size调整了大小。而最后一个维度内的顺序是乱序的。
对于shuffle_batch,注意到,第1维(矩阵每一行)上的数据是打乱的,所以从[1, 2, 3, 4]中取到了[2, 4, 4]。
如果输入的样本是一个3x6的矩阵。设置batch_size=5,enqueue_many = False时,tensor会被扩展为3x6x5的张量, 并且。当enqueue_many = True时,tensor是3x5,第二个维度上截取size。
这里比较疑惑的是shuffle在这里感觉没有任何作用???
(2). tf.parse_example()读取数据
'''
用tf.parse_example()批量读取数据,据说比tf.parse_single_exaple()读取数据的速度快(没有验证)
args:
filename_queue: 文件名队列
shuffle_batch: 是否批量读取数据
if_enq_many: batch时enqueue_many参数的设定,这里主要用于评估该参数的作用
'''
# 第一步: 建立文件名队列
filename_queue = tf.train.string_input_producer([tfrecord_path])
def read_parse(filename_queue, shuffle_batch, if_enq_many):
# 第二步: 建立阅读器
reader = tf.TFRecordReader()
_, serialized_example = reader.read(filename_queue)
# 第三步: 设置shuffle_batch
if shuffle_batch:
batch = tf.train.shuffle_batch([serialized_example],
batch_size=3,
capacity=10000,
min_after_dequeue=1000,
num_threads=1,
enqueue_many=if_enq_many)# 主要是为了评估enqueue_many的作用
else:
batch = tf.train.batch([serialized_example],
batch_size=3,
capacity=10000,
num_threads=1,
enqueue_many=if_enq_many)
# 第四步:根据写入时的格式建立相对应的读取features
features = {
'sample': tf.FixedLenFeature([5], tf.int64), # 如果不是标量,一定要在这里说明数组的长度
'label': tf.FixedLenFeature([], tf.int64)
}
# 第五步: 用tf.parse_example()解析多个EXAMPLE PROTO
Features = tf.parse_example(batch, features)
# 第六步:对数据进行后处理
samples_parse= tf.cast(Features['sample'], tf.float32)
labels_parse = tf.cast(Features['label'], tf.float32)
return samples_parse, labels_parse
x2_samples, y2_labels = read_parse(filename_queue=filename_queue, shuffle_batch=True, if_enq_many=False)
print(x2_samples, y2_labels)
# 定义初始化变量范围
init = tf.global_variables_initializer()
with tf.Session() as sess:
sess.run(init) # 初始化
coord = tf.train.Coordinator() # 管理线程
threads = tf.train.start_queue_runners(coord=coord) # 文件名开始进入文件名队列和内存
for i in range(1):
X2, Y2 = sess.run([x2_samples, y2_labels])
print('X2: ', X2, 'Y2: ', Y2)
coord.request_stop()
coord.join(threads)
调试的时候这里碰到一个bug,提示:return处local variable 'samples_parse' referenced before assignment。网上给的解决办法基本是python在自上而下执行的时候无法区分变量是全局变量还是局部变量。实际上是我在写第四步/第五步的时候多了缩进,导致没有定义features。(⚠️:python对缩进敏感)
⚠️ 阅读器 + 样本
根据以上例子,假设txt中的数据只有2个样本,如下图所示:
在建立文件名队列时,加入这两个txt文档的文件名
# 第一步: 建立文件名队列
filename_queue = tf.train.string_input_producer([tfrecord_path, tfrecord_path1])
(1). 单个阅读器 + 单个样本
batch_size=1 (注意:这里先将num_threads设置为1)
sample_single, label_single = tf.train.batch([sample, label],
batch_size=1,
capacity=10000,
num_threads=1,
enqueue_many=if_enq_many)
for i in range(5):
X14, Y14 = sess.run([x14_samples, y14_labels])
print('X14: ', X14, 'Y14: ', Y14)
打印输出结果为:
('X14: ', array([[8., 2., 6., 8., 1.]], dtype=float32), 'Y14: ', array([0.], dtype=float32))
('X14: ', array([[8., 3., 5., 3., 6.]], dtype=float32), 'Y14: ', array([0.], dtype=float32))
('X14: ', array([[5., 6., 8., 6., 1.]], dtype=float32), 'Y14: ', array([1.], dtype=float32))
('X14: ', array([[6., 4., 8., 1., 8.]], dtype=float32), 'Y14: ', array([1.], dtype=float32))
('X14: ', array([[8., 2., 6., 8., 1.]], dtype=float32), 'Y14: ', array([0.], dtype=float32))
(2). 单个阅读器 + 多个样本
batch_size = 3
输出结果为:
('X14: ', array([[8., 2., 6., 8., 1.],[8., 3., 5., 3., 6.],[5., 6., 8., 6., 1.]], dtype=float32), 'Y14: ', array([0., 0., 1.], dtype=float32))
('X14: ', array([[6., 4., 8., 1., 8.],[5., 6., 8., 6., 1.],[6., 4., 8., 1., 8.]], dtype=float32), 'Y14: ', array([1., 1., 1.], dtype=float32))
('X14: ', array([[8., 2., 6., 8., 1.],[8., 3., 5., 3., 6.],[8., 2., 6., 8., 1.]], dtype=float32), 'Y14: ', array([0., 0., 0.], dtype=float32))
('X14: ', array([[8., 3., 5., 3., 6.],[5., 6., 8., 6., 1.],[6., 4., 8., 1., 8.]], dtype=float32), 'Y14: ', array([0., 1., 1.], dtype=float32))
('X14: ', array([[8., 2., 6., 8., 1.],[8., 3., 5., 3., 6.],[5., 6., 8., 6., 1.]], dtype=float32), 'Y14: ', array([0., 0., 1.], dtype=float32))
(3). 多个阅读器 + 多个样本
多阅读器需要用tf.train.batch_join()或者tf.train.shuffle_batch_join(),对程序作稍微的修改
example_list = [[sample, label] for _ in range(2)] # Reader设置为2
sample_single, label_single = tf.train.batch_join(example_list, batch_size=3)
输出结果为:
('X14: ', array([[5., 6., 8., 6., 1.],[6., 4., 8., 1., 8.],[8., 2., 6., 8., 1.]], dtype=float32), 'Y14: ', array([1., 1., 0.], dtype=float32))
('X14: ', array([[8., 3., 5., 3., 6.],[8., 2., 6., 8., 1.],[8., 3., 5., 3., 6.]], dtype=float32), 'Y14: ', array([0., 0., 0.], dtype=float32))
('X14: ', array([[5., 6., 8., 6., 1.],[6., 4., 8., 1., 8.],[8., 2., 6., 8., 1.]], dtype=float32), 'Y14: ', array([1., 1., 0.], dtype=float32))
('X14: ', array([[8., 3., 5., 3., 6.],[5., 6., 8., 6., 1.],[6., 4., 8., 1., 8.]], dtype=float32), 'Y14: ', array([0., 1., 1.], dtype=float32))
('X14: ', array([[8., 2., 6., 8., 1.],[8., 3., 5., 3., 6.],[5., 6., 8., 6., 1.]], dtype=float32), 'Y14: ', array([0., 0., 1.], dtype=float32))
从输出结果来看,单个阅读器+多个样本和多个阅读器+多个样本在结果呈现时并没有什么区别,至于对运行速度的影响还有待验证。
附上对阅读器进行测试的完整代码:
# -*- coding: UTF-8 -*-
# !/usr/bin/python3
# Env: python3.6
import tensorflow as tf
import numpy as np
import os
data_filename1 = 'data/data_train1.txt' # 生成txt数据保存路径
data_filename2 = 'data/data_train2.txt' # 生成txt数据保存路径
tfrecord_path1 = 'data/test_data1.tfrecord' # tfrecord1文件保存路径
tfrecord_path2 = 'data/test_data2.tfrecord' # tfrecord2文件保存路径
############################## 读取txt文件,并转为tfrecord文件 ###########################
# every line of data is just as follow: 1 2 3 4 5/1. train data: 1 2 3 4 5, label: 1
def txt_to_tfrecord(txt_filename, tfrecord_path):
# 第一步:生成TFRecord Writer
writer = tf.python_io.TFRecordWriter(tfrecord_path)
# 第二步:读取TXT数据,并分割出样本数据和标签
file = open(txt_filename)
for data_line in file.readlines(): # 每一行
data_line = data_line.strip('\n') # 去掉换行符
sample = []
spls = data_line.split('/', 1)[0] # 样本
for m in spls.split(' '):
sample.append(int(m))
label = data_line.split('/', 1)[1] # 标签
label = int(label)
# 第三步: 建立feature字典,tf.train.Feature()对单一数据编码成feature
feature = {'sample': tf.train.Feature(int64_list=tf.train.Int64List(value=sample)),
'label': tf.train.Feature(int64_list=tf.train.Int64List(value=[label]))}
# 第四步:可以理解为将内层多个feature的字典数据再编码,集成为features
features = tf.train.Features(feature=feature)
# 第五步:将features数据封装成特定的协议格式
example = tf.train.Example(features=features)
# 第六步:将example数据序列化为字符串
Serialized = example.SerializeToString()
# 第七步:将序列化的字符串数据写入协议缓冲区
writer.write(Serialized)
# 记得关闭writer和open file的操作
writer.close()
file.close()
return
txt_to_tfrecord(txt_filename=data_filename1, tfrecord_path=tfrecord_path1)
txt_to_tfrecord(txt_filename=data_filename2, tfrecord_path=tfrecord_path2)
# 第一步: 建立文件名队列
filename_queue = tf.train.string_input_producer([tfrecord_path1, tfrecord_path2])
def read_single(filename_queue, shuffle_batch, if_enq_many):
# 第二步: 建立阅读器
reader = tf.TFRecordReader()
_, serialized_example = reader.read(filename_queue)
# 第三步:根据写入时的格式建立相对应的读取features
features = {
'sample': tf.FixedLenFeature([5], tf.int64), # 如果不是标量,一定要在这里说明数组的长度
'label': tf.FixedLenFeature([], tf.int64)
}
# 第四步: 用tf.parse_single_example()解析单个EXAMPLE PROTO
Features = tf.parse_single_example(serialized_example, features)
# 第五步:对数据进行后处理
sample = tf.cast(Features['sample'], tf.float32)
label = tf.cast(Features['label'], tf.float32)
# 第六步:生成Batch数据 generate batch
if shuffle_batch: # 打乱数据顺序,随机取样
sample_single, label_single = tf.train.shuffle_batch([sample, label],
batch_size=1,
capacity=10000,
min_after_dequeue=1000,
num_threads=1,
enqueue_many=if_enq_many) # 主要是为了评估enqueue_many的作用
else: # # 如果不打乱顺序则用tf.train.batch(), 输出队列按顺序组成Batch输出
###################### multi reader, multi samples, please code as below ###############################
'''
example_list = [[sample,label] for _ in range(2)] # Reader设置为2
sample_single, label_single = tf.train.batch_join(example_list, batch_size=3)
'''
####################### single reader, single sample, please set batch_size = 1 #########################
####################### single reader, multi samples, please set batch_size = batch_size ###############
sample_single, label_single = tf.train.batch([sample, label],
batch_size=1,
capacity=10000,
num_threads=1,
enqueue_many=if_enq_many)
return sample_single, label_single
x1_samples, y1_labels = read_single(filename_queue, shuffle_batch=False, if_enq_many=False)
# 定义初始化变量范围
init = tf.global_variables_initializer()
with tf.Session() as sess:
sess.run(init) # 初始化
# 如果tf.train.string_input_producer([tfrecord_path], num_epochs=30)中num_epochs不为空的化,必须要初始化local变量
sess.run(tf.local_variables_initializer())
coord = tf.train.Coordinator() # 管理线程
threads = tf.train.start_queue_runners(coord=coord) # 文件名开始进入文件名队列和内存
for i in range(5):
# Queue + tf.parse_single_example()读取tfrecord文件
X1, Y1 = sess.run([x1_samples, y1_labels])
print('X1: ', X1, 'Y1: ', Y1)
# Queue + tf.parse_example()读取tfrecord文件
coord.request_stop()
coord.join(threads)
2. Dataset + TFrecrods读取数据
这是目前官网上比较推荐的一种方式,相对于队列读取文件的方法,更为简单。
Dataset API:将数据直接放在graph中进行处理,整体对数据集进行上述数据操作,使代码更加简洁
Dataset直接导入比较简单,这里只是简单介绍:
dataset = tf.data.Dataset.from_tensor_slices([1,2,3]) # 输入必须是list
我们重点看dataset读取tfrecord文件的过程 (关于pipeline的相关信息可以参见博客)
def _parse_function(example_proto): # 解析函数
# 创建解析字典
dics = {
'sample': tf.FixedLenFeature([5], tf.int64), # 如果不是标量,一定要在这里说明数组的长度
'label': tf.FixedLenFeature([], tf.int64)}
# 把序列化样本和解析字典送入函数里得到解析的样本
parsed_example = tf.parse_single_example(example_proto, dics)
# 对样本数据类型的变换
# 这里得到的样本数据都是向量,如果写数据的时候对数据进行过reshape操作,可以在这里根据保存的reshape信息,对数据进行还原。
parsed_example['sample'] = tf.cast(parsed_example['sample'], tf.float32)
parsed_example['label'] = tf.cast(parsed_example['label'], tf.float32)
# 返回所有feature
return parsed_example
'''
read_dataset:
arg: tfrecord_path是需要读取的tfrecord文件路径,如tfrecord_path = ['test.tfrecord', 'test2.tfrecord'],同上面Queue方式相同,可以同时读取多个文件
'''
def read_dataset(tfrecord_path = tfrecord_path):
# 第一步:声明 tf.data.TFRecordDataset
# The tf.data.TFRecordDataset class enables you to stream over the contents of one or more TFRecord files as part of an input pipeline
dataset = tf.data.TFRecordDataset(tfrecord_path)
# 第二步:解析样本数据。 tfrecord文件记录的是序列化的样本,因此需要对样本进行解析。
# 个人理解:这个解析的过程,是通过上面_parse_function函数建立feature的字典。
# 而dataset.map()是对dataset的统一操作,map操作可以理解为在每一个元素上应用一个函数,所以其输入是一个函数。
new_dataset = dataset.map(_parse_function)
# 创建获取数据集中样本的迭代器
iterator = new_dataset.make_one_shot_iterator()
# 获得下一个样本
next_element = iterator.get_next()
return next_element
next_element = read_dataset()
# 建立session,打印输出,查看数据是否正确
# 定义初始化变量范围
init = tf.global_variables_initializer()
with tf.Session() as sess:
sess.run(init) # 初始化
coord = tf.train.Coordinator() # 管理线程
threads = tf.train.start_queue_runners(coord=coord) # 文件名开始进入文件名队列和内存
for i in range(5):
print('dataset:', sess.run([next_element['sample'],
next_element['label']]))
coord.request_stop()
coord.join(threads)
输出结果如下:
('dataset:', [array([5., 6., 8., 6., 1.], dtype=float32), 1.0])
('dataset:', [array([6., 4., 8., 1., 8.], dtype=float32), 1.0])
('dataset:', [array([5., 1., 0., 8., 8.], dtype=float32), 0.0])
('dataset:', [array([8., 2., 6., 8., 1.], dtype=float32), 0.0])
('dataset:', [array([8., 3., 5., 3., 6.], dtype=float32), 0.0])
PS: 这里需要特别特别注意的是当sample 或者 label不是标量,而且长度事先无法获得的时候怎么创建解析函数。
此时 tf.FixedLenFeature(shape=(), dtype=tf.float32)的 shape 无法指定。
举例来说: sample.shape=[2,3], 在写入tfrecord的时候要对矩阵reshape,同时保存值和shape. 如果已经知道sample的长度,在解析函数中可以用上面的tf.FixedLenFeature([6,1], dtype=tf.float32)来解析。一定一定不能用tf.FixedLenFeature([6], dtype=tf.float32)。这样无法还原sample的值,而且会报出各种奇葩错误。如果不知道sample的shape,可以用tf.VarLenFeature(dtype=tf.float32)。由于变长得到的是稀疏矩阵,解析后需要进行转为密集矩阵的处理。
parsed_example['sample'] = tf.sparse_tensor_to_dense(parsed_example['sample'])
上面的代码输出是每次取一个样本,按顺序一个样本一个样本出列。如果需要打乱顺序,用.shuffle(buffer_size= ) 来打乱顺序。其中buffer_size设置成大于数据集汇总样本数量的值,以保证样本顺序充分打乱。
打乱样本出列顺序
def read_dataset(tfrecord_path = tfrecord_path):
# 声明读tfrecord文件
dataset = tf.data.TFRecordDataset(tfrecord_path)
# 建立解析函数
new_dataset = dataset.map(_parse_function)
# 打乱样本顺序
shuffle_dataset = new_dataset.shuffle(buffer_size=20000)
# 数据提前进入队列
prefetch_dataset = batch_dataset.prefetch(2000) # 会快很多
# 建立迭代器
iterator = prefetch_dataset.make_one_shot_iterator()
# 获得下一个样本
next_element = iterator.get_next()
return next_element
输出的结果是:
('dataset:', [array([5., 1., 1., 7., 5.], dtype=float32), 0.0])
('dataset:', [array([8., 0., 8., 2., 7.], dtype=float32), 1.0])
('dataset:', [array([6., 5., 9., 1., 2.], dtype=float32), 1.0])
('dataset:', [array([9., 9., 4., 0., 5.], dtype=float32), 0.0])
('dataset:', [array([1., 9., 9., 2., 9.], dtype=float32), 0.0])
再运行一次,取到的数据也完全不一样。已打乱顺序,单样本输出。
批量输出样本:.batch( batch_size )
def read_dataset(tfrecord_path = tfrecord_path):
# 声明阅读器
dataset = tf.data.TFRecordDataset(tfrecord_path)
# 建立解析函数
new_dataset = dataset.map(_parse_function)
# 打乱样本顺序
shuffle_dataset = new_dataset.shuffle(buffer_size=20000)
# batch输出
batch_dataset = shuffle_dataset.batch(2)
# 数据提前进入队列
prefetch_dataset = batch_dataset.prefetch(2000)
# 建立迭代器
iterator = prefetch_dataset.make_one_shot_iterator()
# 获得下一个样本
next_element = iterator.get_next()
return next_element
输出结果如下:
('dataset:', [array([[1., 4., 6., 2., 5.], [3., 7., 6., 6., 9.]], dtype=float32), array([0., 0.], dtype=float32)])
('dataset:', [array([[8., 2., 2., 6., 3.], [7., 5., 3., 0., 3.]], dtype=float32), array([0., 1.], dtype=float32)])
('dataset:', [array([[2., 8., 9., 5., 7.], [0., 5., 1., 5., 5.]], dtype=float32), array([1., 0.], dtype=float32)])
('dataset:', [array([[0., 8., 1., 6., 0.], [7., 3., 8., 8., 1.]], dtype=float32), array([0., 0.], dtype=float32)])
('dataset:', [array([[2., 4., 9., 8., 9.], [3., 5., 9., 6., 0.]], dtype=float32), array([1., 0.], dtype=float32)])
Epoch: 使用.repeat(num_epochs) 来指定遍历几遍数据集
关于Epoch次数,在Queue读取文件的方式中,是在创建文件名队列时设定的
filename_queue = tf.train.string_input_producer([tfrecord_path], num_epochs=3)
根据博客中的实验可知,先取出(样本总数✖️num_Epoch)的数据,打乱顺序,按照batch_size,无放回的取样,保证每个样本都被访问num_Epoch次。
三种读取方式的完整代码
# -*- coding: UTF-8 -*-
# !/usr/bin/python3
# Env: python3.6
import tensorflow as tf
import numpy as np
import os
# path
data_filename = 'data/data_train.txt' # 生成txt数据保存路径
size = (10000, 5)
tfrecord_path = 'data/test_data.tfrecord' # tfrecord文件保存路径
#################### 生成txt数据 10000个样本。########################
def generate_data(data_filename=data_filename, size=size):
if not os.path.exists(data_filename):
np.random.seed(9)
x_data = np.random.randint(0, 10, size=size)
y1_data = np.ones((size[0] // 2, 1), int) # 一半标签是0,一半是1
y2_data = np.zeros((size[0] // 2, 1), int)
y_data = np.append(y1_data, y2_data)
np.random.shuffle(y_data)
xy_data = str('')
for xy_row in range(len(x_data)):
x_str = str('')
for xy_col in range(len(x_data[0])):
if not xy_col == (len(x_data[0]) - 1):
x_str = x_str + str(x_data[xy_row, xy_col]) + ' '
else:
x_str = x_str + str(x_data[xy_row, xy_col])
y_str = str(y_data[xy_row])
xy_data = xy_data + (x_str + '/' + y_str + '\n')
# write to txt
write_txt = open(data_filename, 'w')
write_txt.write(xy_data)
write_txt.close()
return
################ 读取txt文件,并转为tfrecord文件 ###########################
# every line of data is just as follow: 1 2 3 4 5/1. train data: 1 2 3 4 5, label: 1
def txt_to_tfrecord(txt_filename=data_filename, tfrecord_path=tfrecord_path):
# 第一步:生成TFRecord Writer
writer = tf.python_io.TFRecordWriter(tfrecord_path)
# 第二步:读取TXT数据,并分割出样本数据和标签
file = open(txt_filename)
for data_line in file.readlines(): # 每一行
data_line = data_line.strip('\n') # 去掉换行符
sample = []
spls = data_line.split('/', 1)[0] # 样本
for m in spls.split(' '):
sample.append(int(m))
label = data_line.split('/', 1)[1] # 标签
label = int(label)
print('sample:', sample, 'labels:', label)
# 第三步: 建立feature字典,tf.train.Feature()对单一数据编码成feature
feature = {'sample': tf.train.Feature(int64_list=tf.train.Int64List(value=sample)),
'label': tf.train.Feature(int64_list=tf.train.Int64List(value=[label]))}
# 第四步:可以理解为将内层多个feature的字典数据再编码,集成为features
features = tf.train.Features(feature=feature)
# 第五步:将features数据封装成特定的协议格式
example = tf.train.Example(features=features)
# 第六步:将example数据序列化为字符串
Serialized = example.SerializeToString()
# 第七步:将序列化的字符串数据写入协议缓冲区
writer.write(Serialized)
# 记得关闭writer和open file的操作
writer.close()
file.close()
return
############### 用Queue方式中的tf.parse_single_example解析tfrecord #########################
# 第一步: 建立文件名队列
filename_queue = tf.train.string_input_producer([tfrecord_path], num_epochs=30)
def read_single(filename_queue, shuffle_batch, if_enq_many):
# 第二步: 建立阅读器
reader = tf.TFRecordReader()
_, serialized_example = reader.read(filename_queue)
# 第三步:根据写入时的格式建立相对应的读取features
features = {
'sample': tf.FixedLenFeature([5], tf.int64), # 如果不是标量,一定要在这里说明数组的长度
'label': tf.FixedLenFeature([], tf.int64)
}
# 第四步: 用tf.parse_single_example()解析单个EXAMPLE PROTO
Features = tf.parse_single_example(serialized_example, features)
# 第五步:对数据进行后处理
sample = tf.cast(Features['sample'], tf.float32)
label = tf.cast(Features['label'], tf.float32)
# 第六步:生成Batch数据 generate batch
if shuffle_batch: # 打乱数据顺序,随机取样
sample_single, label_single = tf.train.shuffle_batch([sample, label],
batch_size=2,
capacity=10000,
min_after_dequeue=1000,
num_threads=1,
enqueue_many=if_enq_many) # 主要是为了评估enqueue_many的作用
else: # # 如果不打乱顺序则用tf.train.batch(), 输出队列按顺序组成Batch输出
'''
example_list = [[sample,label] for _ in range(2)] # Reader设置为2
sample_single, label_single = tf.train.batch_join(example_list, batch_size=1)
'''
sample_single, label_single = tf.train.batch([sample, label],
batch_size=1,
capacity=10000,
num_threads=1,
enqueue_many=if_enq_many)
return sample_single, label_single
############# 用Queue方式中的tf.parse_example解析tfrecord ##################################
def read_parse(filename_queue, shuffle_batch, if_enq_many):
# 第二步: 建立阅读器
reader = tf.TFRecordReader()
_, serialized_example = reader.read(filename_queue)
# 第三步: 设置shuffle_batch
if shuffle_batch:
batch = tf.train.shuffle_batch([serialized_example],
batch_size=3,
capacity=10000,
min_after_dequeue=1000,
num_threads=1,
enqueue_many=if_enq_many) # 主要是为了评估enqueue_many的作用
else:
batch = tf.train.batch([serialized_example],
batch_size=3,
capacity=10000,
num_threads=1,
enqueue_many=if_enq_many)
# 第四步:根据写入时的格式建立相对应的读取features
features = {
'sample': tf.FixedLenFeature([5], tf.int64), # 如果不是标量,一定要在这里说明数组的长度
'label': tf.FixedLenFeature([], tf.int64)
}
# 第五步: 用tf.parse_example()解析多个EXAMPLE PROTO
Features = tf.parse_example(batch, features)
# 第六步:对数据进行后处理
samples_parse = tf.cast(Features['sample'], tf.float32)
labels_parse = tf.cast(Features['label'], tf.float32)
return samples_parse, labels_parse
############### 用Dataset读取tfrecord文件 ###############################################
# 定义解析函数
def _parse_function(example_proto):
dics = { # 这里没用default_value,随后的都是None
'sample': tf.FixedLenFeature([5], tf.int64), # 如果不是标量,一定要在这里说明数组的长度
'label': tf.FixedLenFeature([], tf.int64)}
# 把序列化样本和解析字典送入函数里得到解析的样本
parsed_example = tf.parse_single_example(example_proto, dics)
parsed_example['sample'] = tf.cast(parsed_example['sample'], tf.float32)
parsed_example['label'] = tf.cast(parsed_example['label'], tf.float32)
# 返回所有feature
return parsed_example
def read_dataset(tfrecord_path=tfrecord_path):
# 声明阅读器
dataset = tf.data.TFRecordDataset(tfrecord_path)
# 建立解析函数,其中num_parallel_calls指定并行线程数
new_dataset = dataset.map(_parse_function, num_parallel_calls=4)
# 打乱样本顺序
shuffle_dataset = new_dataset.shuffle(buffer_size=20000)
# 设置epoch次数为10,这里需要注意的是目前看来只支持先shuffle再repeat的方式
repeat_dataset = shuffle_dataset.repeat(10)
# batch输出
batch_dataset = repeat_dataset.batch(2)
# 数据提前进入队列
prefetch_dataset = batch_dataset.prefetch(2000)
# 建立迭代器
iterator = prefetch_dataset.make_one_shot_iterator()
# 获得下一个样本
next_element = iterator.get_next()
return next_element
################## 建立graph ####################################
# 生成数据
# generate_data()
# 读取数据转为tfrecord文件
# txt_to_tfrecord()
# Queue + tf.parse_single_example()读取tfrecord文件
x1_samples, y1_labels = read_single(filename_queue, shuffle_batch=True, if_enq_many=False)
# Queue + tf.parse_example()读取tfrecord文件
x2_samples, y2_labels = read_parse(filename_queue, shuffle_batch=True, if_enq_many=False)
# Dataset读取数据
next_element = read_dataset()
# 定义初始化变量范围
init = tf.global_variables_initializer()
with tf.Session() as sess:
sess.run(init) # 初始化
# 如果tf.train.string_input_producer([tfrecord_path], num_epochs=30)中num_epochs不为空的化,必须要初始化local变量
sess.run(tf.local_variables_initializer())
coord = tf.train.Coordinator() # 管理线程
threads = tf.train.start_queue_runners(coord=coord) # 文件名开始进入文件名队列和内存
for i in range(1):
# Queue + tf.parse_single_example()读取tfrecord文件
X1, Y1 = sess.run([x1_samples, y1_labels])
print('X1: ', X1, 'Y1: ', Y1)
# Queue + tf.parse_example()读取tfrecord文件
X2, Y2 = sess.run([x2_samples, y2_labels])
print('X2: ', X2, 'Y2: ', Y2)
# Dataset读取数据
print('dataset:', sess.run([next_element['sample'],
next_element['label']]))
#这里需要注意,每run一次,迭代器会取下一个样本。
# 如果是 a= sess.run(next_element['sample'])
# b = sess.run(next_element['label']),
# 则a样本对应的标签值不是b,b是下一个样本对应的标签值。
coord.request_stop()
coord.join(threads)
另外,关于dataset加速的用法,可以参见官网说明
Dataset+TFRecord读取变长数据
使用dataset中的padded_batch方法来进行
padded_batch(
batch_size,
padded_shapes,
padding_values=None #默认使用各类型数据的默认值,一般使用时可忽略该项
)
参数padded_shapes 指明每条记录中各成员要pad成的形状,成员若是scalar,则用[ ],若是list,则用[mx_length],若是array,则用[d1,...,dn],假如各成员的顺序是scalar数据、list数据、array数据,则padded_shapes=([], [mx_length], [d1,...,dn]);
例如tfrecord文件中的key是fea, e.g.fea.shape=[568, 366], 二维,长度变化。fea_shape=[568,366],一维, label=[1, 0, 2,0,3,0]一维,长度变化。
再读取变长数据的时候映射函数应为:
def _parse_function(example_proto):
dics = {
'fea': tf.VarLenFeature(dtype=tf.float32),
'fea_shape': tf.FixedLenFeature(shape=(2,), dtype=tf.int64),
'label': tf.VarLenFeature(dtype=tf.float32)}
parsed_example = tf.parse_single_example(example_proto, dics)
parsed_example['fea'] = tf.sparse_tensor_to_dense(parsed_example['fea'])
parsed_example['label'] = tf.sparse_tensor_to_dense(parsed_example['label'])
parsed_example['label'] = tf.cast(parsed_example['label'], tf.int32)
parsed_example['fea'] = tf.reshape(parsed_example['fea'], parsed_example['fea_shape'])
return parsed_example
利用tf.VarLenFeature()代替tf.FixedLenFeature(),在后处理中要注意用tf.sparse_tensor_to_dense()将读取的变长数据转为稠密矩阵。
def dataset():
tf_lst = get_tf_list(tf_file_lst)
dataset = tf.data.TFRecordDataset(tf_lst)
new_dataset = dataset.map(_parse_function)
shuffle_dataset = new_dataset.shuffle(buffer_size=20000)
repeat_dataset = shuffle_dataset.repeat(10)
prefetch_dataset = repeat_dataset.prefetch(2000)
batch_dataset = prefetch_dataset.padded_batch(2, padded_shapes={'fea': [None, None], 'fea_shape': [None], 'label': [None]})
iterator = batch_dataset.make_one_shot_iterator()
next_element = iterator.get_next()
return next_element
这里padded_shapes={'fea': [None, None], 'fea_shape': [None], 'label': [None]}
如果报错 All elements in a batch must have the same rank as the padded shape for component1: expected rank 2 but got element with rank 1请仔细查看padded_shapes中设置的维度是否正确。如果padded_shapes={'fea': [None, None], 'fea_shape': [None, None], 'label': [None]}即fea_shape本来的rank应该是1,但是在pad的时候设置了2,所以报错。
如果报错The two structures don't have the same sequence type. Input structure has type ,则可能是padded_shapes定义的格式不对,如定义成了padded_shapes=([None, None],[None],[None]),请按照字典格式定义pad的方式。