参考文献
表和索引数据结构体系结构
SqlServer存储结构组织其分区中的数据或索引页
漫谈数据库索引
正文
SqlServer用三种方法来组织其分区中的数据或索引页:
1、聚集索引结构
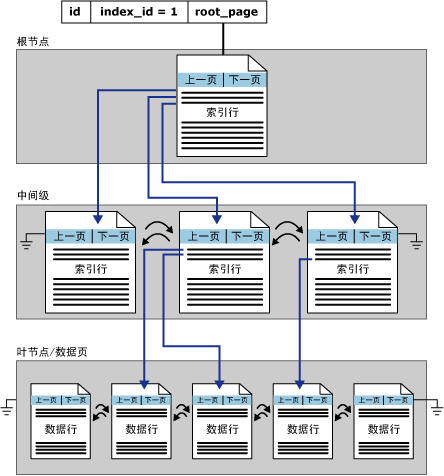
聚集索引是按B树结构进行组织的,B树中的每一页称为一个索引节点。每个索引行包含一个键值和一个指针。指针指向B树上的某一中间级页(比如根节点指向中间级节点中的索引页)或叶级索引中的某个数据行(比如中间级索引页中的某个索引行指向叶子节点中的数据页)。每级索引中的页均被链接在双向链接列表中。数据链内的页和行将按聚集索引键值进行排序,聚集索引保证了表格的数据按照索引行的顺序排列;
补充(PS:2012-7-9)
从上图可以看出,聚集索引的叶子节点是由数据页组成的,表中所有的数据都包含在了聚集索引的叶子节点当中。这也是为什么前一篇博客中提到“If the index is a clustered index then an index scan is really a table scan.”的原因。
补充(PS:2012-7-13)
今天突然理解为什么说聚集索引是带真实数据的。这是因为数据本身也是索引的一部分了。数据内容本身按照一个规则排列,那么排列规则+数据就组成了聚集索引。
举例:
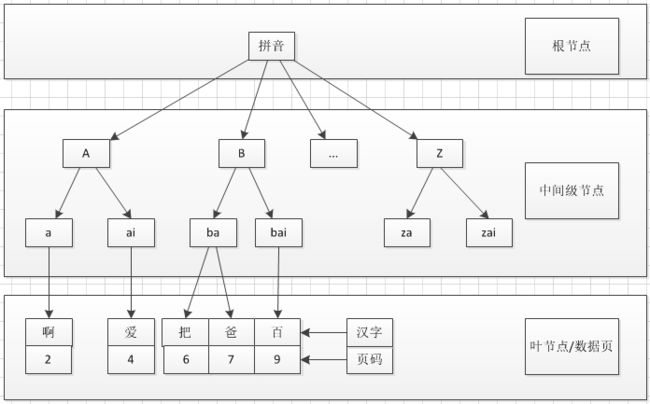
汉语字典的正文本身就是一个聚集索引。比如,我们要查“安”字,就会很自然地翻开字典的前几页,因为“安”的拼音是“an”,而按照拼音排序汉字的字典是以英文字母“a”开头并以“z”结尾的,那么“安”字就自然地排在字典的前部。如果您翻完了所有以“a”开头的部分仍然找不到这个字,那么就说明您的字典中没有这个字;同样的,如果查“张”字,那您也会将您的字典翻到最后部分,因为“张”的拼音是“zhang”。也就是说,字典的正文部分本身就是一个目录,您不需要再去查其他目录来找到您需要找的内容。如果正文内容本身就是一种按照一定规则排列的目录,则称之为“聚集索引”。
2、堆结构
堆是没有聚集索引的表,用"索引分配映射(IAM)"页将堆的页面联系在一起。如下图所示

堆内的数据页和行没有任何特定的顺序;页面也不链接在一起,数据页之间唯一的逻辑连接是记录在IAM页内的信息,页面与页面之间没有什么紧密的联系;用IAM页查找数据页集合中的每一页。从数据存储管理上来讲,用堆去管理一个超大的表格是比较吃力的,经常使用的表格上都建立聚集索引。
sql server默认是在主键上建立聚集索引的。就是可以让您的数据在数据库中按照id进行物理排序,但这样做意义不大,聚集索引的优势是很明显的,而每个表中只能有一个聚集索引的规则,这使得聚集索引变得更加珍贵。因为很少用id号来进行查询,这就使让id号这个主键作为聚集索引成为一种资源浪费。
3、非聚集索引
非聚集索引与聚集索引具有相同的 B 树结构,但是他们之间还是存在显著差异,主要有一下三点:
- 非聚集索引不影响数据行的顺序。
- 基础表的数据行不按非聚集键的顺序排序和存储,
- 非聚集索引的叶层是由索引页而不是由数据页组成,非聚集索引不会去改变或改善数据页的存储模式。
既可以使用聚集索引来为表或视图定义非聚集索引,也可以根据堆来定义非聚集索引。非聚集索引中的每个索引行都包含非聚集键值和行定位符。此定位符指向聚集索引或堆中包含该键值的数据行。
非聚集索引行中的行定位器可以是指向行的指针,也可以是行的聚集索引键,具体根据如下情况而定:
- 如果表是堆(意味着该表没有聚集索引),则行定位器是指向行的指针。该指针由文件标识符 (ID)、页码和页上的行数生成。整个指针称为行 ID (RID)。
- 如果表有聚集索引或索引视图上有聚集索引,则行定位器是行的聚集索引键。如果聚集索引不是唯一的索引,SQL Server 将添加在内部生成的值(称为唯一值)以使所有重复键唯一。此四字节的值对于用户不可见。仅当需要使聚集键唯一以用于非聚集索引中时,才添加该值。SQL Server 通过使用存储在非聚集索引的叶行内的聚集索引键搜索聚集索引来检索数据行。

补充(PS:2012-7-9)
从上图可以看出,非聚集索引的叶子节点是由索引页组成的,索引页中每一个索引行的格式是“索引键值+指针”的形式,索引键值就是我们表中的一个列,如果是复合索引,索引键值就是多个列。而指针的具体指向需要根据表的组织结构而定,如果这张表中已经存在聚集索引了,那么指针指向的是聚集索引,如果表中没有加聚集索引,那么这张表就是无序的堆结构,指针指向表中每一条记录所在的位置。因此,索引行跟数据行是一一对应的,假如一个查询中select后面查询的列和where后面的条件列都在索引当中,那么就是索引覆盖,此时不需要再通过索引行的指针去找数据页,直接返回索引页中的内容就可以了。
举例
聚集索引与非聚集索引的区分
区分聚集索引和非聚集索引的一个主要方法是查看叶子节点,如果叶子节点是真实的数据,那么就是聚集索引;如果叶子节点是指针,那么就是非聚集索引。
如果是在一个有聚集索引的表中使用非聚集索引,那么这个非聚集索引叶子节点指向的是聚集索引的位置,如果没有聚集索引, 那么就指向数据页的rowid,这样的表示无序的,也叫做堆表。
举例说明聚集索引与非聚集索引的关系(ps:2012-7-17)
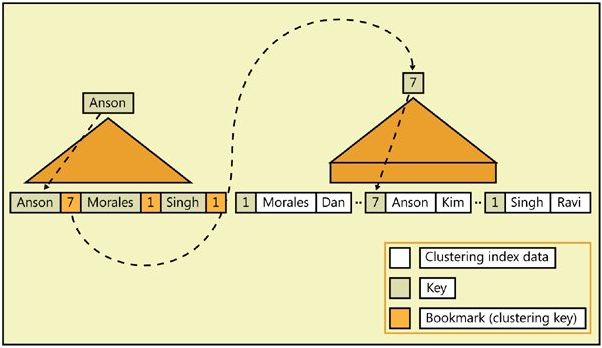
如下图所示,我们需要查找一个First Name为Anson的人的Last Name,我们在First Name字段上创建了非聚集索引,在employeeID列上创建了聚集索引。那么我们的查询步骤是通过非聚集索引查找Anson,然后再非聚集索引的叶子节点上找到了聚集索引的键值7,然后通过这个键值7再去查找聚集索引。不过在聚集索引的叶子节点中保存的就是真实数据,因此我们在聚集索引的叶子节点找到了Anson的Last Name 是Kim。
这就是我们前面提到的,聚集索引的叶子节点是真实的数据,而非聚集索引的叶子节点是一个bookmark,这个bookmark可能是两种情况,如果表中有聚集索引,那么这个bookmark就是聚集索引的键值(我们经常说是指向聚集索引,更准确的说应该是聚集索引的键值,然后通过这个键值直接去聚集索引中查找我们需要的数据行),如果没有聚集索引,那么这个bookmark就是 row identifier (RID,行标识符), 格式为"File#:Page#:Slot#"。