Flume部署安装详细图文步骤(2节点)
下面我来安装部署 Flume NG,这里我们安装配置两个节点cloud003、cloud004,以Avro Source+Memory Channel+HDFS Sink结合方式示例讲解,大家可以尝试其他实现方式。
步骤一:下载flume安装包

apache-flume-1.6.0-bin.tar.gz安装包分别解压到cloud003、cloud004节点上的/usr/java/hadoop/app/目录下。这里我们以cloud003为例,cloud004同样操作。
[hadoop@cloud003 app]$ tar -zxvf apache-flume-1.6.0-bin.tar.gz //解压
[hadoop@cloud003 app]$ mv apache-flume-1.6.0-bin flume //修改文件名称
步骤二:在cloud003节点上,进入flume/conf目录。
[hadoop@cloud003 app]$ cd flume/conf
[hadoop@cloud003 conf]$ ls
flume-conf.properties.template flume-env.ps1.template flume-env.sh.template log4j.properties
需要通过flume-conf.properties.template复制一个flume-conf.properties配置文件。
[hadoop@cloud003 conf]$ cp flume-conf.properties.template flume-conf.properties
[hadoop@cloud003 conf]$ ls
flume-conf.properties flume-conf.properties.template flume-env.ps1.template flume-env.sh.template log4j.properties
修改cloud003节点上的flume-conf.properties配置文件
这里收集日志文件到收集端。配置参数的详细说明可以参考官方文档。

[hadoop@cloud003 conf]$ vi flume-conf.properties #定义source、channel、sink 名称 a1.sources = r1 //这里的a1命名可以自定义,但需要跟后面启动配置名称一致就可以 a1.sinks = k1 a1.channels = c1 #定义并配置r1 a1.sources.r1.channels = c1 a1.sources.r1.type = avro //source类型 a1.sources.r1.bind = 0.0.0.0 //默认绑定本机 a1.sources.r1.port=41414 //默认端口 # 定义并配置k1 a1.sinks.k1.channel = c1 a1.sinks.k1.type = avro //sink类型 a1.sinks.k1.hostname = cloud004 //将数据传递给cloud004 a1.sinks.k1.port = 41414 //默认端口号 #定义并配置c1 a1.channels.c1.type=FILE //channel类型
步骤三:在cloud004节点上,进入flume/conf目录。
[hadoop@cloud004 app]$ cd flume/conf
[hadoop@cloud004 conf]$ ls
flume-conf.properties.template flume-env.ps1.template flume-env.sh.template log4j.properties
需要通过flume-conf.properties.template复制一个flume-conf.properties配置文件
[hadoop@cloud004 conf]$ cp flume-conf.properties.template flume-conf.properties
[hadoop@cloud004 conf]$ ls
flume-conf.properties flume-conf.properties.template flume-env.ps1.template flume-env.sh.template log4j.properties
修改cloud004节点上的flume-conf.properties配置文件
从cloud003端接收数据,然后写入到HDFS文件系统中。配置参数的详细说明可以参考官方文档。
[hadoop@cloud004 conf]$ vi flume-conf.properties # 定义source、channel、sink 名称 a1.sources = r1 a1.sinks = k1 a1.channels = c1 #定义并配置 r1 a1.sources.r1.type = avro //这里要跟cloud003端的sink类型一致 a1.sources.r1.bind = 0.0.0.0 a1.sources.r1.port = 41414 a1.sources.r1.channels = c1 #定义并配置k1 a1.sinks.k1.channel = c1 a1.sinks.k1.type=hdfs //sink的输出类型为hdfs a1.sinks.k1.hdfs.path=hdfs://cloud001:9000/data/flume //hdfs上传文件路径 a1.sinks.k1.hdfs.fileType=DataStream #定义并配置c1 a1.channels.c1.type=File
注意,我的这里cloud001是主节点。
分析:
cloud001和cloud002是mater1和master2(备主节点)。
cloud003和cloud004是slave1和slave2。
过程(本博客)
cloud3从本地文件里去采集数据 --> source 、channle、sink --> cloud4的source -> channle -> cloud4的sink -> cloud1的hdfs上

整图(举例)
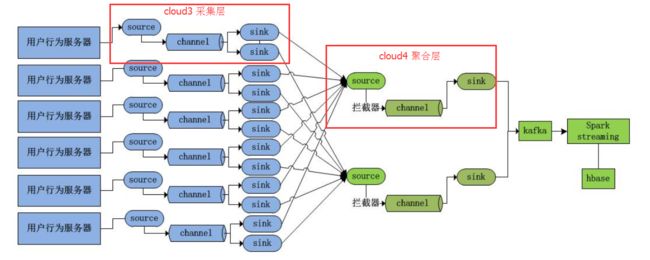
也可以如上。
步骤四:首先要保证 Hadoop 集群正常运行,这里cloud001是Namenode。
[hadoop@cloud001 hadoop]$ jps 2625 JournalNode 1563 QuorumPeerMain 18808 NameNode 26146 Jps 3583 ResourceManager
步骤五、首先在cloud004节点上启动Agent,保证能接受传过来的数据,然后传递给hdfs。(注意启动顺序,就跟田里抽水一样,越在后的,先启动)
[hadoop@cloud003 flume]$ bin/flume-ng agent -c ./conf/ -f conf/flume-conf.properties -Dflume.root.logger=INFO,console -n a1 Info: Including Hadoop libraries found via (/usr/java/hadoop/bin/hadoop) for HDFS access Info: Excluding /usr/java/hadoop/share/hadoop/common/lib/slf4j-api-1.7.5.jar from classpath Info: Excluding /usr/java/hadoop/share/hadoop/common/lib/slf4j-log4j12-1.7.5.jar from classpath Info: Including Hive libraries found via () for Hive access 2016-08-25 08:54:22,018 (conf-file-poller-0) [INFO - org.apache.flume.node.PollingPropertiesFileConfigurationProvider$FileWatcherRunnable.run(PollingPropertiesFileConfigurationProvider.java:133)] Reloading configuration file:conf/flume-conf.properties 2016-08-25 08:54:22,033 (conf-file-poller-0) [INFO - org.apache.flume.conf.FlumeConfiguration$AgentConfiguration.addProperty(FlumeConfiguration.java:1017)] Processing:k1 2016-08-25 08:54:22,829 (lifecycleSupervisor-1-0) [INFO - org.apache.flume.instrumentation.MonitoredCounterGroup.start(MonitoredCounterGroup.java:96)] Component type: CHANNEL, name: c1 started 2016-08-25 08:54:22,830 (conf-file-poller-0) [INFO - org.apache.flume.node.Application.startAllComponents(Application.java:173)] Starting Sink k1 2016-08-25 08:54:22,830 (conf-file-poller-0) [INFO - org.apache.flume.node.Application.startAllComponents(Application.java:184)] Starting Source r1 2016-08-25 08:54:22,832 (lifecycleSupervisor-1-4) [INFO - org.apache.flume.source.AvroSource.start(AvroSource.java:228)] Starting Avro source r1: { bindAddress: 0.0.0.0, port: 41414 }... 2016-08-25 08:54:22,835 (lifecycleSupervisor-1-1) [INFO - org.apache.flume.instrumentation.MonitoredCounterGroup.register(MonitoredCounterGroup.java:120)] Monitored counter group for type: SINK, name: k1: Successfully registered new MBean. 2016-08-25 08:54:22,835 (lifecycleSupervisor-1-1) [INFO - org.apache.flume.instrumentation.MonitoredCounterGroup.start(MonitoredCounterGroup.java:96)] Component type: SINK, name: k1 started 2016-08-25 08:54:23,326 (lifecycleSupervisor-1-4) [INFO - org.apache.flume.instrumentation.MonitoredCounterGroup.register(MonitoredCounterGroup.java:120)] Monitored counter group for type: SOURCE, name: r1: Successfully registered new MBean. 2016-08-25 08:54:23,327 (lifecycleSupervisor-1-4) [INFO - org.apache.flume.instrumentation.MonitoredCounterGroup.start(MonitoredCounterGroup.java:96)] Component type: SOURCE, name: r1 started 2016-08-25 08:54:23,328 (lifecycleSupervisor-1-4) [INFO - org.apache.flume.source.AvroSource.start(AvroSource.java:253)] Avro source r1 started.
需要注意的是:-n a1中的参数值a1必须与flume-conf.properties配置文件的a1名称一致。
步骤六:然后在cloud003节点上,启动Avro Client,发送数据给cloud004节点的agent。
[hadoop@cloud003 flume]$ bin/flume-ng avro-client -c ./conf/ -H cloud004 -p 41414 -F /usr/java/hadoop/app/flume/mydata/2.log -Dflume.root.logger=DEBUG,console Info: Including Hadoop libraries found via (/usr/java/hadoop/bin/hadoop) for HDFS access Info: Excluding /usr/java/hadoop/share/hadoop/common/lib/slf4j-api-1.7.5.jar from classpath Info: Excluding /usr/java/hadoop/share/hadoop/common/lib/slf4j-log4j12-1.7.5.jar from classpath Info: Including Hive libraries found via () for Hive access 2016-08-25 09:10:42,629 (main) [DEBUG - org.apache.flume.api.NettyAvroRpcClient.configure(NettyAvroRpcClient.java:499)] Batch size string = 5 2016-08-25 09:10:42,672 (main) [WARN - org.apache.flume.api.NettyAvroRpcClient.configure(NettyAvroRpcClient.java:634)] Using default maxIOWorkers 2016-08-25 09:10:43,548 (main) [DEBUG - org.apache.flume.client.avro.AvroCLIClient.run(AvroCLIClient.java:234)] Finished 2016-08-25 09:10:43,548 (main) [DEBUG - org.apache.flume.client.avro.AvroCLIClient.run(AvroCLIClient.java:237)] Closing reader 2016-08-25 09:10:43,550 (main) [DEBUG - org.apache.flume.client.avro.AvroCLIClient.run(AvroCLIClient.java:241)] Closing RPC client 2016-08-25 09:10:43,567 (main) [DEBUG - org.apache.flume.client.avro.AvroCLIClient.main(AvroCLIClient.java:84)] Exiting
需要注意:-H cloud004中的cloud004是agent节点地址,-F /usr/java/hadoop/app/flume/mydata/2.log 是发送的日志文件内容。
步骤七:查看HDFS上同步过来的数据。
[hadoop@cloud001 hadoop]$ hadoop fs -ls /data/flume/ Found 1 items -rw-r--r-- 3 hadoop supergroup 21 2016-08-25 09:11 /data/flume/FlumeData.1440465043429
至此flume一个简单的数据收集过程已经分析完毕,大家可以根据需求完成其他实现方式,这里就不多说。
本文转自大数据躺过的坑博客园博客,原文链接:http://www.cnblogs.com/zlslch/p/6116606.html,如需转载请自行联系原作者