熊浩含
问题提出
- 1、在Redis源码中有一句注释,是对sdshdr5的解释:
/* Note: sdshdr5 is never used, we just access the flags byte directly.
* However is here to document the layout of type 5 SDS strings. */
struct __attribute__ ((__packed__)) sdshdr5 {
unsigned char flags; /* 3 lsb of type, and 5 msb of string length */
char buf[];
};那么sdshdr5真的不使用了吗
- 2、在Redis5中,执行以下命令,key和value最终是用哪种sds存放?
比如:
> set a tttsds基础回顾
从Redis3.2开始,sds就有了5种类型,5种类型分别存放不同大小的字符串。在创建字符串时,sds会根据字符串的长度选择不同的类型。最终由sdsnewlen函数创建字符串:
sds sdsnewlen(const void *init, size_t initlen) {
void *sh;
sds s;
char type = sdsReqType(initlen);
if (type == SDS_TYPE_5 && initlen == 0) type = SDS_TYPE_8;//为空时强制用sdshdr8
int hdrlen = sdsHdrSize(type);
unsigned char *fp; /* flags pointer. */
sh = s_malloc(hdrlen+initlen+1);
if (init==SDS_NOINIT)
init = NULL;
else if (!init)
memset(sh, 0, hdrlen+initlen+1);
if (sh == NULL) return NULL;
s = (char*)sh+hdrlen;
fp = ((unsigned char*)s)-1;
switch(type) {
case SDS_TYPE_5: {
*fp = type | (initlen << SDS_TYPE_BITS);
break;
}
case SDS_TYPE_8: {
SDS_HDR_VAR(8,s);
sh->len = initlen;
sh->alloc = initlen;
*fp = type;
break;
}
case SDS_TYPE_16: {
...
}
case SDS_TYPE_32: {
...
}
case SDS_TYPE_64: {
...
}
}
if (initlen && init)
memcpy(s, init, initlen);
s[initlen] = '\0';
return s;
}除了创建空字符串时会强转为SDS_TYPE_8外,没有什么其它特别之处了。
gdb结果
问题中的key和value都是长度短于32的字符串,似乎应该都用sdshdr5来存。但gdb打印后发现,key确实是用sdshdr5存储的,但value却是用sdshdr8存储的。
在getCommand函数处打断点,打印c-db->dict中的相关内容:
![]()
分别打印key和val的值,其中key是sds,val是robj。结果如下:
(gdb) p (sds)0x7f09d2009830
$117 = 0x7f09d2009830 "\ba"
(gdb) p *(robj*)0x7f09d2029830
$118 = {type = 0, encoding = 8, lru = 1536715, refcount = 1, ptr = 0x7f09d2029843}
(gdb) p (sds)0x7f09d2029842
$119 = 0x7f09d2029842 "\001ttt"- ttt前的001,代表flags是00000001(二进制),低三位表类型,意味着存ttt所用的类型为SDS_TYPE_8
- a前的b,代表flags是00001000(二进制),低三位表类型,意味着存a所用类型为SDS_TYPE_5
#define SDS_TYPE_5 0
#define SDS_TYPE_8 1
#define SDS_TYPE_16 2
#define SDS_TYPE_32 3
#define SDS_TYPE_64 4set命令流程
光看sdsnewlen无法解释问题,执行
>set a ttt入口函数是setcommand,我们从setcommand命令入口看起:
void setCommand(client *c) {
...
c->argv[2] = tryObjectEncoding(c->argv[2]);
setGenericCommand(c,flags,c->argv[1],c->argv[2],expire,unit,NULL,NULL);
}最终调setGenericCommand,c->argv[1],c->argv[2]是两个robj,存放着key和value,打印结果如下:
(gdb) p (sds)((*c->argv[1])->ptr-1)
$125 = 0x7f09d2029aca "\001a"
(gdb) p (sds)((*c->argv[2])->ptr-1)
$126 = 0x7f09d202988a "\001ttt"可以看到,__两个robj底层的sds_type都是sdshdr8__。为什么是两个sdshdr8呢?argv应该是在命令解析的时候生成的,继续跟源码。命令解析的源头在readQueryFromClient,从readQueryFromClient一直往下跟,调用链如下:
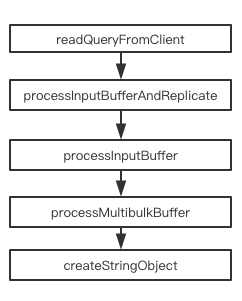
最终走到了createStringObject:
robj *createStringObject(const char *ptr, size_t len) {
if (len <= OBJ_ENCODING_EMBSTR_SIZE_LIMIT)//OBJ_ENCODING_EMBSTR_SIZE_LIMIT = 44
return createEmbeddedStringObject(ptr,len);
else
return createRawStringObject(ptr,len);
}redis在存储命令参数时,根据参数长度选不同的结构。有意思的是,参数长度小于44时,走createEmbeddedStringObject分支,但createEmbeddedStringObject中又强制用sdshdr8来存字符串:
robj *createEmbeddedStringObject(const char *ptr, size_t len) {
robj *o = zmalloc(sizeof(robj)+sizeof(struct sdshdr8)+len+1);//指定sdshdr8
...
return o;
}而当参数长度大于44时,走一般流程。此时创建的字符串长度既然大于44,更大于32了,自然也不可能用sdshdr5。换而言之,__从Buffer中解析出的命令参数,redis统一用大于sdshdr5的结构存,这跟之前gdb的现象是一致的__。
那什么时候key变回由sdshdr5存储了呢?回过头继续跟setGenericCommand,调用链如下:
setGenericCommand-->setKey-->dbAdd在dbAdd函数中,可以看到,redis对待存入的key做了一次复制,__正是这次复制将key由之前的sdshdr8转成了sdshdr5__:
void dbAdd(redisDb *db, robj *key, robj *val) {
sds copy = sdsdup(key->ptr);
int retval = dictAdd(db->dict, copy, val);
...
}sdsdup复制只看字符串内容,根据字符串内容创建新的sds,由于key->ptr指向的字符串是"a",故copy这个robj底层是个sdshdr5。最终调用dictAdd时,键的robj底层是sdshdr5,而值的robj底层是sdshdr8。
总结
最终可以确认,长度小于32的键值对,键的底层是sdshdr5,而值的robj底层是sdshdr8。
- Q1:为什么用sdshdr5存key可以,存value不行?
个人猜想是键不更新而值会更新,故键用尽可能小的结构存;值更新会引起扩容,索性直接用大些的结构存。
- Q2:为什么解析参数时,Redis又抛弃了小的sdshdr5?
个人猜想是为了编码方便。不同命令的参数个数都不相同,一开始分不清哪个位置是key哪个位置是value,索性统一处理,在具体场景下,再单独优化。
- Q3:源码里面的注释是不是错了呢?
笔者给Redis作者发了一封邮件去确认下,还未收到回信。