先贴上主函数代码:
async def init(loop): await orm.create_pool(loop=loop, host='127.0.0.1', port=3306, user='root', password='root', db='awesome') #1 app = web.Application(loop=loop, middlewares=[ #2 logger_factory, response_factory ]) init_jinja2(app, filters=dict(datetime=datetime_filter)) #3 add_routes(app, 'handlers') #4 add_static(app) #5 srv = await loop.create_server(app.make_handler(), '127.0.0.1', 9000) #6 logging.info('server started at http://127.0.0.1:9000...') return srv loop = asyncio.get_event_loop() loop.run_until_complete(init(loop)) loop.run_forever()
#1:创建数据库连接池;
#2:创建Web Application对象,其中middlewares后面重点述说;
#3:后期使用的模板框架;
#4:添加handlers模块中的URL处理函数到Web Application的router中;
#5:添加css等静态文件;
#6:创建服务器接受处理请求;
本节是一个重难点,各种查资料研究了一个多星期,整理心得体会如下:
一、可参阅资料
1、函数参数
coroweb模块中各种判断handlers模块中的URL处理函数的参数(位置参数、默认参数、可变参数、关键字参数、命名关键字参数)
廖雪峰Python教程之函数的参数
2、inspect模块相关
(1)【转载】python中inspect模块
(2)【翻译】模块inspect — Inspect live objects
3、特殊函数__call__
Python特殊函数__call__
4、aiohttp源码解析相关
(1)aiohttp 源码解析之 request 的处理过程
(2)python之aiohttp源码解析——add_route和middleware的工作方式
5、本节廖雪峰Python教程
Day 5 - 编写Web框架
二、分析服务器接收request到处理的过程
1、定义RequestHandler
URL处理函数不一定是一个coroutine,因此我们用RequestHandler()来封装一个URL处理函数。
RequestHandler是一个类,由于定义了__call__()方法,因此可以将其实例视为函数。
RequestHandler目的就是从URL函数中分析其需要接收的参数,从request中获取必要的参数,调用URL函数,然后把结果转换为web.Response对象,这样,就完全符合aiohttp框架的要求:
class RequestHandler(object): def __init__(self, app, fn): self._app = app self._func = fn ... async def __call__(self, request): ... try: r = await self._func(**kw) q return r except APIError as e: ...
再来分析下add_route函数:
def add_route(app, fn): method = getattr(fn, '__method__', None) path = getattr(fn, '__route__', None) if path is None or method is None: raise ValueError('@get or @post not defined in %s.' % str(fn)) if not asyncio.iscoroutinefunction(fn) and not inspect.isgeneratorfunction(fn): fn = asyncio.coroutine(fn) logging.info('add route %s %s => %s(%s)' % (method, path, fn.__name__, ', '.join(inspect.signature(fn).parameters.keys()))) app.router.add_route(method, path, RequestHandler(app, fn))
由此可知,针对请求method,path,处理函数是RequestHandler对象,构造函数中封装有真正的处理函数fn(handlers.py中,例如:def index()...),从RequestHandler类定义中的 r = await self._func(**kw) 也一样可以得出此结论(self._func = fn)。注意:此时URLHandler = RequestHandler (app, fn),因为定义了__call__函数,所以URLHandler(request), 可直接调用__call__函数来处理request。
2、middleware
middleware是一种拦截器,一个URL在被某个函数处理前,可以经过一系列的middleware的处理。
一个middleware可以改变URL的输入、输出,甚至可以决定不继续处理而直接返回。middleware的用处就在于把通用的功能从每个URL处理函数中拿出来,集中放到一个地方。
代码中middleware = [ logger_factory, response_factory ]。
截取《aiohttp 源码解析之 request 的处理过程》中针对middleware的处理源码:
handler = match_info.handler # 这个handler就是我们先前注册的request的最终处理函数,即RequestHandler对象,因为定义了__call__,所以对象即函数 for factory in reversed(self._middlewares): #逆置 handler = yield from factory(app, handler) # 重点来了,这里好像是在等待我们的 url 处理函数处理的结果啊 resp = yield from handler(request)
同时我们贴上两个相关函数:
async def logger_factory(app, handler): async def logger(request): logging.info('Request: %s %s' % (request.method, request.path)) return (await handler(request)) return logger async def response_factory(app, handler): async def response(request): logging.info('Response handler...') r = await handler(request) ... return resp return response
for循环中出现多次handler 和 yield from语句,我们调试分析下:
1、 handler = RequestHandler(app, fn) (Function Object ) factory = response_factory => handler = yield from factory(app, handler) => response_factory(app, RequestHandler(app, fn)) => response 2、 handler = response factory = logger_factory => handler = yield from factory(app, handler) => logger_factory(app, response) => logger
所以此时handler = logger,当有request进来,调用语句 resp = yield from handler(request) 时,分析如下:
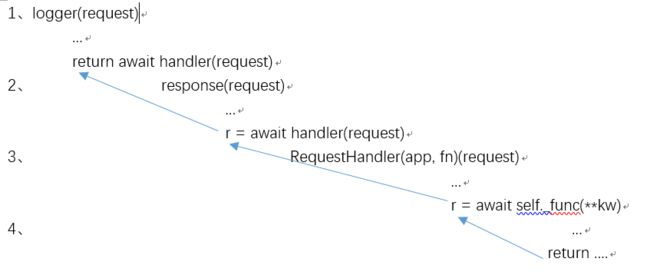
通过await建立管道,实际的URL处理函数func处理完后,将结果层层返回,直至logger。