不多说,直接上干货!
我这里,采取的是CentOS6.5,当然大家也可以在ubuntu 16.04系统里,这些都是小事
CentOS 6.5的安装详解
hadoop-2.6.0.tar.gz + spark-1.5.2-bin-hadoop2.6.tgz的集群搭建(单节点)(Ubuntu系统)
大数据搭建各个子项目时配置文件技巧(适合CentOS和Ubuntu系统)(博主推荐)
新建用户组、用户、用户密码、删除用户组、用户(适合CentOS、Ubuntu系统)
VMware里Ubuntu-16.04-desktop的VMware Tools安装图文详解
Ubuntukylin-14.04-desktop( 不带分区)安装步骤详解
Ubuntu14.04安装之后的一些配置
Ubuntu11.10 带图形安装步骤详解
Ubuntukylin-14.04-desktop(带分区)安装步骤详解
Ubuntu各版本的历史发行界面
Spark standalone模式的安装(spark-1.6.1-bin-hadoop2.6.tgz)(master、slave1和slave2)
我这里,采取的是CentOS6.5,而且Spark on YARN模式
Spark on YARN模式的安装(spark-1.6.1-bin-hadoop2.6.tgz + hadoop-2.6.0.tar.gz)(master、slave1和slave2)(博主推荐)
系统环境变量配置文件
#java export JAVA_HOME=/home/hadoop/app/jdk export JRE_HOME=$JAVA_HOME/jre export CLASSPATH=.:$JAVA_HOME/lib:$JRE_HOME/lib export PATH=$PATH:$JAVA_HOME/bin
#scala export SCALA_HOME=/home/hadoop/app/scala export PATH=$PATH:$SCALA_HOME/bin
#zookeeper export ZOOKEEPER_HOME=/home/hadoop/app/zookeeper
export PATH=$PATH:$ZOOKEEPER_HOME/bin #hadoop
export HADOOP_HOME=/home/hadoop/app/hadoop-2.6.0
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
#spark
export SPARK_HOME=/home/hadoop/app/spark
export PATH=$PATH:$SPARK_HOME/bin:$SPARK_HOME/sbin
我的路径是在/home/hadoop/app下
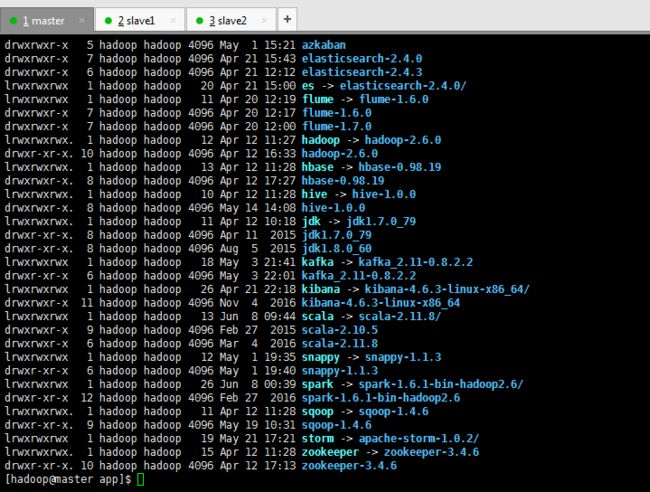

Hadoop的配置文件
slaves
slave1
slave2
hdfs-site.xml
"1.0" encoding="UTF-8"?> "text/xsl" href="configuration.xsl"?>dfs.namenode.rpc-address master:9000 dfs.namenode.http-address master:50070 dfs.replication 3 Set to 1 for pseudo-distributed mode,Set to 2 for distributed mode,Set to 3 for distributed mode. dfs.permissions false dfs.permissions.enabled false
core-site.xml
"1.0" encoding="UTF-8"?> "text/xsl" href="configuration.xsl"?>fs.default.name hdfs://master:9000 The name of the default file system, using 9000 port. hadoop.tmp.dir /home/hadoop/data/tmp A base for other temporary directories. ha.zookeeper.quorum master:2181,slave1:2181,slave2:2181
mapred-site.xml
"1.0"?> "text/xsl" href="configuration.xsl"?>mapred.job.tracker master:9001 mapreduce.framework.name yarn
yarn-site.xml
"1.0"?>yarn.resourcemanager.hostname master yarn.nodemanager.aux-services mapreduce_shuffle yarn.log-aggregation-enable true yarn.log-aggregation.retain-seconds 604800
hadoop-env.sh
# Licensed to the Apache Software Foundation (ASF) under one # or more contributor license agreements. See the NOTICE file # distributed with this work for additional information # regarding copyright ownership. The ASF licenses this file # to you under the Apache License, Version 2.0 (the # "License"); you may not use this file except in compliance # with the License. You may obtain a copy of the License at # # http://www.apache.org/licenses/LICENSE-2.0 # # Unless required by applicable law or agreed to in writing, software # distributed under the License is distributed on an "AS IS" BASIS, # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. # See the License for the specific language governing permissions and # limitations under the License. # Set Hadoop-specific environment variables here. # The only required environment variable is JAVA_HOME. All others are # optional. When running a distributed configuration it is best to # set JAVA_HOME in this file, so that it is correctly defined on # remote nodes. # The java implementation to use. export JAVA_HOME=/home/hadoop/app/jdk1.7.0_79 # The jsvc implementation to use. Jsvc is required to run secure datanodes # that bind to privileged ports to provide authentication of data transfer # protocol. Jsvc is not required if SASL is configured for authentication of # data transfer protocol using non-privileged ports. #export JSVC_HOME=${JSVC_HOME} export HADOOP_CONF_DIR=${HADOOP_CONF_DIR:-"/etc/hadoop"} # Extra Java CLASSPATH elements. Automatically insert capacity-scheduler. for f in $HADOOP_HOME/contrib/capacity-scheduler/*.jar; do if [ "$HADOOP_CLASSPATH" ]; then export HADOOP_CLASSPATH=$HADOOP_CLASSPATH:$f else export HADOOP_CLASSPATH=$f fi done # The maximum amount of heap to use, in MB. Default is 1000. #export HADOOP_HEAPSIZE= #export HADOOP_NAMENODE_INIT_HEAPSIZE="" # Extra Java runtime options. Empty by default. export HADOOP_OPTS="$HADOOP_OPTS -Djava.net.preferIPv4Stack=true" # Command specific options appended to HADOOP_OPTS when specified export HADOOP_NAMENODE_OPTS="-Dhadoop.security.logger=${HADOOP_SECURITY_LOGGER:-INFO,RFAS} -Dhdfs.audit.logger=${HDFS_AUDIT_LOGGER:-INFO,NullAppender} $HADOOP_NAMENODE_OPTS" export HADOOP_DATANODE_OPTS="-Dhadoop.security.logger=ERROR,RFAS $HADOOP_DATANODE_OPTS" export HADOOP_SECONDARYNAMENODE_OPTS="-Dhadoop.security.logger=${HADOOP_SECURITY_LOGGER:-INFO,RFAS} -Dhdfs.audit.logger=${HDFS_AUDIT_LOGGER:-INFO,NullAppender} $HADOOP_SECONDARYNAMENODE_OPTS" export HADOOP_NFS3_OPTS="$HADOOP_NFS3_OPTS" export HADOOP_PORTMAP_OPTS="-Xmx512m $HADOOP_PORTMAP_OPTS" # The following applies to multiple commands (fs, dfs, fsck, distcp etc) export HADOOP_CLIENT_OPTS="-Xmx512m $HADOOP_CLIENT_OPTS" #HADOOP_JAVA_PLATFORM_OPTS="-XX:-UsePerfData $HADOOP_JAVA_PLATFORM_OPTS" # On secure datanodes, user to run the datanode as after dropping privileges. # This **MUST** be uncommented to enable secure HDFS if using privileged ports # to provide authentication of data transfer protocol. This **MUST NOT** be # defined if SASL is configured for authentication of data transfer protocol # using non-privileged ports. export HADOOP_SECURE_DN_USER=${HADOOP_SECURE_DN_USER} # Where log files are stored. $HADOOP_HOME/logs by default. #export HADOOP_LOG_DIR=${HADOOP_LOG_DIR}/$USER # Where log files are stored in the secure data environment. export HADOOP_SECURE_DN_LOG_DIR=${HADOOP_LOG_DIR}/${HADOOP_HDFS_USER} ### # HDFS Mover specific parameters ### # Specify the JVM options to be used when starting the HDFS Mover. # These options will be appended to the options specified as HADOOP_OPTS # and therefore may override any similar flags set in HADOOP_OPTS # # export HADOOP_MOVER_OPTS="" ### # Advanced Users Only! ### # The directory where pid files are stored. /tmp by default. # NOTE: this should be set to a directory that can only be written to by # the user that will run the hadoop daemons. Otherwise there is the # potential for a symlink attack. export HADOOP_PID_DIR=${HADOOP_PID_DIR} export HADOOP_SECURE_DN_PID_DIR=${HADOOP_PID_DIR} # A string representing this instance of hadoop. $USER by default. export HADOOP_IDENT_STRING=$USER
Spark的配置文件
spark-env.sh
# - HADOOP_CONF_DIR, to point Spark towards Hadoop configuration files # - SPARK_EXECUTOR_INSTANCES, Number of executors to start (Default: 2) # - SPARK_EXECUTOR_CORES, Number of cores for the executors (Default: 1). # - SPARK_YARN_DIST_ARCHIVES, Comma separated list of archives to be distributed with the job. # Options for the daemons used in the standalone deploy mode # - SPARK_MASTER_IP, to bind the master to a different IP address or hostname # - SPARK_MASTER_PORT / SPARK_MASTER_WEBUI_PORT, to use non-default ports for the master # - SPARK_MASTER_OPTS, to set config properties only for the master (e.g. "-Dx=y") # - SPARK_WORKER_CORES, to set the number of cores to use on this machine # - SPARK_WORKER_MEMORY, to set how much total memory workers have to give executors (e.g. 1000m, 2g) # - SPARK_WORKER_PORT / SPARK_WORKER_WEBUI_PORT, to use non-default ports for the worker # - SPARK_WORKER_INSTANCES, to set the number of worker processes per node # - SPARK_WORKER_DIR, to set the working directory of worker processes # - SPARK_WORKER_OPTS, to set config properties only for the worker (e.g. "-Dx=y") # - SPARK_DAEMON_MEMORY, to allocate to the master, worker and history server themselves (default: 1g). # - SPARK_HISTORY_OPTS, to set config properties only for the history server (e.g. "-Dx=y") # - SPARK_SHUFFLE_OPTS, to set config properties only for the external shuffle service (e.g. "-Dx=y") # - SPARK_DAEMON_JAVA_OPTS, to set config properties for all daemons (e.g. "-Dx=y") # - SPARK_PUBLIC_DNS, to set the public dns name of the master or workers # Generic options for the daemons used in the standalone deploy mode # - SPARK_CONF_DIR Alternate conf dir. (Default: ${SPARK_HOME}/conf) # - SPARK_LOG_DIR Where log files are stored. (Default: ${SPARK_HOME}/logs) # - SPARK_PID_DIR Where the pid file is stored. (Default: /tmp) # - SPARK_IDENT_STRING A string representing this instance of spark. (Default: $USER) # - SPARK_NICENESS The scheduling priority for daemons. (Default: 0) export JAVA_HOME=/home/hadoop/app/jdk export SCALA_HOME=/home/hadoop/app/scala export HADOOP_HOME=/home/hadoop/app/hadoop export HADOOP_CONF_DIR=/home/hadoop/app/hadoop/etc/hadoop export SPARK_MASTER_IP=192.168.80.145 export SPARK_WORKER_MERMORY=1G
slaves
# # Licensed to the Apache Software Foundation (ASF) under one or more # contributor license agreements. See the NOTICE file distributed with # this work for additional information regarding copyright ownership. # The ASF licenses this file to You under the Apache License, Version 2.0 # (the "License"); you may not use this file except in compliance with # the License. You may obtain a copy of the License at # # http://www.apache.org/licenses/LICENSE-2.0 # # Unless required by applicable law or agreed to in writing, software # distributed under the License is distributed on an "AS IS" BASIS, # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. # See the License for the specific language governing permissions and # limitations under the License. # # A Spark Worker will be started on each of the machines listed below. slave1 slave2
大家一定要去看我的前期博客。
下面,我是接着直接来下载并安装配置Zeppelin
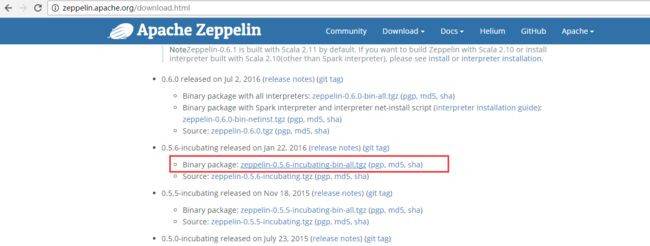
首先一点想说的是版本问题,为什么本博文的标题我会写清楚版本号呢!原因就是版本不对真的很会坑人。
博主我也尝试过hadoop-2.7.3.tar.gz + spark-2.1.0-bin-hadoop2.7.tgz。
但是呢,对于zeppelin的版本,目前官网开发团队确实做的不太好,控制版本有待完善。
坑人的地方在哪里呢,Zeppelin0.5.6不支持Spark2.1.0这个版本
于是我又仔细的查看了官网的教程:
得出的结论是我必须要装老版本的,还好的是支持Spark2.0,于是我又安装了Spark1.6.1
不过呢如果你没有任何的集群环境,上面这篇是值得参考的,只不过你得自己改下版本号,从2.1.0到1.6.1,其他完全一样。
当然,庆幸的是,教大家,灵活会用软连接,实现多版本的使用。
大数据各子项目的环境搭建之建立与删除软连接(博主推荐)

1、上传zeppelin-0.5.6-incubating-bin-all.tgz压缩包
![]()
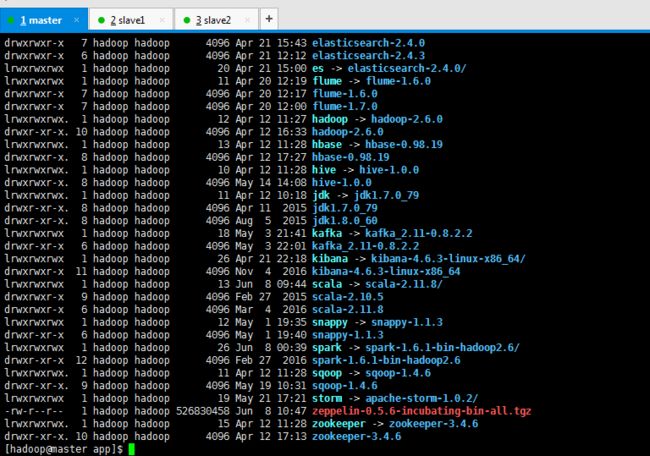
[hadoop@master app]$ pwd /home/hadoop/app [hadoop@master app]$ ll total 80 drwxrwxr-x 2 hadoop hadoop 4096 May 21 17:20 apache-storm-0.9.6 drwxrwxr-x 12 hadoop hadoop 4096 May 21 18:51 apache-storm-1.0.2 drwxrwxr-x 5 hadoop hadoop 4096 May 1 15:21 azkaban drwxrwxr-x 7 hadoop hadoop 4096 Apr 21 15:43 elasticsearch-2.4.0 drwxrwxr-x 6 hadoop hadoop 4096 Apr 21 12:12 elasticsearch-2.4.3 lrwxrwxrwx 1 hadoop hadoop 20 Apr 21 15:00 es -> elasticsearch-2.4.0/ lrwxrwxrwx 1 hadoop hadoop 11 Apr 20 12:19 flume -> flume-1.6.0 drwxrwxr-x 7 hadoop hadoop 4096 Apr 20 12:17 flume-1.6.0 drwxrwxr-x 7 hadoop hadoop 4096 Apr 20 12:00 flume-1.7.0 lrwxrwxrwx. 1 hadoop hadoop 12 Apr 12 11:27 hadoop -> hadoop-2.6.0 drwxr-xr-x. 10 hadoop hadoop 4096 Apr 12 16:33 hadoop-2.6.0 lrwxrwxrwx. 1 hadoop hadoop 13 Apr 12 11:28 hbase -> hbase-0.98.19 drwxrwxr-x. 8 hadoop hadoop 4096 Apr 12 17:27 hbase-0.98.19 lrwxrwxrwx. 1 hadoop hadoop 10 Apr 12 11:28 hive -> hive-1.0.0 drwxrwxr-x. 8 hadoop hadoop 4096 May 14 14:08 hive-1.0.0 lrwxrwxrwx. 1 hadoop hadoop 11 Apr 12 10:18 jdk -> jdk1.7.0_79 drwxr-xr-x. 8 hadoop hadoop 4096 Apr 11 2015 jdk1.7.0_79 drwxr-xr-x. 8 hadoop hadoop 4096 Aug 5 2015 jdk1.8.0_60 lrwxrwxrwx 1 hadoop hadoop 18 May 3 21:41 kafka -> kafka_2.11-0.8.2.2 drwxr-xr-x 6 hadoop hadoop 4096 May 3 22:01 kafka_2.11-0.8.2.2 lrwxrwxrwx 1 hadoop hadoop 26 Apr 21 22:18 kibana -> kibana-4.6.3-linux-x86_64/ drwxrwxr-x 11 hadoop hadoop 4096 Nov 4 2016 kibana-4.6.3-linux-x86_64 lrwxrwxrwx 1 hadoop hadoop 13 Jun 8 09:44 scala -> scala-2.11.8/ drwxrwxr-x 9 hadoop hadoop 4096 Feb 27 2015 scala-2.10.5 drwxrwxr-x 6 hadoop hadoop 4096 Mar 4 2016 scala-2.11.8 lrwxrwxrwx 1 hadoop hadoop 12 May 1 19:35 snappy -> snappy-1.1.3 drwxr-xr-x 6 hadoop hadoop 4096 May 1 19:40 snappy-1.1.3 lrwxrwxrwx 1 hadoop hadoop 26 Jun 8 00:39 spark -> spark-1.6.1-bin-hadoop2.6/ drwxr-xr-x 12 hadoop hadoop 4096 Feb 27 2016 spark-1.6.1-bin-hadoop2.6 lrwxrwxrwx. 1 hadoop hadoop 11 Apr 12 11:28 sqoop -> sqoop-1.4.6 drwxr-xr-x. 9 hadoop hadoop 4096 May 19 10:31 sqoop-1.4.6 lrwxrwxrwx 1 hadoop hadoop 19 May 21 17:21 storm -> apache-storm-1.0.2/ lrwxrwxrwx. 1 hadoop hadoop 15 Apr 12 11:28 zookeeper -> zookeeper-3.4.6 drwxr-xr-x. 10 hadoop hadoop 4096 Apr 12 17:13 zookeeper-3.4.6 [hadoop@master app]$ rz [hadoop@master app]$ ll total 514568 drwxrwxr-x 2 hadoop hadoop 4096 May 21 17:20 apache-storm-0.9.6 drwxrwxr-x 12 hadoop hadoop 4096 May 21 18:51 apache-storm-1.0.2 drwxrwxr-x 5 hadoop hadoop 4096 May 1 15:21 azkaban drwxrwxr-x 7 hadoop hadoop 4096 Apr 21 15:43 elasticsearch-2.4.0 drwxrwxr-x 6 hadoop hadoop 4096 Apr 21 12:12 elasticsearch-2.4.3 lrwxrwxrwx 1 hadoop hadoop 20 Apr 21 15:00 es -> elasticsearch-2.4.0/ lrwxrwxrwx 1 hadoop hadoop 11 Apr 20 12:19 flume -> flume-1.6.0 drwxrwxr-x 7 hadoop hadoop 4096 Apr 20 12:17 flume-1.6.0 drwxrwxr-x 7 hadoop hadoop 4096 Apr 20 12:00 flume-1.7.0 lrwxrwxrwx. 1 hadoop hadoop 12 Apr 12 11:27 hadoop -> hadoop-2.6.0 drwxr-xr-x. 10 hadoop hadoop 4096 Apr 12 16:33 hadoop-2.6.0 lrwxrwxrwx. 1 hadoop hadoop 13 Apr 12 11:28 hbase -> hbase-0.98.19 drwxrwxr-x. 8 hadoop hadoop 4096 Apr 12 17:27 hbase-0.98.19 lrwxrwxrwx. 1 hadoop hadoop 10 Apr 12 11:28 hive -> hive-1.0.0 drwxrwxr-x. 8 hadoop hadoop 4096 May 14 14:08 hive-1.0.0 lrwxrwxrwx. 1 hadoop hadoop 11 Apr 12 10:18 jdk -> jdk1.7.0_79 drwxr-xr-x. 8 hadoop hadoop 4096 Apr 11 2015 jdk1.7.0_79 drwxr-xr-x. 8 hadoop hadoop 4096 Aug 5 2015 jdk1.8.0_60 lrwxrwxrwx 1 hadoop hadoop 18 May 3 21:41 kafka -> kafka_2.11-0.8.2.2 drwxr-xr-x 6 hadoop hadoop 4096 May 3 22:01 kafka_2.11-0.8.2.2 lrwxrwxrwx 1 hadoop hadoop 26 Apr 21 22:18 kibana -> kibana-4.6.3-linux-x86_64/ drwxrwxr-x 11 hadoop hadoop 4096 Nov 4 2016 kibana-4.6.3-linux-x86_64 lrwxrwxrwx 1 hadoop hadoop 13 Jun 8 09:44 scala -> scala-2.11.8/ drwxrwxr-x 9 hadoop hadoop 4096 Feb 27 2015 scala-2.10.5 drwxrwxr-x 6 hadoop hadoop 4096 Mar 4 2016 scala-2.11.8 lrwxrwxrwx 1 hadoop hadoop 12 May 1 19:35 snappy -> snappy-1.1.3 drwxr-xr-x 6 hadoop hadoop 4096 May 1 19:40 snappy-1.1.3 lrwxrwxrwx 1 hadoop hadoop 26 Jun 8 00:39 spark -> spark-1.6.1-bin-hadoop2.6/ drwxr-xr-x 12 hadoop hadoop 4096 Feb 27 2016 spark-1.6.1-bin-hadoop2.6 lrwxrwxrwx. 1 hadoop hadoop 11 Apr 12 11:28 sqoop -> sqoop-1.4.6 drwxr-xr-x. 9 hadoop hadoop 4096 May 19 10:31 sqoop-1.4.6 lrwxrwxrwx 1 hadoop hadoop 19 May 21 17:21 storm -> apache-storm-1.0.2/ -rw-r--r-- 1 hadoop hadoop 526830458 Jun 8 10:47 zeppelin-0.5.6-incubating-bin-all.tgz lrwxrwxrwx. 1 hadoop hadoop 15 Apr 12 11:28 zookeeper -> zookeeper-3.4.6 drwxr-xr-x. 10 hadoop hadoop 4096 Apr 12 17:13 zookeeper-3.4.6 [hadoop@master app]$
2、解压并为创建软连接
[hadoop@master app]$ tar -zxvf zeppelin-0.5.6-incubating-bin-all.tgz
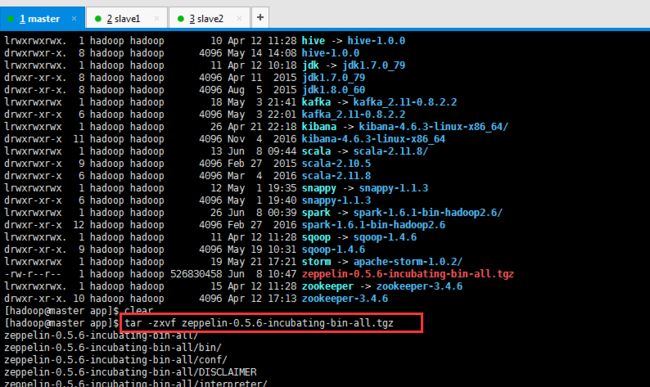
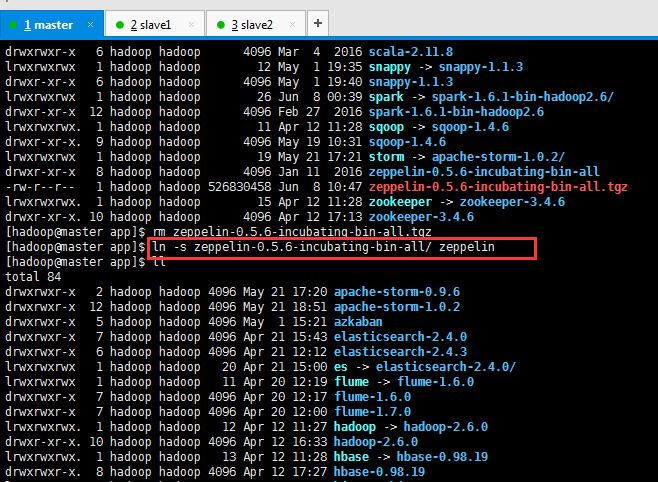
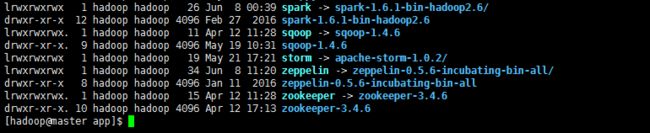
[hadoop@master app]$ ll total 514572 drwxrwxr-x 2 hadoop hadoop 4096 May 21 17:20 apache-storm-0.9.6 drwxrwxr-x 12 hadoop hadoop 4096 May 21 18:51 apache-storm-1.0.2 drwxrwxr-x 5 hadoop hadoop 4096 May 1 15:21 azkaban drwxrwxr-x 7 hadoop hadoop 4096 Apr 21 15:43 elasticsearch-2.4.0 drwxrwxr-x 6 hadoop hadoop 4096 Apr 21 12:12 elasticsearch-2.4.3 lrwxrwxrwx 1 hadoop hadoop 20 Apr 21 15:00 es -> elasticsearch-2.4.0/ lrwxrwxrwx 1 hadoop hadoop 11 Apr 20 12:19 flume -> flume-1.6.0 drwxrwxr-x 7 hadoop hadoop 4096 Apr 20 12:17 flume-1.6.0 drwxrwxr-x 7 hadoop hadoop 4096 Apr 20 12:00 flume-1.7.0 lrwxrwxrwx. 1 hadoop hadoop 12 Apr 12 11:27 hadoop -> hadoop-2.6.0 drwxr-xr-x. 10 hadoop hadoop 4096 Apr 12 16:33 hadoop-2.6.0 lrwxrwxrwx. 1 hadoop hadoop 13 Apr 12 11:28 hbase -> hbase-0.98.19 drwxrwxr-x. 8 hadoop hadoop 4096 Apr 12 17:27 hbase-0.98.19 lrwxrwxrwx. 1 hadoop hadoop 10 Apr 12 11:28 hive -> hive-1.0.0 drwxrwxr-x. 8 hadoop hadoop 4096 May 14 14:08 hive-1.0.0 lrwxrwxrwx. 1 hadoop hadoop 11 Apr 12 10:18 jdk -> jdk1.7.0_79 drwxr-xr-x. 8 hadoop hadoop 4096 Apr 11 2015 jdk1.7.0_79 drwxr-xr-x. 8 hadoop hadoop 4096 Aug 5 2015 jdk1.8.0_60 lrwxrwxrwx 1 hadoop hadoop 18 May 3 21:41 kafka -> kafka_2.11-0.8.2.2 drwxr-xr-x 6 hadoop hadoop 4096 May 3 22:01 kafka_2.11-0.8.2.2 lrwxrwxrwx 1 hadoop hadoop 26 Apr 21 22:18 kibana -> kibana-4.6.3-linux-x86_64/ drwxrwxr-x 11 hadoop hadoop 4096 Nov 4 2016 kibana-4.6.3-linux-x86_64 lrwxrwxrwx 1 hadoop hadoop 13 Jun 8 09:44 scala -> scala-2.11.8/ drwxrwxr-x 9 hadoop hadoop 4096 Feb 27 2015 scala-2.10.5 drwxrwxr-x 6 hadoop hadoop 4096 Mar 4 2016 scala-2.11.8 lrwxrwxrwx 1 hadoop hadoop 12 May 1 19:35 snappy -> snappy-1.1.3 drwxr-xr-x 6 hadoop hadoop 4096 May 1 19:40 snappy-1.1.3 lrwxrwxrwx 1 hadoop hadoop 26 Jun 8 00:39 spark -> spark-1.6.1-bin-hadoop2.6/ drwxr-xr-x 12 hadoop hadoop 4096 Feb 27 2016 spark-1.6.1-bin-hadoop2.6 lrwxrwxrwx. 1 hadoop hadoop 11 Apr 12 11:28 sqoop -> sqoop-1.4.6 drwxr-xr-x. 9 hadoop hadoop 4096 May 19 10:31 sqoop-1.4.6 lrwxrwxrwx 1 hadoop hadoop 19 May 21 17:21 storm -> apache-storm-1.0.2/ drwxr-xr-x 8 hadoop hadoop 4096 Jan 11 2016 zeppelin-0.5.6-incubating-bin-all -rw-r--r-- 1 hadoop hadoop 526830458 Jun 8 10:47 zeppelin-0.5.6-incubating-bin-all.tgz lrwxrwxrwx. 1 hadoop hadoop 15 Apr 12 11:28 zookeeper -> zookeeper-3.4.6 drwxr-xr-x. 10 hadoop hadoop 4096 Apr 12 17:13 zookeeper-3.4.6 [hadoop@master app]$ rm zeppelin-0.5.6-incubating-bin-all.tgz [hadoop@master app]$ ln -s zeppelin-0.5.6-incubating-bin-all/ zeppelin [hadoop@master app]$ ll total 84 drwxrwxr-x 2 hadoop hadoop 4096 May 21 17:20 apache-storm-0.9.6 drwxrwxr-x 12 hadoop hadoop 4096 May 21 18:51 apache-storm-1.0.2 drwxrwxr-x 5 hadoop hadoop 4096 May 1 15:21 azkaban drwxrwxr-x 7 hadoop hadoop 4096 Apr 21 15:43 elasticsearch-2.4.0 drwxrwxr-x 6 hadoop hadoop 4096 Apr 21 12:12 elasticsearch-2.4.3 lrwxrwxrwx 1 hadoop hadoop 20 Apr 21 15:00 es -> elasticsearch-2.4.0/ lrwxrwxrwx 1 hadoop hadoop 11 Apr 20 12:19 flume -> flume-1.6.0 drwxrwxr-x 7 hadoop hadoop 4096 Apr 20 12:17 flume-1.6.0 drwxrwxr-x 7 hadoop hadoop 4096 Apr 20 12:00 flume-1.7.0 lrwxrwxrwx. 1 hadoop hadoop 12 Apr 12 11:27 hadoop -> hadoop-2.6.0 drwxr-xr-x. 10 hadoop hadoop 4096 Apr 12 16:33 hadoop-2.6.0 lrwxrwxrwx. 1 hadoop hadoop 13 Apr 12 11:28 hbase -> hbase-0.98.19 drwxrwxr-x. 8 hadoop hadoop 4096 Apr 12 17:27 hbase-0.98.19 lrwxrwxrwx. 1 hadoop hadoop 10 Apr 12 11:28 hive -> hive-1.0.0 drwxrwxr-x. 8 hadoop hadoop 4096 May 14 14:08 hive-1.0.0 lrwxrwxrwx. 1 hadoop hadoop 11 Apr 12 10:18 jdk -> jdk1.7.0_79 drwxr-xr-x. 8 hadoop hadoop 4096 Apr 11 2015 jdk1.7.0_79 drwxr-xr-x. 8 hadoop hadoop 4096 Aug 5 2015 jdk1.8.0_60 lrwxrwxrwx 1 hadoop hadoop 18 May 3 21:41 kafka -> kafka_2.11-0.8.2.2 drwxr-xr-x 6 hadoop hadoop 4096 May 3 22:01 kafka_2.11-0.8.2.2 lrwxrwxrwx 1 hadoop hadoop 26 Apr 21 22:18 kibana -> kibana-4.6.3-linux-x86_64/ drwxrwxr-x 11 hadoop hadoop 4096 Nov 4 2016 kibana-4.6.3-linux-x86_64 lrwxrwxrwx 1 hadoop hadoop 13 Jun 8 09:44 scala -> scala-2.11.8/ drwxrwxr-x 9 hadoop hadoop 4096 Feb 27 2015 scala-2.10.5 drwxrwxr-x 6 hadoop hadoop 4096 Mar 4 2016 scala-2.11.8 lrwxrwxrwx 1 hadoop hadoop 12 May 1 19:35 snappy -> snappy-1.1.3 drwxr-xr-x 6 hadoop hadoop 4096 May 1 19:40 snappy-1.1.3 lrwxrwxrwx 1 hadoop hadoop 26 Jun 8 00:39 spark -> spark-1.6.1-bin-hadoop2.6/ drwxr-xr-x 12 hadoop hadoop 4096 Feb 27 2016 spark-1.6.1-bin-hadoop2.6 lrwxrwxrwx. 1 hadoop hadoop 11 Apr 12 11:28 sqoop -> sqoop-1.4.6 drwxr-xr-x. 9 hadoop hadoop 4096 May 19 10:31 sqoop-1.4.6 lrwxrwxrwx 1 hadoop hadoop 19 May 21 17:21 storm -> apache-storm-1.0.2/ lrwxrwxrwx 1 hadoop hadoop 34 Jun 8 11:20 zeppelin -> zeppelin-0.5.6-incubating-bin-all/ drwxr-xr-x 8 hadoop hadoop 4096 Jan 11 2016 zeppelin-0.5.6-incubating-bin-all lrwxrwxrwx. 1 hadoop hadoop 15 Apr 12 11:28 zookeeper -> zookeeper-3.4.6 drwxr-xr-x. 10 hadoop hadoop 4096 Apr 12 17:13 zookeeper-3.4.6 [hadoop@master app]$
3、修改环境变量配置
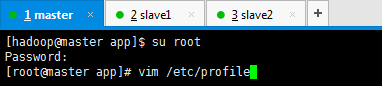
[hadoop@master app]$ su root
Password:
[root@master app]# vim /etc/profile
#zeppelin export ZEPPELIN_HOME=/home/hadoop/app/zeppelin export PATH=$PATH:$ZEPPELIN_HOME/bin
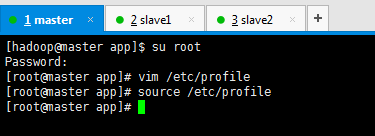
[hadoop@master app]$ su root Password: [root@master app]# vim /etc/profile [root@master app]# source /etc/profile [root@master app]#
4.安装并修改配置文件:
(1)安装
网络安装版需要运行下面的命令:
./bin/install-interpreter.sh --all
而完整版不需要,直接进入到zeppelin的根目录修改配置文件即可。(我这里)
cd zeppelin-0.5.6-incubating-bin-all
(2)/home/hadoop/app/zeppelin-0.5.6-incubating-bin-all/conf/zeppelin-env.sh
export JAVA_HOME=/home/hadoop/app/jdk export SPARK_HOME=/home/hadoop/app/spark export HADOOP_HOME=/home/hadoop/app/hadoop export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop export ZEPPELIN_HOME_INTP_JAVA_OPTS="-XX:PermSize=512M -XX:MaxPermSize=1024M"
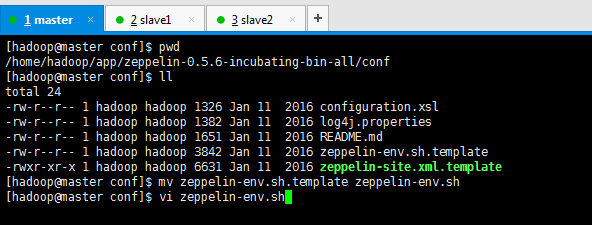
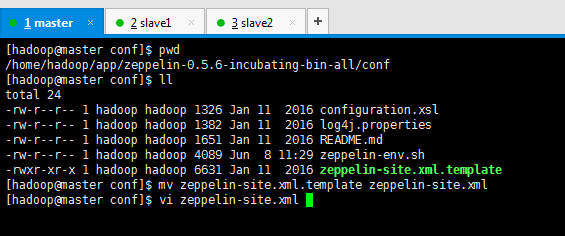
[hadoop@master conf]$ pwd /home/hadoop/app/zeppelin-0.5.6-incubating-bin-all/conf [hadoop@master conf]$ ll total 24 -rw-r--r-- 1 hadoop hadoop 1326 Jan 11 2016 configuration.xsl -rw-r--r-- 1 hadoop hadoop 1382 Jan 11 2016 log4j.properties -rw-r--r-- 1 hadoop hadoop 1651 Jan 11 2016 README.md -rw-r--r-- 1 hadoop hadoop 3842 Jan 11 2016 zeppelin-env.sh.template -rwxr-xr-x 1 hadoop hadoop 6631 Jan 11 2016 zeppelin-site.xml.template [hadoop@master conf]$ mv zeppelin-env.sh.template zeppelin-env.sh [hadoop@master conf]$ vi zeppelin-env.sh
export JAVA_HOME=/home/hadoop/app/jdk export SPARK_HOME=/home/hadoop/app/spark export HADOOP_HOME=/home/hadoop/app/hadoop export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop export ZEPPELIN_HOME_INTP_JAVA_OPTS="-XX:PermSize=512M -XX:MaxPermSize=1024M"
以上,主要是设置Java、Spark、Hadoop的安装路径,并且设置Java内存的使用量。
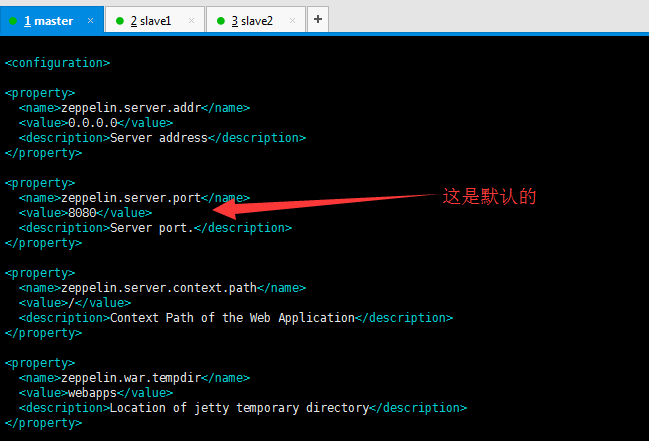
(3)/home/hadoop/app/zeppelin-0.5.6-incubating-bin-all/conf/zeppelin-site.xml
这里,我跟大家普及一个大数据领域的端口知识。(以下是我习惯用的端口情况)
YARN web ui 是8088
HBase web ui是60010、60030
Hadoop web ui是50070
Spark web ui是8081
Ooize web ui是11000
Kibana web ui是5601
Hue web ui是8888
Elasticsearch/Kopf/Head web ui是9200
Resourcemanager web ui是23188
History web ui是19888
Azakban web ui是8443
Storm web ui是9999
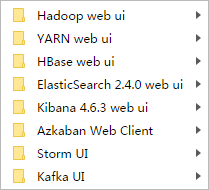
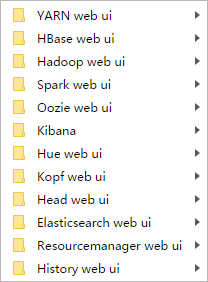
基于以上考虑,
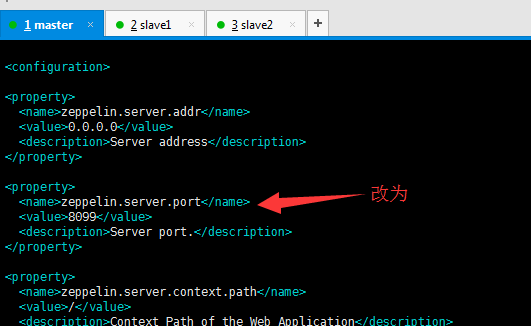
为了防止端口冲突我将zeppelin的默认端口8080改为8099,具体情况要看自己的机子决定:
zeppelin.server.port 8099 Server port.
[hadoop@master conf]$ pwd /home/hadoop/app/zeppelin-0.5.6-incubating-bin-all/conf [hadoop@master conf]$ ll total 24 -rw-r--r-- 1 hadoop hadoop 1326 Jan 11 2016 configuration.xsl -rw-r--r-- 1 hadoop hadoop 1382 Jan 11 2016 log4j.properties -rw-r--r-- 1 hadoop hadoop 1651 Jan 11 2016 README.md -rw-r--r-- 1 hadoop hadoop 4089 Jun 8 11:29 zeppelin-env.sh -rwxr-xr-x 1 hadoop hadoop 6631 Jan 11 2016 zeppelin-site.xml.template [hadoop@master conf]$ mv zeppelin-site.xml.template zeppelin-site.xml [hadoop@master conf]$ vi zeppelin-site.xml
4.启动或关闭:
修改之前的启动脚本为:(当然大家,也可不修改)
#!/bin/bash echo -e "\033[31m ========Start The Cluster======== \033[0m" echo -e "\033[31m Starting Hadoop Now !!! \033[0m" /opt/hadoop-2.7.3/sbin/start-all.sh echo -e "\033[31m Starting Spark Now !!! \033[0m" /opt/spark-2.0.2-bin-hadoop2.7/sbin/start-all.sh echo -e "\033[31m Starting Zeppelin Now !!! \033[0m" /opt/zeppelin-0.6.2-bin-all/bin/zeppelin-daemon.sh start echo -e "\033[31m The Result Of The Command \"jps\" : \033[0m" jps echo -e "\033[31m ========END======== \033[0m"
修改之前的关闭脚本为:(当然大家,也可不修改)
#!/bin/bash echo -e "\033[31m ===== Stoping The Cluster ====== \033[0m" echo -e "\033[31m Stoping Zeppelin Now !!! \033[0m" /opt/zeppelin-0.6.2-bin-all/bin/zeppelin-daemon.sh stop echo -e "\033[31m Stoping Spark Now !!! \033[0m" /opt/spark-2.0.2-bin-hadoop2.7/sbin/stop-all.sh echo -e "\033[31m Stopting Hadoop Now !!! \033[0m" /opt/hadoop-2.7.3/sbin/stop-all.sh echo -e "\033[31m The Result Of The Command \"jps\" : \033[0m" jps echo -e "\033[31m ======END======== \033[0m"
启动Apache Zeppelin
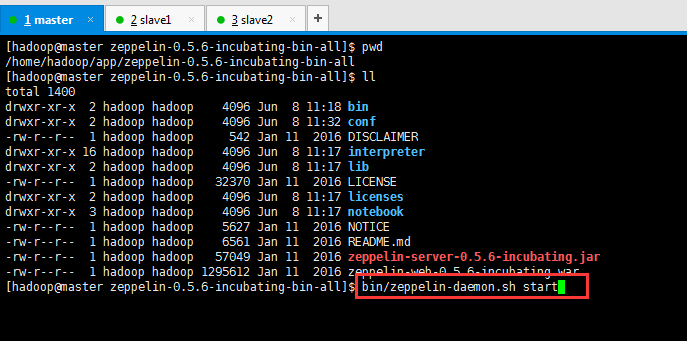
在zeppelin_home目录下执行如下命令:
[hadoop@master zeppelin-0.5.6-incubating-bin-all]$ bin/zeppelin-daemon.sh start
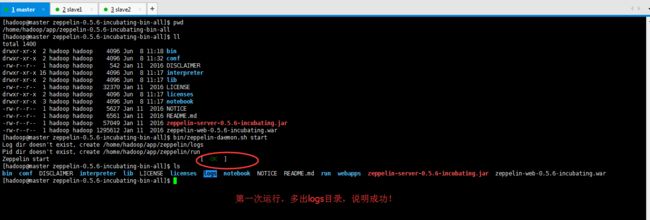
[hadoop@master zeppelin-0.5.6-incubating-bin-all]$ pwd /home/hadoop/app/zeppelin-0.5.6-incubating-bin-all [hadoop@master zeppelin-0.5.6-incubating-bin-all]$ ll total 1400 drwxr-xr-x 2 hadoop hadoop 4096 Jun 8 11:18 bin drwxr-xr-x 2 hadoop hadoop 4096 Jun 8 11:32 conf -rw-r--r-- 1 hadoop hadoop 542 Jan 11 2016 DISCLAIMER drwxr-xr-x 16 hadoop hadoop 4096 Jun 8 11:17 interpreter drwxr-xr-x 2 hadoop hadoop 4096 Jun 8 11:17 lib -rw-r--r-- 1 hadoop hadoop 32370 Jan 11 2016 LICENSE drwxr-xr-x 2 hadoop hadoop 4096 Jun 8 11:17 licenses drwxr-xr-x 3 hadoop hadoop 4096 Jun 8 11:17 notebook -rw-r--r-- 1 hadoop hadoop 5627 Jan 11 2016 NOTICE -rw-r--r-- 1 hadoop hadoop 6561 Jan 11 2016 README.md -rw-r--r-- 1 hadoop hadoop 57049 Jan 11 2016 zeppelin-server-0.5.6-incubating.jar -rw-r--r-- 1 hadoop hadoop 1295612 Jan 11 2016 zeppelin-web-0.5.6-incubating.war [hadoop@master zeppelin-0.5.6-incubating-bin-all]$ bin/zeppelin-daemon.sh start Log dir doesn't exist, create /home/hadoop/app/zeppelin/logs Pid dir doesn't exist, create /home/hadoop/app/zeppelin/run Zeppelin start [ OK ] [hadoop@master zeppelin-0.5.6-incubating-bin-all]$ ls bin conf DISCLAIMER interpreter lib LICENSE licenses logs notebook NOTICE README.md run webapps zeppelin-server-0.5.6-incubating.jar zeppelin-web-0.5.6-incubating.war [hadoop@master zeppelin-0.5.6-incubating-bin-all]$
其启动/停止命令: bin/zeppelin-daemon.sh start/stop。
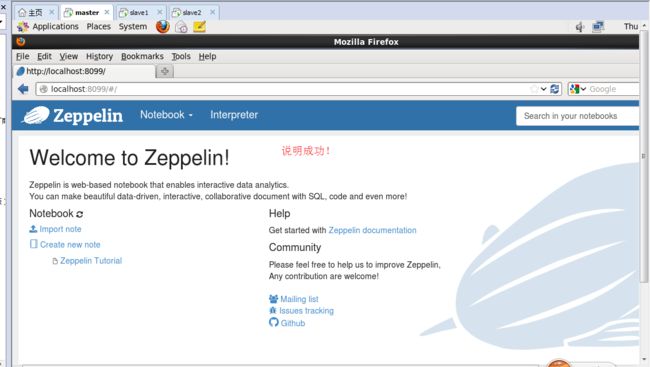
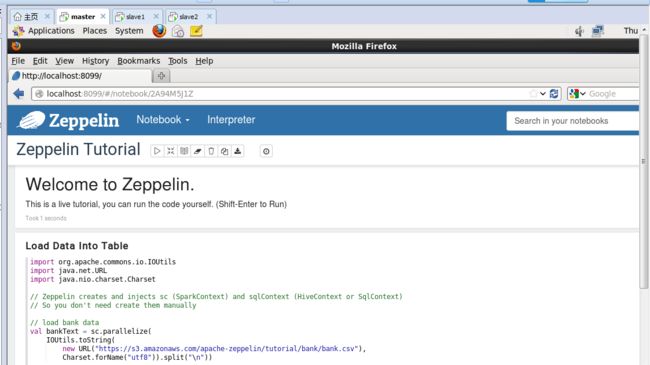
启动之后,打开localhost:8099访问zepplin主页。
http://localhost:8099/#/
我这里是
在打开Zeppelin Web UI界面之后,然后如下
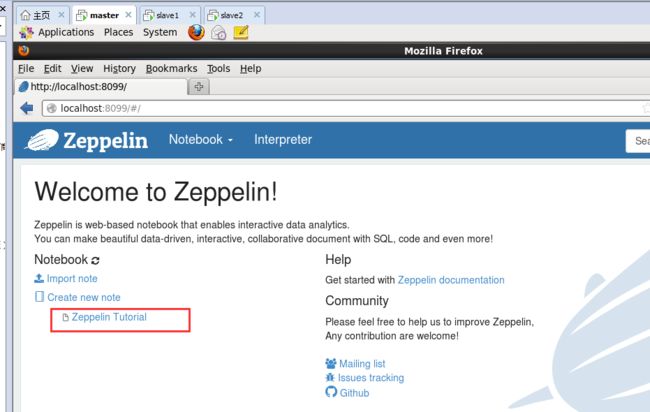
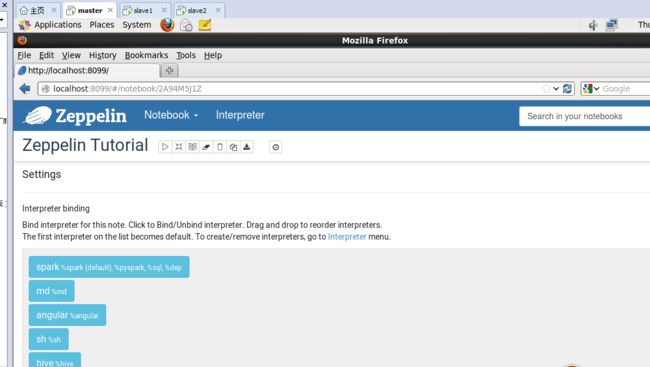
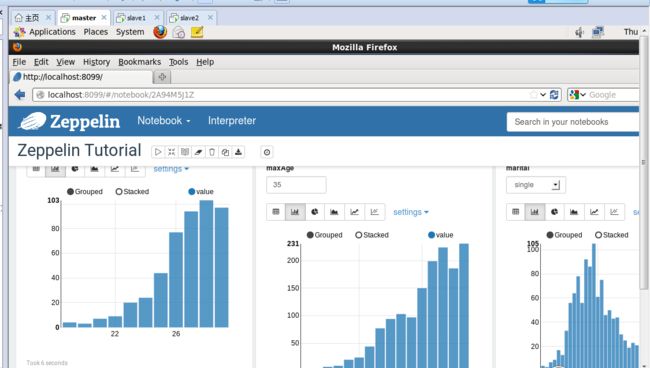
单击,会显示出Zeppelin Tutorial Notebook现成的范例供用户参考
然后,可以看到
后续博客