如何计算Java对象所占内存的大小
关键词:HotspotVM、Java对象头、HSDB、锁原理、分代GC、OOP-Klass
摘要
背景
目前我们系统的业务代码中大量使用了LocalCache的方式做本地缓存,而且cache的maxSize通常设的比较大,比如10000。我们的业务系统中就使用了size为10000的15个本地缓存,所以最坏情况下将可缓存15万个对象。这会消耗掉不菲的本地堆内存,而至于实际上到底应该设多大容量的缓存、运行时这大量的本地缓存会给堆内存带来多少压力,实际占用多少内存大小,会不会有较高的缓存穿透风险,目前并不方便知悉。考虑到对缓存实际占用内存的大小能有个更直观和量化的参考,需要对运行时指定对象的内存占用进行评估和计算。
要计算Java对象占用内存的大小,首先需要了解Java对象在内存中的实际存储方式和存储格式。
另一方面,大家都了解Java对象的存储总得来说会占用JVM内存的堆内存、栈内存及方法区,但由于栈内存中存放的数据可以看做是运行时的临时数据,主要表现为本地变量、操作数、对象引用地址等。这些数据会在方法执行结束后立即回收掉,不会驻留。对存储空间空间的占用也只是执行函数指令时所必须的空间。通常不会造成内存的瓶颈。而方法区中存储的则是对象所对应的类信息、函数表、构造函数、静态常量等,这些信息在类加载时(按需)只会在方法区中存储一份,不会产生额外的存储空间。因此本文所要讨论的主要目标是Java对象对堆内存的占用。
内存占用计算方法
如果读者关心对象在JVM中的存储原理,可阅读本文后边几个小节中关于对象存储原理的介绍。如果不关心对象存储原理,而只想直接计算内存占用的话,其实并不难,笔者这里总结了三种方法以供参考:
1. Instrumentation
使用java.lang.instrument.Instrumentation.getObjectSize()方法,可以很方便的计算任何一个运行时对象的大小,返回该对象本身及其间接引用的对象在内存中的大小。不过,这个类的唯一实现类InstrumentationImpl的构造方法是私有的,在创建时,需要依赖一个nativeAgent,和运行环境所支持的一些预定义类信息,我们在代码中无法直接实例化它,需要在JVM启动时,通过指定代理的方式,让JVM来实例化它。
具体来讲,就是需要声明一个premain方法,它和main方法的方法签名有点相似,只不过方法名叫“premain”,同时方法参数也不一样,它接收一个String类型和instrumentation参数,而String参数实际上和String[]是一样的,只不过用String统一来表达的。在premain函数中,将instrumentation参数赋给一个静态变量,其它地方就可以使用了。如:
/**
* @author yepei
* @date 2018/04/23
* @description
*/
public class SizeTool {
private static Instrumentation instrumentation;
public static void premain(String args, Instrumentation inst) {
instrumentation = inst;
}
public static long getObjectSize(Object o) {
return instrumentation.getObjectSize(o);
}
}从方法名可以猜到,这里的premain是要先于main执行的,而先于main执行,这个动作只能由JVM来完成了。即在JVM启动时,先启动一个agent,操作如下:
假设main方法所在的jar包为:A.jar,premain方法所在的jar包为B.jar。注意为main所在的代码打包时,和其它工具类打包一样,需要声明一个MANIFEST.MF清单文件,如下所求:
Manifest-Version: 1.0
Main-Class: yp.tools.Main
Premain-Class: yp.tools.SizeTool然后执行java命令执行jar文件:
java -javaagent:B.jar -jar A.jar
点评:这种方法的优点是编码简单,缺点就是必须启动一个javaagent,因此要求修改Java的启动参数。
2. 使用Unsafe
java中的sun.misc.Unsafe类,有一个objectFieldOffset(Field f)方法,表示获取指定字段在所在实例中的起始地址偏移量,如此可以计算出指定的对象中每个字段的偏移量,值为最大的那个就是最后一个字段的首地址,加上该字段的实际大小,就能知道该对象整体的大小。如现有一Person类:
class Person{
int age;
String name;
boolean married;
}假设该类的一个实例p,通过Unsafe.objectFieldOffset()方法计算到得age/birthday/married三个字段的偏移量分别是16,21, 17,则表明p1对象中的最后一个字段是name,它的首地址是21,由于它是一个引用,所以它的大小默认为4(开启指针压缩),则该对象本身的大小就是21+4+ 7= 32字节。其中7表示padding,即为了使结果变成8的整数倍而做的padding。
但上述计算,只是计算了对象本身的大小,并没有计算其所引用的引用类型的最终大小,这就需要手工写代码进行递归计算了。
点评:使用Unsafe可以完全不care对象内的复杂构成,可以很精确的计算出对象头的大小(即第一个字段的偏移)及每个字段的偏移。缺点是Unsafe通常禁止开发者直接使用,需要通过反射获取其实例,另外,最后一个字段的大小需要手工计算。其次需要手工写代码递归计算才能得到对象及其所引用的对象的综合大小,相对比较麻烦。
3. 使用第三方工具
这里要介绍的是lucene提供的专门用于计算堆内存占用大小的工具类:RamUsageEstimator,maven坐标:
org.apache.lucene
lucene-core
4.0.0
RamUsageEstimator就是根据java对象在堆内存中的存储格式,通过计算Java对象头、实例数据、引用等的大小,相加而得,如果有引用,还能递归计算引用对象的大小。RamUsageEstimator的源码并不多,几百行,清晰可读。这里不进行一一解读了。它在初始化的时候会根据当前JVM运行环境、CPU架构、运行参数、是否开启指针压缩、JDK版本等综合计算对象头的大小,而实例数据部分则按照java基础数据类型的标准大小进行计算。思路简单,同时也在一定程度上反映出了Java对象格式的奥秘!
常用方法如下:
//计算指定对象及其引用树上的所有对象的综合大小,单位字节
long RamUsageEstimator.sizeOf(Object obj)
//计算指定对象本身在堆空间的大小,单位字节
long RamUsageEstimator.shallowSizeOf(Object obj)
//计算指定对象及其引用树上的所有对象的综合大小,返回可读的结果,如:2KB
String RamUsageEstimator.humanSizeOf(Object obj)点评:使用该第三方工具比较简单直接,主要依靠JVM本身环境、参数及CPU架构计算头信息,再依据数据类型的标准计算实例字段大小,计算速度很快,另外使用较方便。如果非要说这种方式有什么缺点的话,那就是这种方式计算所得的对象头大小是基于JVM声明规范的,并不是通过运行时内存地址计算而得,存在与实际大小不符的这种可能性。
Java对象格式
在HotSpot虚拟机中,Java对象的存储格式也是一个协议或者数据结构,底层是用C++代码定义的。Java对象结构大致如下图所示——
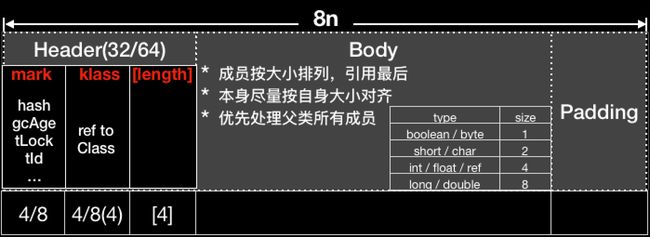
即,Java对象从整体上可以分为三个部分,对象头、实例数据和对齐填充
对象头:Instance Header,Java对象最复杂的一部分,采用C++定义了头的协议格式,存储了Java对象hash、GC年龄、锁标记、class指针、数组长度等信息,稍后做出详细解说。
实例数据:Instance Data,这部分数据才是真正具有业务意义的数据,实际上就是当前对象中的实例字段。在VM中,对象的字段是由基本数据类型和引用类型组成的。其所占用空间的大小如下所示:
| 类型 | 大小(字节) | 类型 | 大小(字节) | ||
| byte | 1 | int | 4 | ||
| boolean | 1 | float | 4 | ||
| char | 2 | long | 8 | ||
| short | 2 | double | 8 | ||
| ref | 4(32bit) OR 8(64bit) OR 4(64bit && -XX:UseCompressedOops) | ||||
说明:其中ref表示引用类型,引用类型实际上是一个地址指针,32bit机器上,占用4字节,64bit机器上,在jdk1.6之后,如果开启了指针压缩(默认开启: -XX:UseCompressedOops,仅支持64位机器),则占用4字节。Java对象的所有字段类型都可映射为上述类型之一,因此实例数据部分的大小,实际上就是这些字段类型的大小之和。当然,实际情况可能比这个稍微复杂一点,如字段排序、内部padding以及父类字段大小的计算等。
对齐填充:Padding,VM要求对象大小须是8的整体数,该部分是为了让整体对象在内存中的地址空间大小达到8的整数倍而额外占用的字节数。
对象头
对象头是理解JVM中对象存储方式的最核心的部分,甚至是理解java多线程、分代GC、锁等理论的基础,也是窥探JVM底层诸多实现细节的出发点。做为一个java程序猿,这是不可不了解的一部分。那么这里提到的对象头到底是什么呢?
参考OpenJDK中JVM源码部分,对对象头的C++定义如下:
class oopDesc {
friend class VMStructs;
private:
volatile markOop _mark;
union _metadata {
wideKlassOop _klass;
narrowOop _compressed_klass;
} _metadata;
...
} 源码里的 _mark 和 _metadata两个字段就是对象头的定义,分别表示对象头中的两个基本组成部分,_mark用于存储hash、gc年龄、锁标记、偏向锁、自旋时间等,而_metadata是个共用体(union),即_klass字段或_compressed_klass,存储当前对象到所在class的引用,而这个引用的要么由“_klass”来存储,要么由“_compressed_klass”来存储,其中_compressed_klass表示压缩的class指针,即当JVM开启了 -XX:UseCompressedOops选项时,就表示启用指针压缩选项,自然就使用_commpressed_klass来存储class引用了,否则使用_klass。
注意到,_mark的类型是 markOop,而_metadata的类型是union,_metadata内部两个字段:_klass和_compressed_klass类型分别为wideKlassOop和narrowOop,分别表示什么意思呢?这里顺便说一个union联合体的概念,这是在C++中的一种结构声明,类似struct,称作:“联合”,它是一种特殊的类,也是一种构造类型的数据结构。在一个“联合”内可以定义多种不同的数据类型, 一个被说明为该“联合”类型的变量中,允许装入该“联合”所定义的任何一种数据,这些数据共享同一段内存,已达到节省空间的目的。由此可见,刚刚所说的使用-XX:UseCompressedOops后,就自动使用_metadata中的_compressed_klass来作为指向当前对象的class引用,它的类型是narrowOop。可以看到,对象头中的两个字段的定义都包含了“Oop”字眼,不难猜出,这是一种在JVM层定义好的“类型”。
OOP-Klass模型
实际上,Java的面向对象在语言层是通过java的class定义实现的,而在JVM层,也有对应的实现,那就是Oop模型。所谓Oop模型,全称:Ordinary Object Pointer,即普通对象指针。JVM层用于定义Java对象模型及一些元数据格式的模型就是:Oop,可以认为是JVM层中的“类”。通过JDK源码可以看到,有很多模型定义的名称都是以Oop结尾:arrayOop/markOop/instanceOop/methodOop/objectArrayOop等,什么意思呢?
HotSpot是基于c++语言实现的,它最核心的地方是设计了两种模型,分别是OOP和Klass,称之为OOP-Klass Model. 其中OOP用来将指针对象化,比C++底层使用的"*"更好用,每一个类型的OOP都代表一个在JVM内部使用的特定对象的类型。而Klass则用来描述JVM层面中对象实例的具体类型,它是java实现语言层面类型的基础,或者说是对java语言层类型的VM层描述。所以看到openJDK源码中的定义基本都以Oop或Klass结尾,如图所示:
由上述定义可以简单的说,Oop就是JVM内部对象类型,而Klass就是java类在JVM中的映射。其中关于Oop和Klass体系,参考定义:https://github.com/openjdk-mirror/jdk7u-hotspot/blob/50bdefc3afe944ca74c3093e7448d6b889cd20d1/src/share/vm/oops/oop.hpp;JVM中把我们上层可见的Java对象在底层实际上表示为两部分,分别是oop和klass,其中oop专注于表示对象的实例数据,不关心对象中的实例方法(包括继承、重载等)所对应的函数表。而klass则维护对象到java class及函数表的功能,它是java class及实现多态的基础。这里列举几个基础的Oop和Klass——
Oop:
//定义了oops共同基类
typedef class oopDesc* oop;
//表示一个Java类型实例
typedef class instanceOopDesc* instanceOop;
//表示一个Java方法
typedef class methodOopDesc* methodOop;
//定义了数组OOPS的抽象基类
typedef class arrayOopDesc* arrayOop;
//表示持有一个OOPS数组
typedef class objArrayOopDesc* objArrayOop;
//表示容纳基本类型的数组
typedef class typeArrayOopDesc* typeArrayOop;
//表示在Class文件中描述的常量池
typedef class constantPoolOopDesc* constantPoolOop;
//常量池告诉缓存
typedef class constantPoolCacheOopDesc* constantPoolCacheOop;
//描述一个与Java类对等的C++类
typedef class klassOopDesc* klassOop;
//表示对象头
typedef class markOopDesc* markOop;Klass:
//klassOop的一部分,用来描述语言层的类型
class Klass;
//在虚拟机层面描述一个Java类
class instanceKlass;
//专有instantKlass,表示java.lang.Class的Klass
class instanceMirrorKlass;
//表示methodOop的Klass
class methodKlass;
//最为klass链的端点,klassKlass的Klass就是它自身
class klassKlass;
//表示array类型的抽象基类
class arrayKlass;
//表示constantPoolOop的Klass
class constantPoolKlass;结合上述JVM层与java语言层,java对象的表示关系如下所示:
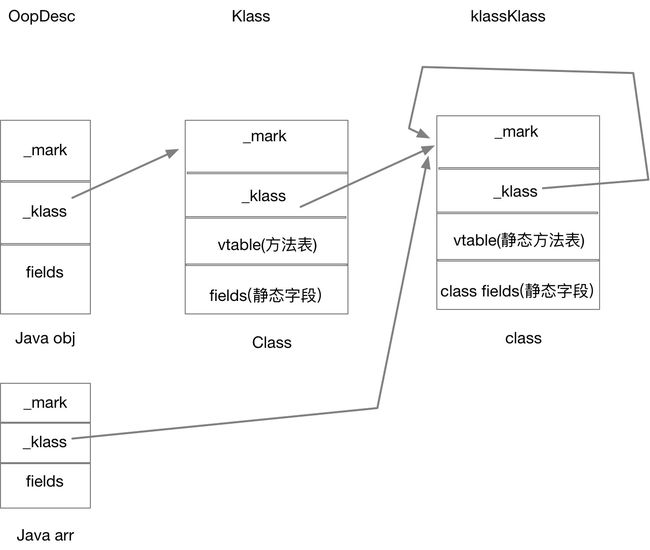
其中OopDesc是对象实例的基类(Java实例在VM中表现为instanceOopDesc),Klass是类信息的基类(Java类在VM中表现为instanceKlass),klassKlass则是对Klass本身的描述(Java类的class对象在VM中表现为klassKlass)。
有了对上述结构的认识,对应到内存中的存储区域,那么对象是怎么存储的,就了比较清楚的认识:对象实例(instanceOopDesc)保存在堆上,对象的元数据(instanceKlass)保存在方法区,对象的引用则保存在栈上。
因此,关于本小节,对OOP-Klass Model的讨论,可以用一句简洁明了的话来总结其意义:一个Java类在被VM加载时,JVM会为其在方法区创建一个instanceKlass,来表示该类的class信息。当我们在代码中基于此类用new创建一个新对象时,实际上JVM会去堆上创建一个instanceOopDesc对象,该对象保含对象头markWord和klass指针,klass指针指向方法区中的instanceKlass,markWord则保存一些锁、GC等相关的运行时数据。而在堆上创建的这个instanceOopDesc所对应的地址会被用来创建一个引用,赋给当前线程运行时栈上的一个变量。
关于Mark Word
mark word是对象头中较为神秘的一部分,也是本文讲述的重点,JDK oop.hpp源码文件中,有几行重要的注释,揭示了32位机器和64位机器下,对象头的格式:
// Bit-format of an object header (most significant first, big endian layout below):
//
// 32 bits:
// --------
// hash:25 ------------>| age:4 biased_lock:1 lock:2 (normal object)
// JavaThread*:23 epoch:2 age:4 biased_lock:1 lock:2 (biased object)
// size:32 ------------------------------------------>| (CMS free block)
// PromotedObject*:29 ---------->| promo_bits:3 ----->| (CMS promoted object)
//
// 64 bits:
// --------
// unused:25 hash:31 -->| unused:1 age:4 biased_lock:1 lock:2 (normal object)
// JavaThread*:54 epoch:2 unused:1 age:4 biased_lock:1 lock:2 (biased object)
// PromotedObject*:61 --------------------->| promo_bits:3 ----->| (CMS promoted object)
// size:64 ----------------------------------------------------->| (CMS free block)
//
// unused:25 hash:31 -->| cms_free:1 age:4 biased_lock:1 lock:2 (COOPs && normal object)
// JavaThread*:54 epoch:2 cms_free:1 age:4 biased_lock:1 lock:2 (COOPs && biased object)
// narrowOop:32 unused:24 cms_free:1 unused:4 promo_bits:3 ----->| (COOPs && CMS promoted object)
// unused:21 size:35 -->| cms_free:1 unused:7 ------------------>| (COOPs && CMS free block)在oop.hpp源码文件中,有对Oop基类中mark word结构的定义,如下:
class oopDesc {
friend class VMStructs;
private:
volatile markOop _mark;
union _metadata {
wideKlassOop _klass;
narrowOop _compressed_klass;
} _metadata;
...
}其中的mark word即上述 _mark字段,它在JVM中的表示类型是markOop, 部分关键源码如下所示,源码中展示了markWord各个字段的意义及占用大小(与机器字宽有关系),如GC分代年龄、锁状态标记、哈希码、epoch、是否可偏向等信息:
...
class markOopDesc: public oopDesc {
private:
// Conversion
uintptr_t value() const { return (uintptr_t) this; }
public:
// Constants
enum { age_bits = 4,
lock_bits = 2,
biased_lock_bits = 1,
max_hash_bits = BitsPerWord - age_bits - lock_bits - biased_lock_bits,
hash_bits = max_hash_bits > 31 ? 31 : max_hash_bits,
cms_bits = LP64_ONLY(1) NOT_LP64(0),
epoch_bits = 2
};
// The biased locking code currently requires that the age bits be
// contiguous to the lock bits.
enum { lock_shift = 0,
biased_lock_shift = lock_bits,
age_shift = lock_bits + biased_lock_bits,
cms_shift = age_shift + age_bits,
hash_shift = cms_shift + cms_bits,
epoch_shift = hash_shift
};
...因为对象头信息只是对象运行时自身的一部分数据,相比实例数据部分,头部分属于与业务无关的额外存储成功。为了提高对象对堆空间的复用效率,Mark Word被设计成一个非固定的数据结构以便在极小的空间内存储尽量多的信息,它会根据对象的状态复用自己的存储空间。
对于上述源码,mark word中字段枚举意义解释如下:
hash: 保存对象的哈希码
age: 保存对象的分代年龄
biased_lock: 偏向锁标识位
lock: 锁状态标识位
JavaThread*: 保存持有偏向锁的线程ID
epoch: 保存偏向时间戳
锁标记枚举的意义解释如下:
locked_value = 0,//00 轻量级锁 unlocked_value = 1,//01 无锁 monitor_value = 2,//10 监视器锁,也叫膨胀锁,也叫重量级锁 marked_value = 3,//11 GC标记 biased_lock_pattern = 5 //101 偏向锁
实际上,markword的设计非常像网络协议报文头:将mark word划分为多个比特位区间,并在不同的对象状态下赋予不同的含义, 下图是来自网络上的一张协议图。

上述协议字段正对应着源码中所列的枚举字段,这里简要进行说明一下。
hash
对象的hash码,hash代表的并不一定是对象的(虚拟)内存地址,但依赖于内存地址,具体取决于运行时库和JVM的具体实现,底层由C++实现,实现细节参考OpenJDK源码。但可以简单的理解为对象的内存地址的整型值。
age
对象分代GC的年龄。分代GC的年龄是指Java对象在分代垃圾回收模型下(现在JVM实现基本都使用的这种模型),对象上标记的分代年龄,当该年轻代内存区域空间满后,或者到达GC最达年龄时,会被扔进老年代等待老年代区域满后被FullGC收集掉,这里的最大年龄是通过JVM参数设定的:-XX:MaxTenuringThreshold ,默认值是15。那这个年龄具体是怎么计算的呢?
下图展示了该年龄递增的过程:
1. 首先,在对象被new出来后,放在Eden区,年龄都是0
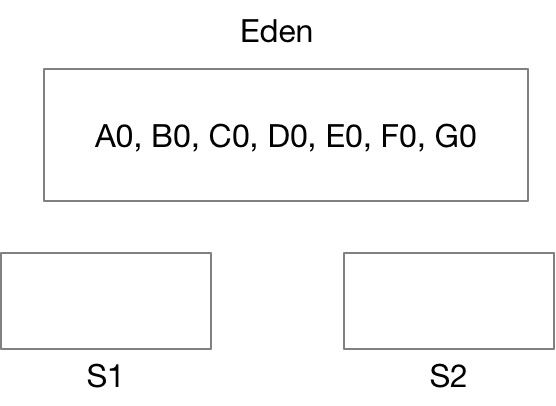
2. 经过一轮GC后,B0和F0被回收,其它对象被拷贝到S1区,年龄增加1,注:如果S1不能同时容纳A0,C0,D0,E0和G0,将被直接丢入Old区
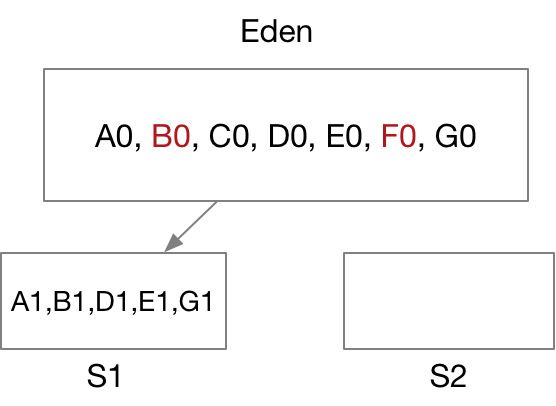
3. 再经一轮GC,Eden区中新生的对象M0,P0及S1中的B1,E1,G1不被引用将被回收,而H0,K0,N0及S1中的A1,D1被拷贝到S2区中,对应年龄增加1
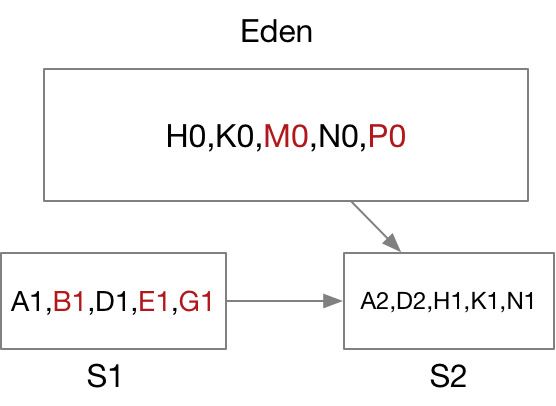
4. 如此经过2、3过滤循环进行,当S1或S2满,或者对象的年龄达到最大年龄(15)后仍然有引用存在,则对象将被转移至Old区。
锁标记:lock/biased_lock/epoch/JavaThread*
锁标记位,此锁为重量级锁,即对象监视器锁。Java在使用synchronized关键字对方法或块进行加锁时,会触发一个名为“objectMonitor”的监视器对目标代码块执行加锁的操作。当然synchronized方法和synchronized代码块的底层处理机制稍有不同。synchronized方法编译后,会被打上“ACC_SYNCHRONIZED”标记符。而synchronized代码块编译之后,会在同步代码的前后分别加上“monitorenter”和“monitorexit”的指令。当程序执行时遇到到monitorenter或ACC_SYNCHRONIZED时,会检测对象头上的lock标记位,该标记位被如果被线程初次成功访问并设值,则置为1,表示取锁成功,如果再次取锁再执行++操作。在代码块执行结束等待返回或遇到异常等待抛出时,会执行monitorexit或相应的放锁操作,锁标记位执行--操作,如果减到0,则锁被完全释放掉。关于objectMonitor的实现细节,参考JDK源码
注意,在jdk1.6之前,synchronized加锁或取锁等待操作最终会被转换为操作系统中线程操作原语,如激活、阻塞等。这些操作会导致CPU线程上下文的切换,开销较大,因此称之为重量级锁。但后续JDK版本中对其实现做了大幅优化,相继出现了轻量级锁,偏向锁,自旋锁,自适应自旋锁,锁粗化及锁消除等策略。这里仅做简单介绍,不进行展开。
如图所示,展示了这几种锁的关系:
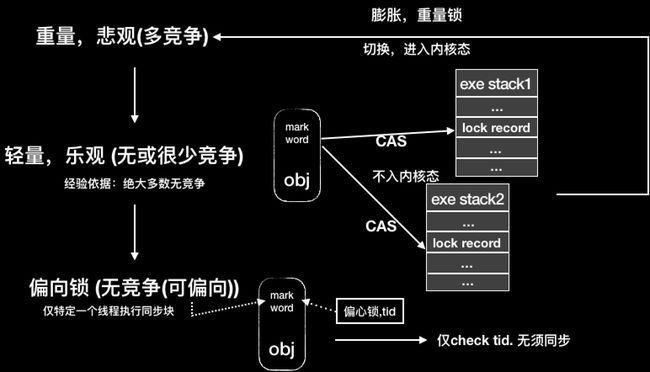
轻量级锁,如上图所示,是当某个资源在没有竞争或极少竞争的情况下,JVM会优先使用CAS操作,让线程在用户态去尝试修改对象头上的锁标记位,从而避免进入内核态。这里CAS尝试修改锁标记是指尝试对指向当前栈中保存的lock record的线程指针的修改,即对biased_lock标记做CAS修改操作。如果发现存在多个线程竞争(表现为CAS多次失败),则膨胀为重量级锁,修改对应的lock标记位并进入内核态执行锁操作。注意,这种膨胀并非属于性能的恶化,相反,如果竞争较多时,CAS方式的弊端就很明显,因为它会占用较长的CPU时间做无谓的操作。此时重量级锁的优势更明显。
偏向锁,是针对只会有一个线程执行同步代码块时的优化,如果一个同步块只会被一个线程访问,则偏向锁标记会记录该线程id,当该线程进入时,只用check 线程id是否一致,而无须进行同步。锁偏向后,会依据epoch(偏向时间戳)及设定的最大epoch判断是否撤销锁偏向。
自旋锁大意是指线程不进入阻塞等待,而只是做自旋等待前一个线程释放锁。不在对象头讨论范围之列,这里不做讨论。
实例数据
实例数据instance Data是占用堆内存的主要部分,它们都是对象的实例字段。那么计算这些字段的大小,主要思路就是根据这些字段的类型大小进行求和的。字段类型的标准大小,如Java对象格式概述中表格描述的,除了引用类型会受CPU架构及是否开启指针压缩影响外,其它都是固定的。因此计算起来比较简单。但实际情其实并不这么简单,例如如下对象:
class People{
int age = 20;
String name = "Xiaoming";
}
class Person extends People{
boolean married = false;
long birthday = 128902093242L;
char tag = 'c';
double sallary = 1200.00d;
}Person对象实例数据的大小应该是多少呢?这里假设使用64位机器,采用指针压缩,则对象头的大小为:8(_mark)+4(_klass) = 12
然后实例数据的大小为: 4(age)+4(name) + 8(birthday) + 8(sallary) + 2(tag) + 1(married) = 27
因此最终的对象本身大小为:12+27+1(padding) = 40字节
注意,为了尽量减少内存空间的占用,这里在计算的过程中需要遵循以下几个规则:
/**
* 1: 除了对象整体需要按8字节对齐外,每个成员变量都尽量使本身的大小在内存中尽量对齐。比如 int 按 4 位对齐,long 按 8 位对齐。
* 2:类属性按照如下优先级进行排列:长整型和双精度类型;整型和浮点型;字符和短整型;字节类型和布尔类型,最后是引用类型。这些属性都按照各自的单位对齐。
* 3:优先按照规则一和二处理父类中的成员,接着才是子类的成员。
* 4:当父类中最后一个成员和子类第一个成员的间隔如果不够4个字节的话,就必须扩展到4个字节的基本单位。
* 5:如果子类第一个成员是一个双精度或者长整型,并且父类并没有用完8个字节,JVM会破坏规则2,按照整形(int),短整型(short),字节型(byte),引用类型(reference)的顺序,向未填满的空间填充。
*/
最后计算引用类型字段的实际大小:"Xiaoming",按字符串对象的字段进行计算,对象头12字节,hash字段4字节,char[] 4字节,共12+4+4+4(padding) = 24字节,其中char[]又是引用类型,且是数组类型,其大小为:对象头12+4(length) + 9(arrLength) * 2(char) +4(padding) = 40字节。
所以综上所述,一个Person对象占用内存的大小为104字节。
关于指针压缩
一个比较明显的问题是,在64位机器上,如果开启了指针压缩后,则引用只占用4个字节,4字节的最大寻址空间为2^32=4GB, 那么如何保证能满足寻址空间大于4G的需求呢?
开启指针压缩后,实际上会压缩的对象包括:每个Class的属性指针(静态成员变量)及每个引用类型的字段(包括数组)指针,而本地变量,堆栈元素,入参,返回值,NULL这些指针不会被压缩。在开启指针压缩后,如前文源码所述,markWord中的存储指针将是_compressed_klass,对应的类型是narrowOop,不再是wideKlassOop了,有什么区别呢?
wideKlassOop和narrowOop都指向InstanceKlass对象,其中narrowOop指向的是经过压缩的对象。简单来说,wideKlassOop可以达到整个寻址空间。而narrowOop虽然达不到整个寻址空间,但它面对也不再是个单纯的byte地址,而是一个object,也就是说使用narrowOop后,压缩后的这4个字节表示的4GB实际上是4G个对象的指针,大概是32GB。JVM会对对应的指针对象进行解码, JDK源码中,oop.hpp源码文件中定义了抽象的编解码方法,用于将narrowOop解码为一个正常的引用指针,或将一下正常的引用指针编码为narrowOop:
// Decode an oop pointer from a narrowOop if compressed.
// These are overloaded for oop and narrowOop as are the other functions
// below so that they can be called in template functions.
static oop decode_heap_oop_not_null(oop v);
static oop decode_heap_oop_not_null(narrowOop v);
static oop decode_heap_oop(oop v);
static oop decode_heap_oop(narrowOop v);
// Encode an oop pointer to a narrow oop. The or_null versions accept
// null oop pointer, others do not in order to eliminate the
// null checking branches.
static narrowOop encode_heap_oop_not_null(oop v);
static narrowOop encode_heap_oop(oop v);对齐填充
对齐填充是底层CPU数据总线读取内存数据时的要求,例如,通常CPU按照字单位读取,如果一个完整的数据体不需要对齐,那么在内存中存储时,其地址有极大可能横跨两个字,例如某数据块地址未对齐,存储为1-4,而cpu按字读取,需要把0-3字块读取出来,再把4-7字块读出来,最后合并舍弃掉多余的部分。这种操作会很多很多,且很频繁,但如果进行了对齐,则一次性即可取出目标数据,将会大大节省CPU资源。
在hotSpot虚拟机中,默认的对齐位数是8,与CPU架构无关,如下代码中的objectAlignment:
// Try to get the object alignment (the default seems to be 8 on Hotspot,
// regardless of the architecture).
int objectAlignment = 8;
try {
final Class beanClazz = Class.forName("com.sun.management.HotSpotDiagnosticMXBean");
final Object hotSpotBean = ManagementFactory.newPlatformMXBeanProxy(
ManagementFactory.getPlatformMBeanServer(),
"com.sun.management:type=HotSpotDiagnostic",
beanClazz
);
final Method getVMOptionMethod = beanClazz.getMethod("getVMOption", String.class);
final Object vmOption = getVMOptionMethod.invoke(hotSpotBean, "ObjectAlignmentInBytes");
objectAlignment = Integer.parseInt(
vmOption.getClass().getMethod("getValue").invoke(vmOption).toString()
);
supportedFeatures.add(JvmFeature.OBJECT_ALIGNMENT);
} catch (Exception e) {
// Ignore.
}
NUM_BYTES_OBJECT_ALIGNMENT = objectAlignment; 可以看出,通过HotSpotDiagnosticMXBean.getVMOption("ObjectAlignmentBytes").getValue()方法可以拿到当前JVM环境下的对齐位数。
注意,这里的HotSpotDiagnosticMXBean是JVM提供的JMX中一种可被管理的资源,即HotSpot信息资源。
使用SA Hotspot Debuger(HSDB)查看oops结构
前文所述都是源码+理论,其实Hotspot为我们提供了一种工具可以方便的用来查询运行时对象的Oops结构,即SA Hotspot Debuger,简称HSDB. 其中SA指“Serviceability Agent”,它是一个JVM服务工具集的Agent,它原本是sun公司用来debug Hotspot的工具,现在开放给开发者使用,能够查看Java对象的oops、查看类信息、线程栈信息、堆信息、方法字节码和JIT编译后的汇编代码等。SA提供的入口在$JAVA_HOME/lib/sa-jdi.jar中,包含了很多工具,其中最常用的工具就是HSDB。
下面演示一下HSDB的使用——
1. 先准备如下代码并运行:
public class Obj{
private int age;
private long height;
private boolean married;
private String name;
private String addr;
private String sex;
...
get/set
}package yp.tools;
/**
* @author yepei
* @date 2018/05/14
* @description
*/
public class HSDBTest {
public static void main(String[] args) throws InterruptedException {
Obj o = new Obj(20, 175, false, "小明", "浙江杭洲", "男");
Thread.sleep(1000 * 3600);
System.out.println(o);
}
}
2. 执行jps命令,获取当前运行的Java进程号:
3. 启动HSDB,并添加目标进程:
sudo java -cp $JAVA_HOME/lib/sa-jdi.jar sun.jvm.hotspot.HSDB
可以看到当前Java进程中的线程信息:
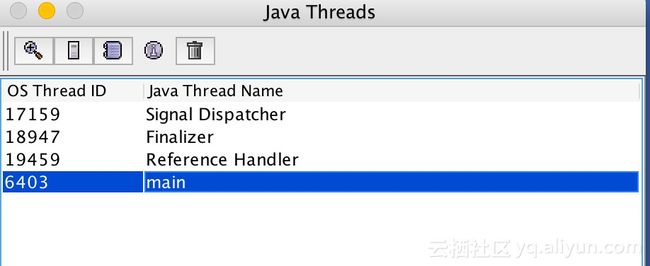
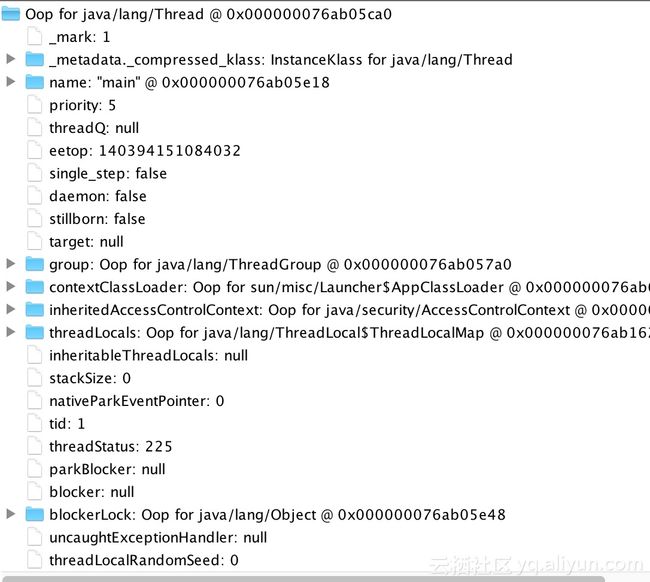
双击指定线程,可以查看到当前线程对象的Oop结构信息,可以看到线程对象头也是包含_mark和_metadata两个协议字段的:
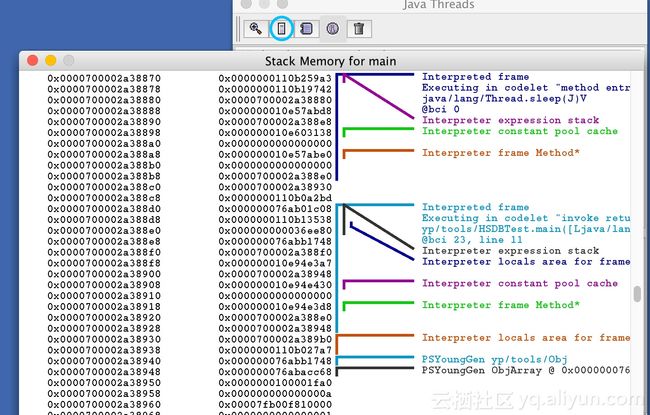
点击上方的栈图标,可以查询当前线程的栈内存:
那么如何查看当前线程中用户定义的类结存储信息呢?
先到方法区去看一下类信息吧
Tools——Class Browser,搜索目标类

可以看到该类对应的对象的各个字段的偏移量,最大的是36,String类型,意味着该对象本身的大小就是36+4 = 40字节。同时,下方可以看到这个类相关的函数表、常量池信息。
要查看对象信息,从Tools菜单,打开Object Histogram
在打开的窗口中搜索目标类:yp.tools.Obj
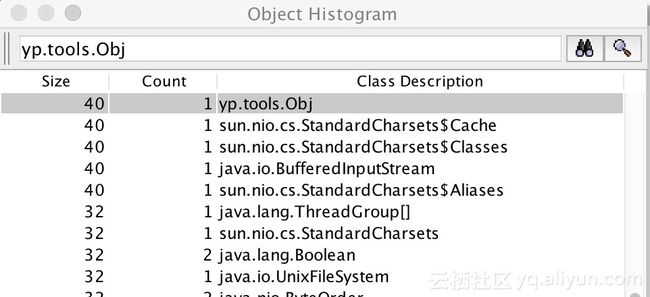
双击打开:
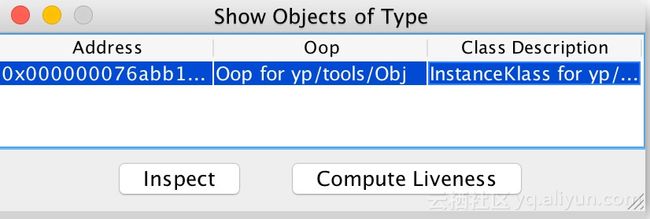
点击Inspect查看该对象的Oop结构信息:
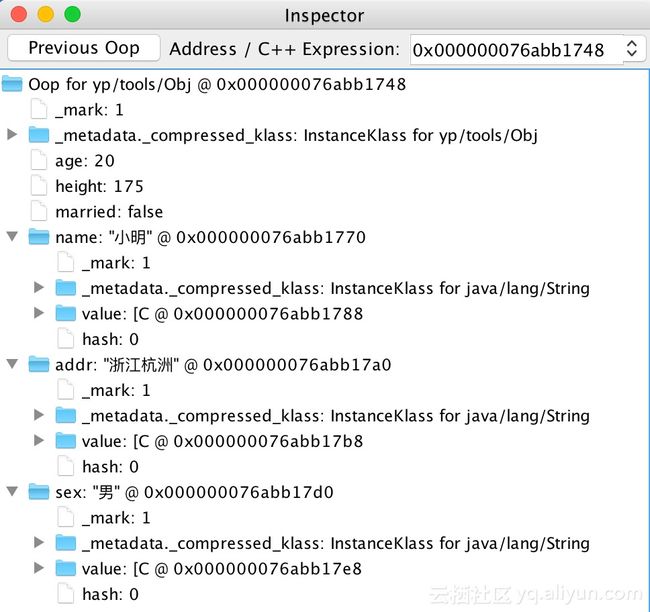
如上图所示即是对象Obj的Oop结构,对象头包含_mark与代表class指针的_metadata。示例中的类没有并发或锁的存在,所以mark值是001,代表无锁状态。
除此之外,HSDB还有其它一些不错的功能,如查看反编译信息、根据地址查找对象、crash分析、死锁分析等。
总结
本文围绕“计算Java对象占用内存大小”这一话题,简要介绍了直接计算指定对象在内存中大小的三种方法:使用Instrumentation、Unsafe或第三方工具(RamUsageEstimator)的方式,其中Instrumentation和Unsafe计算精确,但使用起来不太方便,Instrumentation需要以javaagent代理的方式启动,而Unsafe只能计算指定对象的每个字段的地址起始位置偏移量,需要手工递归并增加padding才能完整计算对象大小,使用RamUsageEstimator可以很方便的计算对象本身或对象引用树整体的大小,但其并非直接基于对象的真实内存地址而计算的,而是通过已知JVM规则和数据类型的标准大小推算的,存在计算误差的可能性。
为了揭开Java对象在堆内存中存储格式的面纱,结合OpenJDK源码,本文着重讨论了Java对象的格式:对象头、实例数据及对齐填充三部分。其中对象头最为复杂,包含_mark、_klass以及_length(仅数组类型)的协议字段。其中的mark word字段较为复杂,甚至涉及了OOP-Klass模型、hash、gc、锁的原理及指针压缩等知识。
最后,从实践的方面入手,介绍了JDK自带的Hotspot Debuger工具——HSDB的使用,透过它能够让我们更直观的查看运行中的java对象在内存中的存在形式和状态,如对象的oops、类信息、线程栈信息、堆信息、方法字节码和JIT编译后的汇编代码等。
本文查询了一些资料,并参考了OpenJDK源码。可能会有些不正确的地方敬请指正,欢迎探讨。
参考资料
- OpenJDK源码
- Hotspot虚拟机对象探秘
- 《深入理解Java虚拟机》第2版,周志明,机械工业出版社
-
Java ServiceabilityAgent(HSDB)使用和分析