微服务架构上云最佳实践
摘要:7月27日,云栖社区、阿里中间件举办了首届阿里巴巴中间件技术峰会,揭秘阿里10年分布式技术干货。在首届阿里巴巴中间件技术峰会上,具有10年研发经验的阿里巴巴中间件技术专家李颜良结合EDAS团队上云两年多以来积累的经验为大家分享了如何进行微服务拆分、微服务架构上云最佳实践以及微服务架构常用的模式,精彩不容错过。
以下内容根据演讲嘉宾现场视频以及PPT整理而成。
本次分享主要围绕以下三个方面:
首先从真实的案例开始讲起,当一些客户接触到了一些微服务之后,他们就会将原本经典的分层架构模式拆分成为微服务。如下图所示,客户原本的架构是比较经典的分层架构模型,可以看到每一层的结构都非常清晰,当此时想要做微服务拆分的时候第一步就是将DAO层直接拆分出来。而大家都知道,这样做肯定会有一些不妥之处,那么不妥之处到底在哪里呢?在这里就埋下一个疑问,大家可以先思考一下对于这样的经典的分层架构究竟应该如何去进行拆分。

微服务的拆分其实要先从DDD开始说起,那么什么是DDD呢?DDD其实是一种软件设计的指导思想,它可以指导我们设计一些高质量的软件架构,DDD的核心是想让技术人员和业务人员使用一种共同的语言并且都把关注点聚焦在业务层面,在这样情况下去讨论、发现和实现业务的价值。DDD中有一些核心的概念,首先其中有“领域”的概念,所谓“领域”这个概念的意思就是团队所关注的业务。在领域中我们会提炼出一些模型,而这些模型有的是需要口口相传的;也有的是需要我们写在开发文档上面,便于新进入团队的同学学习开发的;还有的是需要直接写在给客户看的文档上面供客户去理解的;等等这些我们称之为为领域模型。在领域模型确定之后,就需要有一个称之为“通用语言”的东西,这个通用语言就是用于大家进行交流的。大家可能会觉得这个是非常自然的事情,但是事实上并不是这样的,这里举一个例子给大家解释一下,比如两个程序员之间进行沟通时,描述转账这个场景可能是这样的:定义一个变量transformMoney接收这个钱这个值,从第一个账户上面把这个钱减掉然后加到另一个账户上面去,然后使用DAO进行Save操作就可以了,这是程序员之间很自然的沟通语言。但是如果这个时候有业务人员进来了之后,他可能并不理解这样的描述,业务人员的描述可能是这样的:转账的这笔钱可能会需要分为系统内部转账和系统外部转账,根据转账金额的大小可能会采用不同的审计策略,根据这些策略每一笔资金可能使不同的系统感知到不同的事件,而且这些路径可能需要做沉淀和记录,可能会有交易的记录产生等等,这样描述出来可能技术人员也能够听懂,业务人员也能可以听懂。

这是什么意思呢?其实大家可以仔细想想,上面的这段对话其实是可以直接翻译成为代码的,这就是所谓的通用语言。但是通用语言的产生过程也是不断地提升的过程,就像代码需要不断地进行重构和完善。而上面这段对话其实需要在一定的边界之内才会有意义,而边界又是什么意思呢?还是使用刚才转账的例子,转账时使用的账户和登录时使用的账户虽然都叫做账户,但是肯定不是同一个东西,这时候就产生了限界,也就是BoundedContext这个概念。
在介绍完这些基本概念之后,我们继续分享DDD的战略和战术。从一个比较标准的解释来说,战略就是用于指导军队去打赢某场战争的思想,也就是一种方法和谋略。而DDD的战略当然不是用于打仗的,而是用于拆分领域等其他方面的。当然DDD的战略和战争的战略有一定相同之处,比方在打仗的时候需要选好一块什么样的地盘,以及在上面用什么样子的方式如何发动这场战争,而这块地盘在微服务拆分上就是可以理解成选择一个什么样子的领域,这个领域可以分为核心域和子域。对于核心域而言,从我们的业务就能显而易见地看出来它是区别于其他业务的一块领域,也就是核心业务。如果这块领域不复存在的话,那么整个团队或者公司就会出现问题。在核心域周围则会存在支撑子域,比如对于电商业务而言,交易就是核心,核心域的旁边则会有支撑核心域来区分业务的子域,比如图中的物流和支付,这两部分的支撑子域也是整个业务独有的。当然也会有其他的部分,比如通用子域,这部分就是其他公司可能会有或者其他业务也会存在的领域,这部分的业务逻辑可能可以直接从某些开源软件或者商业软件拿过来使用,比如像每个公司都会使用的会员系统以及积分系统等。除此之外还有一些基础的技术服务,比如像短信服务这样的技术服务。
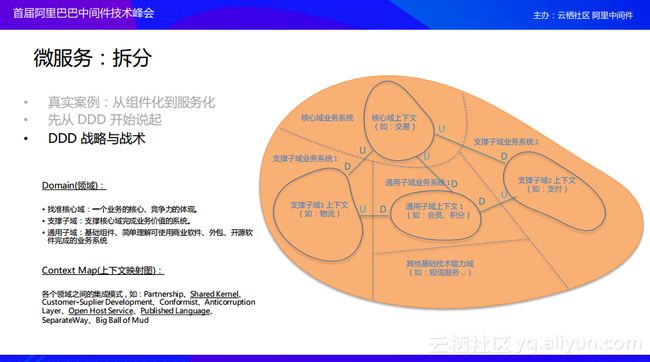
当上面这样整个图构建完成之后,我们会发现每一块领域之间,每一块上下文之间都是存在一定的关系的。这些关系可能是比较简单的上下游的关系,除此之外,还可能存在客户关系或者供应商关系,或者是共享同一块内核、模型这样的关系,比方说前台系统和后台系统往往会共享同一种数据模型,还可能存在两个领域之间需要做很多的适配器等等,这些在DDD中也会有一些推荐架构模式去遵循。

除了上述在架构模式上面的东西以外,在一个领域内部还会有一些战术上的模式让我们定义一些东西。还是使用刚刚那么转账的例子来分析,每一个账户以及每一笔交易的记录都是需要进行唯一性区分的,这些需要进行唯一性区分存储的东西可以我们叫做实体,还有说转账的时候的那笔钱其实也会是一个对象,因为它可能存在汇率不同、币种等信息,它也是以一个对象存在的,但是可能这个对象是不变的,因为我的三块钱和你的三块钱是一样的,我们将这样的对象称为值对象。在做转账的时候,这个转账的过程可能会与某些交易机构或者其他的实体之间发生关系,所以需要内聚更加合理的地方,这个时候就出现了领域服务。然后回到刚才提到的需求之一就是每一笔钱都需要能够被感知到,要能够感知到就需要能够产生或处理一些事件,这样就会有一些领域事件出来。还有就是人与账户是什么关系呢?想要拿到账户去做转账之前首先需要先找到人,此时这个人就会与账户出现一种聚合的关系,既然有了这样聚合的关系;然后发现人对账户开通的过程,并不是简单的new可以实现的,因为可能会需要绑定很多东西,开通很多东西,所以这时候很可能需要工厂来帮你的忙。同样的道理,当你去做资源池的交互的时候,可能DAO帮不了你,因为DAO仅仅是对于DB的各种动作的转义,它其实是没有领域含义的,所以这时候就会需要资源库。
聊完了DDD这部分之后,我们再来看一下它和我们今天提到的微服务的拆分到底存在什么样的关系。对于服务拆分而言,首先可以看到刚才分享的根据公司内部的核心域或者业务内部的核心域或者业务能力,拆分其实很简单,首先就是“一纵”,纵向拆分就像阿里巴巴这样将业务拆分成为淘宝、天猫、聚划算以及咸鱼等。然后再是“一横”,横指的就是拆分成刚才介绍的那些领域,包括核心域、支撑子域以及通用子域等。然后再找一些东西,也就是找其他的一些基础的通用子域、一些基础的能力域等。

当我们已经将服务拆分好了,那么是不是这时候就可以真正地开始实现功能了呢?其实在真正开始做之前还需要好好思考一些问题,因为微服务没有银弹。首先第一个需要考虑的问题就是我们的服务的内聚和耦合是不是真的合理,因为内聚和耦合难以量化,所以这里所强调的是合理。还有就是团队的构成,因为微服务产生的目的就是为了减少团队成员之间的沟通,那么团队构成是什么意思呢?首先第一个要点就是团队本身是需要全栈的,即自主性一定要很高。那么团队规模究竟应该多大呢?有一个参考的方法,就是“Two PizzaTeam”,也就是正好吃完两个披萨的团队。第二点的一个关键问题就是问自己准备好组织架构的变化了吗?这样的说法来自于康威定律,这个定律说的核心思想可以理解为:一个公司的技术架构可能最终会发展成为公司的组织架构的样子,当然组织架构也有可能发展成为技术架构的样子。第三点就是微服务在未来肯定会面临更多的挑战,到底是哪些挑战呢?在后续会为大家揭晓。
二、服务化案例分享与最佳实践
接下来为大家分享一些实际的案例,这些案例是提取自EDAS上云两年多以来在客户的环境中存在的实际问题。在正式介绍案例之前需要首先介绍几个简单的名词:
下图是HSF服务的简单介绍。首先第一个要分享的案例就是开发的时候遇到的问题,在分享这个案例之前首先简单地介绍一下HSF。HSF有一个注册中心,这个注册中心用来管理发布和订阅服务。当一个生产者启动起来之后可能会对于自己的服务进行发布,注册中心监听了这个服务就会发送给正在监听的消费者,然后消费者拿到地址之后就可以直接进行RPC的调用了。

那么如何使用HSF服务呢,在开始一个RPC的使用之前肯定会需要定义一个服务,而定义这个服务是通过一个接口的方式进行的。消费端可以直接使用这个接口在Spring容器的XML里面声明这是一个消费端,而生产者除了需要实现这个接口之外,也是需要向容器做声明,表示自己是一个生产者。

当将服务部署完成之后,就可以实现RPC真正的调用了;下图是一个客户真实的案例,案例中的请求会牵涉到一个非常重的Task,客户的想法是希望服务端做完这个 Task 之后异步地通知给进程。如果在单进程层面下这样写代码一点问题都没有,甚至可以说是很优雅,但是在分布式环境下这样写却是存在问题的,因为callback是回不来的,所以说我们写代码的思维方式需要发生一定的转变。

那么除了这样思维方式的变化还需要有什么东西呢?在下图中就为大家列举了开发过程中的最佳实践,这些最佳实践有些是参考的集团规约、有一部分是自己从客户的案例中整理的,没有高深的技术,我理解起来完全是平时的一些小的点,大的点我不讲、道行不深也讲不出什么感觉、而且大的点肯定是有一帮人和帮你一起考虑的,反倒是一些小的点是我们容易忽略的,因为只有你一个人在思考,很容易因为偷懒或者着急上个厕所就忘了。小反而是一门更大的学问。这些小点就小到一行日志、一个参数的校验、一个返回值、一个命名等等。具体不多说,可以自己参考。

服务化:部署篇
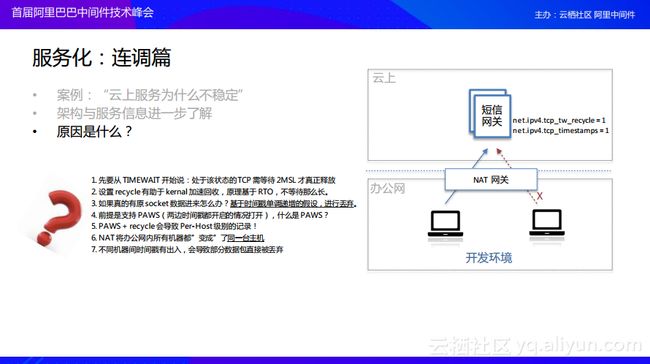
分享完了开发,接下来为大家分享关于部署的问题。曾经有客户提出了一个工单,就是服务都能够看到,但是还是会出现时好时坏的情况。我们仔细地审视了客户部署的架构,发现客户的架构是这样的:他们使用了两个VPC,这两个VPC之间有生产者和消费者,还有一个在另外一个VPC中,这时候就会发现我们所看到的部署架构肯定是调用不通的,因为他们的网络本身就是不通的。

这里为大家简单地介绍一下VPC。VPC其实是为了隔离用户网络环境而生的网络产品,可以简单地理解成为服务放入到VPC中去会更加安全。大家可能会想如果只是划分网络的话,通过路由器或者交换机这些也能够做到,那么为什么要使用VPC呢?其实VPC除了划分网络的基础功能之外,其实还可以实现跨可用区,可以实现同城容灾,另外VPC中还有一些比较基础的网络产品,比方说可以使用SNAT/DNAT做源地址和目的地址的转换,甚至可以做VPC内的统一的安全组管理等等。在什么样的场景下面会使用到VPC呢?关于这一点在阿里云官网上面有详细的介绍,在这里就不再赘述,大概就是做混合云架构或者有NAT需求的时候就可以使用。

接下来介绍HSF路由,刚才提到当消费者启动的时候就会去做监听,生产者启动的时候就会去做发布,当发布的时候注册中心知道这个地址之后就会推送给消费者,这就是一次简单的服务发现过程。那么第一次选择连接的时候,假设地址列表中有两个,一个好的一个坏的,这时候应该怎么样呢?首先第一次Round Robin选择连一个,与此同时启动心跳进程,进行心跳检测,如果此时发现地址有问题就会把这个地址放在一个不可用连接地址的列表中,但是心跳还会继续,当第二次再进行连接的时候过程与上述大致相同,但是不会再去启动一个心跳进程了。

在EDAS中的运维层面可能有一些点需要列出来给用户看的,因为经常会有用户遇到这些问题。在这里想要强调的点是 iptables ,很多用户非常喜欢设置iptables,但是却不建议大家去设置 iptables,首先它的学习成本比较高,其次它真的非常不好进行维护和管理以及知识的传递,而且几乎不可能去实现批量的运维和管理。除此之外,在 iptables 中用到的那些功能基本上可以在云上面使用VPC + NAT的方式进行处理,除非需要有一些非常高级的特性,比如需要根据数据包中的字符串进行过滤等这样的需求。

服务化:连调篇

回到我们当前的这个案例,当两台机器通过 NAT 网关进行访问的时候,服务器端看到的是一个 Host,当有时间不一致的时候,根据我们刚刚说的这些论断,有些数据包就自然被 drop 掉了,这个问题我们也引申出来了一些建议的做法。首先无论什么样的环境,服务器上的时间戳一定要 check 是不是一致,尤其是有 https 和 openapi 调用的场景。还有生产环境我们不怎么推荐使用 recycle 的,建议设置合理的 timewait buckets 代替。同时尽量避免在生产环境使用 NAT,最好走 SLB 的转发。
服务化:压测
接下来分享一下关于压测的内容,这里讲的压测可能会与大家通常理解的场景不太一样,因为是客户在做压测的时候拿着我们的RPC框架和另外一个目前比较流行的Restful的框架进行对比,给回来的反馈是性能不行。在接到这样的反馈之后,我们大概看了一下客户的代码是什么样子,客户的代码大概是将一个对象使用JSON序列化之后做RPC,RPC回来之后也是一个String,之后再将这个String反序列化成为一个对象返回给客户端,也就是客户在代码中做了两次JSON的序列化。在HSF中大家都知道它是字节支持序列化的,这里的两次序列化是浪费的;这种写法很普遍,希望大家注意。

还有一种典型的问题就是将一个Request直接转发出去,这种方式我们知道也是不行的。在HSF中支持的方式是Java的Native以及Hessian等,目前在序列化方面其实是不需要关注太多的性能的,整个框架对于性能而言已经优化的足够好了,除此之外在做序列化的时候这里也列出了一些大家比较容易遗漏的点,这些点就包括了为什么 HTTP 对象不行,因为它其实一个不可序列化的对象。总结而言,就是在每一次序列化之前要好好思考一下这个对象是不是可以序列化的;其次在序列化之前还需要好好想想序列化之后的字节大小为多少,是不是一个很大的对象。还有就是需要对于一些特殊的场景多留一些心眼,比如说枚举、单例和一些范型等。

服务化:上线运行
下图的这个案例就是HSF的线程池满了,这个问题我相信很多同学都已经遇到过,针对于这个问题这里首先列出了一个大概的时序图,也就是可能在自己的业务中需要依赖于外部服务,可能就会影响到内部的情况。

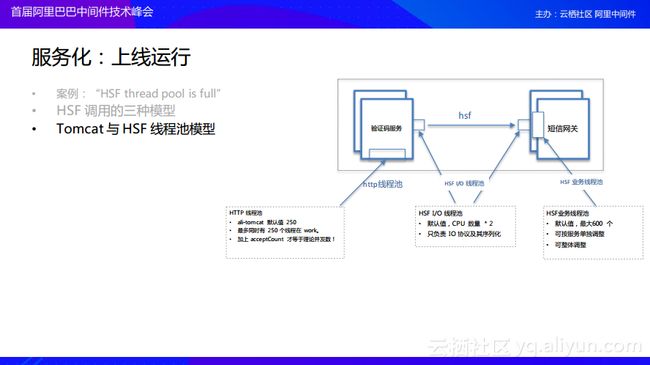
当客户与我们沟通的时候我们首先解释了为什么连接池会满,首先简单介绍一下HSF三种调用模型,第一种就是很自然的同步调用模式,就是一个一个地来,调用完成之后再回去;第二种情况就是异步调用,就是调用外部服务的请求不在乎调用的请求什么时候返回,调用之后就继续做自己的事情,对下图中的实例而言,我在发送验证码的之后就可以继续执行后续的步骤,这样的好处就是用户的体验将会得到提升,但是这种方式会带来一些业务的损耗,如果短信真的发送失败了则可能无法感知,系统认为用户拿到验证码了,但是事实上并没有;所以比较推荐的是第三种方式——Future的方式,这种方式还是基于异步的,Future是什么意思呢?其实是可以进程可以先去干自己的活,如果想要结果可以来拿,当自己的任务完成再回头取得异步调用结果的时候可能结果也就回来了,如果此时结果还没有返回回来,那么在这里等待也不会影响太大的事情。

在介绍完这三种HSF的调用模型之后,还需要介绍一些线程池的模型,毕竟这个案例是与线程池相关的。其实HSF中有三种线程池,第一个就是IO线程,但是这个线程池中线程比较少,因为其所做的工作也很少,基本上就做两件事情:序列化和处理协议;第二个线程池就是和我们这个案例息息相关的,在Server端会有一个很大的线程池,这个线程池默认的最大值可以达到600,当谈到HSF的线程池满了也就是说这个地方满了。还有一个地方是大家比较容易忽略的,就是在Tomcat的入口其实也有一个线程池,这个线程池其实决定了服务的并发数,但是这个并发数并不是单单由这个线程池决定的,理论上还需要加上另外一个字段Accept Count。
当我们向客户介绍完了以上两种的内部实现的时候,就开始进行优化了,优化的过程也是根据刚才的思路进行的,第一种方式主要是将调用的方法进行了修改,第二种方式则是将一些线程池的参数调高了,把Tomcat线程池入口的并发数以及HSF的线程池的值调高了,然而这样的调整只是缓解了一些问题,但是并没有解决最根本的问题。然后用户下意识地采取了在云上进行扩容的方式,然后“奇迹”出现了,整个服务全挂掉了。

为什么服务会挂掉呢?后来经过了解发现客户的架构是这样的:使用Redis特别容易忽略掉一些东西,这些东西从运维的层面上讲会有一些规格,这些规格主要分为两种,包括连接数和带宽。很多运维人员误以为在云上面的环境走内网没有带宽限制,其实完全错了,所以对于云上规格模型一定要特别清楚。还有就是在开发层面的问题,在开发时,大家都喜欢使用common-pool,并且默认喜欢设置成为一个很大的值,不管使不使用这些个连接都可能会默认起来这么多连接,比如所有的机器都用50,机器规模扩容到百级别的时候就可能会撑死。还有就是在开发时很喜欢使用一些List,把这些List序列化成JSON然后存储为String,再从List返回仅有的几个元素,这些也是会引起问题的原因,以上这些就是我们用 Redis 的时候会遇到的一些问题。

三、一些微服务架构的常用模式
服务化:模式
在这里大家可能就会希望有一种东西可以动态地调整Redis这部分的连接数,其实这就是微服务中的一种模式叫做Externalized configuration——外部配置动态推送,也就是通过外部的某些配置批量化地更新某些东西。

刚才提到的是因为某些东西不行了导致网站会怎么样,这时候可以选择考虑当发生故障的时候可以选择将这个服务进行限流降级或者甚至将整个链路都进行降级,这就是微服务推荐的第二种模式,Circuit Breaker——限流降级。

之前介绍的两个应用比较简单,只有两个服务之间的模型。当面对如下图所示的这样的情况下就需要使用第三个模式Distributed tracing——分布式追踪。

当然其实微服务的模式不止上面提到的这三种,下图就展现了整个微服务这部分能够想到的一些模式。首先我们需要这样的一个基础组件,这个基础组件包含了一些东西,包括了一些架构的思想,以及服务之间的架构如何进行编排交互,还有采用什么样的部署模式,包括应该采用单个容器级别的部署还是单个机器级别的部署,甚至是单个VM级别的部署。还需要制定某一种服务发现策略等;当在真正决定好了架构之后,可能需要真正的微服务的底座来支撑起整个微服务的架构,底座规划好之后就需要选择服务之间的通讯模型。那么通讯模型选择好之后,就需要开始考虑服务高可用方面的事情了。当这方面规划之后就需要考虑到一些日志、审计以及分布式追踪等等这些数据化运营之类的东西。还有一点比较重要的就是当要对于服务进行拆分就需要考虑数据库到底是该分还是该合。如果需要分的话,那么问题来了,数据的一致性今后应该如何保证,当然这里也有一些模式可寻的;还有分开之前数据可能是从一个地方取,现在需要从各个地方取了、测试也是一样,以前可能是测一块,现在可能会需要测试一打,这些都是在微服务拆分完之后需要面对的挑战,这也是本次最想传递给大家的东西。

以下内容根据演讲嘉宾现场视频以及PPT整理而成。
本次分享主要围绕以下三个方面:
- 微服务拆分
- 服务化案例分享与最佳实践
- 一些微服务架构的常用模式
首先从真实的案例开始讲起,当一些客户接触到了一些微服务之后,他们就会将原本经典的分层架构模式拆分成为微服务。如下图所示,客户原本的架构是比较经典的分层架构模型,可以看到每一层的结构都非常清晰,当此时想要做微服务拆分的时候第一步就是将DAO层直接拆分出来。而大家都知道,这样做肯定会有一些不妥之处,那么不妥之处到底在哪里呢?在这里就埋下一个疑问,大家可以先思考一下对于这样的经典的分层架构究竟应该如何去进行拆分。
在介绍完这些基本概念之后,我们继续分享DDD的战略和战术。从一个比较标准的解释来说,战略就是用于指导军队去打赢某场战争的思想,也就是一种方法和谋略。而DDD的战略当然不是用于打仗的,而是用于拆分领域等其他方面的。当然DDD的战略和战争的战略有一定相同之处,比方在打仗的时候需要选好一块什么样的地盘,以及在上面用什么样子的方式如何发动这场战争,而这块地盘在微服务拆分上就是可以理解成选择一个什么样子的领域,这个领域可以分为核心域和子域。对于核心域而言,从我们的业务就能显而易见地看出来它是区别于其他业务的一块领域,也就是核心业务。如果这块领域不复存在的话,那么整个团队或者公司就会出现问题。在核心域周围则会存在支撑子域,比如对于电商业务而言,交易就是核心,核心域的旁边则会有支撑核心域来区分业务的子域,比如图中的物流和支付,这两部分的支撑子域也是整个业务独有的。当然也会有其他的部分,比如通用子域,这部分就是其他公司可能会有或者其他业务也会存在的领域,这部分的业务逻辑可能可以直接从某些开源软件或者商业软件拿过来使用,比如像每个公司都会使用的会员系统以及积分系统等。除此之外还有一些基础的技术服务,比如像短信服务这样的技术服务。
聊完了DDD这部分之后,我们再来看一下它和我们今天提到的微服务的拆分到底存在什么样的关系。对于服务拆分而言,首先可以看到刚才分享的根据公司内部的核心域或者业务内部的核心域或者业务能力,拆分其实很简单,首先就是“一纵”,纵向拆分就像阿里巴巴这样将业务拆分成为淘宝、天猫、聚划算以及咸鱼等。然后再是“一横”,横指的就是拆分成刚才介绍的那些领域,包括核心域、支撑子域以及通用子域等。然后再找一些东西,也就是找其他的一些基础的通用子域、一些基础的能力域等。
二、服务化案例分享与最佳实践
接下来为大家分享一些实际的案例,这些案例是提取自EDAS上云两年多以来在客户的环境中存在的实际问题。在正式介绍案例之前需要首先介绍几个简单的名词:
- HSF:阿里巴巴集团所使用的 RPC 框架,全称为 High Speed Framework,江湖人称:“好舒服”。
- EDAS:企业级分布式应用服务,阿里巴巴中间件提供的云上商业微服务解决方案。
- VPC:Virtual Private Cloud,虚拟私有云服务。阿里云上的一个基础网络产品,为隔离用户的网络环境而生。
下图是HSF服务的简单介绍。首先第一个要分享的案例就是开发的时候遇到的问题,在分享这个案例之前首先简单地介绍一下HSF。HSF有一个注册中心,这个注册中心用来管理发布和订阅服务。当一个生产者启动起来之后可能会对于自己的服务进行发布,注册中心监听了这个服务就会发送给正在监听的消费者,然后消费者拿到地址之后就可以直接进行RPC的调用了。
分享完了开发,接下来为大家分享关于部署的问题。曾经有客户提出了一个工单,就是服务都能够看到,但是还是会出现时好时坏的情况。我们仔细地审视了客户部署的架构,发现客户的架构是这样的:他们使用了两个VPC,这两个VPC之间有生产者和消费者,还有一个在另外一个VPC中,这时候就会发现我们所看到的部署架构肯定是调用不通的,因为他们的网络本身就是不通的。
分享完部署我们再聊一聊连调,在连调过程中我们遇到了一些非常怪的事情,就是客户的反馈就是在云上面部署的一个服务,有的人可以连接,但是有的人就是偶尔不可以连接,非常不稳定!我们看到这样的现象之后就去客户的服务器上提取了一些关键的信息,其中的就包括这些:客户开启了recycle以及timestamps,然后主要说有NAT网关,而且办公网下的开发机器上存在时间戳不一致的情况,说到了这里很多有经验的同学就已经猜出来问题到底是怎么一回事了,原因就如下图中左边所列举的这样。

接下来分享一下关于压测的内容,这里讲的压测可能会与大家通常理解的场景不太一样,因为是客户在做压测的时候拿着我们的RPC框架和另外一个目前比较流行的Restful的框架进行对比,给回来的反馈是性能不行。在接到这样的反馈之后,我们大概看了一下客户的代码是什么样子,客户的代码大概是将一个对象使用JSON序列化之后做RPC,RPC回来之后也是一个String,之后再将这个String反序列化成为一个对象返回给客户端,也就是客户在代码中做了两次JSON的序列化。在HSF中大家都知道它是字节支持序列化的,这里的两次序列化是浪费的;这种写法很普遍,希望大家注意。
下图的这个案例就是HSF的线程池满了,这个问题我相信很多同学都已经遇到过,针对于这个问题这里首先列出了一个大概的时序图,也就是可能在自己的业务中需要依赖于外部服务,可能就会影响到内部的情况。
服务化:模式
在这里大家可能就会希望有一种东西可以动态地调整Redis这部分的连接数,其实这就是微服务中的一种模式叫做Externalized configuration——外部配置动态推送,也就是通过外部的某些配置批量化地更新某些东西。
当然挑战之下必有陪伴,EDAS就是陪伴大家的解决方案。
