概述
Kubernetes中有很多的控制器,比如常用的ReplicaSet,Deployment,DaemonSet,StatefulSet等。以这四种为例,我们可以将它们分为两种,一种为有状态控制器,一种为无状态控制器,StatefulSet则为有状态控制器,通常用于管理有状态的服务,如:MySQL,Redis,MongoDB等。
有状态控制器通常有以下几个特点:
稳定的,唯一的网络标识
稳定的,持久的存储
有序的,优雅的部署和伸缩
有序的,优雅的删除和停止
有序的,自动的滚更新
也就是说如果我们的应用如有以上的任何一个特点我们就可以使用statefulset控制器来完成应用的部署。
网络标识:
Pod名称:唯一且不会发生变化,由 $(statefulset name)-(0-N)组成,N为一个无限大的正整数,从0开始。
容器内计算机名:与Pod名称一至且不会发生变化。
DNS A记录:每一个副本都拥有唯一且不变的一条A记录指定自己,格式组成:$(pod name).$(service name).$(namespace name).svc。
唯一的Pod标签,通过StatefulSet创建的每个副本都拥有一个唯一的标签,格式为:statefulset.kubernetes.io/pod-name=$(pod name),通常可以将新的service单独关联到此标签,来解决某个Pod的问题等。
以上的标识只要配置不发生改变,发生重启,升级,删除后再创建这些标识都不会发生变化。
备注:Pod的IP地址会发生变化,但我们也可以使用另外的方案来结合StatefulSet实现固定IP的方案,通常不推荐这么做。
持久存储:
每个Pod都对应一个PVC,PVC的名称组成:$(volumeClaimTemplates name)-$(pod name)-(0-N),N为一个无限大的正整数,从0开始。
当Pod被删除的时候不会自动删除对应的PVC,需要手动删除。
每次Pod升级,重启,删除重新创建后都呆以保证使用的是首次使用的PVC,保证数据的唯一性与持久化。
有序:
当部署有N个副本的StatefulSet时候,严格按照从0到N的顺序创建,并且下一个Pod创建的前提是上一个Pod已经Running状态。
当删除有N个副本的StatefulSet时候,严格按照从N到0的顺序删除,并且下一个Pod删除的前提是上一个Pod已经完全Delete。
当扩容StatefulSet副本的时候,每增加一个pod前提是上一个Pod已经Running状态。
当减少StatefulSet副本的时候,每删除一个pod前提是上一个Pod已经完全Delete。
当升级StatefulSet的时候,严格按照从N到1的顺序升级,并且下一个Pod升级的前提是上一个Pod已经Running状态。
无头服务(headless service)
无头服务是Kubernetes中service类型的一种,为什么需要无头服务?通常我们在使用Deployment部署Pod的时候名称是随机的字符串,Pod也是无序的。但 StatefulSet是有序且名称唯一,每一个Pod不可以被取代,所以这时候就需要使用无头服务来实现。
无头服务特点:当使用Kubernetes内DNS解析去访问Service的时候,会将解析的IP指向Service后端的Pod。当无头服务与StatefulSet控制器使用的时候,因为每个Pod的数据可能是不一样的,所以在Service名前面再加了一个Pod名,这样我们的每个StatefulSet控制器的Pod就拥有了唯一的网络标识(A记录)。
无头服务案例:
apiVersion: v1 kind: Service metadata: namespace: test name: mysql-test spec: selector: app: mysql-test clusterIP: None ports: - port: 3306 targetPort: 3306
ClusterIP:当此项的值为“None”的时候,此服务就为无头服务,Kubernetes不会给此服务分配IP地址。当使用type为NodePort的时候不可以使用无头服务。
volumeClaimTemplates:
此为Kubernetes中的一个对象,对象的路径为“statefulset.spec.volumeClaimTemplates”,用于给StatefulSet的Pod申请PVC,称为卷申请模板,它会为每个Pod生成不同的PVC,关绑定到PV,从而实现Pod的专有存储。
通常我们在使用Deployment中使用“deployment.spec.template.spec.volumes”与PVC建立关联的时候,所有的副本使用的是相同的PV与PVC,他们的数据是相同的。而StatefulSet为实现各Pod的专有存储,所以才有了“statefulset.spec.volumeClaimTemplates”此方法。
实际应用场景
以MySQL主从为例,我们将实现通过同一个StatefulSet控制器创建出主库和从库,主库和从库的my.cnf配置自定义,和从库的自动扩容(目前实现半自动)
思路:
使用ConfigMap实现主库和从库的自定义配置
使用initContainers实现主容器在启动之前初始化配置
关于initContainers简单介绍
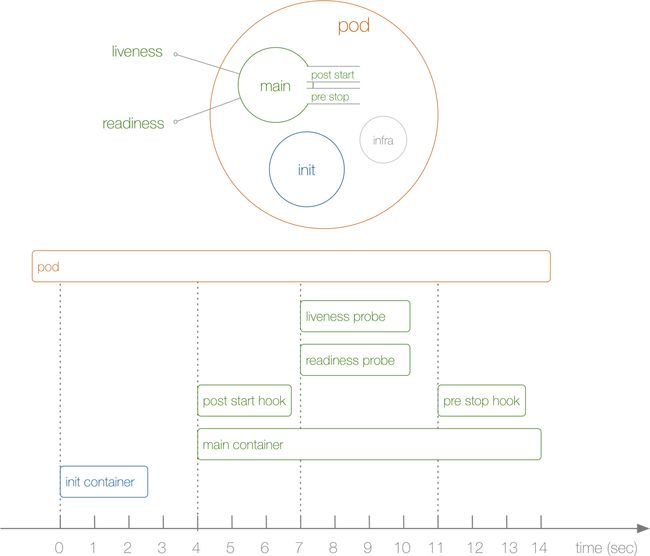
从上图我们可以看出一个Pod的生命周期包含:initContainer,PostStart,PreStop,Liveness和Readiness。其中容器(Container)的生命周期只包含PostStart,PreStop,Liveness和Readiness,而initContainer是属于在容器启动之前的。
initContainer应用场景:
可以解决服务之间的依赖问题,如我们有一个Web服务和MySQL,如果我们将两个服务同时启动有可能会出现数据库连接异常等问题,那么我们可以通过initContainer去监测当只有MySQL启动成功的时候再启动Web。
做初始化配置,如我们现在做的MySQL主从案例,主库与从库my.cnf的server_id不一样,我们无法使用同一配置,为减少管理上的麻烦也不推荐使用两个StatefulSet控制器,那么这时候我们就可以使用initContainer来完成我们的需求。我们可以将数据卷挂载到initContainer,在initContainer内产生的数据是可以被主容器所使用的,所以我们server_id通过initContainer内生成并写入my.cnf。
在此不对初始化容器做过多介绍,详情可参考:初始化容器,或者查看官方文档。
首先创建名称空间
apiVersion: v1 kind: Namespace metadata: name: test
定义ConfigMap配置文件
apiVersion: v1 kind: ConfigMap metadata: namespace: test name: mysql-cnf data: master.cnf: | [mysqld] log-bin=mysql-bin binlog-ignore-db=information_schema,performance_schema,mysql,sys expire_logs_days=7 slave.cnf: | [mysqld] slave_parallel_workers=16 slave_parallel_type=logical_clock master_info_repository=TABLE relay_log_info_repository=TABLE relay_log_recovery=ON
根据自身情况,可自定义自己的选项。其中server_id不需要指定,将在初始化容器的时候写入。
定义StatefulSet配置文件
apiVersion: apps/v1
kind: StatefulSet
metadata:
namespace: test
name: mysql-test
spec:
serviceName: mysql-test
replicas: 2
selector:
matchLabels:
app: mysql-test
template:
metadata:
namespace: test
name: mysql-test
labels:
app: mysql-test
spec:
initContainers:
- name: init-mysql
image: mysql:5.7
command:
- bash
- "-c"
- |
hostname=`echo $HOSTNAME | awk -F '-' '{print $NF}'`
server_id=$[hostname+100]
if [[ $hostname -eq 0 ]]; then
cp /mnt/my.cnf.d/master.cnf /mnt/conf.d/my.cnf
else
cp /mnt/my.cnf.d/slave.cnf /mnt/conf.d/my.cnf
fi
echo "server_id=${server_id}" >> /mnt/conf.d/my.cnf
volumeMounts:
- name: mysql-cnf
mountPath: /mnt/my.cnf.d/
- name: conf
mountPath: /mnt/conf.d/
containers:
- name: mysql-test
image: mysql:5.7
args: ["--character_set_server=utf8","--collation-server=utf8_unicode_ci"]
env:
- name: MYSQL_ROOT_PASSWORD
value: "!gogen123"
volumeMounts:
- name: conf
mountPath: /etc/mysql/conf.d/
- name: mysql-data
mountPath: /var/lib/mysql/
volumes:
- name: mysql-cnf
configMap:
name: mysql-cnf
- name: conf
emptyDir: {}
volumeClaimTemplates:
- metadata:
namespace: test
name: mysql-data
spec:
accessModes: ["ReadWriteOnce"]
resources:
requests:
storage: 2Gi
storageClassName: nas
---
apiVersion: v1
kind: Service
metadata:
namespace: test
name: mysql-test
spec:
selector:
app: mysql-test
clusterIP: None
ports:
- port: 3306
targetPort: 3306
initContainers:该配置段主要实现主容器启动时的配置初始化,初始化容器。因为StatefulSet控制器拥有唯一的网络标识,如计算机机名是唯一,所以我们根据计算机名做判断 ,让一个副本做Master,其余的做Slave,从而将不同的配置复制到共享数据卷“conf”。此卷由我们自己定义,并采用emptyDir方式,前面我们讲了在initContainers中产生的数据可以在主容器中使用,那么同样主容器也挂载此数据卷,那么就可以使用我们自定义的配置,我们通过volumes直接将conf挂载到/etc/mysql/conf.d/目录即可使用。
volumeClaimTemplates:关于此块配置用于自动申请pvc并于pv进行关联,因为我们使用的是阿里云的NAS,默认情况下无法自动申请成功,需要定义一个存储类(storageClassName),具体此参数的值可以通过 pv的配置获取,可以将pv输出为yaml查看。
最后:
我们的应用已经启动成功,还剩下最后一步。进入从库的MySQL Shell内执行以下命令。
change master to master_host='mysql-test-0.mysql-test.test.svc',master_port=3306,master_user='root',master_password='!gogen123',master_log_file='mysql-bin.000003',master_log_pos=154; start slave;
正常情况下这时候查看我们的从库状态就已经成功,如果需要扩容,扩容后的从库同样也只需要执行上面两条SQL命令即可。
总结:最后一步还需要手动完成,不是特别完善,也大大提高了我们部署时的麻烦,扩容也相对方便,后续考虑将最后一步也实现自动化。