注意:我们将大数据相关组件全部安装在/opt/bigdata目录
1.hadoop2.x 概述
hadoop2中NameNode可以有多个(目前只支持2个)。每一个都有相同的职能。一个是active状态的,一个是standby状态的。当集群运行时,只有active状态的NameNode是正常工作的,standby状态的NameNode是处于待命状态的,时刻同步active状态NameNode的数据。一旦active状态的NameNode不能工作,standby状态的NameNode就可以转变为active状态的,就可以继续工作了。
2个NameNode的数据其实是实时共享的。新HDFS采用了一种共享机制,Quorum Journal Node(JournalNode)集群或者Nnetwork File System(NFS)进行共享。NFS是操作系统层面的,JournalNode是hadoop层面的,我们这里使用JournalNode集群进行数据共享(这也是主流的做法)。JournalNode的架构图如下:
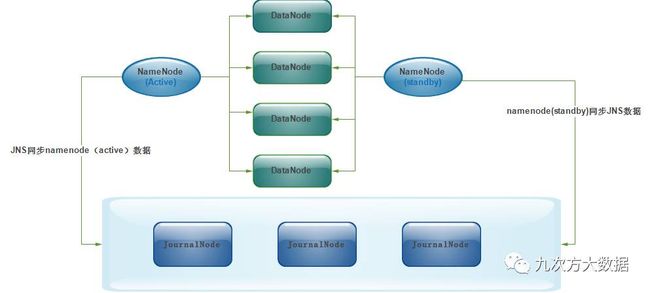
两个NameNode为了数据同步,会通过一组称作JournalNodes的独立进程进行相互通信。当active状态的NameNode的命名空间有任何修改时,会告知大部分的JournalNodes进程。standby状态的NameNode有能力读取JNs中的变更信息,并且一直监控edit log的变化,把变化应用于自己的命名空间。standby可以确保在集群出错时,命名空间状态已经完全同步了。
对于HA集群而言,确保同一时刻只有一个NameNode处于active状态是至关重要的。否则,两个NameNode的数据状态就会产生分歧,可能丢失数据,或者产生错误的结果。为了保证这点,这就需要利用使用ZooKeeper了。首先HDFS集群中的两个NameNode都在ZooKeeper中注册,当active状态的NameNode出故障时,ZooKeeper能检测到这种情况,它就会自动把standby状态的NameNode切换为active状态。
2.hadoop2.8 安装
现在cluster201上将配置文件修改好
[hadoop@cluster201 bigdata]$ pwd
/opt/bigdata
# 下载hadoop2.8安装包
[hadoop@cluster201 bigdata]$ wget http://www.apache.org/dyn/closer.cgi/hadoop/common/hadoop-2.8.0/hadoop-2.8.0.tar.gz
# 解压文件
[hadoop@cluster201 bigdata]$ tar -zvxf hadoop-2.8.0.tar.gz
增加hadoop环境变量,使用root在/etc/profile文件末尾增加如下内容:
#Hadoop
export HADOOP_HOME=/opt/bigdata/hadoop-2.8.0
export PATH=$PATH:$HADOOP_HOME/bin
创建相应目录
[hadoop@cluster201 bigdata]$ mkdir hadoop-2.8.0/tmp
[hadoop@cluster201 bigdata]$ mkdir hadoop-2.8.0/hdfs
[hadoop@cluster201 bigdata]$ mkdir hadoop-2.8.0/hdfs/name
[hadoop@cluster201 bigdata]$ mkdir hadoop-2.8.0/hdfs/data
进入到$HADOOP_HOME/etc/hadoop目录修改配置文件,配置项可参考文档http://hadoop.apache.org/docs/r2.8.0/

[hadoop@cluster201 bigdata]$ cd hadoop-2.8.0/etc/hadoop/
[hadoop@cluster201 hadoop]$ pwd
/opt/bigdata/hadoop-2.8.0/etc/hadoop
[hadoop@cluster201 hadoop]$ ll
总用量 160
-rw-r--r--. 1 hadoop hadoop 4942 3月 17 13:31 capacity-scheduler.xml
-rw-r--r--. 1 hadoop hadoop 1335 3月 17 13:31 configuration.xsl
-rw-r--r--. 1 hadoop hadoop 318 3月 17 13:31 container-executor.cfg
-rw-r--r--. 1 hadoop hadoop 1148 6月 20 15:22 core-site.xml
-rw-r--r--. 1 hadoop hadoop 3804 3月 17 13:31 hadoop-env.cmd
-rw-r--r--. 1 hadoop hadoop 4682 6月 20 14:56 hadoop-env.sh
-rw-r--r--. 1 hadoop hadoop 2598 3月 17 13:31 hadoop-metrics2.properties
-rw-r--r--. 1 hadoop hadoop 2490 3月 17 13:31 hadoop-metrics.properties
-rw-r--r--. 1 hadoop hadoop 9683 3月 17 13:31 hadoop-policy.xml
-rw-r--r--. 1 hadoop hadoop 1379 6月 20 16:18 hdfs-site.xml
-rw-r--r--. 1 hadoop hadoop 1449 3月 17 13:31 httpfs-env.sh
-rw-r--r--. 1 hadoop hadoop 1657 3月 17 13:31 httpfs-log4j.properties
-rw-r--r--. 1 hadoop hadoop 21 3月 17 13:31 httpfs-signature.secret
-rw-r--r--. 1 hadoop hadoop 620 3月 17 13:31 httpfs-site.xml
-rw-r--r--. 1 hadoop hadoop 3518 3月 17 13:31 kms-acls.xml
-rw-r--r--. 1 hadoop hadoop 1611 3月 17 13:31 kms-env.sh
-rw-r--r--. 1 hadoop hadoop 1631 3月 17 13:31 kms-log4j.properties
-rw-r--r--. 1 hadoop hadoop 5546 3月 17 13:31 kms-site.xml
-rw-r--r--. 1 hadoop hadoop 13661 3月 17 13:31 log4j.properties
-rw-r--r--. 1 hadoop hadoop 951 3月 17 13:31 mapred-env.cmd
-rw-r--r--. 1 hadoop hadoop 1383 3月 17 13:31 mapred-env.sh
-rw-r--r--. 1 hadoop hadoop 4113 3月 17 13:31 mapred-queues.xml.template
-rw-r--r--. 1 hadoop hadoop 862 6月 20 16:18 mapred-site.xml
-rw-r--r--. 1 hadoop hadoop 758 3月 17 13:31 mapred-site.xml.template
-rw-r--r--. 1 hadoop hadoop 33 6月 20 16:05 slaves
-rw-r--r--. 1 hadoop hadoop 2316 3月 17 13:31 ssl-client.xml.example
-rw-r--r--. 1 hadoop hadoop 2697 3月 17 13:31 ssl-server.xml.example
-rw-r--r--. 1 hadoop hadoop 2250 3月 17 13:31 yarn-env.cmd
-rw-r--r--. 1 hadoop hadoop 4567 3月 17 13:31 yarn-env.sh
-rw-r--r--. 1 hadoop hadoop 928 6月 20 16:19 yarn-site.xml
修hadoop-env.sh的JAVA_HOME地址
# The java implementation to use.
export JAVA_HOME=/usr/local/java/jdk1.8.0_121
vim core-site.xml
fs.defaultFS
hdfs://cluster201:9000
hadoop.tmp.dir
/opt/bigdata/hadoop-2.8.0/tmp
ha.zookeeper.quorum
cluster201:2181,cluster202:2181,cluster203:2181
vim hdfs-site.xml
dfs.namenode.name.dir
/opt/bigdata/hadoop-2.8.0/hdfs/name
dfs.datanode.name.dir
/opt/bigdata/hadoop-2.8.0/hdfs/data
dfs.replication
1
dfs.namenode.http-address
cluster201:50070
dfs.namenode.secondary.http-address
cluster201:50090
vim mapred-site.xml
mapreduce.framework.name
yarn
vim yarn-site.xml
yarn.resourcemanager.hostname
cluster201
yarn.nodemanager.aux-services
mapreduce_shuffle
将修改好配置的hadoop安装包压缩拷贝到cluster202,cluster203上,并到对应机器上进行解压
[hadoop@cluster201 hadoop]$ cd /opt/bigdata/
[hadoop@cluster201 bigdata]$ pwd
/opt/bigdata
[hadoop@cluster201 bigdata]$ tar -zvcf hadoop-2.8.0.tar.gz hadoop-2.8.0
[hadoop@cluster201 bigdata]$ scp hadoop-2.8.0.tar.gz cluster202:/opt/bigdata/
[hadoop@cluster201 bigdata]$ scp hadoop-2.8.0.tar.gz cluster203:/opt/bigdata/
3. 启动haoop(先将zookeeper启动好)
# 格式化hdfs
[hadoop@cluster201 bigdata] hadoop namenode -format
# 启动hadoop
[hadoop@cluster201 bigdata] ./hadoop-2.8.0/sbin/start-all.sh
在宿主机windows的hosts文件种增加如下内容(C:\Windows\System32\drivers\etc\hosts):
192.168.88.201 cluster201
192.168.88.202 cluster202
192.168.88.203 cluster203
hdfs webUI地址:http://cluster201:50070

yarn webUI地址:http://cluster201:8088
