Pandas常用数据预处理方法及指令
1.前言
前一段时间,在小伙伴的怂恿下参加了京东的Jdata数据大赛(并以剪刀石头布的方式决定的组长,草率!

不过非常感谢小伙伴们对我的信任,还有我们一起学习的热情让我一下恢复了对学习的xing趣了呢),作为一名小白,抱着学习的心态去的,所谓的万事开头难是真的,从来没接触过这种比赛或工作的我也是一头雾水,以前没上过数据处理和挖掘的课程,不知从何下手,就是在这样一穷二白的情况下开始了长达两周的工作。

向曾经参加过类似比赛的师兄取经、请教老师解题思路、查阅相关书籍(幸好我之前有买许多相关书籍)、逛各种论坛、竞赛官方qq群,做了很多准备,当然最难的就是动手实践。很多理论在实战面前都是苍白的,比如书里面经常说可视化、可视化,对于数据的可视化我们可以得到很多的信息,然而有一些是可以这样做的,另一些如用户购买关系网络因为数据量的问题、而且就算抽样的话,可视化后我们依然分析不出个所以然来

(可能还是方法没用对)。
在这两周内在每天提交次数、每周截至提交日期的压力下,我快速成长了起来,一开始不知道用什么软件、代码处理数据,后来查资料、问人确定了几个可选方案,直接上手干,第一个方案不行,查查怎么回事还不行就换,最后决定使用jupyter notebook+pandas+matplot的方案果断上;(神奇的 )

从pandas数据结构什么都不知道,到从各种博客搜集所需要的代码,后来发现遗忘速度真的很快,用完就忘还得重新找对应博客、资料很麻烦,所以就有了我这篇总结的雏形,经过不断的完善在经历了一整个数据处理流程下来,常用的代码都已经总结的很完善了,然后就是学习了一些大牛开源的代码后,发现:我艹,还能这么搞! 于是进一步完善总结。
于是进一步完善总结。
两周的工作主要就是两个部分:数据处理+上模型跑代码,然后就不断的循环重复,跑完代码提交看看有什么问题,藉由这次比赛经历我也得到了许多宝贵的经验,如很多事情想和做是不一样的,做了才会有深刻的理解,理解了才会更好的思考。

不过很遗憾的是,因为时间和精力有限,没能继续做下去,再往下做基本就是用户推荐的事了,也看了一些用户推荐的资料和具体的实现方法,可以实现的,但因为已过两周,超过了我的预算,而且与我感兴趣领域不很相关,而且在此期间有了一些成长,从无到有还是收获许多,所以选择退出。
不过好记性不如烂笔头,已过去一段时间,发现再不总结归纳,又要忘的差不多,所以给自己一个借口,好好整理一下,以便日后需要的时候用的着,在这里也是想和大家分享一下。
最后还想和大家分享的是微信文章的下载和学习小技巧,我一般都是直接将网页下载或者另存为pdf看,foxit reader还是一个很好的pdf阅读器,我可以在上面设置各种快捷键方便我做注释。
PS:因为时间有限而且总结的内容有点多,格式来不及统计,各位将就看吧!
2.常用数据预处理方法
这个部分总结的是在python中常见的数据预处理方法。
2.1标准化(Standardization or Mean Removal and Variance Scaling)
变换后各维特征有0均值,单位方差。也叫z-score规范化(零均值规范化)。计算方式是将特征值减去均值,除以标准差。
sklearn.preprocessing.scale(X)
一般会把train和test集放在一起做标准化,或者在train集上做标准化后,用同样的标准化去标准化test集,此时可以用scaler
scaler = sklearn.preprocessing.StandardScaler().fit(train)
scaler.transform(train)
scaler.transform(test)
实际应用中,需要做特征标准化的常见情景:SVM
2.2最小-最大规范化
最小-最大规范化对原始数据进行线性变换,变换到[0,1]区间(也可以是其他固定最小最大值的区间)
min_max_scaler = sklearn.preprocessing.MinMaxScaler()
min_max_scaler.fit_transform(X_train)
2.3规范化(Normalization)
规范化是将不同变化范围的值映射到相同的固定范围,常见的是[0,1],此时也称为归一化。
将每个样本变换成unit norm。
X = [[ 1, -1, 2],[ 2, 0, 0], [ 0, 1, -1]]
sklearn.preprocessing.normalize(X, norm='l2')
得到:
array([[ 0.40, -0.40, 0.81], [ 1, 0, 0], [ 0, 0.70, -0.70]])
可以发现对于每一个样本都有,0.4^2+0.4^2+0.81^2=1,这就是L2 norm,变换后每个样本的各维特征的平方和为1。类似地,L1 norm则是变换后每个样本的各维特征的绝对值和为1。还有max norm,则是将每个样本的各维特征除以该样本各维特征的最大值。
在度量样本之间相似性时,如果使用的是二次型kernel,需要做Normalization
2.4特征二值化(Binarization)
给定阈值,将特征转换为0/1
binarizer = sklearn.preprocessing.Binarizer(threshold=1.1)
binarizer.transform(X)
2.5标签二值化(Label binarization)
lb = sklearn.preprocessing.LabelBinarizer()
2.6类别特征编码
有时候特征是类别型的,而一些算法的输入必须是数值型,此时需要对其编码。
enc = preprocessing.OneHotEncoder()
enc.fit([[0, 0, 3], [1, 1, 0], [0, 2, 1], [1, 0, 2]])
enc.transform([[0, 1, 3]]).toarray() #array([[ 1., 0., 0., 1., 0., 0., 0., 0., 1.]])
上面这个例子,第一维特征有两种值0和1,用两位去编码。第二维用三位,第三维用四位。
另一种编码方式
newdf=pd.get_dummies(df,columns=["gender","title"],dummy_na=True)
详细的说明可以在后面常用指令中看到
Examples
>>> import pandas as pd
>>> s = pd.Series(list('abca'))
>>> pd.get_dummies(s)
a b c
0 1 0 0
1 0 1 0
2 0 0 1
3 1 0 0
>>> s1 = ['a', 'b', np.nan]
>>> pd.get_dummies(s1)
a b
0 1 0
1 0 1
2 0 0
>>> pd.get_dummies(s1, dummy_na=True)
a b NaN
0 1 0 0
1 0 1 0
2 0 0 1
>>> df = pd.DataFrame({'A': ['a', 'b', 'a'], 'B': ['b', 'a', 'c'],
'C': [1, 2, 3]})
>>> pd.get_dummies(df, prefix=['col1', 'col2'])
C col1_a col1_b col2_a col2_b col2_c
0 1 1 0 0 1 0
1 2 0 1 1 0 0
2 3 1 0 0 0 1
>>> pd.get_dummies(pd.Series(list('abcaa')))
a b c
0 1 0 0
1 0 1 0
2 0 0 1
3 1 0 0
4 1 0 0
2.7标签编码(Label encoding)
le = sklearn.preprocessing.LabelEncoder()
le.fit([1, 2, 2, 6])
le.transform([1, 1, 2, 6]) #array([0, 0, 1, 2])
#非数值型转化为数值型
le.fit(["paris", "paris", "tokyo", "amsterdam"])
le.transform(["tokyo", "tokyo", "paris"]) #array([2, 2, 1])
2.8特征中含异常值时
sklearn.preprocessing.robust_scale
2.9生成多项式特征
这个其实涉及到特征工程了,多项式特征/交叉特征。
poly = sklearn.preprocessing.PolynomialFeatures(2)
poly.fit_transform(X)
原始特征:
转化后:
3常用指令
#以后调用pandas函数都用pd
import pandas as pd
#将matplotlib的图表直接嵌入到Notebook之中,或者使用指定的界面库显示图表
%matplotlib inline
df = pd.read_csv('文件路径地址/名.csv',header=0,encoding='gbk')
df.head(5)
df.tail(5)
3.1对缺失值的处理
#填充缺失值
df.fillna(0)
df.model_id.fillna(-1)
pandas使用isnull()和notnull()函数来判断缺失情况。
对于缺失数据一般处理方法为滤掉或者填充。
滤除缺失数据
对于一个Series,dropna()函数返回一个包含非空数据和索引值的Series,例如:

对于DataFrame,dropna()函数同样会丢掉所有含有空元素的数据,例如:
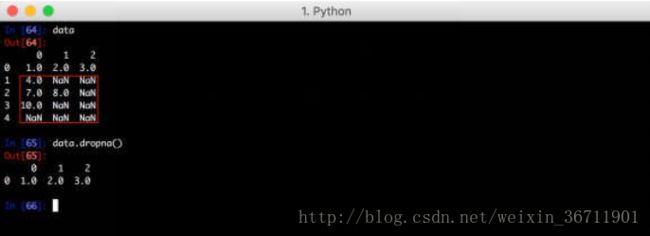
但是可以指定how='all',这表示只有行里的数据全部为空时才丢弃,例如:

如果想以同样的方式按列丢弃,可以传入axis=1,例如:

#将第2列为空的行去掉
tmp=tmp[-pd.isnull(tmp.iloc[:,2])]
填充缺失数据
如果不想丢掉缺失的数据而是想用默认值填充这些空洞,可以使用fillna()函数:

如果不想只以某个标量填充,可以传入一个字典,对不同的列填充不同的值:

3.2快速描述
df.describe()
3.3返回df的长度
len(df)
3.4赋值
df.loc[:,’a’]=np.array([5]*len(df))#给df赋新列‘a’
df[df>0]=-df
通过定位df.loc or df.iloc [,]=1
3.5设置每列标签,推荐使用第二种。其实可以直接打开编辑,在表头写上标签(直接编辑这个如果不需要多次重复读取数据可以这么干,其他情况尽量不要这么干)。
df.columns = ['water_year','rain_octsep', 'outflow_octsep',
'rain_decfeb','outflow_decfeb','rain_junaug', 'outflow_junaug']
df.rename(columns={'total_bill': 'total', 'tip': 'pit', 'sex': 'xes'}, inplace=True)
3.6有时你想提取一整列,使用列的标签可以非常简单地做到:
df['rain_octsep']或df.rain_ocstep
注意,当我们提取列的时候,会得到一个 series ,而不是 dataframe 。记得我们前面提到过,你可以把 dataframe 看作是一个 series 的字典,所以在抽取列的时候,我们就会得到一个 series。
还记得我在命名列标签的时候特意指出的吗?不用空格、破折号之类的符号,这样我们就可以像访问对象属性一样访问数
3.7返回由【布尔值】构成的dataframe,就是这个标签小于1000和大于1000的信息。
df.rain_octsep < 1000 # Or df['rain_octsep] < 1000
3.8过滤后,得到的表,信息的筛选
df[df.rain_octsep < 1000]
3.9选择区域
df[0:3]选择行;df.loc[:,[‘a’,’b’]]通过标签在多个轴上选择
df.loc[0:3,[‘a’,’b’]]标签切片
#返回索引为xxx字符串的series
df.loc['xxx']
df.loc[3,’a’]快速访问标量
#数据条件筛选,筛选出标签为a内容=x的行series
df.loc[df[‘a’]==’x’]
#保留b,c列筛选外加排序
df.loc[df[‘a’]==’x’,[‘a’,‘b’,’c’]].sort([‘a’],ascending=False)
#多列数据筛选并排序
df.loc[(df[‘a’]==’x’)&(df[‘b’]>10),[‘a’,’b’,’c’]].sort([‘a’],ascending=False)
#按筛选条件求和,满足前一条件则对b求和..还有按条件计算均值mean(),max(),min(),count()
df.loc[df[‘a’]==’x’].b.sum()
df.loc[(df[‘a’]==’x’)&(df[‘c’]>10)].b.sum()#就是多条件求和,sumifs
3.10用isin()方法过滤,确认a列中是否有one、two,有则筛出来
df[df[‘a’].isin([‘one’,’two’])]
3.11iloc返回固定行的series,非常好用
df.iloc[30]
df.iloc[3]返回行
df.iloc[3:5,1:2]返回某一选片
df.iloc[[1,2,4],[0,2]]返回特定选片交集
df.iloc[1:3,:]返回1:3行
df.iloc[1,2]返回特定位置数据
3.12设置某标签为索引
df=df.set_index(['xxx'])
3.13将索引恢复为数据,如果先排序了,再恢复不影响排序结果
df = df.reset_index('xxx')
3.14排序,True是升序,False是降序,.head(x)选取特定行排序
df.sort_index(ascending=True)
#对‘a’进行排序
df.sort([‘a’],ascending=False)
df.sort(colums=’a’)
#对多列进行排序
df.sort([‘a’,’b’],ascending=False)
3.15分组,将某一列标签合并并统计将结果赋给tf,如size(),max、min、mean等函数
#10*10指间隔为10,1000*1000间隔为1000
tf=df.groupby(df.year // 10 *10).max()
decade_rain = df.groupby([df.year // 10 * 10, df.rain_octsep // 1000 * 1000])[['outflow_octsep','outflow_decfeb', 'outflow_junaug']].mean()
#分别对k1,k2列进行排序,df1,df2都是中间变量类型,为groupby类型,使用推导式【x for x in df1】显示
df1=df.groupby([‘k1’,’k2’])
df2=df.groupby(‘k1’)



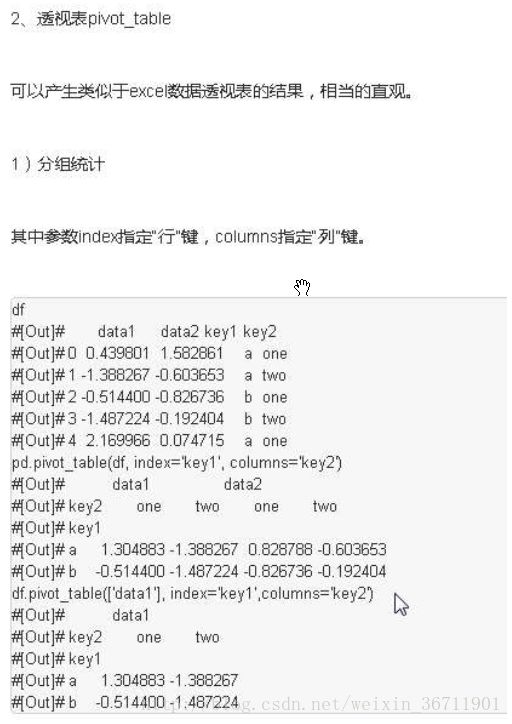

3.16返回数据规模,行和列
df.shape
3.17返回各列数据格式
df.dtypes
3.18python输出替代%s替代string,等,‘’%(a,b)后面括号内是几个替代值
print("I'm %s. I'm %d year old" % ('Vamei', 99))
3.19添加列,除了insert
df[‘new’]=[‘a’,’b’,’c’]
#插入列,第二个位置,名为‘e’,值=df[‘a’]
df.insert(1,’e’,df[‘a’])
3.20删除行列,1为列0为行
df2=df.drop([‘a’,’b’],axis=1)
#输出并删除‘b’列,将b列插入到第一列
b=df.pop(‘b’)
df.insert(0,’b’,b)
3.21将结果输出成csv
df.to_csv(‘xxx.csv’,index=False,encoding=’utf-8’,)
|
|
path_or_buf:字符串或文件句柄,默认为无 文件路径或对象,如果没有提供结果作为字符串返回。 sep:character,default',' 输出文件的字段分隔符。 na_rep:string,default'' 缺少数据表示 float_format:string,default None 格式化浮点数字符串 列:序列,可选 要写的列 标题:布尔或字符串列表,默认为True 写出列名。如果给出了一个字符串列表,那么它被认为是列名称的别名 index:boolean,默认为True 写行名(索引) index_label:字符串或序列,或False,默认为无 如果需要,索引列的列标签。如果没有给出,并且 头和索引为True,则使用索引名称。如果DataFrame使用MultiIndex,则应该给出一个序列。如果False不打印索引名称的字段。使用index_label = False更容易在R中导入 模式:str Python写入模式,默认'w' encoding:string,可选 表示在输出文件中使用的编码的字符串,在Python 2上默认为“ascii”,在Python 3上默认为“utf-8”。 压缩:字符串,可选 表示在输出文件中使用的压缩字符串的字符串,允许的值为'gzip','bz2','xz',仅在第一个参数为文件名时使用 line_terminator:string,default'\n' 在输出文件中使用的换行字符或字符序列 引用:来自csv模块的可选常量 默认为csv.QUOTE_MINIMAL。如果您设置了一个float_format, 那么float将被转换为字符串,因此csv.QUOTE_NONNUMERIC将它们视为非数字 quotechar:string(length 1),default'“' 字符用来引用字段 doublequote:boolean,默认为True 控制在一个字段内引用quotechar escapechar:string(length 1),default None 适当时用于逃避sep和quotechar的字符 chunksize:int或None 一次写入的行 tupleize_cols:boolean,default False 将multi_index列作为元组列表(如果为True)或新(扩展格式),如果为False) date_format:string,default无 格式为datetime对象的字符串 decimal:string,default'。' 字符识别为小数分隔符。例如使用','为欧洲数据 新版本0.16.0。 |
3.22数据合并
1.merge
merge 函数通过一个或多个键来将数据集的行连接起来。该函数的主要 应用场景是针对同一个主键存在两张包含不同特征的表,通过该主键的连接,将两张表进行合并。合并之后,两张表的行数没有增加,列数是两张表的列数之和减一。
函数的具体参数为:
merge(left,right,how='inner',on=None,left_on=None,right_on=None,
left_index=False,right_index=False,sort=False,suffixes=('_x','_y'),copy=True)
· on=None 指定连接的列名,若两列希望连接的列名不一样,可以通过left_on和right_on 来具体指定
· how=’inner’,参数指的是左右两个表主键那一列中存在不重合的行时,取结果的方式:inner表示交集,outer 表示并集,left 和right 表示取某一边。
举例如下
import pandas as pd
df1 = pd.DataFrame([[1,2,3],[5,6,7],[3,9,0],[8,0,3]],columns=['x1','x2','x3'])
df2 = pd.DataFrame([[1,2],[4,6],[3,9]],columns=['x1','x4'])
print df1
print df2
df3 = pd.merge(df1,df2,how = 'left',on='x1')
print df3
在这里我分别设置了两个DataFrame类别的变量df1,df2,(平常我们用的表csv文件,读取之后也是DataFrame 格式)。然后我设置 on=’x1’,即以两个表中的x1为主键进行连接,设置how=’left’ ,即是以两个表中merge函数中左边那个表的行为准,保持左边表行数不变,拿右边的表与之合并。结果如下:

第一个结果为how=’left’的情况。第二个结果为how=’inner’的情况。
注意:在how=’left’设置后,左边行之所以能够保持不变,是因为右边的表主键列没有重复的值,x下面我会举个例子作为思考题:

这是两张表,分别为df1,df2;
第一个问题:
在默认情况下即merge(df1,df2)其他参数为默认值的返回结果是 什么?
第二个问题:
在加上how=’left’之后的返回结果是什么?
看完了问题之后,返回去看这两张表,不着急看答案,仔细想想。
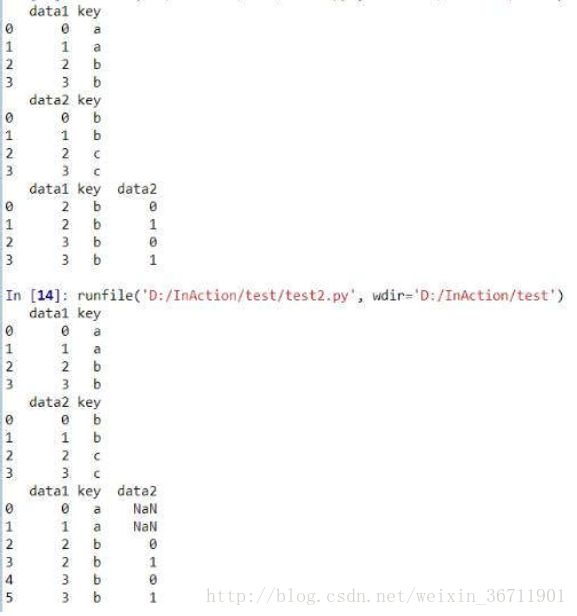
这两个问题明白之后,表之间的连接和映射应该都能够明白了。
2.concat
concat 与其说是连接,更准确的说是拼接。就是把两个表直接合在一起。于是有一个突出的问题,是横向拼接还是纵向拼接,所以concat 函数的关键参数是axis 。
函数的具体参数是:
concat(objs,axis=0,join='outer',join_axes=None,ignore_index=False,keys=None,levels=None,names=None,verigy_integrity=False)
· objs 是需要拼接的对象集合,一般为列表或者字典
· axis=0 是行拼接,拼接之后行数增加,列数也根据join来定,join=’outer’时,列数是两表并集。同理join=’inner’,列数是两表交集。
在默认情况下,axis=0为纵向拼接,此时有
concat([df1,df2]) 等价于 df1.append(df2)
在axis=1 时为横向拼接 ,此时有
concat([df1,df2],axis=1) 等价于 merge(df1,df2,left_index=True,right_index=True,how='outer')
举个例子
import pandas as pd
df1 = pd.DataFrame({'key':['a','a','b','b'],'data1':range(4)})
print df1
df2 = pd.DataFrame({'key':['b','b','c','c'],'data2':range(4)})
print df2
print pd.concat([df1,df2],axis=1)
print pd.merge(df1,df2,left_index=True,right_index=True,how='outer')

3.23类别特征编码get_dummy
是一种很实用的将字典中某一列的可能存在的值,多维化映射在对应行,有点像one-hot编码方式,统计该列所有可能存在的值(像sort),作为字典新添加的几个列向量,每一行之前存在哪个值,对应列处值就是1,否则为0。
格式如下:pandas.get_dummies()
参数有:data(数据),prefix(前缀),columns(选择进行处理的列),dummy_na(是否将NaN添加到dummies),drop_first(将统计出来的k个dummies去掉第一个得到k-1个dummies)
举例:import pandas as pd
S=pd.Series(list(‘abca’))
>>> pd.get_dummies(s)
a b c
0 1 0 0
1 0 1 0
2 0 0 1
3 1 0 0
>>> s1 = ['a', 'b', np.nan]
>>> pd.get_dummies(s1)
a b
0 1 0
1 0 1
2 0 0
>>> pd.get_dummies(s1, dummy_na=True)
a b NaN
0 1 0 0
1 0 1 0
2 0 0 1
>>> df = pd.DataFrame({'A': ['a', 'b', 'a'], 'B': ['b', 'a', 'c'], 'C': [1, 2, 3]})
>>> pd.get_dummies(df, prefix=['col1', 'col2'])
C col1_a col1_b col2_a col2_b col2_c
0 1 1 0 0 1 0
1 2 0 1 1 0 0
2 3 1 0 0 0 1
>>> pd.get_dummies(pd.Series(list('abcaa')))
a b c
0 1 0 0
1 0 1 0
2 0 0 1
3 1 0 0
4 1 0 0
>>> pd.get_dummies(pd.Series(list('abcaa')), drop_first=True))
b c
0 0 0
1 1 0
2 0 1
3 0 0
4 0 0
3.24apply函数lambda部分
python的lambda表达式很想swift语言里的Closure闭包,无函数名的语句块,可以指定传入参数、计算结果。
语法格式如下:
lambda 传入参数 : 返回的计算表达式
eg1, 求一个数的平方
>>> g = lambda x : x ** 2
# x为传入参数, 冒号后的x ** 2为传回表达式
>>> print g(4)
16
>>> def h(x):
... return x ** 2
...
>>> print h(4)
16
eg2, 求两数之和
>>> t = lambda x,y: x +y
# x和y为传入参数, 冒号后的 x + y为传回值的表达式
>>> t(2, 4)
6
eg3,用map 求1...4平方 => 1*1,2*2,3*3,4*4
map(lambda x : x * x, range(1,5))
返回值是[1,4,9,16]
lambda赋值语句是倒装的,0 if x==-1 #令x=0当x==-1时。
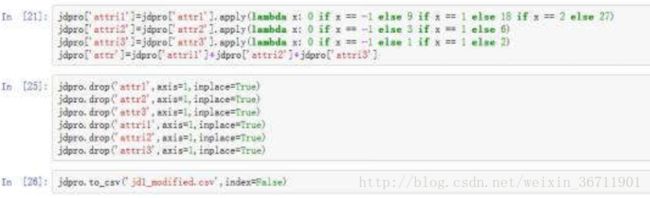
3.25对多列条件进行apply处理,定义函数
def do_something(x, y):
return x * y
df['new_col'] = map(lambda x, y: do_something(x, y) , df['col_1'], df['col_2'])
3.26浮点小数四舍五入
round(x,5)#保留小数点后5位
3.27常用时间处理,time、datetime、timedelta
Python其实内置了很多方式处理日期和时间,很方便,在我最初对时间的处理上,简单粗暴的用几位数表示,带来了后续时间间隔计算的各种麻烦,后来忽然发现python已经内置了时间的处理的库。。。
Python 提供了一个 time 和 calendar 模块可以用于格式化日期和时间。
时间间隔是以秒为单位的浮点小数。
每个时间戳都以自从1970年1月1日午夜(历元)经过了多长时间来表示。
Python 的 time 模块下有很多函数可以转换常见日期格式。如函数time.time()用于获取当前时间戳, 如下实例:
#!/usr/bin/python# -*- coding: UTF-8 -*-
import time; # 引入time模块
ticks = time.time()print "当前时间戳为:", ticks
以上实例输出结果:
当前时间戳为: 1459994552.51
时间戳单位最适于做日期运算。但是1970年之前的日期就无法以此表示了。太遥远的日期也不行,UNIX和Windows只支持到2038年。
什么是时间元组?很多Python函数用一个元组装起来的9组数字处理时间:
| 序号 |
字段 |
值 |
| 0 |
4位数年 |
2008 |
| 1 |
月 |
1 到 12 |
| 2 |
日 |
1到31 |
| 3 |
小时 |
0到23 |
| 4 |
分钟 |
0到59 |
| 5 |
秒 |
0到61 (60或61 是闰秒) |
| 6 |
一周的第几日 |
0到6 (0是周一) |
| 7 |
一年的第几日 |
1到366 (儒略历) |
| 8 |
夏令时 |
-1, 0, 1, -1是决定是否为夏令时的旗帜 |
| 序号 |
属性 |
值 |
| 0 |
tm_year |
2008 |
| 1 |
tm_mon |
1 到 12 |
| 2 |
tm_mday |
1 到 31 |
| 3 |
tm_hour |
0 到 23 |
| 4 |
tm_min |
0 到 59 |
| 5 |
tm_sec |
0 到 61 (60或61 是闰秒) |
| 6 |
tm_wday |
0到6 (0是周一) |
| 7 |
tm_yday |
1 到 366(儒略历) |
| 8 |
tm_isdst |
-1, 0, 1, -1是决定是否为夏令时的旗帜 |
上述也就是struct_time元组。这种结构具有如下属性:
获取当前时间
从返回浮点数的时间辍方式向时间元组转换,只要将浮点数传递给如localtime之类的函数。
#!/usr/bin/python# -*- coding: UTF-8 -*-
import time
localtime = time.localtime(time.time())print "本地时间为 :", localtime
以上实例输出结果:
本地时间为 : time.struct_time(tm_year=2016, tm_mon=4, tm_mday=7, tm_hour=10, tm_min=3, tm_sec=27, tm_wday=3, tm_yday=98, tm_isdst=0)
获取格式化的时间
你可以根据需求选取各种格式,但是最简单的获取可读的时间模式的函数是asctime():
#!/usr/bin/python# -*- coding: UTF-8 -*-
import time
localtime = time.asctime( time.localtime(time.time()) )print "本地时间为 :", localtime
以上实例输出结果:
本地时间为 : Thu Apr 7 10:05:21 2016
格式化日期
我们可以使用 time 模块的 strftime 方法来格式化日期,:
time.strftime(format[, t])
#!/usr/bin/python# -*- coding: UTF-8 -*-
import time
# 格式化成2016-03-20 11:45:39形式print time.strftime("%Y-%m-%d %H:%M:%S", time.localtime())
# 格式化成Sat Mar 28 22:24:24 2016形式print time.strftime("%a %b %d %H:%M:%S %Y", time.localtime())
# 将格式字符串转换为时间戳
a = "Sat Mar 28 22:24:24 2016"print time.mktime(time.strptime(a,"%a %b %d %H:%M:%S %Y"))
以上实例输出结果:
2016-04-07 10:25:09Thu Apr 07 10:25:09 20161459175064.0
python中时间日期格式化符号:
· %y 两位数的年份表示(00-99)
· %Y 四位数的年份表示(000-9999)
· %m 月份(01-12)
· %d 月内中的一天(0-31)
· %H 24小时制小时数(0-23)
· %I 12小时制小时数(01-12)
· %M 分钟数(00=59)
· %S 秒(00-59)
· %a 本地简化星期名称
· %A 本地完整星期名称
· %b 本地简化的月份名称
· %B 本地完整的月份名称
· %c 本地相应的日期表示和时间表示
· %j 年内的一天(001-366)
· %p 本地A.M.或P.M.的等价符
· %U 一年中的星期数(00-53)星期天为星期的开始
· %w 星期(0-6),星期天为星期的开始
· %W 一年中的星期数(00-53)星期一为星期的开始
· %x 本地相应的日期表示
· %X 本地相应的时间表示
· %Z 当前时区的名称
· %% %号本身
获取某月日历
Calendar模块有很广泛的方法用来处理年历和月历,例如打印某月的月历:
#!/usr/bin/python# -*- coding: UTF-8 -*-
import calendar
cal = calendar.month(2016, 1)print "以下输出2016年1月份的日历:"print cal;
以上实例输出结果:
以下输出2016年1月份的日历:
January 2016Mo Tu We Th Fr Sa Su
1 2 3
4 5 6 7 8 9 1011 12 13 14 15 16 1718 19 20 21 22 23 2425 26 27 28 29 30 31
Time 模块
| 序号 |
函数及描述 |
| 1 |
time.altzone |
| 2 |
time.asctime([tupletime]) |
| 3 |
time.clock( ) |
| 4 |
time.ctime([secs]) |
| 5 |
time.gmtime([secs]) |
| 6 |
time.localtime([secs]) |
| 7 |
time.mktime(tupletime) |
| 8 |
time.sleep(secs) |
| 9 |
time.strftime(fmt[,tupletime]) |
| 10 |
time.strptime(str,fmt='%a %b %d %H:%M:%S %Y') |
| 11 |
time.time( ) |
| 12 |
time.tzset() |
Time 模块包含了以下内置函数,既有时间处理相的,也有转换时间格式的:
Time模块包含了以下2个非常重要的属性:
| 序号 |
属性及描述 |
| 1 |
time.timezone |
| 2 |
time.tzname |
日历(Calendar)模块
此模块的函数都是日历相关的,例如打印某月的字符月历。
| 序号 |
函数及描述 |
| 1 |
calendar.calendar(year,w=2,l=1,c=6) |
| 2 |
calendar.firstweekday( ) |
| 3 |
calendar.isleap(year) |
| 4 |
calendar.leapdays(y1,y2) |
| 5 |
calendar.month(year,month,w=2,l=1) |
| 6 |
calendar.monthcalendar(year,month) |
| 7 |
calendar.monthrange(year,month) |
| 8 |
calendar.prcal(year,w=2,l=1,c=6) |
| 9 |
calendar.prmonth(year,month,w=2,l=1) |
| 10 |
calendar.setfirstweekday(weekday) |
| 11 |
calendar.timegm(tupletime) |
| 12 |
calendar.weekday(year,month,day) |
星期一是默认的每周第一天,星期天是默认的最后一天。更改设置需调用calendar.setfirstweekday()函数。模块包含了以下内置函数:
其他相关模块和函数
在Python中,其他处理日期和时间的模块还有:
· datetime模块
· pytz模块
· dateutil模块
欢迎各位童鞋交流和指教!