数学推导+纯Python实现机器学习算法1:线性回归
很多同学在学习机器学习的时候,理论粗略看一遍之后就直接上手编程了,非常值得表扬。但是他不是真正的上手写算法,而是去直接调用 sklearn 这样的 package,这就不大妥当了。笔者不是说调包不好,在实际工作和研究中,封装好的简单易用的 package 给我们的工作带来了莫大的便利,大大提高了我们机器学习模型和算法的实现效率。但这仅限于使用过程中。
笔者相信很多有企图心的同学肯定不满足于仅仅去使用这些 package 而不知模型和算法的细节。所以,如果你是一名机器学习算法的学习者,在学习过程中最好不要一上来就使用这些封装好的包,而是根据自己对算法的理解,在手推过模型和算法的数学公式后,仅依靠 numpy 和 pandas 等基础包的情况下手写机器学习算法。如此一遍过程之后,再去学习如何调用 sklearn 等机器学习库,相信各位更能体会到调包的便利和乐趣。之后再去找数据实战和打比赛做项目,相信你一定会成为一名优秀的机器学习算法工程师。
本机器学习系列文章的两个主题就是数学推导+纯 numpy 实现。第一讲我们从最基础的线性回归模型开始。相信大家对回归算法一定是相当熟悉了,特别是咱们有统计背景的同学。所以,笔者直接上数学推导。
回归分析的数学推导
本来想着上笔者的手推草稿的,但字迹过于张扬,在 word 里或者用 markdown 写公式又太耗费时间,这里就直接借用周志华老师的机器学习教材上的推导过程:

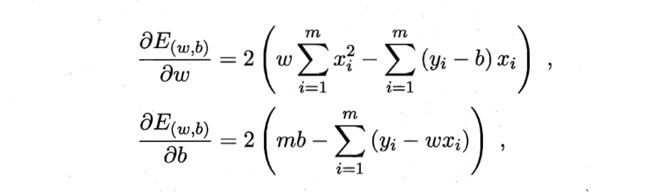
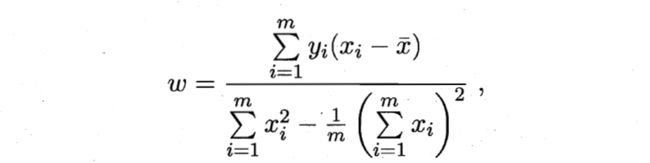
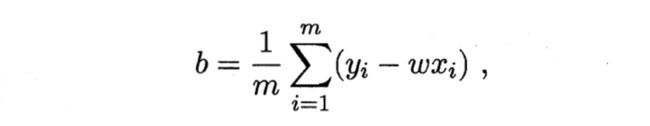
推广到矩阵形式就是:

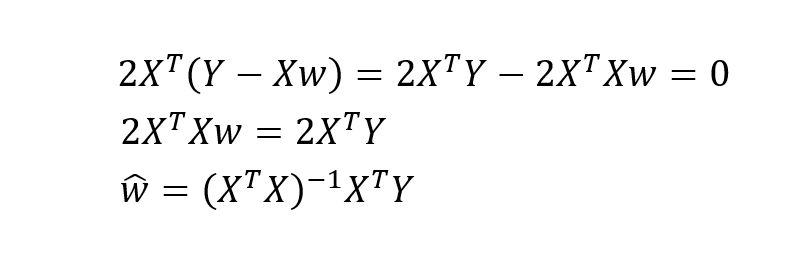
以上便是线性回归模型中参数估计的推导过程。
回归分析的 numpy 实现
按照惯例,动手写算法之前我们需要理一下编写思路。回归模型主体部分较为简单,关键在于如何在给出 mse 损失函数之后基于梯度下降的参数更新过程。首先我们需要写出模型的主体和损失函数以及基于损失函数的参数求导结果,然后对参数进行初始化,最后写出基于梯度下降法的参数更新过程。当然,我们也可以写出交叉验证来得到更加稳健的参数估计值。话不多说,直接上代码。
回归模型主体:
import numpy as np
def linear_loss(X, y, w, b): num_train = X.shape[0] num_feature = X.shape[1]
# 模型公式 y_hat = np.dot(X, w) + b
# 损失函数 loss = np.sum((y_hat-y)**2)/num_train
# 参数的偏导 dw = np.dot(X.T, (y_hat-y)) /num_train db = np.sum((y_hat-y)) /num_train
return y_hat, loss, dw, db
参数初始化:
def initialize_params(dims): w = np.zeros((dims, 1)) b = 0 return w, b
基于梯度下降的模型训练过程:
def linar_train(X, y, learning_rate, epochs): w, b = initialize(X.shape[1])
loss_list = []
for i in range(1, epochs):
# 计算当前预测值、损失和参数偏导 y_hat, loss, dw, db = linar_loss(X, y, w, b)
loss_list.append(loss)
# 基于梯度下降的参数更新过程 w += -learning_rate * dw b += -learning_rate * db
# 打印迭代次数和损失 if i % 10000 == 0: print('epoch %d loss %f' % (i, loss))
# 保存参数 params = {
'w': w,
'b': b }
# 保存梯度 grads = {
'dw': dw,
'db': db }
return loss_list, loss, params, grads
以上便是线性回归模型的基本实现过程。下面以 sklearn 中的 diabetes 数据集为例进行简单的训练。
数据准备:
from sklearn.datasets import load_diabetes
from sklearn.utils import shuffle diabetes = load_diabetes() data = diabetes.data target = diabetes.target # 打乱数据
X, y = shuffle(data, target, random_state=13) X = X.astype(np.float32)
# 训练集与测试集的简单划分
offset = int(X.shape[0] * 0.9) X_train, y_train = X[:offset], y[:offset] X_test, y_test = X[offset:], y[offset:] y_train = y_train.reshape((-1,1)) y_test = y_test.reshape((-1,1)) print('X_train=', X_train.shape) print('X_test=', X_test.shape) print('y_train=', y_train.shape) print('y_test=', y_test.shape)

执行训练:
loss_list, loss, params, grads = linar_train(X_train, y_train, 0.001, 100000)
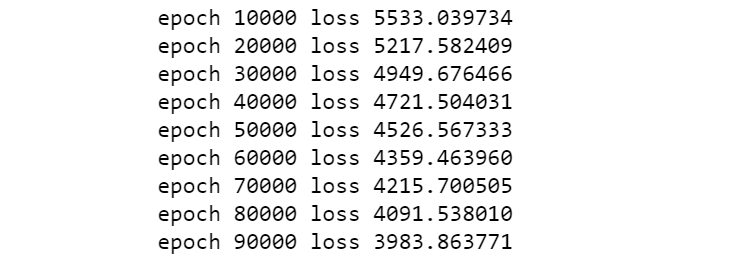
查看训练得到的回归模型参数值:
print(params)
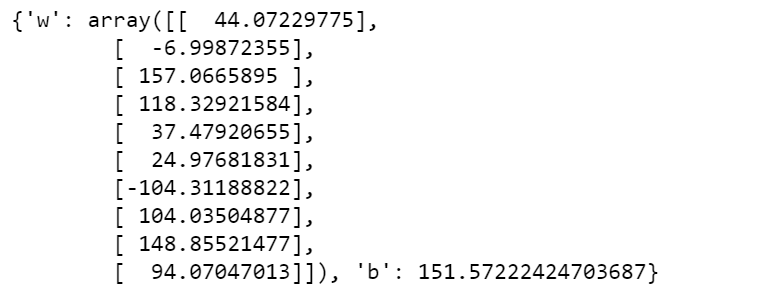
下面定义一个预测函数对测试集结果进行预测:
def predict(X, params): w = params['w'] b = params['b'] y_pred = np.dot(X, w) + b
return y_pred y_pred = predict(X_test, params) y_pred[:5]

利用 matplotlib 对预测结果和真值进行展示:
import matplotlib.pyplot as plt f = X_test.dot(params['w']) + params['b'] plt.scatter(range(X_test.shape[0]), y_test) plt.plot(f, color = 'darkorange') plt.xlabel('X') plt.ylabel('y') plt.show()
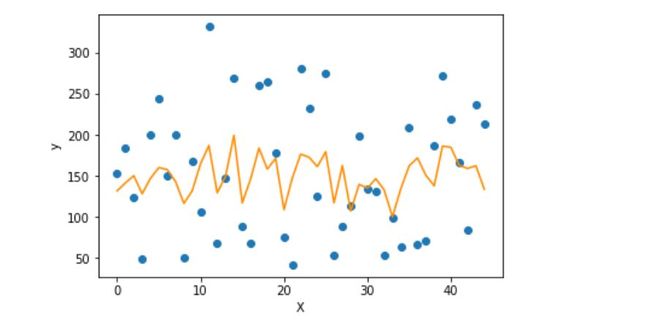
可见全变量的数据对于线性回归模型的拟合并不好,一来数据本身的分布问题,二来简单的线性模型对于该数据拟合效果差。当然,我们只是为了演示线性回归模型的基本过程,不要在意效果。
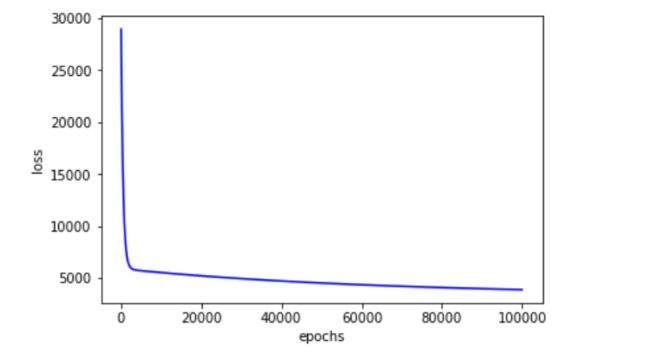
训练过程中损失的下降:
plt.plot(loss_list, color = 'blue') plt.xlabel('epochs') plt.ylabel('loss') plt.show()
封装一个线性回归类
笔者对上述过程进行一个简单的 class 封装,其中加入了自定义的交叉验证过程进行训练:
import numpy as np
from sklearn.utils import shuffle
from sklearn.datasets import load_diabetes
class lr_model():
def __init__(self):
pass def prepare_data(self): data = load_diabetes().data target = load_diabetes().target X, y = shuffle(data, target, random_state=42) X = X.astype(np.float32) y = y.reshape((-1, 1)) data = np.concatenate((X, y), axis=1)
return data
def initialize_params(self, dims): w = np.zeros((dims, 1)) b = 0 return w, b
def linear_loss(self, X, y, w, b): num_train = X.shape[0] num_feature = X.shape[1] y_hat = np.dot(X, w) + b loss = np.sum((y_hat-y)**2) / num_train dw = np.dot(X.T, (y_hat - y)) / num_train db = np.sum((y_hat - y)) / num_train
return y_hat, loss, dw, db
def linear_train(self, X, y, learning_rate, epochs): w, b = self.initialize_params(X.shape[1])
for i in range(1, epochs): y_hat, loss, dw, db = self.linear_loss(X, y, w, b) w += -learning_rate * dw b += -learning_rate * db
if i % 10000 == 0: print('epoch %d loss %f' % (i, loss))
params = {
'w': w,
'b': b } grads = {
'dw': dw,
'db': db }
return loss, params, grads
def predict(self, X, params): w = params['w'] b = params['b'] y_pred = np.dot(X, w) + b
return y_pred
def linear_cross_validation(self, data, k, randomize=True):
if randomize: data = list(data) shuffle(data) slices = [data[i::k] for i in range(k)]
for i in range(k): validation = slices[i] train = [data
for s in slices if s is not validation for data in s] train = np.array(train) validation = np.array(validation)
yield train, validation
if __name__ == '__main__': lr = lr_model() data = lr.prepare_data()
for train, validation in lr.linear_cross_validation(data, 5): X_train = train[:, :10] y_train = train[:, -1].reshape((-1, 1)) X_valid = validation[:, :10] y_valid = validation[:, -1].reshape((-1, 1)) loss5 = [] loss, params, grads = lr.linear_train(X_train, y_train, 0.001, 100000) loss5.append(loss) score = np.mean(loss5) print('five kold cross validation score is', score) y_pred = lr.predict(X_valid, params) valid_score = np.sum(((y_pred - y_valid) ** 2)) / len(X_valid) print('valid score is', valid_score)
以上便是本节的内容,基于 numpy 手动实现一个简单的线性回归模型。
参考资料:
周志华 机器学习
往期精彩:
一个数据科学从业者的学习历程


长按二维码.关注数据科学家养成记
