Python中web服务器、web框架以及WSGI的作用和关系浅析
文章目录
- 一、web服务器、web框架
- 二、网络服务器网关接口(WSGI)
- 三、web服务器、web框架和WSGI
- 四、代码示例
- 1. web服务器程序
- 2. web框架程序
- 3. 代码分析
在Python实现web服务器入门学习笔记(6)——多进程实现并发HTTP服务器的面向对象封装中,我们已经实现了并发HTTP服务器,并且将代码进行了面向对象封装。
实际上,在真实的web开发中,为了提高开发效率、复用已有成果、降低系统耦合度,实际运行在服务器上的程序可以大致解耦为web服务器、web框架。
常用的web服务器有Apache、Nginx等,常用的Python后端web框架有Django、Flask、Tornado等。
在Python的web开发中,一般web服务器和web框架之间为了实现互通,二者还会遵循web服务器网关接口(WSGI:Web Server Gateway Interface)
一、web服务器、web框架
web服务器的功能一般为:
- 用于以并发方式处理来自多客户端基于HTTP协议的连接请求;
- 当客户端请求静态资源时,web服务器直接将部署在其上的静态资源在响应中返回客户端;
- 当客户端请求动态资源,以及当后端希望实现复杂的业务逻辑(如:用户注册、登录、验证等)时,web服务器负责先将收到的响应请求发送web框架,而后web服务器负责将web框架处理的结果以HTTP协议应答方式返回。
web框架的功能一般为:
- 处理web服务器转发过来的动态资源请求;
- 处理复杂的业务逻辑,如:用户注册、登录、验证、订单管理等。
总体来说:
进行web服务器和web框架的功能划分是为了实现功能解耦,即:
- 对于Apache、Nginx这类web服务器来说,其主要需解决的问题是高并发:和数以千万计的用户同时保持连接;能够在一定时间内传送大量数据(吞吐量);以HTTP协议接收请求并返回应答;
- 对于Django、Flask这类web框架来说,其主要需解决的问题是“重复造轮子”的困境:在web后端开发中,很多业务逻辑是共通的,如:用户管理、会话保持等。
二、网络服务器网关接口(WSGI)
现今,虽然开发者使用Python语言进行web后端开发时,可以根据需要搭配使用web服务器和web框架,以使得二者的组合可以最大限度满足自己的需求,但是事实并非一直如此。
因为web服务器和web框架的开发者并不是同一批人,二者内部的功能封装并不遵循相同的接口,故早先时候,开发者对web服务器的选择会影响其对可用web框架的选择,反之亦然。
鉴于上述原因,在PEP(Python Enhancement Proposal) 333中,Python社区提出了WSGI,这是一套简单、通用的接口,用于web服务器和web框架之间,使得web服务器和web框架的开发者专注于各自的领域,也能降低web后端的开发者进行web服务器和web框架之间适配的工作。
简单来说:
WSGI是一套用于web服务器和Python web框架之间的协议,用于规定二者之间交换数据的要求。
三、web服务器、web框架和WSGI
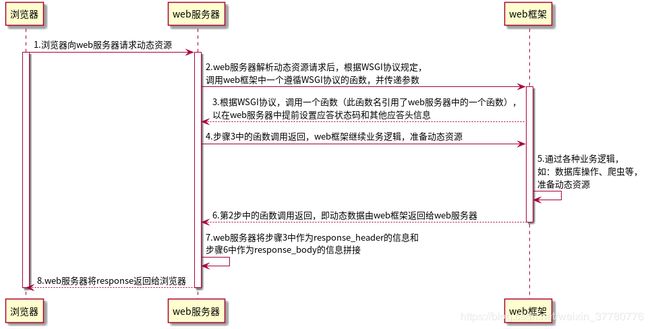
下图是遵循WSGI协议的web服务器和web框架配合完成浏览器一次动态资源请求的时序图。
四、代码示例
下面是自定义遵循WSGI协议的web服务器和web框架:
1. web服务器程序
import socket
import re
import multiprocessing
import mini_web_frame
class WSGIServer(object):
def __init__(self):
# 1.创建套接字
self.tcp_server_socket = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
# 通过设定套接字选项解决[Errno 98]错误
self.tcp_server_socket.setsockopt(socket.SOL_SOCKET, socket.SO_REUSEADDR, 1)
# 2.绑定端口
self.tcp_server_socket.bind(("", 7899))
# 3.变为监听套接字
self.tcp_server_socket.listen(128)
# 定义两个实例属性,用于存储response_header信息
self.status = None
self.headers = None
def set_response_header(self, status, headers):
self.status = status
# 在服务器程序中指定web服务器的信息
self.headers = [("Server", "user-defined web server v1.0")]
self.headers += headers
def serve_client(self, new_client_socket):
"""为这个客户端返回数据"""
# 6.接收浏览器发送过来的http请求
request = new_client_socket.recv(1024).decode("utf-8")
# 7.将请求报文分割成字符串列表
request_lines = request.splitlines()
print(request_lines)
# 8.通过正则表达式提取浏览器请求的文件名
file_name = None
ret = re.match(r"^[^/]+(/[^ ]*)", request_lines[0])
if ret:
file_name = ret.group(1)
print("file_name:", file_name)
if file_name == "/":
file_name = "/index.html"
# 9.返回http格式的应答数据给浏览器
# 9.1 如果请求的资源不是以.py结尾,那么就认为浏览器请求的是静态资源(HTML、CSS、JPG、PNG等)
if not file_name.endswith(".py"):
# 静态资源处理逻辑
pass
else:
# 9.2 如果浏览器请求的资源是以.py结尾,则表示浏览器请求的是动态资源
env = dict()
env["PATH_INFO"] = file_name
body = mini_web_frame.application(env, self.set_response_header)
header = "HTTP/1.1 %s\r\n" % self.status
for each in self.headers:
header += "%s:%s\r\n" % (each[0], each[1])
header += "\r\n"
response = header + body
new_client_socket.send(response.encode("utf-8"))
# 10. 关闭此次服务的套接字
new_client_socket.close()
def run_forever(self):
"""用来完成程序整体控制"""
while True:
# 4.等待新客户端连接
new_client_socket, client_addr = self.tcp_server_socket.accept()
# 5.为连接上的客户端服务
process = multiprocessing.Process(target=self.serve_client, args=(new_client_socket,))
process.start()
new_client_socket.close()
# 关闭监听套接字
self.tcp_server_socket.close()
def main():
"""
控制整体,创建一个web服务器对象,然后调用这个对象的run_forever()方法运行
:return:
"""
wsgi_server = WSGIServer()
wsgi_server.run_forever()
if __name__ == "__main__":
main()
2. web框架程序
import time
def index():
return "这是主页"
def login():
return "这是登录页面"
def application(environ, start_response):
start_response("200 OK", [("Content-Type", "text/html;charset=utf-8")])
file_name = environ['PATH_INFO']
print("file_name = ", file_name)
if file_name == "/index.py":
return index()
elif file_name == "/login.py":
return login()
else:
return "Hello World, 你好,世界: %s" % time.ctime()
3. 代码分析
上述代码中,假设动态资源是以.py结尾的,启动服务器程序后,假设在浏览器的地址栏输入:127.0.0.1:7899/index.py(服务器程序和浏览器处于同一台物理服务器上),则浏览器成功连接上服务器后:
- 服务器程序执行至第45行,提取出资源名称index.py;
- 服务器程序执行至第52行,判断此请求为动态资源;
- 服务器程序执行至第55行,而后定义待传入框架的字典变量;
- 服务器程序执行至第61行,根据WSGI协议,服务器调用web框架中符合WSGI协议的application()函数,并传入两个参数:
- 字典:用于以键值对形式向web框架传入资源名称;
- web服务器中符合WSGI协议的函数的引用:用于后续被web框架调用以设置应答的header。
- 转入web框架第12行,开始执行application()函数;
- web框架程序执行至第13行,调用start_response引用的web服务器方法set_response_header(),以设置应答状态和其他header信息,分别存储于服务器的实例属性status和headers中;
- web框架程序继续向下执行,进行业务逻辑处理,处理完成后,application()函数返回;
- 程序回到web服务器程序中,此时application()函数的返回值即作为应答的body;
- 服务器程序执行至第63行,开始拼接应答的header;
- 最后,拼接好的应答response被发送至浏览器。