大连理工大学中文情感词汇本体库(含情绪分析代码)

中文文本数据的情绪计算
昨天 如何对微博推文进行情绪分析(细粒度情感分析) 介绍了英文的NRC情绪词典。虽然支持中文,但由于制作问题,导致并不完全适应中文场景。今天介绍大连理工大学中文情感词汇本体库
依旧使用微博数据
import pandas as pd
weibo_df = pd.read_csv('simplifyweibo_4_moods.csv')
weibo_df.head()

我们使用中文的情绪词典重复昨天的分析,看看效果。首先我们了解一下大工的这个词库
中文情感词汇本体库介绍
中文情感词汇本体库是大连理工大学信息检索研究室在林鸿飞教授的指导下经过全体 教研室成员的努力整理和标注的一个中文本体资源。该资源从不同角度描述一个中文词汇或 者短语,包括词语词性种类、情感类别、情感强度及极性等信息。
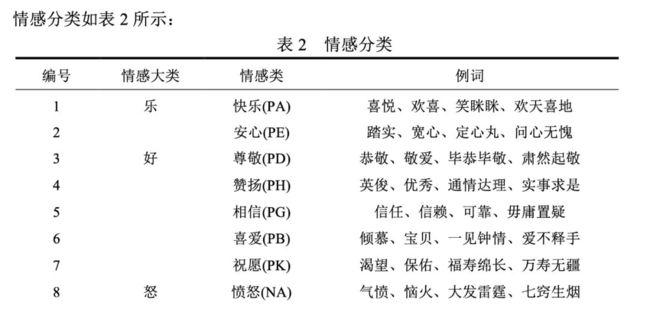
中文情感词汇本体的情感分类体系是在国外比较有影响的 Ekman 的 6 大类情感分类体 系的基础上构建的。在 Ekman 的基础上,词汇本体加入情感类别“好”对褒义情感进行了 更细致的划分。最终词汇本体中的情感共分为 7 大类 21 小类。
构造该资源的宗旨是在情感计算领域,为中文文本情感分析和倾向性分析提供一个便捷 可靠的辅助手段。中文情感词汇本体可以用于解决多类别情感分类的问题,同时也可以用于 解决一般的倾向性分析的问题。
本体格式
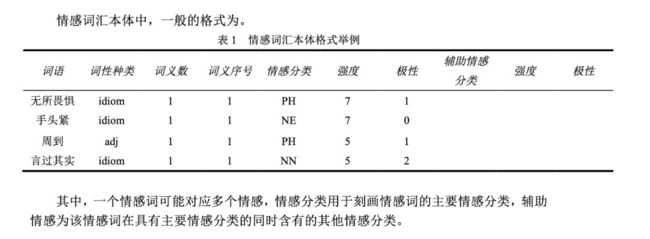
情感分类按照论文《情感词汇本体的构造》所述,情感分为 7 大类 21 小类。情感强度分为 1,3,5,7,9 五档,9 表示强度最大,1 为强度最小。
情感分类及情感强度

词性种类
情感词汇本体中的词性种类一共分为 7 类,分别是
名词(noun)
动词(verb)
形容词 (adj)
副词(adv)
网络词语(nw)
成语(idiom)
介词短语(prep)
词性标注
每个词在每一类情感下都对应了一个极性。其中,0 代表中性,1 代表褒义,2 代表贬 义,3 代表兼有褒贬两性。
注:褒贬标注时,通过词本身和情感共同确定,所以有些情感在一些词中可能极性 1, 而其他的词中有可能极性为 0。
存储格式及规模
中文情感本体以 excel 的格式进行存储,共含有情感词共计 27466 个,文件大小为 1.22M。
本体库词典使用
读取
import pandas as pd
df = pd.read_excel('大连理工大学中文情感词汇本体.xlsx')
df.head(10)
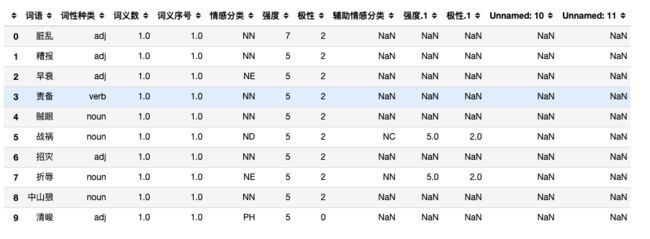
我们暂时只使用 ['词语','词性种类','词义数','词义序号','情感分类','强度','极性']
df = df[['词语', '词性种类', '词义数', '词义序号', '情感分类', '强度', '极性']]
df.head()

情绪词语列表整理完成
按照七大情绪划分
Happy = []
Good = []
Surprise = []
Anger = []
Sad = []
Fear = []
Disgust = []
for idx, row in df.iterrows():
if row['情感分类'] in ['PA', 'PE']:
Happy.append(row['词语'])
if row['情感分类'] in ['PD', 'PH', 'PG', 'PB', 'PK']:
Good.append(row['词语'])
if row['情感分类'] in ['PC']:
Surprise.append(row['词语'])
if row['情感分类'] in ['NA']:
Anger.append(row['词语'])
if row['情感分类'] in ['NB', 'NJ', 'NH', 'PF']:
Sad.append(row['词语'])
if row['情感分类'] in ['NI', 'NC', 'NG']:
Fear.append(row['词语'])
if row['情感分类'] in ['NE', 'ND', 'NN', 'NK', 'NL']:
Disgust.append(row['词语'])
Positive = Happy + Good +Surprise
Negative = Anger + Sad + Fear + Disgust
print('情绪词语列表整理完成')
情绪词语列表整理完成
计情绪计算函数
这里只是朴素的使用情绪词计数统计文本的情绪值
import jieba
import time
def emotion_caculate(text):
positive = 0
negative = 0
anger = 0
disgust = 0
fear = 0
sad = 0
surprise = 0
good = 0
happy = 0
wordlist = jieba.lcut(text)
wordset = set(wordlist)
wordfreq = []
for word in wordset:
freq = wordlist.count(word)
if word in Positive:
positive+=freq
if word in Negative:
negative+=freq
if word in Anger:
anger+=freq
if word in Disgust:
disgust+=freq
if word in Fear:
fear+=freq
if word in Sad:
sad+=freq
if word in Surprise:
surprise+=freq
if word in Good:
good+=freq
if word in Happy:
happy+=freq
emotion_info = {
'length':len(wordlist),
'positive': positive,
'negative': negative,
'anger': anger,
'disgust': disgust,
'fear':fear,
'good':good,
'sadness':sad,
'surprise':surprise,
'happy':happy,
}
indexs = ['length', 'positive', 'negative', 'anger', 'disgust','fear','sadness','surprise', 'good', 'happy']
return pd.Series(emotion_info, index=indexs)
emotion_caculate(text='这个国家再对这些制造假冒伪劣食品药品的人手软的话,那后果真的会相当糟糕。坐牢?从快判个死刑')
length 25
positive 0
negative 4
anger 0
disgust 4
fear 0
sadness 0
surprise 0
good 0
happy 0
dtype: int64
并行加速计算过程
在本文中的情绪计算特别耗时间,测试数据相比昨天少了一大半,使用df.apply依旧很慢,没办法这里需要使用pandarallel并行加速库。多核处理速度快
!pip3 install pandarallel
开始计算
from pandarallel import pandarallel
#并行初始化
pandarallel.initialize()
start = time.time()
emotion_df = weibo_df['review'].parallel_apply(emotion_caculate)
#emotion_df = weibo_df['review'].apply(emotion_caculate)
end = time.time()
print(end-start)
emotion_df.head()

series数据变为dataframe,详情可了解下apply http://dwz.date/dzB
输出分析结果
将原始数据与分析结果合并, 输出到新的csv中。
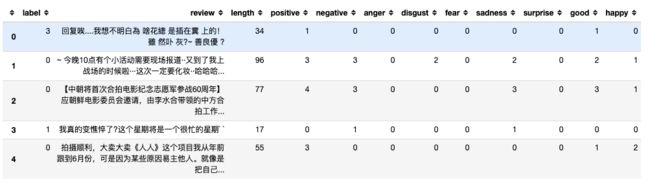
output_df = pd.concat([weibo_df, emotion_df], axis=1)
output_df.to_csv('output.csv', index=False)
output_df.head()
检查
我们查看一下随机抽查一下,看看
最fear
最positive
最negative 的分别是什么内容
fear = output_df.sort_values(by='fear',ascending=False)
fear.head()
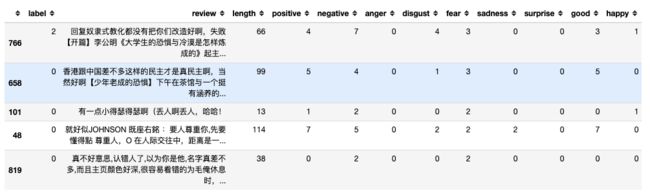
最fear
fear = output_df.sort_values(by='fear',ascending=False)
print(fear.iloc[0, :]['review'])
Run
回复奴隶式教化都没有把你们改造好啊,失败【开篇】
李公明《大学生的恐惧与冷漠是怎样炼成的》起主要作用的倒不是冷漠,而是恐惧,
有关眼下利益(各种奖学金等等)与未来(就业等等)的恐惧。
这时候长期以来的奴化教育自然会显示其功能。
最负面
negative = output_df.sort_values(by='negative',ascending=False)
print(negative.iloc[0, :]['review'])
Run
回复菜鸟已经被宰掉鸟啊呀,错过鸟,错过鸟!什么事?
围观,围观他们在造谣,不要脸的无耻之徒好了,SB 都进垃圾箱了一会儿就车去焚烧炉了按照某些人的逻辑。
你说句成语,你得注明出处,否则就是抄袭。按照某些人的逻辑,你写,某某说。。。
你也是抄袭,我真莫名了,别人不也是转某人的话的吗?为什么别人不是抄袭!
所以,那些人就是在发泄私愤,完全是没有逻辑的小人!傻逼!!!!牛鬼蛇神!!!!!!!!
最正面
positive = output_df.sort_values(by='positive',ascending=False)
print(positive.iloc[0, :]['review'])
Run
彼岸的Blue: 对,这才是喜欢一个人的态度。。。
喜欢一个人不是要疯狂的追逐,而是要站在正确的位置关心他,爱护他,小哇,真心的为你祝福,
希望你永远健康、开心、快乐,享受你所享受的,爱你所爱的,善良的人,一生幸福,平安。。。真心的为你祝福顶
分析结束
Tips:
以上的案例只是简单的使用了大连理工大学中文情感词汇本体库, 用最朴素的统计情绪词的个数作为情绪值的度量方法。
其实中文情感词汇本体库每个词语还有权重和极性,上面的方法有些粗糙。
各位如果要使用,需要多学习pandas的知识点,自己diy适用于自己场景的情绪计算函数。
近期文章
Python数据采集与文本分析(学术)
2020年B站跨年晚会弹幕内容分析
综述:文本分析在市场营销研究中的应用
NRC词语情绪词典和词语色彩词典
如何对微博推文进行情绪分析(细粒度情感分析)
Lazy Prices公司年报内容变动碰上股价偷懒
使用pandas做数据可视化
用statsmodels库做计量分析
YelpDaset: 酒店管理类数据集10+G
Loughran&McDonald金融文本情感分析库
股评师分析报告文本情感分析预测股价
使用分析师报告中含有的情感信息预测上市公司股价变动
【公开视频课】Python语法快速入门
【公开视频课】Python爬虫快速入门
一行pandas代码生成哑变量
使用Python读取图片中的文本数据
代码不到40行的超燃动态排序图
jupyter notebook代码获取方式,公众号后台回复关键词“20200108”