使用Python转换PDF,Word/Excel/PPT/md/HTML都能转!
今天讲的是各位一定会接触到的PDF转换,关于各种格式的文件转换为PDF有很多第三方工具与网站可以实现,但是使用Python的好处不仅可以批量转换,同时一旦脚本写完了以后就可以一键执行,彻底解放双手,那么本文就来盘一盘如何使用Python来将Word/Excel/PPT/Markdown/Html等各种格式的文件转换为PDF!
Word转PDF
Word转PDF应该是最常见的需求了,毕竟使用PDF格式可以更方便展示文档,虽然在Word中可以直接导出为PDF格式,但是使用Python可以批量转换,更加高效。
目前在Python中针对Word转换为PDF的库有很多,比如win32就可以调用word底层vba,将word转成pdf,或者comtypes等,但是这些常用的库仅能在Windows机器上运行,所以为了照顾mac用户本文使用一个比较小众的库docx2pdf,看名字就能知道这是专门用于word转pdf,安装很简单
pip install docx2pdf使用也比win32等库更简洁,一行代码导入一行代码转换即可
from docx2pdf import convert
convert("input.docx", "output.pdf")但是有人就会说虽然简单,但是这个操作word本身就可以完成,好的接下来放大招,我们可以使用下面的代码找到当前或者指定文件夹下的全部word文件
#查找当前目录下的全部word文件
import os
import glob
from pathlib import Path
path = os.getcwd() + '/'
p = Path(path) #初始化构造Path对象
FileList=list(p.glob("**/*.docx")) 
接下来只要写一个循环就可以将该目录下的全部word一次性转换为PDF
for file in FileList:
convert(file,f"{file}.pdf")就这样,不到10行代码,只要一秒,指定文件夹中5份Word就轻松转换为PDF,现在还能使用我们之前自动化系列文章写过的批量合并PDF结合一键合并这5份PDF!
Excel转PDF
Excel转PDF可能平时用的不多,但是作为Office全家桶中的重要工具,并且转换完的表格可以复制所以我们也讲一下。使用到的工具既不是常用的openpyxl也不是pandas,而是另一个专门用于处理PDF的库fpdf
import pandas as pd
import numpy as np
df_1 = pd.DataFrame(np.random.randn(10, 2), columns=list('AB'))为了方便讲解我们使用Pandas和NumPy来创建一个示例数据文件,当然也可以使用从本地读取

现在可以使用下面的代码将这个表格转换为PDF
from fpdf import FPDF
pdf = FPDF()
pdf.add_page()
pdf.set_xy(0, 0)
pdf.set_font('arial', 'B', 14)
pdf.cell(60)
pdf.cell(70, 10, 'Excel to PDF', 0, 2, 'C')
pdf.cell(-40)
pdf.cell(50, 10, 'Index Column', 1, 0, 'C')
pdf.cell(40, 10, 'A', 1, 0, 'C')
pdf.cell(40, 10, 'B', 1, 2, 'C')
pdf.cell(-90)
pdf.set_font('arial', '', 12)
for i in range(0, len(df_1)):
col_ind = str(i)
col_a = str(df_1.A.iloc[i])
col_b = str(df_1.B.iloc[i])
pdf.cell(50, 10, '%s' % (col_ind), 1, 0, 'C')
pdf.cell(40, 10, '%s' % (col_a), 0, 0, 'C')
pdf.cell(40, 10, '%s' % (col_b), 0, 2, 'C')
pdf.cell(-90)
pdf.output('Excel2PDF.pdf', 'F')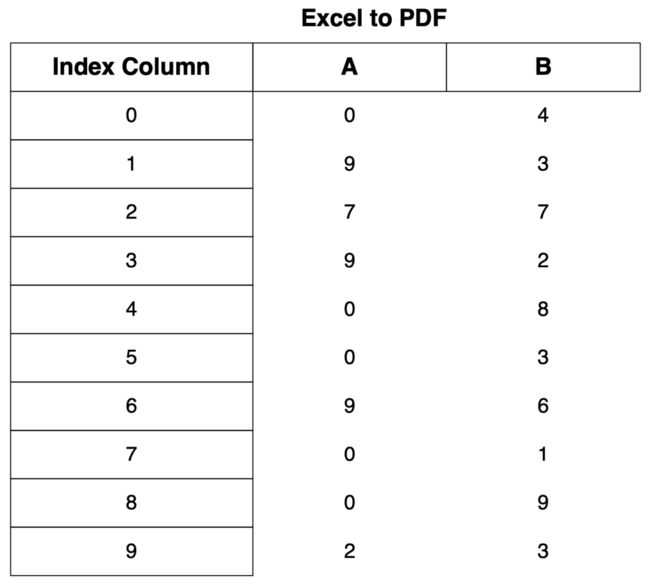
,其实思路和openpyxl类似,遍历每一个单元格并写入数据,只不过现在是往PDF文件中写入。
PPT转PDF
本节介绍一下PPT如何转换为PDF,但是我搜了一大圈都没有MAC用户可以实现的方法,所以只能针对Windows去操作,使用到的就是在word2pdf中讲到的comtypes
import sys
import os
import comtypes.client
#设置路径
input_file_path = sys.argv[1]
output_file_path = sys.argv[2]
input_file_path = os.path.abspath(input_file_path)
output_file_path = os.path.abspath(output_file_path)
#创建PDF
powerpoint = comtypes.client.CreateObject("Powerpoint.Application")
powerpoint.Visible = 1
slides = powerpoint.Presentations.Open(input_file_path)
#保存PDF
slides.SaveAs(output_file_path, 32)
slides.Close()相关参数与细节可以查阅comtypes官方文档,因为我是mac所以没有过多研究,在成功转换之后就可以和我们之前的批量操作与合并进行结合实现自动化了!
md转pdf
关于markdown转pdf,几乎所有markdown编辑器都支持导出为pdf格式,本以为这个需求并不高,但是研究了一圈发现很多老外造了很多md转pdf的轮子,比如md2pdf、markdown2pdf、md2pdf-client等。因为大多数博客使用的是markdown格式,使用这些库可以很好的将博客文章批量转换为PDF文档存储。
早起都试了一圈,找到一个语法最简单的markdown2pdf3,直接pip安装即可,使用两行代码即可将一个md文件转换为pdf
from markdown2pdf3 import *
convert_markdown_to_pdf('test.md') #你的markdown文件路径但是要注意的是如果有中文,还需要进行一些额外的设置,可以查阅官方文档,不过现在就能和之前讲的Word转PDF结合,批量转换指定路径下的全部markdown文件为pdf,比如可以使用下面的代码找到当前文件夹下的全部md文件
import os
import glob
from pathlib import Path
path = os.getcwd() + '/'
p = Path(path) #初始化构造Path对象
FileList=list(p.glob("**/*.md")) html转pdf
关于html也就是网页转为PDF是来问我最多的问题,其实很简单,之前在Selenium爬取公众号全部文章这篇文章中就提到使用PDFKIT即可,但是并不是直接pip安装pdfkit就行,我们需要提前进入下面的网站选择自己电脑系统对应的wkhtmltopdf下载安装
https://wkhtmltopdf.org/downloads.html
安装完使用pip安装pdfkit
pip install pdfkit现在我们就能使用两行代码转换指定网页为PDF格式,比如将我的第一篇自动化文章转为PDF
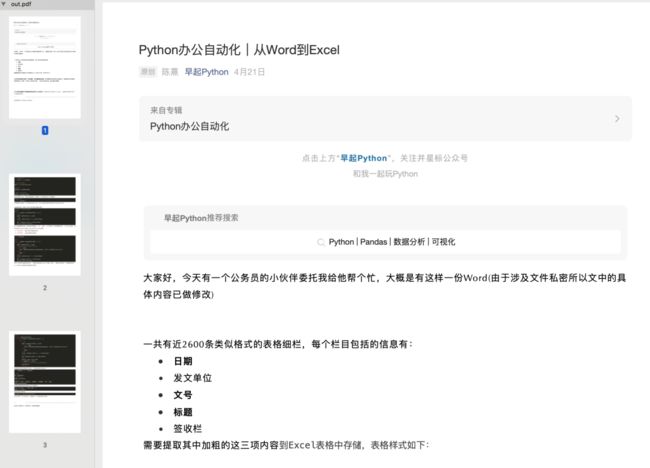

看起来效果还是非常好的,所有格式包括代码都完整的保存了下来,接下来怎么做就不用我多说了,比如你想下载一个公众号所有文章为PDF格式,那就先将历史文章URL提取出来,接着使用pdfkit转换即可,而这两步骤我们都已经详细讲解过了!
