FPN(特征图金字塔网络)理论基础与具体实现
我们在做目标检测和超分辨率重建等问题的时候,我们一般是对同一个尺寸的图片进行网络训练。我们希望我们的网络能够适应更多尺寸的图片,我们传统的做法使用图像金字塔,但是这种做法从侧面提升了计算的复杂度,我们希望可以改善这个问题,所以本文就提出了一种在特征图金字塔的方法,我们称这种网络结构叫做FPN。
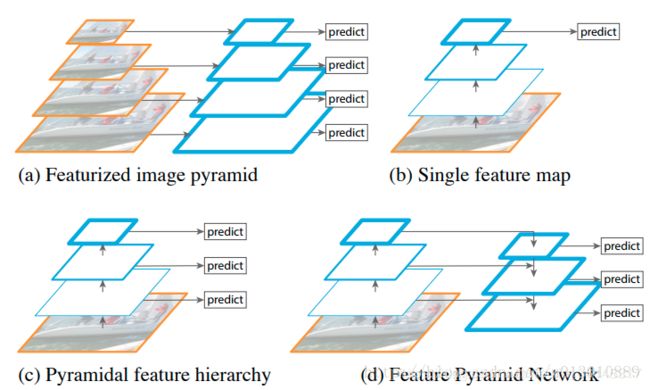
SSD的做法,在不同尺度的feature map 上做检测, 按理说它该在计算好的不同scale的feature map上做检测,但是它放弃了前面的low-level的featrue map, 而是从conv4_3开始用而且在后面加了一些conv, 生成更多高层语义的feature map在上面检测(个人猜想是因为这些low-level的featrue map一是太大了很大地拖慢ssd最追求的速度,而是这些low-level语义信息太差了,效果没多大提升).
如何即利用conv net本省的这种已经计算过的不同scale 的feature, 又想让low-level的高分辨率的feature具有很强的语义,所以自然的想法就是把high-level的低分辨率的feature map 融合过来.
方法:
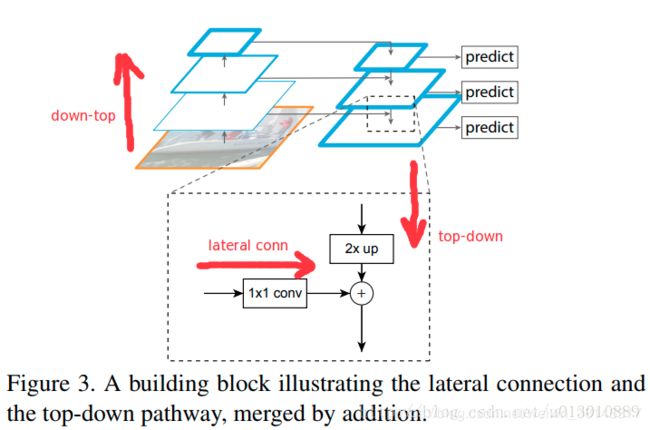
做法比较简单, down-top, top-down, lateral conn(侧路连接)如下图所示,以resnet101为例
1. down-top 就是每个residual block(c1 去掉了, 太大太耗内存了), scale缩小2,c2, c3, c4, c5,(1/4, 1/8, 1/16, 1/32)
2. top-down就是把每层的低分辨率语义的feature最近邻上采样2x(上采样就是放大图像, 下采样就是缩小图像)
3. lateral conn比如把c2通过1x1卷积调整channel和top-down过来的一样,然后两者直接相加,
通过上述操作,一直迭代到生成最好分辨率的feature(此处指c2)
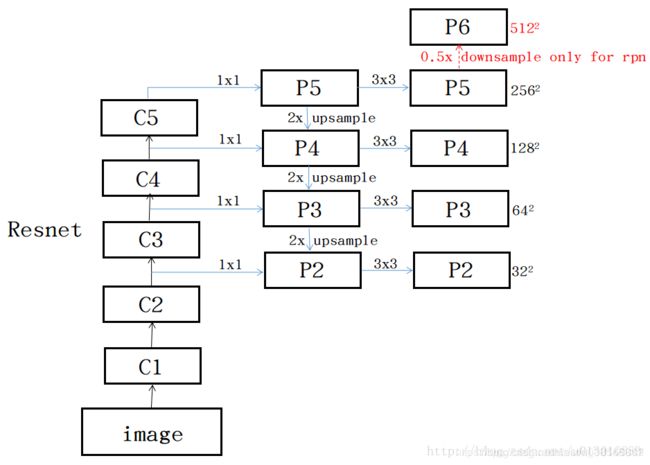
具体迭代操作
1.从c5(512)开始加个1*1到256个channel, 生成分辨率最低但语义最强的feature p5, 开始迭代,
2. 然后p5上采样放大2倍,c4经过一个1*1*256的卷即后和放大后p5尺寸什么都一样了,然后add
3.以此迭代下去到p2结束
4. 每个p层之后加一个3*3的卷积,可以减小上采样的混叠效果
P5 = keras.layers.Conv2D(feature_size, kernel_size=1, strides=1, padding='same', name='C5_reduced')(C5)
#P5:(?, ?, ?, 256) C4:(?, ?, ?, 1024),这里P5, C4的维度一样吗?
P5_upsampled = layers.UpsampleLike(name='P5_upsampled')([P5, C4])#把P5的尺寸resize到与C4的尺寸一样,
# 比如若p5=(?,230,230,256) # ,C4:(?, 416, 416, 1024),则会把p5缩放成(?, 416, 416, 256)
#P5_upsampled (?, ?, ?, 256)
P5 = keras.layers.Conv2D(feature_size, kernel_size=3, strides=1, padding='same', name='P5')(P5)
# add P5 elementwise to C4
P4 = keras.layers.Conv2D(feature_size, kernel_size=1, strides=1, padding='same', name='C4_reduced')(C4)
P4 = keras.layers.Add(name='P4_merged')([P5_upsampled, P4])
P4 = keras.layers.Conv2D(feature_size, kernel_size=3, strides=1, padding='same', name='P4')(P4)