mysql 视图、触发器、存储过程、游标、存储函数、物化视图
视图
定义: 视图是一种简单的数据查询机制,可以理解为数据库的虚拟表并由查询语句定义其内容,视图并不在数据库中以存储的数据值集形式存在,因此不用担心视图会充满磁盘空间。
实战:
假设test表,字段有id,name,age,sex,height等。
//创建视图
create view view-test ( a,b,c...) as select A,B,C... from test;
//调用视图
select * from view-test ;
//查询有哪些视图
show tables;
show tables like '%viewname%'
show table status where comment='view';
select * from information_schema.TABLES where TABLE_TYPE='view'
优点:
1:简化sql操作;
2:提高数据库安全性,通过视图可以限制不同用户只可以查询特定数据;
3:数据库重构时,不影响程序的操作。
缺点
1: 从性能上说,是不会提高查询速度的,但可能从数据库视图查询数据会很慢,特别是当前视图是基于其他视图创建的。
2:表依赖关系,每当更改与视图相关联的表的结构时,都必须更改视图。
注意 想一想,子查询和视图机制是不是有些像;例如:
//子查询
select * from (select id,name from test where id>20) as childtest;
//视图
create view view-test as select id,name from test where id>20;
select * from view-test ;
触发器
定义: 触发器,也叫触发程序,是与表有关的命名数据库对象。触发器是个特殊的存储过程,但是触发器不需要CALL语句调用,也不需要手动启动。它由事件触发,事件包括INSERT,UPDATE和DELETE语句,当表中出现这些特定事件时,将激活该对象 。
实战:
// 单个执行语句的触发器语法结构:
CREATE TRIGGER [触发器名称] [触发时机(before,after) ] [触发事件
(INSERT,UPDATE和DELETE) ] ON [建立触发器的表名] FOR EACH ROW
[触发器执行语句];
// 多个执行语句的触发器语法结构:
CREATE TRIGGER [触发器名称] [触发时机(before,after)] [触发事件
(INSERT,UPDATE和DELETE)] ON [建立触发器的表名] FOR EACH ROW
BEGIN
触发器执行语句;
END;
//删除触发器
drop trigger trigger-name;
//查看触发器
show triggers like '%trigger-name%';
show triggers;
存储过程
定义: 一组可编程的函数,是为了完成特定功能的SQL语句集,经编译创建并保存在数据库中,用户可通过CALL指定存储过程的名字并给定参数(需要时)来调用执行。
所以调用存储过程就是调用编译过的sql语句。
创建的存储过程保存在数据库的数据字典中。
存储过程中可以使用索引,事务等。
实战
//创建存储过程
CREATE
[DEFINER = { user | CURRENT_USER }]
PROCEDURE sp_name ([proc_parameter[,...]])
[characteristic ...] routine_body
proc_parameter:
[ IN | OUT | INOUT ] param_name type
characteristic:
COMMENT 'string'
| LANGUAGE SQL
| [NOT] DETERMINISTIC
| { CONTAINS SQL | NO SQL | READS SQL DATA | MODIFIES SQL DATA }
| SQL SECURITY { DEFINER | INVOKER }
routine_body:
Valid SQL routine statement
[begin_label:] BEGIN
[statement_list]
……
END [end_label]
//删除
drop procedure sp_name;
//调用
call sp_name(参数);
//查看
show procedure status
这里要注意的就是参数的传递、定义,使用。参考文章
三种类型的参数:in 、out 、inout。
传参: 加@符号时,表示该参数名(变量名)共用一个内存空间,类似php的引用。
例子:
这是一个向数据库刷10000条数据数据的存储过程。
CREATE PROCEDURE pro_test()
BEGIN
SET i=1;//定义局部变量
WHILE i<=10000 DO
insert into test(id,name) values (i,concat("user",i));
SET i=i+1;
END WHILE;
END
call pro_test();
优缺点:
优点:
1:执行速度快,因为每个sql语句都是预编译的,不需要编译了,注意这里是执行速度快,存储过程并不加快查询速度。
2:降低网络流量,在程序执行与数据库交互时,传输一个存储过程比传输大量sql语句开销小很多,特别是进行“跑批”时。
3:提高系统安全性,存储过程可以与数据库用户绑定,从而进行权限控制,通过mysql.proc表 的definer字段实现,另外参数化的存储过程可以有效防止sql注入。
4:降低程序与数据库的耦合性,即数据库表结构改变时,只需修改存储过程,不需要动java/php/python代码。
缺点:
1:难以调试扩展,并且移植性差,这是阿里巴巴开发文件中明确指明的。具体如下:参考文章为什么阿里巴巴Java开发手册里要求禁止使用存储过程?。
调试:线上调试一般就是打日志,在应用层,日志可以在任何一步打,但是存储过程的话,日志没法跟踪详细的执行过程。
扩展:譬如你的 产品购买流程 要增加一个动作,这时候就要修改存储过程到db里,你这时候要直接操作db,而在大公司,直接操作db只能有dba来进行,其他都要审批后使用公司自己开发的工作来进行,且只能是简单的crud。
移植:你用mysql写的存储过程,到了sqlserver不一定能直接用。但是在应用层的话,程序里的crud的基础sql基本上通用的,修改下连接串一般就ok了。
2:优势不明显和赘余功能,对于小型web应用来说,直接使用sql语句开销并不大,并且可以利用mysql的查询缓存,存储过程无法使用缓存。另外存储过程还需要检查权限一类的开销,这些赘余功能一定程度上拖累性能。
游标
定义: 游标的作用就是用于对查询数据库所返回的结果集进行遍历,以便进行相应的操作,每次只取一行。
使用方法
一、声明一个游标: declare 【游标名称】 CURSOR for table;(这里的table可以是你查询出来的任意集合)
二、打开定义的游标:open 游标名称;
三、获得下一行数据:FETCH 游标名称 into testrangeid,versionid;
四、需要执行的语句(增删改查):这里视具体情况而定
五、释放游标:CLOSE 游标名称;
例子:
begin
//定义变量
declare test_id BIGINT;
declare test_age BIGINT;
declare flag int default 0; //标志位
//创建游标,并存储数据
declare cur_test cursor for
select id,age from test where id>20;
//游标中的内容执行完后将flag设置为1 ,避免游标陷入死循环
DECLARE CONTINUE HANDLER FOR NOT FOUND SET flag=1;
//打开游标
open cur_test;
//执行循环
posLoop:LOOP
//判断是否结束循环
IF flag=1 THEN
LEAVE posLoop;
END IF;
//取游标中的值
FETCH cur_test into test_id,test_age;
//执行更新操作
IF test_age>20 THEN
update test set age=test_age+1 where id = test_id;
END IF;
END LOOP posLoop;
//释放游标
CLOSE cur_test;
特点:
游标主要用在循环处理、存储过程、存储函数中使用。
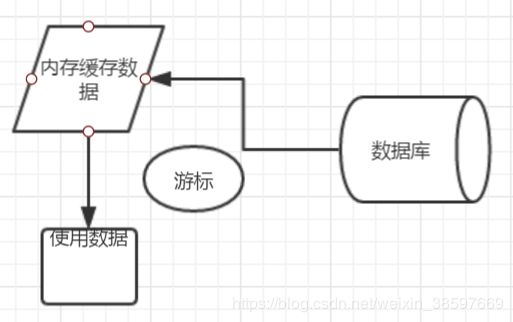
如图,游标工作机制,将数据临时放到内存中,再从中读出来进行数据使用,可以看到数据太多(可能内存不足)游标就不适合了。
存储函数
概况: 存储函数和存储过程类似,即 封装一段sql代码,完成一种特定的功能,返回结果,但也有不同的地方,本人不是数据库开发工程师,了解不多,用的不多,就不做过多介绍了,具体参考文章。
物化视图
定义: 在SqlServer和oracle中物化视图功能很好的被实现,Mysql目前还没有该功能,这里要强调的是物化视图是相对于视图而言的,但是两者实际上并没有什么关系,就如java/javaScript一样。
物化视图可以理解为是一张实际的表,帮助记录要查询的结果,这样查询物化视图即可。
使用场景: 一般在聚合函数或进行统计时为了提升查询效率使用。
一般结合存储过程,触发器使用。
对于实时性高的统计数据:用触发器完成,但开销大。
对于实时性不高的统计数据:可以设置定时任务来完成。
具体使用要结合项目实际情况。
查看数据库状态
查询数据库中的存储过程和函数
select `name` from mysql.proc where db = 'xx' and `type` = 'PROCEDURE' //存储过程
select `name` from mysql.proc where db = 'xx' and `type` = 'FUNCTION' //函数
show procedure status; //存储过程
show function status; //函数
查看存储过程或函数的创建代码
show create procedure proc_name;
show create function func_name;
查看视图
SELECT * from information_schema.VIEWS //视图
SELECT * from information_schema.TABLES //表
查看触发器
SHOW TRIGGERS [FROM db_name] [LIKE expr]
SELECT * FROM triggers T WHERE trigger_name=”mytrigger” \G