【Python3实战Spark大数据分析及调度】第13章 项目实战
企业级大数据开发流程


企业级大数据应用
企业级大数据分析平台
目的和分析
获得数据价值
离线和实时
1)商业
2)自研
数据量预估及集群规划
一条日志300~500字节,一天1000w访问量,一个人访问5次,每天访问5个页面

DN:DataNode数量
NN:NameNode数量
RM:ResourceManager数量
NM:NodeManager数量
ZK:ZooKeeper数量
GATEWAY:提交作业到集群

资源设置:
cpu:32core
memory:250g
disk:几十个T
network:万兆网卡
项目需求
使用PySpark分析空气质量

数据样例:
空气质量指标

数据分析后健康与否的结果写入es中,最后使用kibana展示
功能实现
发现出了问题,在列名上
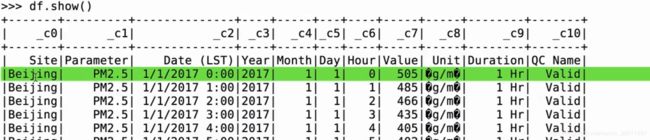
设置头部信息为true
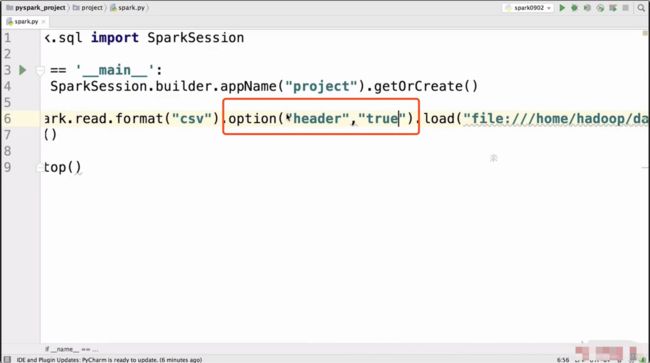
又有了问题,将我们所有的数据类型都设置成了String

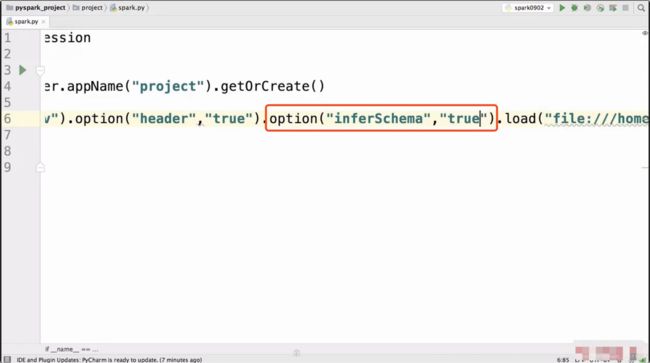
添加自动推导数据类型
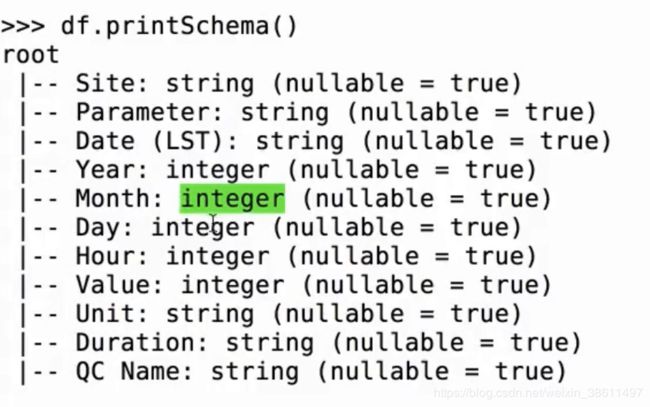
已经自动转换了数据类型
只使用部分的列

写一个空气指数转换健康程度的函数
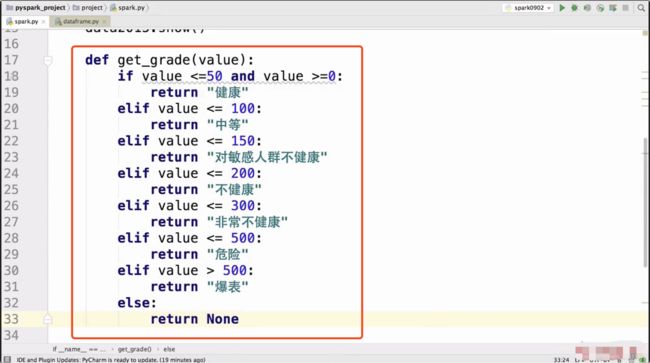
尝试增加一个列表示空气质量的好坏

报错

需要使用udf函数进行转换
导入udf

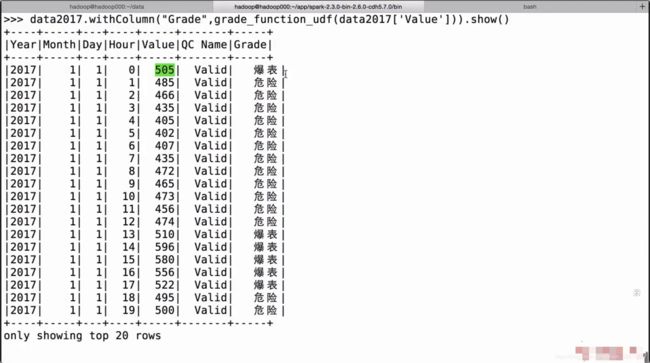
使用udf对get_grade进行封装

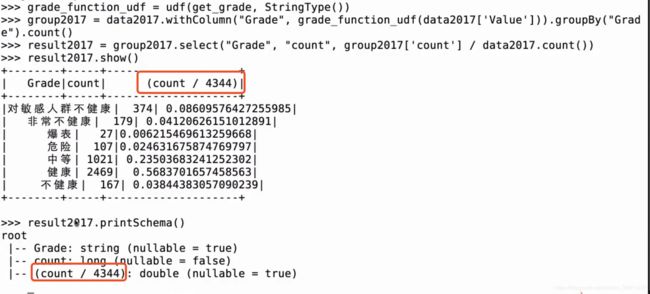
结果如下:
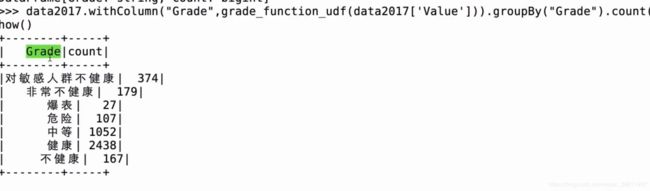
groupby + count 统计各个类型的次数

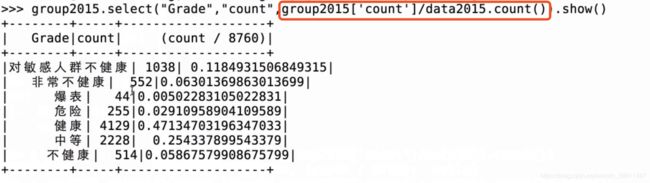
查看各个类型在全年中的占比情况
下面需要把分析得到的数据导入es后用kibana展示出来
ElasticSearch & Kibana
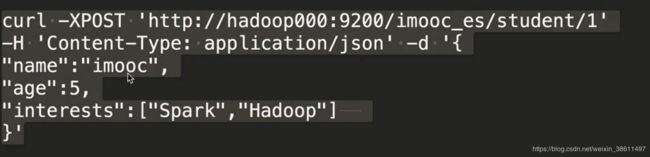
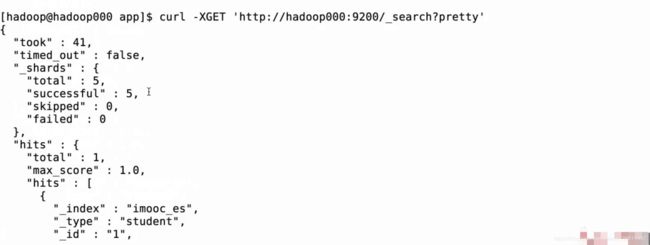
向es中添加数据
![]()
![]()
添加一名学生

Kibana部分
在配置文件中可以直接配置连接的es
![]()
可以直接在es中进行查询

使用kibana查询es中的数据需要添加es索引
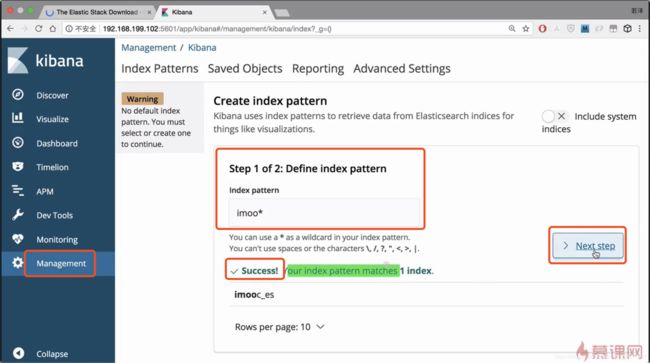

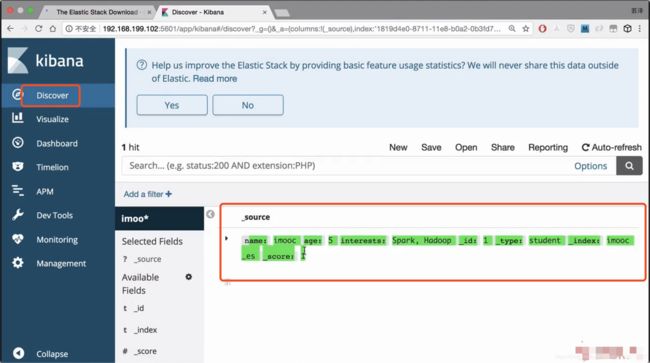
在Discover中就可以看到索引下的数据
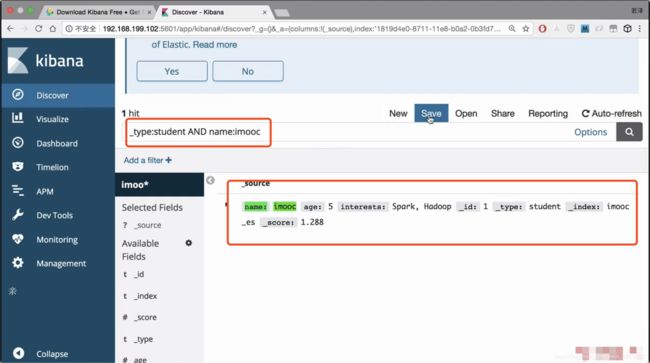
进行查询试验
sparkyarn.py
from pyspark.sql import SparkSession
from pyspark.sql.types import *
from pyspark.sql.functions import udf
def get_grade(value):
if value <= 50 and value >= 0:
return "健康"
elif value <= 100:
return "中等"
elif value <= 150:
return "对敏感人群不健康"
elif value <= 200:
return "不健康"
elif value <= 300:
return "非常不健康"
elif value <= 500:
return "危险"
elif value > 500:
return "爆表"
else:
return None
if __name__ == '__main__':
spark = SparkSession.builder.appName("project").getOrCreate()
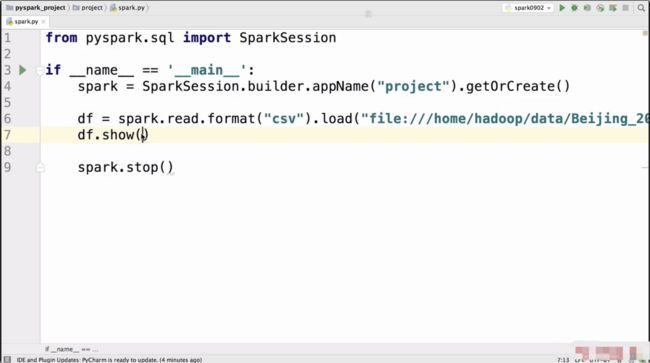
df = spark.read.format("csv").option("header","true").option("inferSchema","true").load("file:///home/hadoop/data/Beijing_2017_HourlyPM25_created20170803.csv")
df.select("Year","Month","Day","Hour","Value","QC Name").show()
data2017 = spark.read.format("csv").option("header","true").option("inferSchema","true").load("file:///home/hadoop/data/Beijing_2017_HourlyPM25_created20170803.csv").select("Year","Month","Day","Hour","Value","QC Name")
data2016 = spark.read.format("csv").option("header","true").option("inferSchema","true").load("file:///home/hadoop/data/Beijing_2016_HourlyPM25_created20170201.csv").select("Year","Month","Day","Hour","Value","QC Name")
data2015 = spark.read.format("csv").option("header","true").option("inferSchema","true").load("file:///home/hadoop/data/Beijing_2015_HourlyPM25_created20160201.csv").select("Year","Month","Day","Hour","Value","QC Name")
data2017.show()
data2016.show()
data2015.show()
grade_function_udf = udf(get_grade(),StringType())
# 进来一个Value,出去一个Grade
group2017 = data2017.withColumn("Grade",grade_function_udf(data2017['Value'])).groupBy("Grade").count()
group2016 = data2016.withColumn("Grade",grade_function_udf(data2016['Value'])).groupBy("Grade").count()
group2015 = data2015.withColumn("Grade",grade_function_udf(data2015['Value'])).groupBy("Grade").count()
group2015.select("Grade", "count", group2015['count'] / data2015.count()).show()
group2016.select("Grade", "count", group2016['count'] / data2016.count()).show()
group2017.select("Grade", "count", group2017['count'] / data2017.count()).show()
group2017.show()
group2016.show()
group2015.show()
df.show()
spark.stop()
将脚本跑在YARN上,通过spark-submit提交
使用Spark SQL 将统计结果写入到ES中
需要使用jar包

这里列名会有这种问题
将数据写入到Spark SQL中

结果,这个列名不方便查看
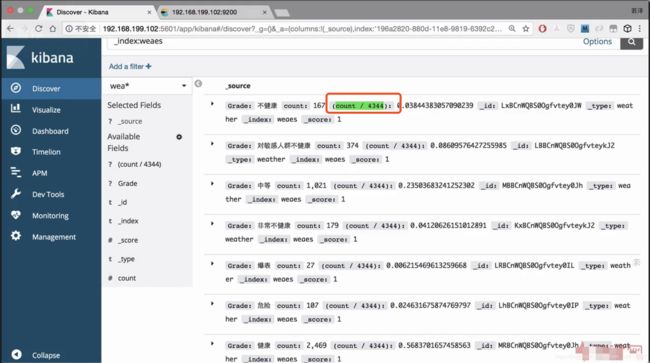
使用withColumn改一下列的名字
![]()
改好了
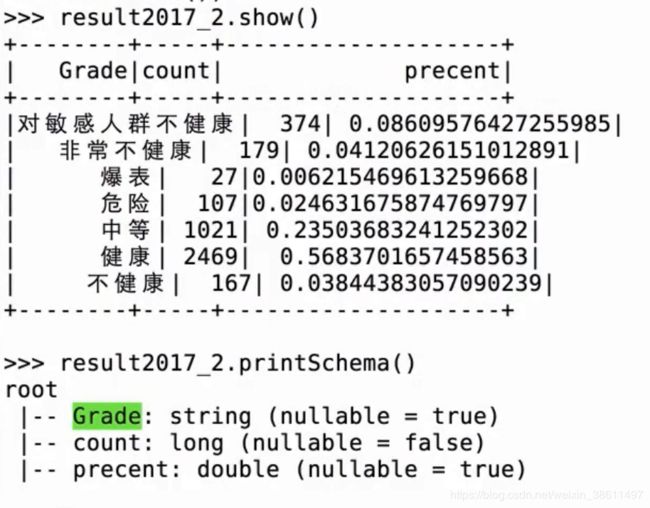
但是Grade我想要grade,改一下大小写

重新导入es,在kibana中展示

将 precent改成百分比重新导入
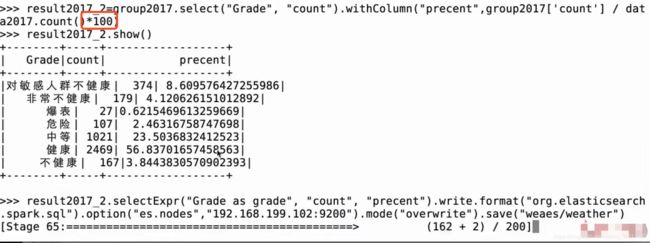

全部代码 wea.py
from pyspark.sql import SparkSession
from pyspark.sql.functions import *
from pyspark.sql.types import *
def get_grade(value):
if value <= 50:
return "健康"
elif value <= 100:
return "中等"
elif value <= 150:
return "对敏感人群不健康"
elif value <= 200:
return "不健康"
elif value <= 300:
return "非常不健康"
elif value <= 500:
return "危险"
elif value > 500:
return "爆表"
else:
return None
if __name__ == '__main__':
spark = SparkSession.builder.appName("project").getOrCreate()
data2017 = spark.read.format("csv").option("header","true").option("inferSchema","true").load("/data/Beijing_2017_HourlyPM25_created20170803.csv").select("Year","Month","Day","Hour","Value","QC Name")
data2016 = spark.read.format("csv").option("header","true").option("inferSchema","true").load("/data/Beijing_2016_HourlyPM25_created20170201.csv").select("Year","Month","Day","Hour","Value","QC Name")
data2015 = spark.read.format("csv").option("header","true").option("inferSchema","true").load("/data/Beijing_2015_HourlyPM25_created20160201.csv").select("Year","Month","Day","Hour","Value","QC Name")
grade_function_udf = udf(get_grade, StringType())
group2017 = data2017.withColumn("Grade", grade_function_udf(data2017['Value'])).groupBy("Grade").count()
group2016 = data2016.withColumn("Grade", grade_function_udf(data2016['Value'])).groupBy("Grade").count()
group2015 = data2015.withColumn("Grade", grade_function_udf(data2015['Value'])).groupBy("Grade").count()
result2017 = group2017.select("Grade", "count").withColumn("precent",group2017['count'] / data2017.count()*100)
result2016 = group2016.select("Grade", "count").withColumn("precent",group2016['count'] / data2016.count()*100)
result2015 = group2015.select("Grade", "count").withColumn("precent",group2015['count'] / data2015.count()*100)
result2017.selectExpr("Grade as grade", "count", "precent").write.format("org.elasticsearch.spark.sql").option("es.nodes","192.168.199.102:9200").mode("overwrite").save("weather2017/pm")
result2016.selectExpr("Grade as grade", "count", "precent").write.format("org.elasticsearch.spark.sql").option("es.nodes","192.168.199.102:9200").mode("overwrite").save("weather2016/pm")
result2015.selectExpr("Grade as grade", "count", "precent").write.format("org.elasticsearch.spark.sql").option("es.nodes","192.168.199.102:9200").mode("overwrite").save("weather2015/pm")
spark.stop()
这回提交到local就可以,还是注意要加上jar
已经全部导入
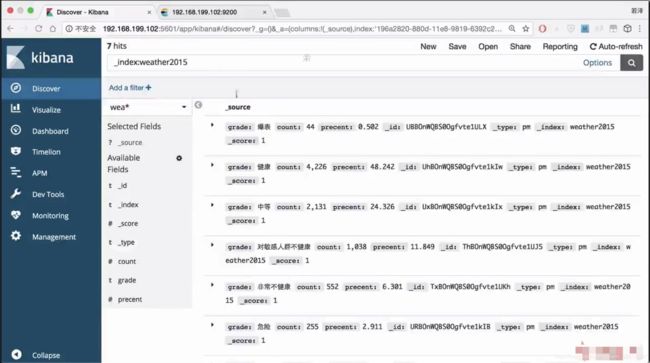
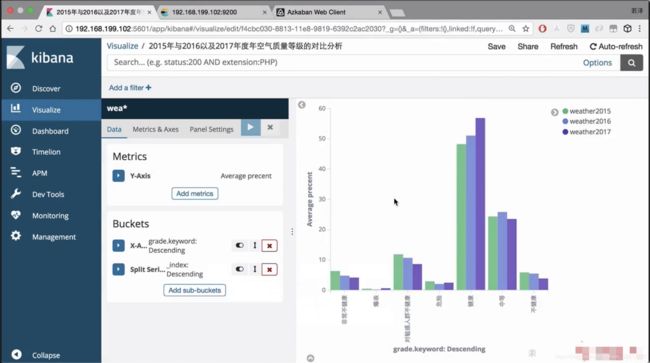
使用kibana进行可视化

选择一个柱状图
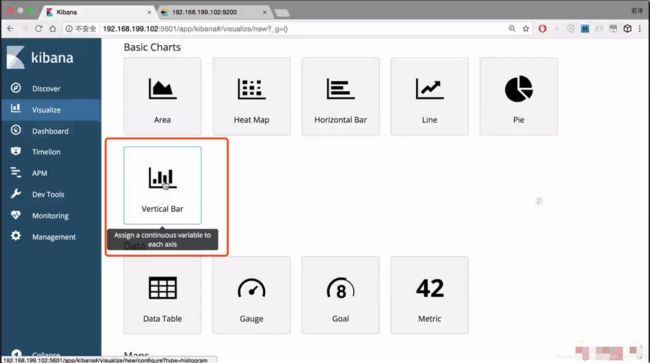
点进去选择索引

添加y轴
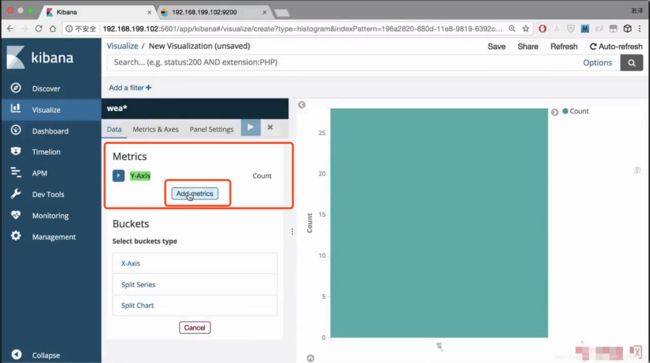
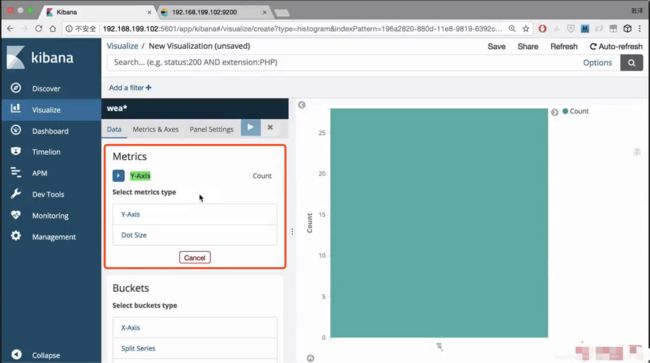
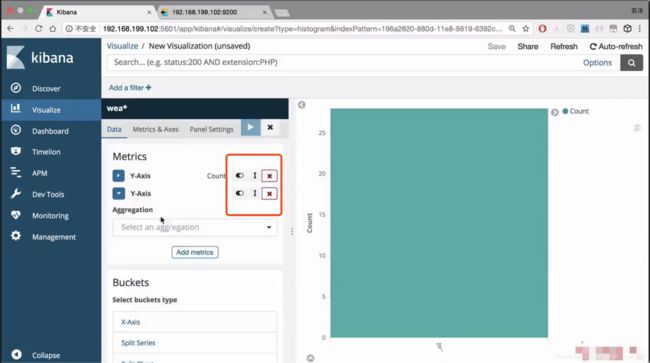

选择x轴
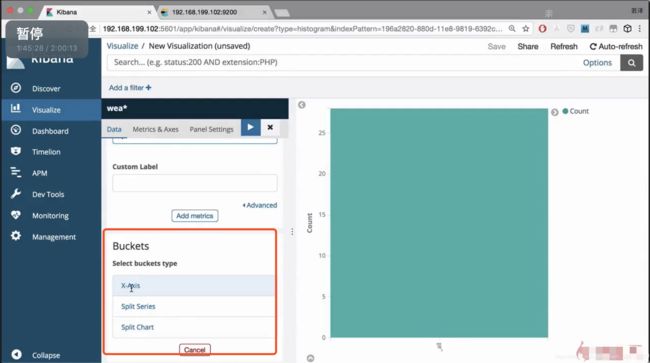


生成图像
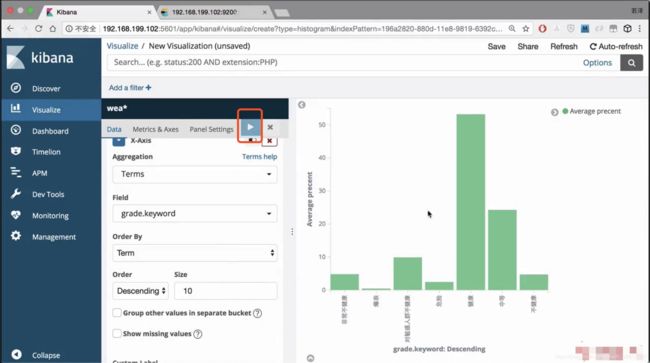
添加子图


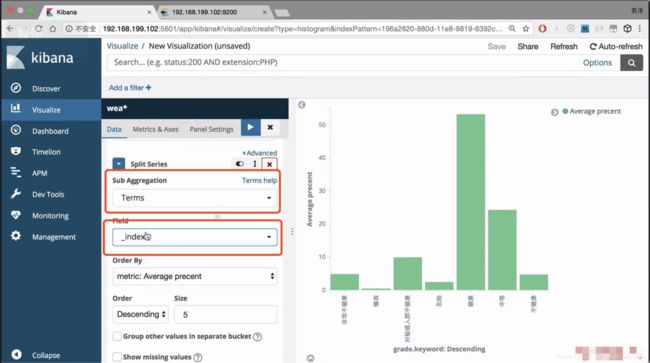
发现多了一个不想要的index,想要进行删除
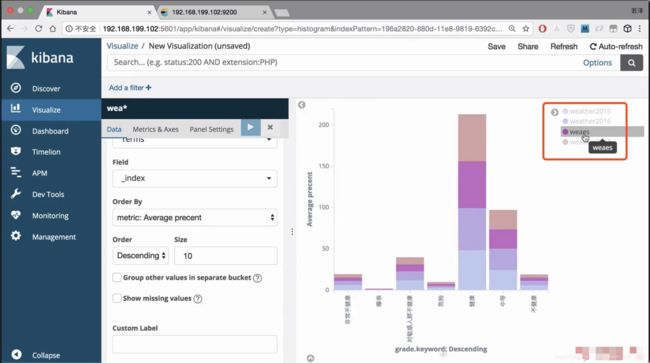
对索引进行删除

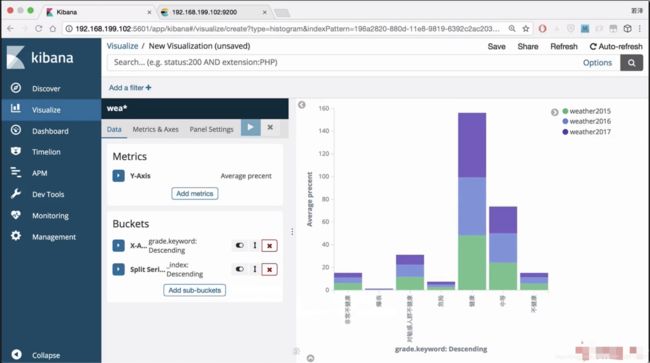
还需要对格式进行调整,变成横向的
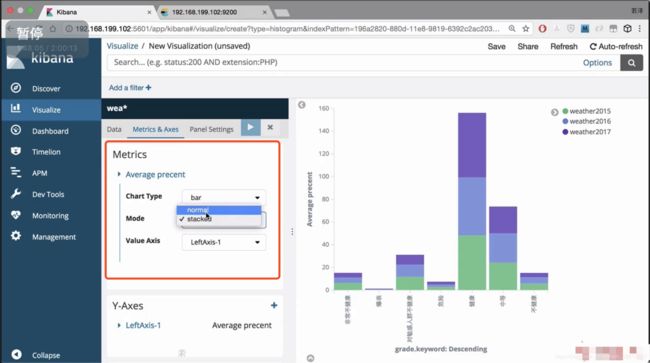

可以看出健康值在逐年递增
保存图像
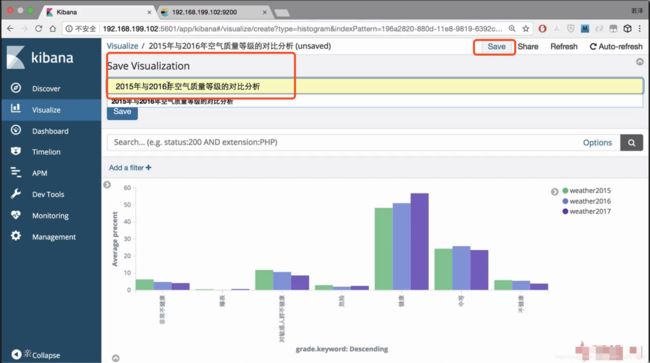
通过Azkaban进行调度
在es将三个索引删除,使用Azkaban进行调度测试
weather.job文件
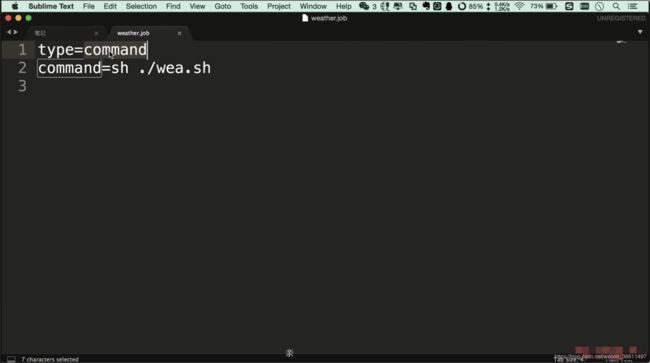
wea.sh 就是上面写过的spark-submit指令,注意还是要指定spark-submit 的详细位置

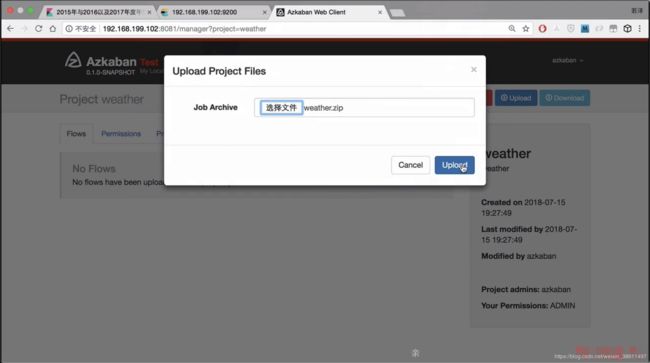
再加上wea.py文件,打成zip包
上传至Azkaban
正在执行
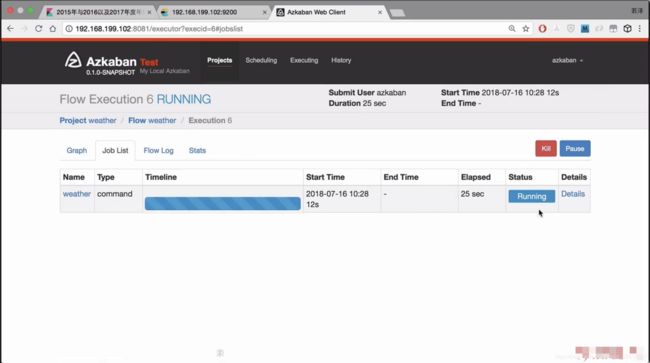
执行成功

在kibana中又可以看到图了