71803倍!超强Pandas循环提速攻略

标星★公众号 爱你们♥
作者:Benedikt Droste
编译:1+1=6
近期原创文章:
♥ 5种机器学习算法在预测股价的应用(代码+数据)
♥ Two Sigma用新闻来预测股价走势,带你吊打Kaggle
♥ 2万字干货:利用深度学习最新前沿预测股价走势
♥ 机器学习在量化金融领域的误用!
♥ 基于RNN和LSTM的股市预测方法
♥ 如何鉴别那些用深度学习预测股价的花哨模型?
♥ 优化强化学习Q-learning算法进行股市
♥ WorldQuant 101 Alpha、国泰君安 191 Alpha
♥ 基于回声状态网络预测股票价格(附代码)
♥ 计量经济学应用投资失败的7个原因
♥ 配对交易千千万,强化学习最NB!(文档+代码)
♥ 关于高盛在Github开源背后的真相!
♥ 新一代量化带货王诞生!Oh My God!
♥ 独家!关于定量/交易求职分享(附真实试题)
♥ Quant们的身份危机!
♥ 拿起Python,防御特朗普的Twitter
♥ AQR最新研究 | 机器能“学习”金融吗?
前言
如果你使用Python和Pandas进行数据分析,循环是不可避免要使用的。然而,即使对于较小的DataFrame来说,使用标准循环也是非常耗时的,对于较大的DataFrame来说,你懂的 。今天,公众号为大家分享一个关于Pandas提速的小攻略,助你一臂之力!
。今天,公众号为大家分享一个关于Pandas提速的小攻略,助你一臂之力!

相关文章
1、30倍!使用Cython加速Python代码
2、CuPy:将Numpy提速700倍!
3、10个提高工作效率的Pandas小技巧
4、高逼格使用Pandas加速代码,向for循环说拜拜!
标准循环
Dataframe是Pandas对象,具有行和列。如果使用循环,你将遍历整个对象。Python不能利用任何内置函数,而且速度非常慢。 我们创建了一个包含65列和1140行的Dataframe。它包含了2016-2019赛季的足球比赛结果。我们希望创建一个新列,用于标注某个特定球队是否打了平局。
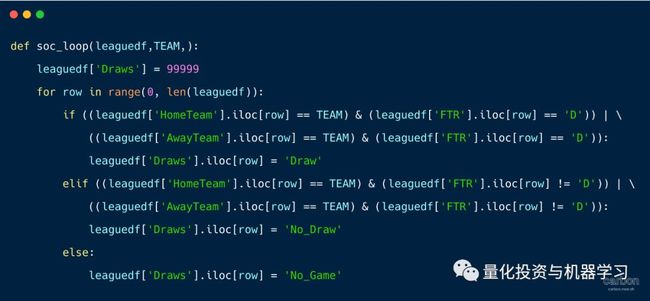

正如你看到的,这个循环非常慢,花了20.7秒。让我们看看如何才能更有效率。
iterrows():快321倍
在第一个例子中,我们循环遍历了整个DataFrame。Iterrows()为每一行返回一个 Series,因此它以索引对的形式遍历DataFrame,以Series的形式遍历目标列。这使得它比标准循环更快:

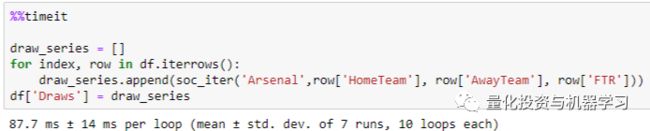
该代码运行时间为87毫秒,比标准循环快321倍。
但是,我们建议不要使用它,因为有更快的选择,而且iterrows()不能保留行之间的 dtype。这意味着,如果你在dataframe dtypes上使用iterrows() ,它会被更改,这可能会导致很多问题。如果一定要保留dtypes,也可以使用itertuple()。这里我们不详细讨论,你可以在这里找到官方文件:
https://pandas.pydata.org/pandas-docs/stable/reference/api/pandas.DataFrame.itertuples.html?source=post_page-----805030df4f06----------------------
Apply():快811倍
apply本身并不快,但与DataFrame结合使用时,它具有很大的优势。这取决于apply表达式的内容。 如果它可以在Cython中执行,那么apply要快得多。
我们可以在Lambda函数中使用apply。 所要做的就是指定轴,使用axis=1,因为我们希望执行按列操作:

这段代码甚至比以前的方法更快,时间为27毫秒。
Pandas Vectorization:快9280倍
我们利用向量化的优势来创建真正高效的代码。关键是要避免案例1中那样的循环代码:

我们再次使用了开始时构建的函数。我们所要做的就是改变输入。我们直接将Pandas Series传递给我们的功能,这使我们获得了巨大的速度提升。
Nump Vectorization:快71803倍
在前面的示例中,我们将Pandas Series传递给函数。通过adding.values,我们得到一个Numpy数组:

Numpy数组是如此之快,因为我们引用了局部性的好处:
访问局部性(locality of reference)
在计算机科学中,访问局部性,也称为局部性原理,是取决于存储器访问模式频繁访问相同值或相关存储位置的现象的术语。访问局部性有两种基本类型——时间和空间局部性。时间局部性是指在相对较小的持续时间内对特定数据和/或资源的重用。空间局部性是指在相对靠近的存储位置内使用数据元素。当数据元素被线性地排列和访问时,例如遍历一维数组中的元素,发生顺序局部性,即空间局部性的特殊情况。
局部性只是计算机系统中发生的一种可预测的行为。展示强访问局部性的系统是通过使用诸如在处理器核心的流水线级处的高速缓存,用于存储器的预取和高级分支预测器的技术的性能优化的良好候选者。
代码运行了0.305毫秒,比开始时使用的标准循环快了 71803倍!
总结
我们比较了五种不同的方法,并根据一些计算将一个新列添加到我们的DataFrame中。我们注意到了速度方面的巨大差异:
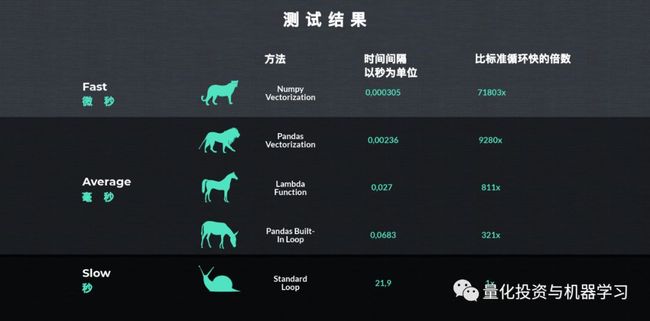
请记住:
1、如果确定需要使用循环,则应始终选择apply方法。
2、否则,vectorization总是更好的,因为它更快!
文章参考
[1] https://stackoverflow.com/questions/52673285/performance-of-pandas-apply-vs-np-vectorize-to-create-new-column-from-existing-c
[2 ] https://en.wikipedia.org/wiki/Locality_of_reference
—End—
量化投资与机器学习微信公众号,是业内垂直于Quant、MFE、CST、AI等专业的主流量化自媒体。公众号拥有来自公募、私募、券商、银行、海外等众多圈内10W+关注者。每日发布行业前沿研究成果和最新量化资讯。

你点的每个“在看”,我们都认真当成了喜欢