记一次在 MOSN 对 Dubbo、Dubbo-go-hessian2 的性能优化
背景
蚂蚁金服内部对 Service Mesh 的稳定性和性能要求是比较高的,内部 MOSN 广泛用于生产环境。在云上和开源社区,RPC 领域 Dubbo 和 Spring Cloud 同样广泛用于生产环境,我们在 MOSN 基础上,支持了 Dubbo 和 Spring Cloud 流量代理。我们发现在支持 Dubbo 协议过程中,经过 Mesh 流量代理后,性能有非常大的性能损耗,在大商户落地 Mesh 中也对性能有较高要求,因此本文会重点描述在基于 Go 语言库 dubbo-go-hessian2 、Dubbo 协议中对 MOSN 所做的性能优化。
dubbo-go-hessian2:https://github.com/apache/dubbo-go-hessian2
MOSN:https://github.com/mosn/mosn
性能优化概述
根据实际业务部署场景,并没有选用高性能机器,使用普通 Linux 机器,配置和压测参数如下:
Intel(R) Xeon(R) Platinum 8163 CPU @ 2.50GHz 4核16G;
pod 配置
2c、1g,jvm 参数-server-Xms1024m-Xmx1024m;网络延迟 0.23ms, 2台 Linux 机器,分别部署 server+MOSN, 压测程序 rpc-perfomance;
rpc-perfomance:https://github.com/zonghaishang/rpc-performance
经过3轮性能优化后,使用优化版本 MOSN 将会获得以下性能收益(框架随机512和1k字节压测):
512字节:MOSN+Dubbo 服务调用 tps 整体提升55-82.8%,rt 降低45%左右,内存占用 40M;
1k数据:MOSN+Dubbo 服务调用 tps 整体提升51.1-69.3%,rt 降低41%左右, 内存占用 41M;
性能优化工具 pprof
磨刀不误砍柴工,在性能优化前首先要找到性能卡点,找到性能卡点后,另一个难点就是如何用高效代码优化替代 slow code。因为蚂蚁金服 Service Mesh 是基于 Go 语言实现的,我们首选 Go 自带的 pprof 性能工具,我们简要介绍这个工具如何使用。如果我们 Go 库自带 http.Server 时并且在 main 头部导入 import_"net/http/pprof",Go 会帮我们挂载对应的 handler, 详细可以参考 godoc 。
godoc:https://pkg.go.dev/net/http/pprof?tab=doc
因为 MOSN 默认会在 34902端口暴露 http 服务,通过以下命令轻松获取 MOSN 的性能诊断文件:

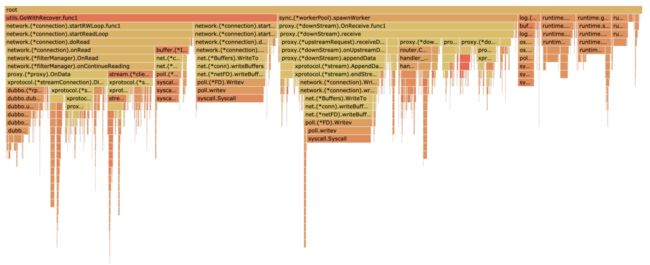
然后继续用 pprof 打开诊断文件,方便在浏览器查看,在图1-1给出压测后 profiler 火焰图:
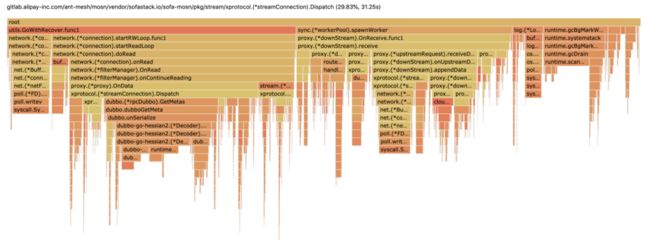
在获得诊断数据后,可以切到浏览器 Flame Graph(火焰图,Go 1.11以上版本自带),火焰图的 X 轴坐标代表 CPU 消耗情况,Y 轴代码方法调用堆栈。在优化开始之前,我们借助 Go 工具 pprof 可以诊断出大致的性能卡点在以下几个方面(直接压 Server 端 MOSN):
MOSN 在接收 Dubbo 请求,CPU 卡点在streamConnection.Dispatch;
MOSN 在转发 Dubbo 请求,CPU 卡点在 downStream.Receive;
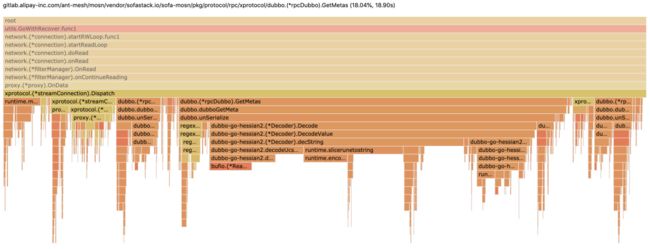
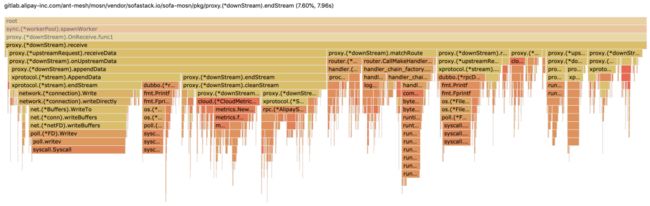
可以点击火焰图任意横条,进去查看长方块耗时和堆栈明细(请参考图1-2和1-3所示):
性能优化思路
本文重点记录优化了哪些 case 才能提升 50%+ 的吞吐量和降低 rt,因此后面直接分析当前优化了哪些 case。在此之前,我们以 Dispatch 为例,看下它为啥那么吃性能 。在 terminal 中通过以下命令可以查看代码行耗费 CPU 数据(代码有删减):

通过上面 listDispatch 命令,性能卡点主要分布在 159 、 171 、 172 、 181 、和 190 等行,主要卡点在解码 Dubbo 参数、重复解参数、Tracer、反序列化和 Log 等。
1. 优化 Dubbo 解码 GetMetas
我们通过解码 Dubbo 的 body 可以获得以下信息,调用的目标接口(interface)和调用方法的服务分组(group)等信息,但是需要跳过所有业务方法参数,目前使用开源的 hessian-go 库,解析 string 和 map 性能较差, 提升 hessian 库解码性能,会在本文后面讲解。
优化思路:
在 MOSN 的 ingress 端(MOSN 直接转发请求给本地 java server 进程), 我们根据请求的 path 和 version 去窥探用户使用的 interface 和 group, 构建正确的 dataId 可以进行无脑转发,无需解码 body,榨取性能提升。
我们可以在服务注册时,构建服务发布的 path、version 和 group 到 interface、group 映射。在 MOSN 转发 Dubbo 请求时可以通过读锁查 cache+ 跳过解码 body,加速 MOSN 性能。
因此我们构建以下 cache 实现(数组+链表数据结构), 可参见优化代码 diff :
优化代码 diff:https://github.com/mosn/mosn/pull/1174/commits/9020ee9995cd15a7a4321a375a9506cf94dc70a8#diff-f5ff30debd68b8318c8236a0b5ccde07R6
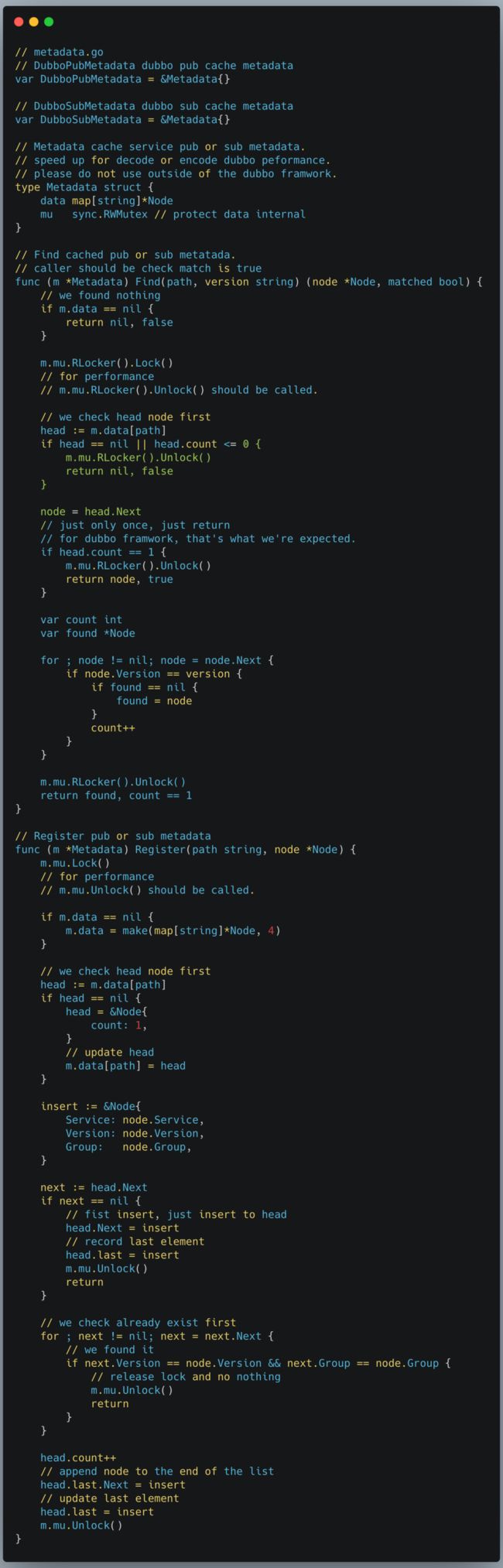
通过服务注册时构建好的 cache,可以在 MOSN 的 stream 做解码时命中 cache, 无需解码参数获取接口和 group 信息,可参见优化代码 diff :
优化代码 diff:https://github.com/mosn/mosn/pull/1174/commits/9020ee9995cd15a7a4321a375a9506cf94dc70a8#diff-73d1153005841c788c91116915f460a5R188
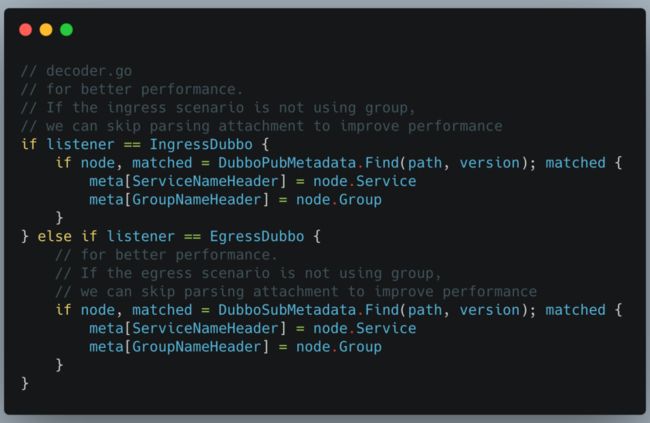
在 MOSN 的 egress 端(MOSN 直接转发请求给本地 java client 进程), 我们采用类似的思路, 我们根据请求的 path 和 version 去窥探用户使用的 interface 和 group, 构建正确的 dataId 可以进行无脑转发,无需解码 body,榨取性能提升。
2. 优化 Dubbo 解码参数
在 Dubbo 解码参数值的时候 ,MOSN 采用的是 Hessian 的正则表达式查找,非常耗费性能。我们先看下优化前后 benchmark 对比, 性能提升50倍!!!
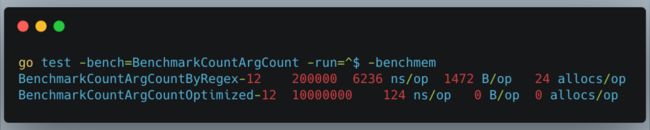
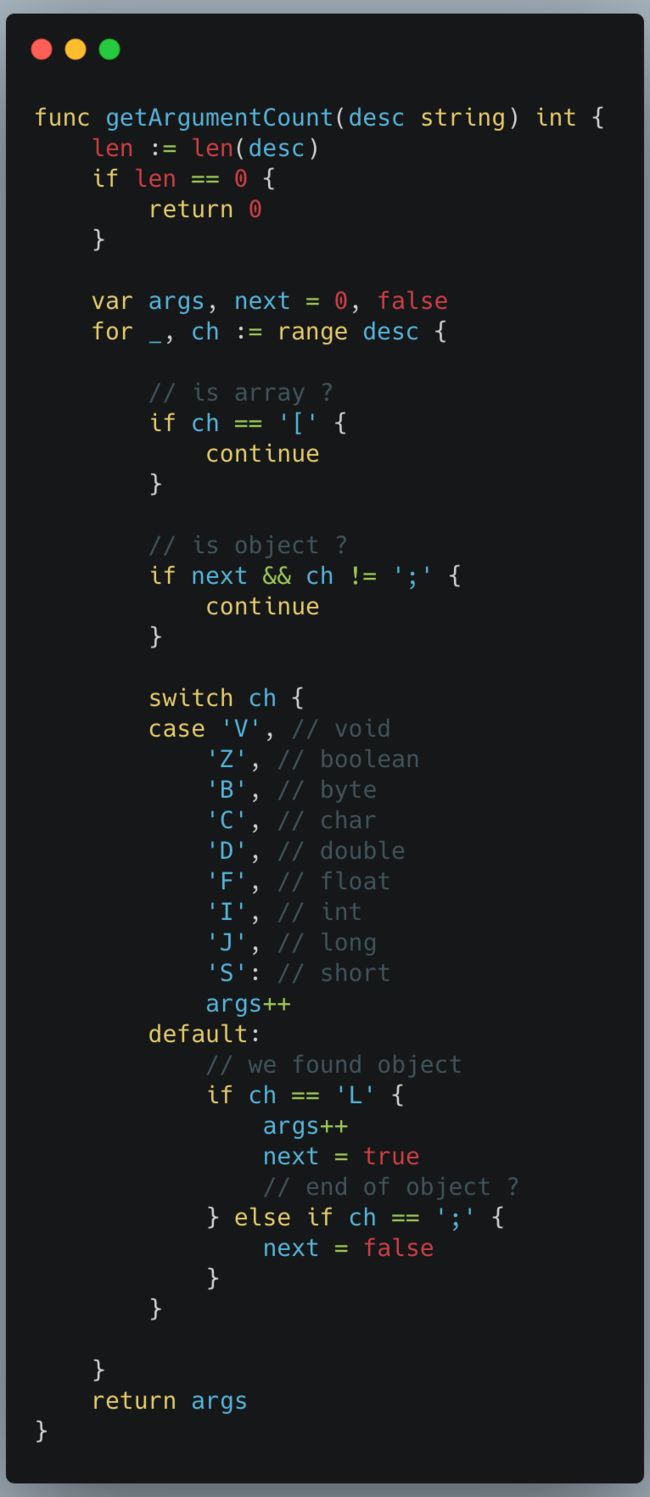
优化思路:
可以消除正则表达式,采用简单字符串解析识别参数类型个数, Dubbo 编码参数个数字符串实现 并不复杂, 主要给对象加L前缀、数组加[、primitive 类型有单字符代替。采用 Go 可以实现同等解析, 可以参考优化代码 diff :
优化代码 diff:https://github.com/mosn/mosn/pull/1174/commits/9020ee9995cd15a7a4321a375a9506cf94dc70a8#diff-73d1153005841c788c91116915f460a5R245
3. 优化 hessian go 解码 string 性能
在图1-2中可以看到 hessian go 在解码 string 占比 CPU 采样较高,我们在解码 Dubbo 请求时,会解析 Dubbo 框架版本、调用 path、接口版本和方法名,这些都是 string 类型,hessian go 解析 string 会影响 RPC 性能。
我们首先跑一下 benchmark 前后解码 string 性能对比,性能提升 56.11%!!! 对应到 RPC 中有5%左右提升。

优化思路:
直接使用 utf-8 byte 解码,性能最高,之前先解码 byte 成 rune, 对 rune 解码成 string 及其耗费性能。增加批量string chunk copy, 降低 read 调用,并且使用 unsafe 转换 string(避免一些校验),因为代码优化 diff 较多,这里给出优化代码 PR 。
优化代码 PR:https://github.com/apache/dubbo-go-hessian2/pull/188
Go SDK 代码 runtime/string.go#slicerunetostring(rune 转换成 string), 同样是把 rune 转成 byte 数组,这里给了我优化思路启发。
4. 优化 hessian 库编解码对象
虽然消除了 Dubbo 的 body 解码部分,但是 MOSN 在处理 Dubbo 请求时,必须要借助 hessian 去 decode 请求头部的框架版本、请求 path 和接口版本值。但是每次在解码的时候都会创建序列化对象,开销非常高,因为 hessian 每次在创建 reader 的时候会 allocate 4k 数据并 reset。

我们可以写个池化内存前后性能对比, 性能提升85.4%!!! , benchmark 用例 :
benchmark:https://github.com/zonghaishang/dubbo-go-hessian2/blob/9b418c4e2700964f244e6b982855b4e89b45990d/string_test.go#L161

优化思路:
在每次编解码时,池化 hessian 的 decoder 对象,新增 NewCheapDecoderWithSkip 并支持 reset 复用 decoder。

5. 优化重复解码 service 和 methodName 值
xprotocol 在实现 xprotocol.Tracing 获取服务名称和方法时,会触发调用并解析2次,调用开销比较大。

优化思路:
因为在 GetMetas 里面已经解析过一次了,可以把解析过的 headers 传进去,如果 headers 有了就不用再去解析了,并且重构接口名称为一个,返回值为二元组,消除一次调用。
6. 优化 streamId 类型转换
在 Go 中将 byte 数组和 streamId 进行互转的时候,比较费性能。
优化思路:
生产代码中, 尽量不要使用 fmt.Sprintf 和 fmt.Printf 去做类型转换和打印信息。可以使用 strconv 去转换。

7. 优化昂贵的系统调用
MOSN 在解码 Dubbo 的请求时,会在 header 中塞一份远程 host 的地址,并且在 for 循环中获取 remoteIp,系统调用开销比较高。
优化思路:

在获取远程地址时,尽可能在 streamConnection 中 cache 远程 ip 值,不要每次都去调用 RemoteAddr。
8. 优化 slice 和 map 触发扩容和 rehash
在 MOSN 处理 Dubbo 请求时,会根据接口、版本和分组去构建 dataId,然后匹配 cluster, 会创建默认 slice 和 map 对象,经过性能诊断,导致不断 allocate slice 和 grow map 容量比较费性能。
优化思路:
使用 slice 和 map 时,尽可能预估容量大小,使用 make(type, capacity) 去指定初始大小。
9. 优化 Trace 日志级别输出
MOSN 中不少代码在处理逻辑时,会打很多 Trace 级别的日志,并且会传递不少参数值。
优化思路:
调用 Trace 输出前,尽量判断一下日志级别,如果有多个 Trace 调用,尽可能把所有字符串写到 buf 中,然后把 buf 内容写到日志中,并且尽可能少的调用 Trace 日志方法。
10. 优化 Tracer、Log 和 Metrics
在大促期间,对机器的性能要求较高,经过性能诊断,Tracer、MOSN Log 和 Cloud Metrics 写日志(IO 操作)非常耗费性能。
优化思路:
通过配置中心下发配置或者增加大促开关,允许 API 调用这些 Feature 的开关。

11. 优化 route header 解析
MOSN 中在做路由前,需要做大量的 header 的 map 访问,比如 ldc、antvip 等逻辑判断,商业版或者开源 MOSN 不需要这些逻辑,这些也会占用一些开销。
优化思路:
如果是云上逻辑,内部 MOSN 的逻辑都不走。
12. 优化 featuregate 调用
在 MOSN 中处理请求时,为了区分内部和商业版路由逻辑,会通过 featuregate 判断逻辑走哪部分。通过 featuregate 调用开销较大,需要频繁的做类型转换和多层 map 去获取。
优化思路:
通过一个 bool 变量记录 featuregate 对应开关,如果没有初始化过,就主动调用一下 featuregate。
未来性能优化思考
经过几轮性能优化 ,目前看火焰图,卡点都在 connection 的 read 和 write,可以优化的空间比较小了。但是可能从以下场景中获得收益:
减少 connection 的 read 和 write 次数(syscall);
优化 IO 线程模型,减少携程和上下文切换等;
作为结束,给出了最终优化后的火焰图 ,大部分卡点都在系统调用和网络读写, 请参考图1-4。
关于作者
诣极,开源 Apache Dubbo PMC。目前就职于蚂蚁金服中间件团队,主攻 RPC 和 Service Mesh 方向。《深入理解 Apache Dubbo 与实战》图书作者。
github: https://github.com/zonghaishang
其他
pprof 工具异常强大,可以诊断 CPU、Memory、Go 协程、Tracer 和死锁等,该工具可以参考 godoc,性能优化参考:
https://blog.golang.org/pprof
https://www.cnblogs.com/Dr-wei/p/11742414.html
https://www.youtube.com/watch?v=N3PWzBeLX2M
MOSN 终端用户征集
如果您也在使用 MOSN 请访问 https://github.com/mosn/community/issues/8 进行登记,已以获得 MOSN 社区更好的服务并帮助 MOSN 做的更好。
