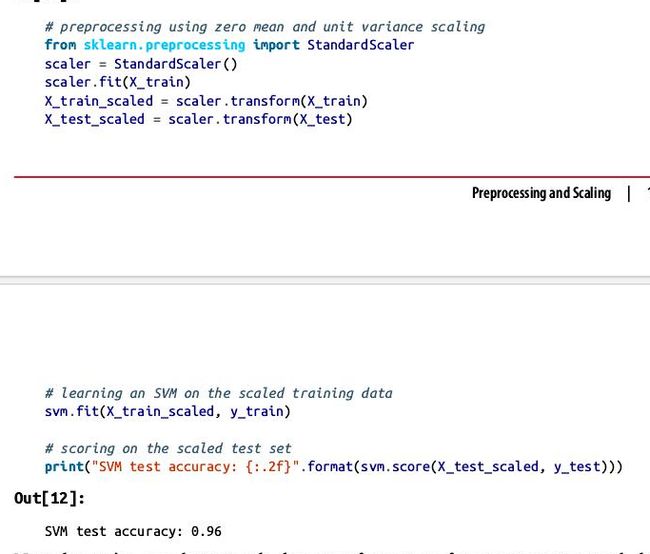
今天看数据预处理,其实预处理和不处理,对结果的得分有很大的影响,最好是先比较两者的差异,再决定要不要用,预处理一般包括

scaler.fit(X_train)
X_train_scaled = scaler.transform(X_train)
三个步骤:1导入相关的预处理模块,并初始化,
2 匹配要处理的数据(一般都是因变量 测试的和训练的)
3 转换匹配处理后的结果
scaler = Min Max Scaler()
scaler.fit(X_train)
X_train_scaled = scaler.transform(X_train)
X_test_scaled = scaler.transform(X_test)
这个可以将两部合为一体: X_scaled_d = scaler.fit_transform(X)
但卧槽

还有一种常见的:
##preprocessing using zero mean and unit variance scaling
from sklearn.preprocessing import StandardScaler
Principal Component Analysis (PCA)



Original shape: (569, 30)
Reduced shape: (569, 2)


擦,,看不懂打

from sklearn.cluster import KMeans
from sklearn.datasets import make_blobs
from sklearn.cluster import KMeans
# generate synthetic two-dimensional data
X, y = make_blobs(random_state=1)
# build the clustering model
kmeans = KMeans(n_clusters=3)
kmeans.fit(X)

data_dummies = pd.get_dummies(data) 生成哑变量
数字进行编码
demo_df = pd.Data Frame({'Integer Feature': [0, 1, 2, 1],
'Categorical Feature': ['socks', 'fox', 'socks', 'box']})







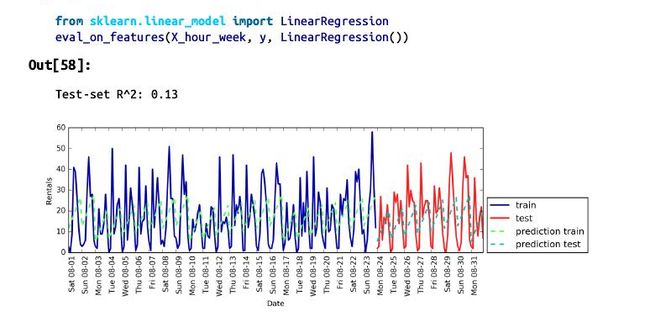


模型检测和提高
k-fold cross-validation, 最常用的交叉验证

最常用的函数是cross_val_score(), 第一个参数是选择的模型,第二个是因变量,第三个是输出值,默认是三重交叉验证,可以改变重数
A common way to summarize the cross-validation accuracy is to compute the mean:,最常用的是输出其均值
print("Average cross-validation score: {:.2f}".format(scores.mean()))


from sklearn.model_selection import Grid Search CV
from sklearn.svm import SVC
grid_search = Grid Search CV(SVC(), param_grid, cv=5)
X_train, X_test, y_train, y_test = train_test_split(
iris.data, iris.target, random_state=0)
grid_search.fit(X_train, y_train)
print("Test set score: {:.2f}".format(grid_search.score(X_test, y_test)))
Test set score: 0.97
print("Best parameters: {}".format(grid_search.best_params_))
print("Best cross-validation score: {:.2f}".format(grid_search.best_score_))









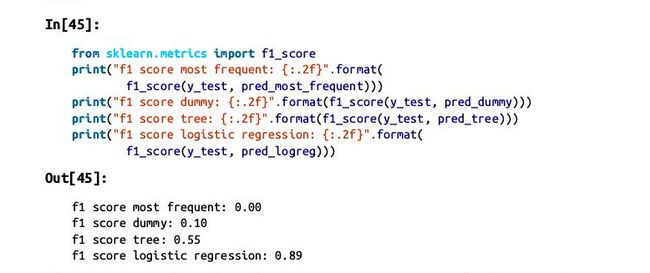

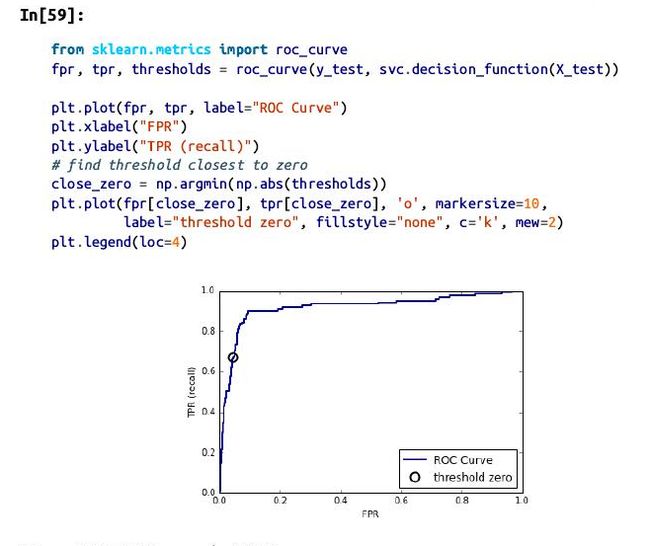
Precision-recall curves and ROC curves:
from sklearn.metrics import precision_recall_curve
precision, recall, thresholds = precision_recall_curve(
y_test, svc.decision_function(X_test))

Receiver operating characteristics (ROC) and AUC