机器学习/深度学习常用库的配置及其适用的算法总结
机器学习、深度学习相关配置须知及其适用算法的总结
常识
传统机器学习框架和深度学习框架之间有区别。本质上,机器学习框架涵盖用于分类,回归,聚类,异常检测和数据准备的各种学习方法,并且其可以或可以不包括神经网络方法。深度学习或深度神经网络(DNN)框架涵盖具有许多隐藏层的各种神经网络拓扑。这些层包括模式识别的多步骤过程。网络中的层越多,可以提取用于聚类和分类的特征越复杂。
按照各类框架主要实现的算法的性质,我们可将这些框架(库)分为几大阵营:
- Caffe,CNTK,DeepLearning4j,Keras,MXNet和TensorFlow等是深度学习框架(库)。
- Scikit-learn和Spark MLlib是机器学习框架(库)。
- Theano跨越了这两个类别。
配置的常识
- 一般来说,深层神经网络计算在GPU(特别是Nvidia CUDA通用GPU,大多数框架)上运行的速度要比CPU快一个数量级。
- 一般来说,更简单的机器学习方法不需要GPU的加速。
虽然可以在一个或多个CPU上训练DNN,训练往往是缓慢的,慢不是说秒或分钟。需要训练的神经元和层数越多,可用于训练的数据越多,需要的时间就越长。
举个例子:
当Google Brain小组在2016年针对新版Google翻译训练语言翻译模型时,他们在多个GPU上同时运行了一周的训练时间。没有GPU,每个模型训练实验将需要几个月。
这些框架中每一个框架具有至少一个显著特征。 Caffe的强项是用于图像识别的卷积DNN。 MXNet具有良好的可扩展性,可用于多GPU和多机器配置的训练。 Scikit-learn具有广泛的强大的机器学习方法,易学易用。 Spark MLlib与Hadoop集成,具有良好的机器学习可伸缩性。 TensorFlow为其网络图TensorBoard提供了一个独特的诊断工具。
另一方面,所有深度学习框架在GPU上的训练速度几乎相同。这是因为训练内循环在Nvidia CuDNN包中花费大部分时间。然而,每个框架采用一种不同的方法来描述神经网络,具有两个主要的阵营:
- 使用图形描述文件的阵营
- 通过执行代码来创建它们的描述的阵营。
考虑到这一点,让我们来看看各个算法和机器学习/深度学习框架的总结。
30个机器学习/深度学习算法总结
| 序号 | 算法名称 | 简称 | 所属类别 | 用途 |
|---|---|---|---|---|
| 1 | 卷积神经网络(Convolutional Neural Network) | CNN | 深度学习 | 常运用在图像和语音识别 |
| 2 | 递归神经网络(Recurrent Neural Network) | RNN | 机器学习 | 常用于NLP(自然语言识别) |
| 3 | 长短期记忆神经网络(long-short term memory) | LSTM | RNN的其中一种形式 | 机器翻译、图像分析、文档摘要、语音识别、图像识别、预测疾病等 |
| 4 | 门控循环单元(Gated Recurrent Unit) | GRU | LSTM的改进 | 机器翻译、语音识别等 |
| 5 | 多层感知器(Multilayer Perceptron) | MLP | MLP是感知器的推广 | 常用于语音识别、图像识别、机器翻译等 |
| 6 | 生成对抗网络(Generative Adversarial Networks) | GAN | BP的推广 | 最常使用的地方就是图像生成,如超分辨率任务,语义分割等 |
| 7 | 受限波尔兹曼机(Restricted Boltzmann Machine) | BM | 机器学习 | 用于协同过滤,降维,分类,特征学习,主题建模以及搭建深度置信网络。 |
| 8 | 深度置信网络(Deep Belief Network) | DBN | 多层RBM | 使用DBN识别特征,分类数据,还可以用来生成数据。 |
| 9 | 自编码器(AutoEncoder) | AE | 机器学习 | 主要用于数据可视化的数据降噪和降维 |
| 10 | 堆叠神经网络(Stacked Auto-Encoder) | SAE | 多层自编码器 | 降维,将复杂的输入数据转化成简单的高维特征 |
| 11 | 稀疏自编码器(Sparse AutoEncoder) | SAE | 自编码器的基础上加上L1的Regularity限制 | 一般用来学习特征,以便用于分类 |
| 12 | 降噪自编码器(Denoising AutoEncoder) | DAE | 自编码器的扩展 | 可用于图像识别、图像复原 |
| 13 | Hopfield网络(Hopfield Neural Network) | HNN | 反馈型神经网络 | 求解最优化问题、文本处理 |
| 14 | 自组织映射(Self-Organizing Map) | SOM | 神经网络 | 用于数据降维、可视化以及聚类 |
| 15 | 径向基函数网络(Radial Basis Function Network) | RBF network | 前馈型神经网络 | 时间序列预测、模式分类、系统控制和非线性回归 |
| 16 | 脉冲神经网络(Spiking Neural Network) | SNN | 神经网络 | 用来学习生物神经系统的工作 |
| 17 | 极限学习机(Extreme learning Machine) | ELM | 前馈神经网络 | 可用于完成分类任务 |
| 18 | 反卷积网络(Deconvolutional Network) | DN | CNN的扩展 | 主要用于特征可视化 |
| 19 | 深度卷积逆向图网络(Deep Convolutional Inverse Graphics Network) | DCIGN | 变分自编码器(VAE) | 可成功学习在3D渲染图像中表示姿态和光线的图形代码 |
| 20 | 回声状态网络(Echo State Network) | ESN | 属于RNN的范畴 | 动态模式分类,机器人控制,对象跟踪和运动目标检测,事件检测等 |
| 21 | 深度残差网络(Deep Residual Network) | DRN | 深度神经网络 | 图像分类,目标检测 |
| 22 | 支持向量机(Support Vector Machine) | SVM | 一种线性分类器 | 模式分类和非线性回归 |
| 23 | 神经图灵机Neural Turing Machine | NTM | 神经网络+记忆库 | 可用于自然语言处理 |
| 24 | AlexNet | AlexNet | 其本质仍旧是CNN | 目标检测 |
| 25 | GoogLeNet | GoogLeNet | 深度神经网络 | 目标检测、图像识别 |
机器学习/深度学习常用框架(库)总结
| 序号 | 库名称 | 支持语言 | 硬件要求 | 基础依赖包 | 显著特征(强项) | 适用算法 | 配置参考 |
|---|---|---|---|---|---|---|---|
| 1 | scikit-learn | python | 不支持GPU加速 | NumPy和SciPy | 机器学习 | 支持向量机(SVM),最近邻,逻辑回归,随机森林,决策树 | 配置 |
| 2 | Theano | python | 支持GPU计算 | NumPy、SciPy、BLAS | 速度与C媲美 | 机器学习和深度学习 | 配置 |
| 3 | TensorFlow | 主要python/c++,也支持Go/Java/Lua/Javascript/R | 支持GPU加速 | NumPy、SciPy等,CUDA和cuDNN | 图像识别等 | CNN、GAN、RNN、LSTM、AE等 | 配置 |
| 4 | Keras | python | 支持GPU加速 | 基于Theano和TensorFlow | 支持快速实验而生 | CNN和RNN,或二者的结合 | 配置 |
| 5 | Caffe | C++、matlab、python | 完美支持GPU | 独立框架 | 图像处理 | 更支持CNN | 配置 调用 |
| 6 | Pytorch | python | 有一套很好的GPU运算体系 | python基础包 | 计算机视觉,NLP | CNN、RNN等 | 配置 |
| 7 | Sonnet | python | 支持GPU加速 | TensorFlow | 搭建AI高级结构 | LSTM、RNN、CNN等 | 配置 |
| 8 | MXNet | C++, Python, R, Scala, Julia, Matlab、JavaScript等语言 | 支持CPU加速 | CUDA和cuDNN | 图像识别、NLP情感分析 | CNN、RNN | 配置 |
| 9 | CNTK | C ++和Python | 实现了跨多个gpu和服务器的自动分异和并行化 | python基础包或Keras | 语音识别领域 | 支持各种前馈网络,包括MLP、CNN、RNN、LSTM等 | 配置 |
| 10 | Dlib | C ++、python | 支持GPU加速 | cuda、cudnn | 图像处理 | SVM、聚类算法、数值算法等 | 配置 |
更多详细的库和算法的使用情况可以查看我们的思维导图
服务器配置建议
CPU
根据在所有的机器学习和深度学习的框架以及库中,大部分都只是支持GPU运算的,即使是可以CPU与GPU混用的,CPU的运行速度比GPU运行速度不只低一个数量级。GPU可以短时间运行结束的,CPU需要大量的时间来运行。
CPU在深度学习任务中,CPU并不负责主要任务,单显卡计算时只有一个核心达到100%负荷,所以CPU的核心数量和显卡数量一致即可,太多没有必要,但是处理PICE的带宽要到40.
建议CPU配置
- Intel i7-7800X(内核数:6核;线程数:12;处理器基频:3.5GHz;最大睿频频率:4.00GHz;缓存:8.25MB L3)
- Intel E5-2620 v3(内核数:6核;线程数:12;处理器基频:2.6GHz;最大睿频频率:3.2GHz;缓存:15MB SmartCache)
- Intel i7-6850K(核心数:6核;线程数:12核;处理器基频:2.6GHz;最大睿频率频率:4.0GHz;缓存:15MB)
GPU
现在机器学习与深度学习最主要都是基于CUDA计算(CUDA是NVIDIA开发GPU并行计算环境),所以建议使用的GPU为NVIDIA公司的GPU
由于现在机器学习和深度学习的框架都只是支持单精度,所以双精度浮点计算时不必要的。并且,太高精度对于深度学习的错误率时没有提升的。
建议GPU配置:(建议GPU配置至少要有两个)
- GeForce GTX1060(显存:6GB;内存带宽:216GB/s;处理器:1280个CUDA核心@1708核心MHz)(最低配置)
- GeForce GTX1070(显存:8GB;内存带宽:256GB/s;处理器:1920个CUDA核心@1683核心MHz)
- GeForce GTX1070Ti(显存:8GB;内存带宽:256GB/s;处理器:2432个CUDA核心@1683核心MHz)
- GeForce Gtx1080(显存:8GB;内存带宽:320GB/s;处理器:2560个CUDA核心@1733核心MHz)
- GeForce GTX1080Ti(显存:11GB;内存带宽:484GB/s;处理器:3585个CUDA核心@1582核心MHz)
DDR
- 海盗船32G-DDR4
- 金士顿骇客神条Fury系列DDR4 2400 32G(16GB*2)
硬盘
最主要是使用来存储数据,所以存储空间越大越好,至少是1T
SSD
- Intel 600P系列 512G M.2
- Intel 600P系列 1T M.2
- 三星 960EVO 1TB M.2 NVMe
常用库的配置详情
scikit-learn
安装conda包
为什么要安装conda?
- 1、用conda我们可以非常方便地安装python的各种package(e.g. numpy, scipy, matplotlib, tensorflow, pytorch, etc.),而不用管包与包之间的dependency问题——比如有的时候你安装新的package1,它要求numpy 1.0版本,你再次安装package2,他又要求numpy1.3,这个时候就会出问题:要么package1用不了,要么package2安装失败。
- 2、conda有点类似于pip(它们是竞争关系),但是比pip更方便,更具优势,因为它允许在一台机器上有多个python版本共存。我们可以使用conda建立多个独立的开发环境(env),在每个环境中安装自己需要的python版本及各种相关的package版本。
- 3、对于多用户的机器,如实验室的服务器,conda的安装本身也是相互独立的。也就是说,如果你安装了conda,别人是不知道的,也就不会去动你的开发环境。
下载并安装conda
安装conda可以通过安装Anaconda或者Miniconda实现。我们的目的——安装科学研究使用的开发环境而言,使用轻量化的Miniconda就可以了。
-
用户登录后开始配置
login username -
通过wget下载conda
# 在用户目录下:/home/username/ wget https://repo.continuum.io/miniconda/Miniconda3-latest-Linux-x86_64.sh -
安装conda
进入该.sh文件所在位置。输入下面的命令并回车运行
bash Miniconda3-latest-Linux-x86_64.sh仔细看安装提示,一般是Enter或者输入yes,然后会安装一堆东西
Do you wish the installer to prepend the Miniconda3 install location to PATH in your /home/(your directory)/.bashrc ? [yes|no] [no] >>> yes上面输入yes,会在你文件夹下的~/.bashrc 文件末尾添加一句export PATH=/home/[your directory]/miniconda3/bin:$PATH,表示将conda加入你的环境变量。通过vim ~/.bashrc可以查看。
如果提示下面信息,输入no:(在服务器上我们不适用Microsoft VSCode,所以选no)Do you wish to proceed with the installation of Microsoft VSCode? [yes|no] >>> no -
检验当前python版本
安装conda的时候,默认安装了一个python,我们下载了python3.6版本的conda, 所以应该有一个3.6版本的python。输入python,或者python3,你发现你的python版本还是原来服务器上的2.7和3.4。或者你输入which python或which python3,显示的python的位置也是/usr/bin/python或/usr/bin/python3。也就是说,我们安装好的conda还没有被激活。
-
激活conda
因为每个人安装的conda都是独立的,所以每次重新登录的时候,conda是没有被激活的,可以在命令行输入conda测试一下,应该会返回
conda: commmand not found此时需要输入source /.bashrc。这表示激活/.bashrc文件中的环境变量。
所以这里有一点小麻烦,在每次你想使用conda或者相应的开发环境的时候,你都得用source ~/.bashrc激活一次。这么做是为了保证conda的相对独立性。默认不激活conda,此时,你可以使用服务器公用的python2.7和python3.4。需要你自己配置的开发环境时你再激活。
此时输入:conda --version会看到
conda 4.5.11 -
简单的conda指令
强烈建议直接看官方doc Getting started with conda ,这里各种conda的命令和作用讲得比较全。
- 检查conda里的开发环境(env):
看到conda env list 或者conda info --envs
只有上面这一行,就是默认的环境,中间有个*。这一行的意思是,我们当前所在的环境是默认环境。我们可以直接在这个默认环境上安装包,但是这不是明智的做法,大家都会第一时间使用默认环境,容易出问题。所以,下面将介绍如何创建并配置自己的独立的开发环境。base * /home/(your directory)/miniconda3
- 检查conda里的开发环境(env):
-
创建独立的开发环境并同时安装基础包
名字是python27,也可以改成自己想要的名字,python版本是2.7,后面的是基础的python包
conda create -n python27 python=2.7 numpy scipy seaborn pandas matplotlib scikit-learn jupyter notebook会出现一堆列表然后让你选[Y]/n, 直接回车就可以了。
这段命令同时干了两件事:-
1)建立python版本为2.7的开发环境;
-
2)在该环境下同时安装 numpy scipy seaborn pandas matplotlib scikit-learn jupyter notebook 等python包。
安装结束后得到如下内容:
Preparing transaction: done Verifying transaction: done Executing transaction: done # # To activate this environment, use: # > source activate python27 # # To deactivate an active environment, use: # > source deactivate按照上面说的,激活环境python27:source activate python27,你会看到你的命令行的开头多出来(python27)的字样,表示你处于python27环境中。输入 python,which python之类的命令可以再次看出与之前python版本不同。
输入 source deactivate可以退出当前环境(回到默认环境base)。再次检验conda环境:
conda env list
现在应该会出现两行,如果你处在python27环境中, *会出现在开头是python27的那一行检验python27环境下的python包安装情况
conda list
应该会出来一个列表,显示所有安装好的包及版本。 -
安装python包
激活env
source activate python27
激活后如下:
(python27) username@hostname:~$
激活后可使用下列两种方式安装
-
用pip装
使用conda新建一个env的时候都会默认安装pip,所以你可以直接在激活该环境的情况下用pip安装其他python包。建议安装前用which pip 检验pip所在环境。
-
用conda装
可以先用conda search [package_name]检查conda是否提供了该package的安装,如果返回正常,则使用 conda install [package_name]安装
安装 Scikit-learn
在虚拟环境中执行如下命令:
-
更新pip
python -m pip install --upgrade pip -
更新包
列出可升级的包 -
更新需要更新的包
pip install --upgrade pakagename -
开始安装(sklearn是scikit-learn的简称)
pip install sklearn 或者 pip install scikit-learn -
当看到如下说明安装成功
Sueccessfully installed scikit-learn-x.x.x sklearn.x.x打开python检验
python Python 2.7.15 |Anaconda, Inc.| (default, Oct 10 2018, 21:32:13) [GCC 7.3.0] on linux2 Type "help", "copyright", "credits" or "license" for more information. >>>import sklearn >>>
TensorFlow
安装python包或者安装conda
在上一个库的配置中已经安装了conda,具体配置可见上面sklearn的配置中的conda安装,这里不再赘述。
基于 VirtualEnv 的安装
我们推荐使用 virtualenv 创建一个隔离的容器, 来安装 TensorFlow. 这是可选的, 但是这样做能使排查安装问题变得更容易.
-
创建虚拟环境
创建一个名为TensorFlow的虚拟环境,也可以用其它的名字,使用的python的版本为python3.5(也可以为其它版本)
执行命令:conda create -n tensorflow python=3.5提示信息:
Solving environment: done ## Package Plan ## environment location: /home/zhongxiao/miniconda3/envs/tensorflow added / updated specs: - python=3.5 The following packages will be downloaded: ... The following NEW packages will be INSTALLED: ca-certificates: 2018.03.07-0 certifi: 2018.8.24-py35_1 libedit: 3.1.20170329-h6b74fdf_2 libffi: 3.2.1-hd88cf55_4 ... wheel: 0.31.1-py35_0 xz: 5.2.4-h14c3975_4 zlib: 1.2.11-ha838bed_2 # 输入y,回车继续 Proceed ([y]/n)? y ... Preparing transaction: done Verifying transaction: done Executing transaction: done # # To activate this environment, use # # $ conda activate tensorflow # # To deactivate an active environment, use # # $ conda deactivate -
激活虚拟环境
我们需要激活刚才创建的python3版本的虚拟环境后才可以选择在其基础上安装TensorFlow。所以如下命令激活名为tensorflow的虚拟环境:
source activate tensorflow可以看到:
(tensorflow) username@hostname:~$ -
更新pip
pip install --upgrade pip -
安装不支持GPU加速的TensorFlow
如果你的电脑显卡很渣,或者你并不想用GPU版的TensorFlow,那可以选择装不要GPU加速的Tenso。
pip install tensorflow- 如果出现:
Your CPU supports instructions that this TensorFlow binary was not compiled to use: AVX2 FMA
由于tensorflow默认分布是在没有CPU扩展的情况下构建的,例如SSE4.1,SSE4.2,AVX,AVX2,FMA等。默认版本(来自pip install tensorflow的版本)旨在与尽可能多的CPU兼容。另一个观点是,即使使用这些扩展名,CPU的速度也要比GPU慢很多,并且期望在GPU上执行中型和大型机器学习培训。
-
解决方法:
-
1.在代码中加入如下代码,忽略警告:
import os os.environ['TF_CPP_MIN_LOG_LEVEL'] = '2' -
2.编译TensorFlow源码
如果你没有GPU并且希望尽可能多地利用CPU,那么如果您的CPU支持AVX,AVX2和FMA,则应该从针对CPU优化的源构建tensorflow。在这个问题中已经讨论过这个问题,也是这个GitHub问题。 Tensorflow使用称为bazel的ad-hoc构建系统,构建它并不是那么简单,但肯定是可行的。在此之后,不仅警告消失,tensorflow性能也应该改善。也可参考编译安装TensorFlow
-
-
测试TensorFlow
在home目录下创建tensorflow文件夹,再在里面创建tensorboard.py文件,并写入:
""" Please note, this code is only for python 3+. If you are using python 2+, please modify the code accordingly. """ from __future__ import print_function import tensorflow as tf import numpy as np def add_layer(inputs, in_size, out_size, n_layer, activation_function=None): # add one more layer and return the output of this layer layer_name = 'layer%s' % n_layer with tf.name_scope(layer_name): with tf.name_scope('weights'): Weights = tf.Variable(tf.random_normal([in_size, out_size]), name='W') tf.summary.histogram(layer_name + '/weights', Weights) with tf.name_scope('biases'): biases = tf.Variable(tf.zeros([1, out_size]) + 0.1, name='b') tf.summary.histogram(layer_name + '/biases', biases) with tf.name_scope('Wx_plus_b'): Wx_plus_b = tf.add(tf.matmul(inputs, Weights), biases) if activation_function is None: outputs = Wx_plus_b else: outputs = activation_function(Wx_plus_b, ) tf.summary.histogram(layer_name + '/outputs', outputs) return outputs # Make up some real data x_data = np.linspace(-1, 1, 300)[:, np.newaxis] noise = np.random.normal(0, 0.05, x_data.shape) y_data = np.square(x_data) - 0.5 + noise # define placeholder for inputs to network with tf.name_scope('inputs'): xs = tf.placeholder(tf.float32, [None, 1], name='x_input') ys = tf.placeholder(tf.float32, [None, 1], name='y_input') # add hidden layer l1 = add_layer(xs, 1, 10, n_layer=1, activation_function=tf.nn.relu) # add output layer prediction = add_layer(l1, 10, 1, n_layer=2, activation_function=None) # the error between prediciton and real data with tf.name_scope('loss'): loss = tf.reduce_mean(tf.reduce_sum(tf.square(ys - prediction), reduction_indices=[1])) tf.summary.scalar('loss', loss) with tf.name_scope('train'): train_step = tf.train.GradientDescentOptimizer(0.1).minimize(loss) sess = tf.Session() merged = tf.summary.merge_all() writer = tf.summary.FileWriter("logs/", sess.graph) init = tf.global_variables_initializer() sess.run(init) for i in range(1000): sess.run(train_step, feed_dict={xs: x_data, ys: y_data}) if i % 50 == 0: result = sess.run(merged, feed_dict={xs: x_data, ys: y_data}) writer.add_summary(result, i) # direct to the local dir and run this in terminal: # $ tensorboard --logdir logs -
在虚拟环境下执行
$ python tensorboard.py-
查看运行结果
因为服务器一般不支持桌面系统,所以无法查看tensorflow的运行结果,但是我们连接ssh时,可以将服务器的6006端口重定向到自己机器上来:
-
首先退出远程连接
exit -
ssh连接
ssh -L 16006:127.0.0.1:6006 username@remote_server_ip其中:16006:127.0.0.1代表自己机器上的16006号端口,6006是服务器上tensorboard使用的端口。
-
进入tenorflow虚拟环境
source activate tensorflow -
如果报错,如果没有报错,则可跳过下面几行:
shell脚本中含有source命令运行时提示 source: not found -
测试:
ls -l /bin/sh 显示:/bin/sh -> dash可见,这是由于默认的dash导致source解析不了,需要切换为bash
-
解决方案:
sudo dpkg-reconfigure dash(在界面中选择no ,再运行ls -l /bin/sh 后显示/bin/sh -> bash
,至此问题已解决。 -
再次运行命令进入虚拟环境
source activate tensorflow -
将路径切换到tensorflow文件夹下,执行:
(tensorflow) username@Hostname:~/tensorflow$ tensorboard --logdir logs -
可以看到:
TensorBoard 1.11.0 at http://WeiLy:6006 (Press CTRL+C to quit) -
在本地浏览器中查看,在浏览器输入:
http://127.0.0.1:16006 -
可见:
loss曲线:
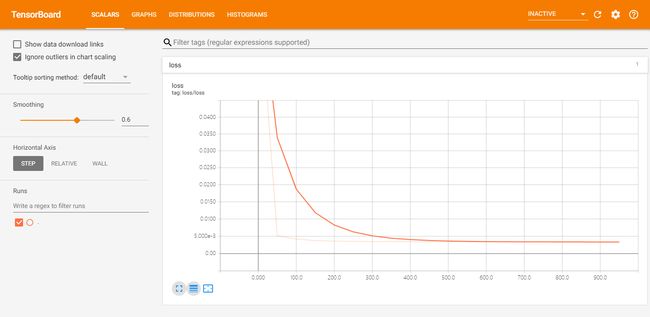
神经网络图:
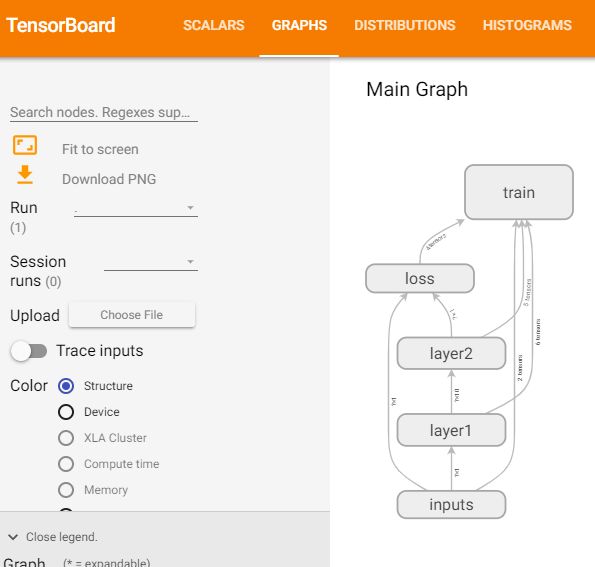
每一层的weights和biases变化情况
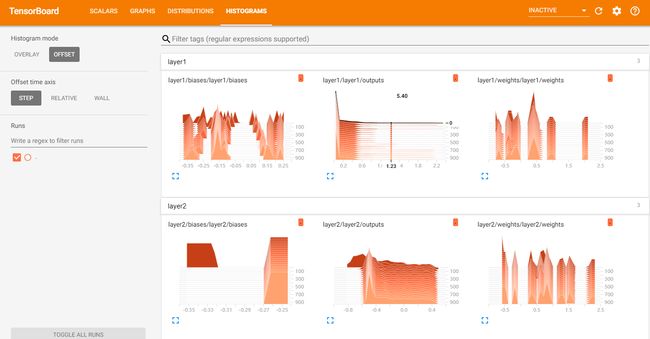
- 说明我们CPU版本的TensorFlow配置已经大工告成了!
-
- 如果出现:
-
安装支持GPU加速的TensorFlow
-
安装CUDA
简介:CUDA(Compute Unified Device Architect,统一计算架构),是NVIDIA创造的一个并行计算平台和编程模型。它利用图形处理器(GPU)能力,实现计算性能的显著提高。
根据TensorFlow的版本安装对应的cuda,本服务器上需要安装的是cuda9.0- 可用命令行下载
wget https://developer.nvidia.com/compute/cuda/9.0/Prod/local_installers/cuda-repo-rhel7-9-0-local-9.0.176-1.x86_64-rpm
- 可用命令行下载
-
Theano
Theano是一个Python库,可让您定义,优化和评估数学表达式,尤其是具有多维数组的数学表达式(numpy.ndarray)。使用Theano可以获得与手工制作的C实现相媲美的速度,以解决涉及大量数据的问题。通过利用最近的GPU,它还可以在CPU上超过C级数。
安装Theano
-
用conda创建虚拟环境
创建名为theano_python35,基于python3.5的虚拟环境。conda create -n theano_python35 python=3.5激活虚拟环境:
source activate theano_python35更新pip:
pip install --upgrade pip -
安装基础依赖包和可选包
安装基础包
pip install numpy scipy mkl安装可选包,其作用如下:
-
nose > = 1.3.0
运行Theano的测试套件。
-
Sphinx > = 0.5.1,pygments
用于构建文档。数学显示为图像也需要LaTeX和dvipng。
-
pydot-NG
处理gif /图像的大图片。
-
NVIDIA CUDA驱动程序和SDK
强烈建议在NVIDIA gpus上生成/执行GPU代码。
-
libgpuarray
在CUDA和OpenCL设备上生成GPU / CPU代码时需要。 -
pycuda和skcuda
GPU上的一些额外操作(如fft和求解器)需要。我们用它们来包裹袖口和cusolver。快速安装 。对CUDA 8,需要用于cusolver skcuda的dev的版本。
这里可选择,安装nose、sphinx、pydot-ng,其它包需要用时再安装:pip install nose sphinx pydot-ng -
安装和配置GPU驱动程序
因为服务器GPU目前不支持CUDP驱动,所以这项暂且跳过。
-
-
安装稳定版的Theano
如果使用conda,可以直接安装theano和pygpu。Libgpuarray将作为pygpu的依赖项自动安装。这里我直接用conda安装:
conda install theano pygpu
测试Theano
用下面的指令测试(测试时会有其他错误提示或是warnings,但基本上还能运行的话则说明theano没问题,错误提示可能是有些东西还没安装好):
import theano
theano.test()
如果遇到报错:
ImportError: No module named 'parameterized'
安装parameterized:
pip install parameterized
Keras
Keras是一个高层神经网络API,Keras由纯Python编写而成并基Tensorflow、Theano以及CNTK后端。Keras 为支持快速实验而生,能够把你的idea迅速转换为结果,如果你有如下需求,请选择Keras:
- 简易和快速的原型设计(keras具有高度模块化,极简,和可扩充特性)
- 支持CNN和RNN,或二者的结合
- 无缝CPU和GPU切换
Keras适用的Python版本是:Python 2.7-3.6
Keras的设计原则是
- 用户友好:用户的使用体验始终是Keras考虑的首要和中心内容。Keras遵循减少认知困难的最佳实践:Keras提供一致而简洁的API, 能够极大减少一般应用下用户的工作量,同时,Keras提供清晰和具有实践意义的bug反馈。
- 模块性:模型可理解为一个层的序列或数据的运算图,完全可配置的模块可以用最少的代价自由组合在一起。具体而言,网络层、损失函数、优化器、初始化策略、激活函数、正则化方法都是独立的模块,你可以使用它们来构建自己的模型。
- 易扩展性:添加新模块超级容易,只需要仿照现有的模块编写新的类或函数即可。创建新模块的便利性使得Keras更适合于先进的研究工作。
- 与Python协作:Keras没有单独的模型配置文件类型(作为对比,caffe有),模型由python代码描述,使其更紧凑和更易debug,并提供了扩展的便利性。
由于Keras默认以Tensorflow为后端,且Theano后端更新缓慢,这里默认采用Tensorflow1.0作为Keras后端。
对配置的要求
-
推荐配置
如果是高校学生或者高级研究人员,并且实验室或者个人资金充沛,建议采用如下配置:
- 主板:X299型号或Z270型号
- CPU: i7-6950X或i7-7700K 及其以上高级型号
- 内存:品牌内存,总容量32G以上,根据主板组成4通道或8通道
- SSD: 品牌固态硬盘,容量256G以上
- 显卡:NVIDIA GTX TITAN(XP) NVIDIA GTX 1080ti、NVIDIA GTX TITAN、NVIDIA GTX 1080、NVIDIA GTX 1070、NVIDIA GTX 1060 (顺序为优先建议,并且建议同一显卡,可以根据主板插槽数量购买多块,例如X299型号主板最多可以采用×4的显卡)
-
最低配置
如果仅仅用于自学或代码调试,亦或是条件所限仅采用自己现有的设备进行开发,那么电脑至少满足以下几点:
- CPU:Intel第三代i5和i7以上系列产品或同性能AMD公司产品
- 内存:总容量4G以上
安装Keras
-
进入需要配置库的python环境
这里我利用conda建立了虚拟环境python35(基于python3.5)
conda create -n python35 python=3.5如果提示:
conda: command not found执行如下命令导入环境变量之后再执行上面:
source ~/.barshrc -
安装依赖库TensorFlow
- 激活虚拟环境
看到命令行前出现(python3.5)表明正处于虚拟环境中,如果你不需要用到虚拟环境,这一步可以跳过。source activate python35 - 安装tensorflow
出现:pip install tensorflow
表明安装成功Successfully installed ......
- 激活虚拟环境
-
安装Keras
执行如下命令:
pip install keras等待几分钟,出现下面表明安装成功:
Successfully built pyyaml Installing collected packages: scipy, pyyaml, keras
测试Keras
-
创建测试py文件:
addition_rnn.py,内容参考
-
开始测试
执行命令
python addition.py迭代200次后的结果:
... Iteration 199 Train on 45000 samples, validate on 5000 samples Epoch 1/1 45000/45000 [==============================] - 8s 187us/step - loss: 1.4244e-04 - acc: 1.0000 - val_loss: 7.8142e-04 - val_acc: 0.9998 Q 73+384 T 457 ☑ 457 Q 90+833 T 923 ☑ 923 Q 28+473 T 501 ☑ 501 Q 241+598 T 839 ☑ 839 Q 371+811 T 1182 ☑ 1182 Q 940+1 T 941 ☑ 941 Q 5+451 T 456 ☑ 456 Q 111+70 T 181 ☑ 181 Q 729+3 T 732 ☑ 732 Q 328+42 T 370 ☑ 370
Caffe
Caffe是由伯克利大学的贾杨清等人开发的一个开源的深度学习框架,采用高效的C++语言实现,并内置有Python和MATLAB接口,以供开发人员使用Python或MATLAB来开发和部署以深度学习为核心算法的应用。Caffe适用于互联网级别的海量数据处理,包括语音,图片,视频等多媒体数据。Caffe的高速运算是通过GPU来实现的,在K40或者Titan GPU上每天可处理4千万张图片,相当于1张图片仅用2.5ms,速度非常快。
创建虚拟安装Caffe的虚拟环境
如果不用虚拟环境安装可跳过这步
conda create -n caffe_python35 python=3.5
激活
source activate caffe_python35
更新pip
pip install --upgrade pip
安装依赖包
-
Caffe的基础依赖包:
-
GPU模式需要CUDA。
建议使用库版本7+和最新的驱动程序版本,但6. *也可以
5.5和5.0是兼容的,但被认为是遗留的 -
BLAS通过ATLAS,MKL或OpenBLAS。
-
Boost > = 1.55
-
protobuf,glog,gflags,hdf5
-
-
可选的依赖项:
- OpenCV > = 2.4包括3.0
- IO库:lmdb,leveldb(注意:leveldb要求snappy)
- 用于GPU加速的cuDNN(v6)
仅限CPU的Caffe:设置Makefile.config中的CPU_ONLY := 1以配置和构建没有CUDA的Caffe。这有助于云或群集部署。
cuDNN Caffe:为了实现最快的操作,通过嵌入式集成NVIDIA cuDNN加速了Caffe的发展。要加速Caffe模型,请安装cuDNN,然后在Makefile.config中设置标志:USE_CUDNN := 1。
-
执行安装
- 更新系统库
sudo apt-get update- 安装依赖包
sudo apt-get install libprotobuf-dev libleveldb-dev libsnappy-dev libopencv-dev libhdf5-serial-dev protobuf-compiler sudo apt-get install --no-install-recommends libboost-all-dev sudo apt-get install libopenblas-dev liblapack-dev libatlas-base-dev sudo apt-get install libgflags-dev libgoogle-glog-dev liblmdb-dev sudo apt-get install git cmake build-essential有一定几率安装失败而导致后续步骤出现问题,所以要确保以上依赖包都已安装成功,验证方法就是重新运行安装命令,如验证 git cmake build-essential是否安装成功共则再次运行以下命令:
username@Hostname:~$ sudo apt-get install git cmake build-essential Reading package lists... Done Building dependency tree Reading state information... Done build-essential is already the newest version (12.1ubuntu2). cmake is already the newest version (3.5.1-1ubuntu3). git is already the newest version (1:2.7.4-0ubuntu1.5). The following packages were automatically installed and are no longer required: gir1.2-git2-glib-1.0 gir1.2-gucharmap-2.90 gir1.2-zeitgeist-2.0 libgit2-24 libgit2-glib-1.0-0 libhttp-parser2.1 libllvm3.8 libpango1.0-0 libqmi-glib1 libssh2-1 linux-headers-4.4.0-21 linux-headers-4.4.0-21-generic linux-image-4.4.0-21-generic linux-image-extra-4.4.0-21-generic Use 'sudo apt autoremove' to remove them. 0 upgraded, 0 newly installed, 0 to remove and 7 not upgraded.- 安装CUDA
如果是仅CPU安装caffe,可以跳过CUDA安装。
-
安装 opencv3.1
来源于参考文档
-
下载OpenCV3.1
sudo git clone https://github.com/opencv/opencv.git我在下载的时候出现timed out的报错,也就是下载不下来,最后只好先用本地电脑浏览器进入OpenCV官网下载好source包,再用winSCP传到服务器,虽然有些笨拙,但着实实用。
-
解压到你要安装的位置,命令行进入已解压的文件夹 opencv-3.1.0 目录下,执行:
mkdir build # 创建编译的文件目录 cd build cmake -D CMAKE_BUILD_TYPE=Release -D CMAKE_INSTALL_PREFIX=/usr/local .. -
但是在安装OpenCv 3.1的过程中要下载ippicv_linux_20151201,由于网络的原因,这个文件经常会下载失败。
CMake Error at 3rdparty/ippicv/downloader.cmake:73 (file): file DOWNLOAD HASH mismatch for file: [/home/opencv-3.1.0/3rdparty/ippicv/downloads/linux-808b791a6eac9ed78d32a7666804320e/ippicv_linux_20151201.tgz] expected hash: [808b791a6eac9ed78d32a7666804320e] actual hash: [d41d8cd98f00b204e9800998ecf8427e] status: [7;"Couldn't connect to server"] -
解决方案
来源于: 参考文档1 参考文档2
-
用本地下载 ippicv_linux_20151201,用winSCP上传到服务器。
-
将下载好的文件ippicv_linux_20151201.tgz拷贝到文件夹路径中:
cp <文件所在路径>/ippicv_linux_20151201.tgz /home/opencv-3.1.0/3rdparty/ippicv/downloads/linux-808b791a6eac9ed78d32a7666804320e/注意,在报错之前,系统不会创建该文件夹,报错之后系统会创建该文件夹用来存储ippicv_linux_20151201.tgz文件,但是下载失败,所以可以把手动下载的文件替换。
-
重新cmake
cmake -D CMAKE_BUILD_TYPE=Release -D CMAKE_INSTALL_PREFIX=/usr/local .. -
编译
make -j8 #编译编译是可能会有一些警告,因为我们没有安装CUDA造成的,我们只需要安装CPU版本的caffe,所以我们暂且可以忽视错误
-
编译成功后安装:
sudo make install #安装 -
测试OpenCV
安装完成后通过查看 opencv 版本验证是否安装成功:
pkg-config --modversion opencv
-
-
安装caffe
-
首先在你要安装的路径下 clone :
git clone https://github.com/BVLC/caffe.git如果像上面一样失败,就用本地下载,在上传到服务器。
-
进入 caffe ,将 Makefile.config.example 文件复制一份并更名为 Makefile.config ,也可以在 caffe 目录下直接调用以下命令完成复制操作 :
sudo cp Makefile.config.example Makefile.config -
修改 Makefile.config 文件内容:
vim Makefile.config-
应用 opencv 版本
将 #OPENCV_VERSION := 3 修改为: OPENCV_VERSION := 3 -
使用 python 接口
将 #WITH_PYTHON_LAYER := 1 修改为 WITH_PYTHON_LAYER := 1 -
修改 python 路径
INCLUDE_DIRS := $(PYTHON_INCLUDE) /usr/local/include LIBRARY_DIRS := $(PYTHON_LIB) /usr/local/lib /usr/lib 修改为: INCLUDE_DIRS := $(PYTHON_INCLUDE) /usr/local/include /usr/include/hdf5/serial LIBRARY_DIRS := $(PYTHON_LIB) /usr/local/lib /usr/lib /usr/lib/x86_64-linux-gnu /usr/lib/x86_64-linux-gnu/hdf5/serial -
修改boost library所在位置
PYTHON_LIBRARIES := boost_python2.7 python2.7m PYTHON_INCLUDE := /usr/include/python3.5m \ /usr/lib/python2.7/dist-packages/numpy/core/includ 修改为 PYTHON_LIBRARIES := boost_python3 python3.5m PYTHON_INCLUDE := /usr/include/python3.5m \ /usr/lib/python3.5/dist-packages/numpy/core/include
-
-
然后修改 caffe 目录下的 Makefile 文件:
将: NVCCFLAGS +=-ccbin=$(CXX) -Xcompiler-fPIC $(COMMON_FLAGS) 替换为: NVCCFLAGS += -D_FORCE_INLINES -ccbin=$(CXX) -Xcompiler -fPIC $(COMMON_FLAGS)将: LIBRARIES += glog gflags protobuf boost_system boost_filesystem m hdf5_hl hdf5 改为: LIBRARIES += glog gflags protobuf boost_system boost_filesystem m hdf5_serial_hl hdf5_serial -
开始编译了,在 caffe 目录下执行 :
make all -j8如果报错:
errorwhile loading shared libraries: libopencv_core.so.3.1解决的方法,安装ffmpeg:
sudo apt install ffmpeg重新编译
sudo make clean sudo make all -j8如果出现:
/usr/bin/ld: cannot find -lboost_python3 collect2: error: ld returned 1 exit status Makefile:584: recipe for target '.build_release/lib/libcaffe.so.1.0.0' failed make: *** [.build_release/lib/libcaffe.so.1.0.0] Error 1 make: *** Waiting for unfinished jobs....解决方法:
首先去/usr/lib/x86_64-linux-gnu目录下查看是否有python3版本的libboost,如果有类似libboost_python35.so但是没有libboost_python3.so则需要手动建立连接。
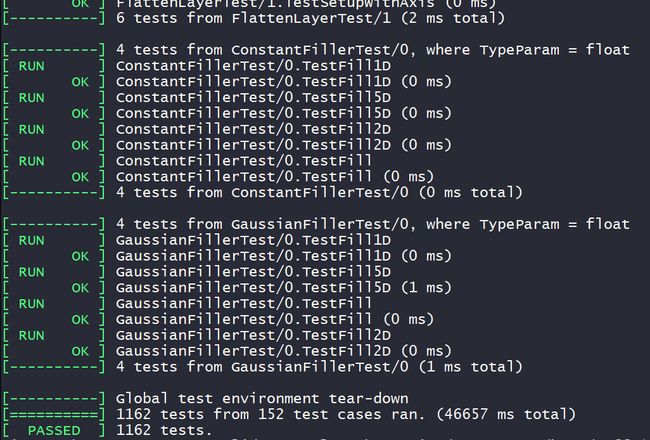
sudo ln -s libboost_python-py35.so libboost_python3.so测试caffe
sudo make runtest -j8看到这个图,说明Caffe成功安装:
-
安装 pycaffe 接口环境
在上一步成功安装 caffe 之后,就可以通过 caffe 去做训练数据集或者预测各种相关的事了,只不过需要在命令行下通过 caffe 命令进行操作,而这一步是 pycaffe 的安装,这样我们就可以用python操作caffe了。
- 首先编译 pycaffe :
$ sudo make pycaffe - 编译之后,引入环境变量:
source ~/.bashrc - 测试caffe
如果出现:# 打开默认的python环境 python # 输入: import caffe
执行:ImportError: No module named 'skimage'
重新编译sudo apt-get install python-skimage sudo pip install scikit-image --upgrade
测试:sudo make clean sudo make all -j8
如果没报错,说明pycaffe配置成功。# 输入python,打开默认python环境 python # 尝试引入caffe包 import caffe
- 首先编译 pycaffe :
最后,配置环境变量
你会发现当你再次登录的时候,pycaffe又不能用le,因为之前的环境变量是临时的,下面是将环境变量存到文件中,永久有效:
sudo vim /etc/profile
添加
# 这里的路径是caffe安装的路径
export PYTHONPATH=/path/to/caffe/python:$PYTHONPATH
这样就不用每次进入环境都需要导入一次环境变脸了。