《RabbitMQ实战指南》读书笔记——高级特性
高级特性部分偏运维,讲了很多配置和命令,简单了解,重点了解一下集群和负载均衡。
1、RabbitMQ管理
(1)多租户与权限
每一个RabbitMQ服务器能创建虚拟的消息服务器(vhost),拥有独立的Queue、Exchange、Bindings、权限等,提供了逻辑上的分离,默认创建的vhost为“/”,权限控制以vhost为单位。
rabbitmqctl是用来管理RabbitMQ中间件的命令行工具,连接各个RabbitMQ节点来执行所有操作,语法如下:
rabbitmqctl [-n node] [-t timeout] [-q] {command} [command options ...],默认的节点是rabbit@hostname,可以使用rabbitmqctl来分配vhost、设置权限、添加用户、管理集群、网络分区等所有操作。
(2)用户管理
用户是访问控制的基本单元,单个用户可以跨越多个vhost授权,有nono、management(可以访问Web管理页面)、policymaker(management所有权限,管理策略和参数)、monitoring(management所有权限,看到所有connection,channel和node)、administrator(monitoring所有权限,管理用户、vhost、权限等)五种用户角色。
(3)Web端管理
RabbitMQ management插件提供Web管理界面管理上述所有数据,还有监控和统计的功能,涵盖了RabbitMQ管理的所有功能。访问http://localhost:15672/,默认帐号/密码 guest/guest。
通常可以通过rabbitmqctl命令行、Web端和HTTP API三种方式管理RabbitMQ。
2、RabbitMQ配置和运维
RabbitMQ提供了环境变量(节点名称、配置文件地址、节点内部通信端口)、配置文件(TCP监听端口、网络、内存、磁盘设置)、运行时策略和参数(集群层面)三种方式定制化服务。
介绍一下参数和策略,绝大多数配置可以修改rabbitmq.config文件,需要重启Broker,Parameter支持动态修改,有vhost和global(集群)两种级别。策略(Policy)是vhost级别的,匹配多个exchange或者Queue,便于批量管理,也可以动态修改,用来配置federation、镜像、AE、死信队列等。
RabbitMQ集群即使Queue、Exchange都持久化,如果节点崩溃也会丢失消息(可以用镜像队列增加可靠性)。集群中的所有节点都会备份所有元数据信息(而非消息),包括Queue/Exchange的名称和属性、bindings、vhost元数据等。创建Queue、Exchange时只会在单个节点上创建队列的进程,包含完整的队列信息(元数据、状态、内容),其他节点只知道队列的元数据和指向该队列所在节点的指针,该集群节点崩溃时会丢失消息。集群延迟敏感,应当在局域网使用,广域网用Federation或者Shovel。
在集群中创建Queue、Exchange。Bindings时,需要等到所有节点都成功提交了元数据变更之后才会返回,对于磁盘节点来说意味着昂贵的磁盘写入操作。集群状态中的disc标注了节点类型(内存节点或者磁盘节点),集群中至少有一个磁盘节点存储元信息。如果唯一的磁盘节点崩溃,集群可以发送、接收消息,但不可以进行元数据操作(创建Queue、Exchange、bindings,更改权限等),集群中应该保证两个以上的磁盘节点。内存节点唯一存储到磁盘的元数据信息是磁盘节点的地址,用于重新加入集群。
查看服务日志时,可以查阅RABBITMQ_NODENAME.LOG文件,日志级别有none、error、warning、info、debug五种,默认info。RabbitMQ默认创建amq.rabbitmq.log交换器来收集日志。类型为topic,采集不同级别的日志。
集群迁移时,需要进行元数据重建、数据迁移和客户端连接的切换。元数据重建可以通过Web端下载源数据,再进行JSON解析、创建。数据迁移原理是先消费,存入缓存区,再读取缓存区向新集群发布消息。
可以通过AMQP-ping检查客户端和Broker的连接。
3、分布式部署:集群、Federation、Shovel
(1)Federation
联邦交换器,适合异地消费的场景。
如图,上游业务broker1想要向broker3中的exchangeA发送消息(两者地理上相隔很远,延迟很大),会先建立Federation link,在broker1中建立同名ExchangeA(联邦交换器),并建立一个队列,federation插件在broker1的队列和broker3的exchangeA之间建立一条AMPQ连接,经过Federation link转发的消息会带有特殊的headers属性。Federation完成了消息转发的过程和内部复杂的编程逻辑,业务方编码不用考虑网络延迟,可以异地部署。Federation还有多叉树、环形拓扑等多种复杂结构。
联邦队列,在多个Broker间为单个队列提供负载均衡。
如图,Broker1作为upstream,消费者连接Broker2。如果Broker2中的Queue1/Queue2有消息堆积,则不会从Broker1中拉取,没有消息时通过Federation link拉取Broker1中的消息(如图时单向联邦队列,也可以部署为双向的)。
一条消息可以在联邦队列间转发无数次,而联邦交换器转发有次数限制。如果要从Broker1中拉取消息,需要阻塞等待通过Federation link拉去消息之后在消费,所以不能使用Basic.Get。
(2)Shovel
与Federation的数据转发类似,Shovel能够可靠持续的从一个Broker中的队列(源端)拉取数据转发到另一个Broker中的交换器(Queue到Exchange,而联邦是Exchange到Exchange,或者Queue到Queue),如图。
通常配置队列为源端,交换器为目的端。也可以将队列配置为目的端,中途经过了默认交换器的转发,实质上也是Queue到exchange,配置交换器作为源端同理。消息堆积严重时,可以通过Shovel将队列中的消息移交给另一个集群。
(3)Federation/Shovel和集群的对比
Federation/Shovel工作在多个Broker节点之间,,可以在广域网中相连,从CAP中选择了AP,可用性和分区耐受性;集群逻辑上是一个Broker节点,在局域网中双向连接所有其他节点,从CAP中选择了CA,一致性和可用性。
4、高级特性
(1)存储机制
不管消息是否持久化,都可以被写入磁盘(非持久化消息内存吃紧时写入磁盘)。队列消息会处于四种状态之一(1)消息内容和消息索引都在内存(2)消息在磁盘,索引在内存(3)消息在磁盘,索引内存磁盘都有(4)都在磁盘。队列内部通过五个子队列体现消息的各个状态,当消息状态改变时会进入不同的队列。
惰性队列会尽可能将消息存入磁盘,支持更长的队列,当长时间不能消费消息时可以避免频繁换页。不适合消息能力很强的场景,适合大量消息(千万级)的场景。对于普通队列,发送一千万条消息速度约13000/s,惰性队列24000/s,因为普通队列会频繁换页。
当内存或磁盘使用超过阈值,会阻塞Connection并停止接受消息,客户端和Broker的心跳检测也会失效。在一个集群里,内存或磁盘受限,会引起集群里所有Connection被阻塞。通常内存阈值是40%,因为Erlang GC最坏情况下会导致两倍内存消耗。
(2)流控
内存和磁盘告警是全局流控,阻塞所有Connection,也有针对单个Connection的流控。通过监控各进程的进程邮箱,如果消息堆积到一定数量阻塞上游消息。只要该进程阻塞,上游的进程会全部阻塞,第一个不处于flow状态(阻塞状态)的下游是性能瓶颈。
(3)打破队列的瓶颈
封装队列,Exchange一对多个队列,进行封装(消费者轮询接收消息,或者将多个队列的消息推送至BlocknigQueue供消费者消费)。
(4)镜像队列

如图,一主两从,环形结构,master失效时最老的slave晋升为master。发送到镜像队列的所有消息被同时发往slave,master先确认,继而slave1、slave2确认,返回给master,这样才算一个ACK。除发送消息外的所有动作只向master发送,比如消费者向slave请求Basic.Get,slave会将请求转发给master,master返回数据,由slave投递给消费者。
镜像队列使用一种可靠的组播通信协议,该协议能够保证组播消息的原子性。除非master挂掉而且所有slave都处于未同步状态,未同步的消息才会丢失。
5、网络分区
网络分区时,不同分区里的节点会认为不属于自身所在分区的节点都已经挂了,对 queue、exchange、binding 的操作仅对当前分区有效。在 RabbitMQ 的默认配置下,即使网络恢复了也不会自动处理网络分区带来的问题从而恢复集群。
RabbitMQ(3.1+)会自动探测网络分区,并且提供了配置来解决这个问题。
(1)ignore:默认配置,发生网络分区时不作处理,当认为网络是可靠时选用该配置
(2)pause_minority:分区发生后判断自己所在分区内节点是否超过集群总节点数一半,如果没有超过则暂停这些节点(保证 CP,总节点数为奇数个)
(3)pasue_if_all_down:节点在和任何节点不能交互时关闭
(4)autoheal:客户端连接最多的分区获胜,重启其他分区节点,恢复集群(CAP 中保证 AP,有状态丢失)
6、扩展
Firehose功能实现消息追踪,发送、消费时按指定格式发送到默认交换器上,实现追踪。
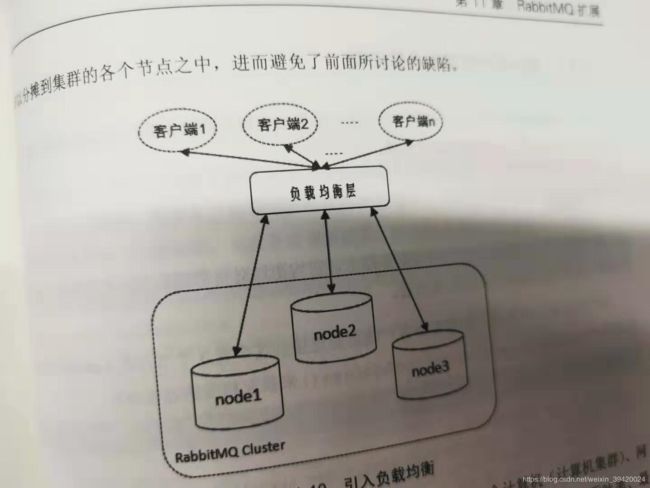
负载均衡:使用轮询法、加权轮询法、随机法、加权随机、源地址哈希(同一IP地址的客户端映射到同一服务器)等方法,可以使用HAProxy或者LVS(使用了IP隧道技术,将IP报文封装进另一IP报文,可转发到另一IP),配合Keepalived(双机热备,避免负载均衡层挂掉,无法访问所有服务器)。