Python爬虫实战Scrapy抓取商品信息并写入数据库
本文介绍了Scrapy 框架爬取当当图书信息,并将结果写入mysql数据库中。
系列文章
Python3 基础教程最全总结
Python3 进阶教程最全总结
一文掌握Python基础知识
一文掌握Python列表/元组/字典/集合
一文掌握Python函数用法
Python面向对象之类与对象详解
Python面向对象之装饰器与封装详解
Python面向对象之继承和多态详解
Python异常处理和模块详解
Python文件(I/O)操作详解
Python网络编程之Socket原理与基本用法
Python多线程threading模块基本用法
Python爬虫正则表达式详解 爬爬爬爬个虫子
Python爬虫实战Urllib抓取段子
Python爬虫实战抓包分析视频评论
Python爬虫实战Requests抓取博客文章
Python爬虫实战Scrapy抓取商品信息并写入数据库
文章目录
- 系列文章
- 1 Scrapy 框架
- 1.1 简介
- 1.2 常用指令
- 2. 基本使用
- 3. Scrapy实战:爬取当当网商品数据
- 3.1 图书名称字段分析
- 3.2 图书评论数字段分析
- 3.3 商品链接字段分析
- 3.4 不同页码的URL变化规律分析
- 4. 完整代码
- 4.1 创建爬虫项目
- 4.2 修改items.py文件
- 4.3 修改/创建爬虫文件dd_books.py
- 4.4 编写pipeline.py文件
- 4.5 修改setting.py
- 4.6 命令行启动爬虫
需要安装的包:
- pip install wheel
- pip install twisted
- pip install lxml
- pip install scrapy
建议使用Anaconda Prompt安装。
1 Scrapy 框架
1.1 简介
Scrapy是一个为了爬取网站数据,提取结构性数据而编写的应用框架。可以应用在包括数据挖掘,信息处理或存储历史数据等一系列的程序中。
其最初是为了 页面抓取 (更确切来说, 网络抓取 )所设计的, 也可以应用在获取API所返回的数据(例如 Amazon Associates Web Services ) 或者通用的网络爬虫。
1.2 常用指令
scrapy startproject tutorial:创建爬虫项目;scrapy genspider -l:查看爬虫模板;scrapy genspider -t basic example example.com(实例):模板basic,爬虫文件名example,域名example.com;scrapy crawl:运行爬虫;scrapy list:列出当前项目中所有可用的spider。每行输出一个spider。
2. 基本使用
1.打开命令行,输入以下指令,创建scrapy project
scrapy startproject FirstProject
2.工程目录结构
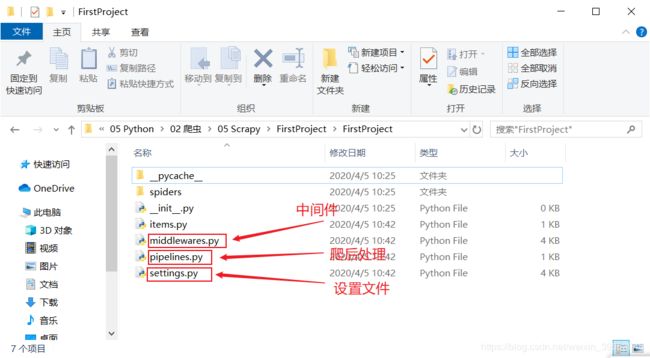
3.进入工程,查看爬虫模板:
>cd FirstProject
>scrapy genspider -l
Available templates:
basic
crawl
csvfeed
xmlfeed
4.创建爬虫,注意是域名,不包含主机名(比如www.);
比如假设爬取CCTV5天下足球的视频,网址为:http://tv.cctv.com/lm/txzq/videoset/,生成之后还可以在程序中修改,写错了也没关系,只是修改程序的时候,注意有一个字段是域名。
>scrapy genspider -t basic first cctv.com/lm/txzq/videoset/
Created spider 'first' using template 'basic' in module:
FirstProject.spiders.first
创建好的文件:

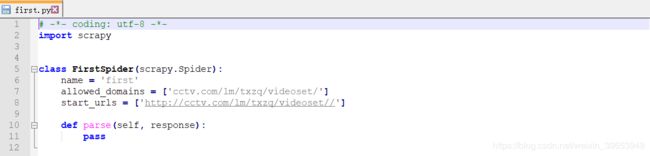
5.运行爬虫
>scrapy crawl first
6.查看当前可用的爬虫
>scrapy list
7.查看scrapy指令
>scrapy
3. Scrapy实战:爬取当当网商品数据
编写一个Scrapy 爬虫项目流程:
- 创建爬虫项目;
- 编写 items;
- 创建爬虫文件;
- 编写爬虫文件;
- 编写pipelines;
- 配置settings;
当当网计算机图书类主页:http://category.dangdang.com/cp01.54.26.00.00.00.html
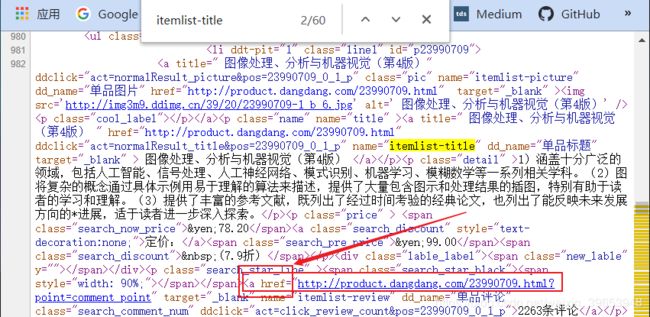
3.1 图书名称字段分析
打开上述页面,右击空白处,查看网页源码,找到如下字段,经过分析和搜索结果,可以确定该字段包含了图书标题信息。可以通过商品界面的评论数进行定位,然后确定包含商品名称的字段。
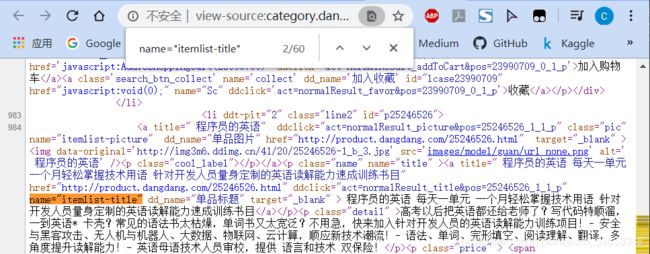
3.2 图书评论数字段分析
分析完图书名称字段后,分析评论数字段,经过查找,可以确定如下字段为包含商品评论数的字段,我们可以使用此字段来构建正则表达式。
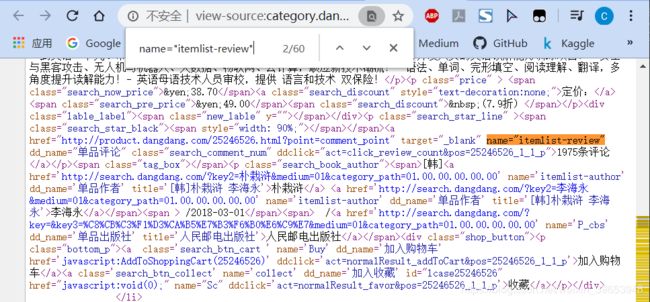
3.3 商品链接字段分析
经过分析我们可以知道,商品链接字段包含在商品名称字段的href属性中,因此可以利用此来构建正则表达式。
3.4 不同页码的URL变化规律分析
当当网每页显示60条结果,如果需要进行翻页处理,则需要对不同页码的URL变化规律进行分析。我们先将第1-5页的网页链接粘贴到word文档中,方便对比,不同页码的URL如下图所示:
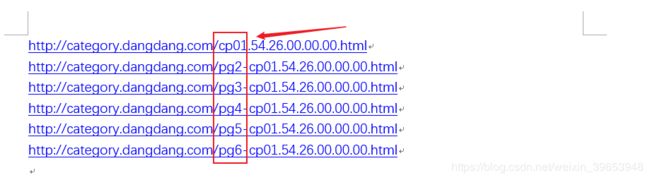
可以看到只有pg字段发生了变化,但是第一页不含该字段,我们可以此猜想,第一页的URL为:http://category.dangdang.com/pg1-cp01.54.26.00.00.00.html,如果打开跟上图中第一页的URL打开界面是相同的,则可证明我们的猜想是正确的。经过验证,的确是,因此我们可以据此构建页码变化时,URL的变化规律。
4. 完整代码
4.1 创建爬虫项目
scrapy startproject dangdang
cd dangdang
scrapy genspider dd_books dangdang.com
4.2 修改items.py文件
import scrapy
class DangdangItem(scrapy.Item):
# define the fields for your item here like:
title = scrapy.Field()
link = scrapy.Field()
comment = scrapy.Field()
4.3 修改/创建爬虫文件dd_books.py
import scrapy
from dangdang.items import DangdangItem
from scrapy.http import Request # 实现翻页
class DdBooksSpider(scrapy.Spider):
name = 'dd_books'
allowed_domains = ['dangdang.com']
start_urls = ['http://category.dangdang.com/pg1-cp01.54.26.00.00.00.html']
def parse(self, response):
item = DangdangItem()
item["title"] = response.xpath("//a[@name='itemlist-title']/@title").extract()
item["link"] = response.xpath("//a[@name='itemlist-title']/@href").extract()
item["comment"] = response.xpath("//a[@name='itemlist-review']/text()").extract()
yield item
for i in range(2, 3):
url = "http://category.dangdang.com/pg"+str(i)+"-cp01.54.26.00.00.00.html"
yield Request(url, callback=self.parse)
4.4 编写pipeline.py文件
此部分实现了写入PyMySQL数据库的操作,如果没配置mysql需要先配置,如果不想写入,这部分注释掉就好了。
import pymysql
class DangdangPipeline(object):
def process_item(self, item, spider):
conn = pymysql.connect("localhost", "root", "mysql105", "ddbooks", charset='utf8')
for i in range(0, len(item["title"])):
title = item["title"][i]
link = item["link"][i]
comment = item["comment"][i]
sql = "insert into dangdang(title, link, comment) values('"+title+"', '"+link+"', '"+comment+"')"
conn.query(sql)
conn.commit()
conn.close()
return item
4.5 修改setting.py
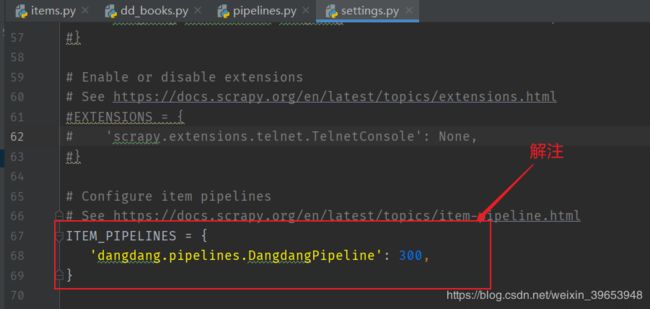
4.6 命令行启动爬虫
(keras)D:\Project\05 Python\02 爬虫\05 Scrapy\dangdang>scrapy crawl dd_books
输出:
数据库中的结果:
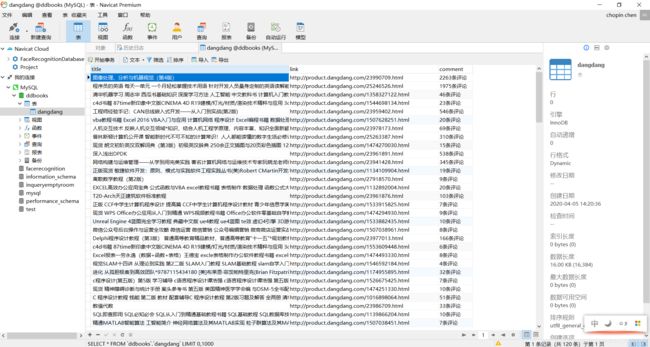
注意:修改pymysql 的connections模块,以防乱码,charset 设置为 utf8,不是utf-8!
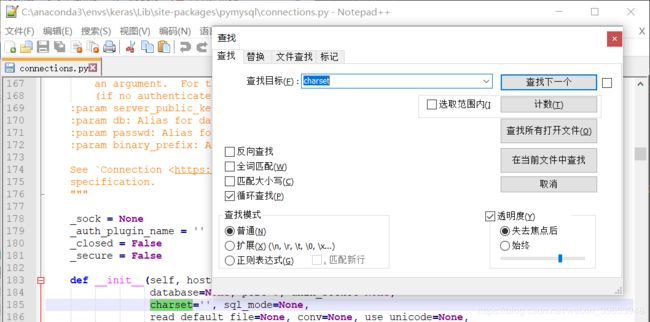
参考:
Scrapy官方文档:https://doc.scrapy.org/en/latest/intro/tutorial.html
Scrapy中文文档:https://scrapy-chs.readthedocs.io/zh_CN/latest/intro/overview.html
相关课程:https://edu.aliyun.com/course/1994