python搭建IP池
,都说标题是文章的灵魂,想了半天没想到什么比较有创意的标题,只好百度了一个。啊哈哈哈哈哈哈,朕真是太机智了

这是一篇介绍如何使用python搭建IP池的文章,如果爱卿对此不感兴趣,那很抱歉,标题耽误了你宝贵的时间。

事情的起因是这样,前段时间我写了一篇介绍如何爬取小说的blog【python那些事.No2】,在爬取的过程中,发现同一个IP连续只能获取前几页小说内容,原本是想搭建IP池绕过这个限制的,奈何项目上来了新任务,为了在被关进小黑屋之前把文章发布出来,就想了一个折中的办法–延时获取。

没想到文章发出来后,竟然还有人评论催更 搭建IP池。朕当时就龙颜大怒,长这么大朕何时受过这种气啊。从来都是朕催更那些小说作者,被别人催更还是头一遭
但是打又打不到,骂又骂不得,咋办?想了想那还是更吧。

众所周知,由于python爬虫这种简单易学的技术普及之后,为了网站的稳定运行和网站数据的安全,越来越多的网站对爬虫做各式各样的限制和反扒措施。其中,限制一定时间内同一IP的请求次数似乎已经成为了最常见的手段。
很多时候,使用延时获取的方式–‘在两次请求之间sleep一定的时间’ 可以解决网站对爬虫的限制。可是像朕这种年轻人,想要的现在就要,怎么办呢?

既然是对同一IP的限制,那就意味着两次请求的IP如果不同,此限制就形同虚设。
One way of thinking 去网上买代理IP。搞这个业务的有很多,不过真正哪个服务提供商的有效IP率最高,还需要各方仔细斟酌
Another way of thinking 自己搭建IP池。毕竟对朕这种吃一碗面都还要犹豫加不加煎蛋的社畜来说,买代理IP这种事情,是万万干不出来的。那么这个时候,就有必要了解一下如何搭建IP池,以及如何提高IP池的有效IP率

先介绍一下搭建IP池的基本思路:
1.找免费代理IP网站:网上代理IP网站有很多,大多都是免费+收费模式。如西刺代理、89免费代理、快代理等。
2.分析页面,获取数据(IP、端口、类型)并存储(多存于数据库,方便存取和分析)
3.筛选、过滤:为了保证IP的有效性,有必要对获取的免费代理IP进行过滤和筛选,去掉不可用的和重复的

本文以西刺代理的国内高匿代理IP为例:
地址请在代码里查找,或者自行百度
页面大概长这样:
先写一个方法获取所有页面url并put入队,【原理:获取页面 下一页按钮的href值,并组装】。
warning:访问速度别太快,很容易被西刺封IP(经过朕的亲自测试,确定西刺官网的封IP机制很灵敏),下同,切记。如果你不幸被封,可以切换网络继续(如:将WIFI切换成手机热点),或者等第二天西刺会将IP解封。
#获取页面URL
def get_url(start_url,queue):
while True:
print(start_url)
#生成请求代理信息
headers = random.choice(header_list)
# 获取页面信息
response = requests.get(url=start_url, headers=headers)
# 获取请求状态码
code = response.status_code
#将页面URL入队
queue.put(start_url)
if code == 200:
html = et.HTML(response.content.decode('utf-8'))
#获取信息
r = html.xpath('//a[@rel="next"]/@href')
if r:
#拼接下一页的url
start_url = 'https://www.xicidaili.com/' + r[0]
else:
#跳出循环,页面url获取完成
break
else:
print(code)
time.sleep(2)
print('Get url complete')
然后写一个方法获取页面中(页面地址从队列get)我们所需要的那些信息,包括IP、类型、端口。【分析页面可得,我们所需要的信息在一个非常整齐的table里面,只需要取相应的td就行】
#获取页面IP信息
def get_info(queue):
while not queue.empty():
#休息一下
time.sleep(3)
#生成请求代理信息
headers = random.choice(header_list)
#从队列获取页面url
page_url = queue.get()
queue.task_done()
print(page_url)
# 获取页面信息
response = requests.get(url=page_url, headers=headers)
# 获取请求状态码
code = response.status_code
#页面所有代理IP信息存储
data_map = []
if code == 200:
html = et.HTML(response.content.decode('utf-8'))
#获取信息
r = html.xpath('//tr[position()>1]')
for i in r:
#每一个tr中的信息
data = {
'ip' : ''.join(i.xpath(".//td[2]//text()")),
'port' : ''.join(i.xpath(".//td[3]//text()")),
'type' : ''.join(i.xpath(".//td[6]//text()"))
}
#汇总
data_map.append(data)
#【一种更优雅的获取表格数据方式:pandas】
#存储
db_save(data_map)
else:
print(code)
print('It is NUll')
当然还需要一个存储方法,存入数据库是为了方便分析、验证和调用(你当然也可以存入文件)
#插入数据库
def db_save(data):
conn = mysql.connector.connect(user='root',password='root',database='test')
for k in data:
try:
cursor = conn.cursor()
cursor.execute('insert into ip_pool (ip, port, type) values (%s, %s, %s)', [k['ip'], k['port'], k['type']])
conn.commit()
print('【OK】数据插入成功,IP:',k['ip'])
except Exception as e:
print('【ERROR】数据插入失败:',e)
finally:
cursor.close()
conn.close()
既然要存数据库,那肯定要建个数据表(此处提供一个数据表简单demo):
# Host: localhost (Version: 5.7.26)
# Date: 2020-01-19 13:47:45
# Generator: MySQL-Front 5.3 (Build 4.234)
/*!40101 SET NAMES utf8 */;
#
# Structure for table "ip_pool"
#
DROP TABLE IF EXISTS `ip_pool`;
CREATE TABLE `ip_pool` (
`Id` int(11) NOT NULL AUTO_INCREMENT,
`ip` char(16) DEFAULT NULL COMMENT 'ip',
`port` char(5) DEFAULT NULL COMMENT '端口号',
`type` char(5) DEFAULT NULL COMMENT '类型',
`created_at` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP,
`updated_at` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP,
PRIMARY KEY (`Id`)
) ENGINE=MyISAM DEFAULT CHARSET=utf8;
整理整理思路,得如下代码:
#IP池搭建 西刺代理
import requests
import random
from lxml import etree as et
from queue import Queue #导入queue模块
import time #导入time模块
import mysql.connector #导入数据库模块
import threading #导入threading模块
#常用请求代理
header_list = [
{"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.86 Safari/537.36"},
{"User-Agent":"Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.25 Safari/537.36 Core/1.70.3676.400 QQBrowser/10.4.3469.400"},
{"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/79.0.3945.117 Safari/537.36"},
{"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.102 Safari/537.36 Edge/18.18362"}
]
#插入数据库
def db_save(data):
conn = mysql.connector.connect(user='root',password='root',database='test')
for k in data:
try:
cursor = conn.cursor()
cursor.execute('insert into ip_pool (ip, port, type) values (%s, %s, %s)', [k['ip'], k['port'], k['type']])
conn.commit()
print('【OK】数据插入成功,IP:',k['ip'])
except Exception as e:
print('【ERROR】数据插入失败:',e)
finally:
cursor.close()
conn.close()
#获取页面URL
def get_url(start_url,queue):
while True:
print(start_url)
#生成请求代理信息
headers = random.choice(header_list)
# 获取页面信息
response = requests.get(url=start_url, headers=headers)
# 获取请求状态码
code = response.status_code
#将页面URL入队
queue.put(start_url)
if code == 200:
html = et.HTML(response.content.decode('utf-8'))
#获取信息
r = html.xpath('//a[@rel="next"]/@href')
if r:
#拼接下一页的url
start_url = 'https://www.xicidaili.com/' + r[0]
else:
#跳出循环,页面url获取完成
break
else:
print(code)
time.sleep(2)
print('Get url complete')
#获取页面IP信息
def get_info(queue):
while not queue.empty():
#休息一下
time.sleep(3)
#生成请求代理信息
headers = random.choice(header_list)
#从队列获取页面url
page_url = queue.get()
queue.task_done()
print(page_url)
# 获取页面信息
response = requests.get(url=page_url, headers=headers)
# 获取请求状态码
code = response.status_code
#页面所有代理IP信息存储
data_map = []
if code == 200:
html = et.HTML(response.content.decode('utf-8'))
#获取信息
r = html.xpath('//tr[position()>1]')
for i in r:
#每一个tr中的信息
data = {
'ip' : ''.join(i.xpath(".//td[2]//text()")),
'port' : ''.join(i.xpath(".//td[3]//text()")),
'type' : ''.join(i.xpath(".//td[6]//text()"))
}
#汇总
data_map.append(data)
#【一种更优雅的获取表格数据方式:pandas】
#存储
db_save(data_map)
else:
print(code)
print('It is NUll')
# 主函数
if __name__ == "__main__":
#开始页URL
start_url = 'https://www.xicidaili.com/nn/'
#用Queue构造一个大小为1000的线程安全的先进先出队列
page_url_queue = Queue(maxsize=1000)
#创建一个线程抓取页面url
t1 = threading.Thread(target=get_url, args=(start_url,page_url_queue))
#开始线程
t1.start()
time.sleep(2)
#创建一个线程分析页面信息,并存储
t2 = threading.Thread(target=get_info, args=(page_url_queue,))
t2.start()
#结束线程
t1.join()
t2.join()
print('the end!')
一运行:
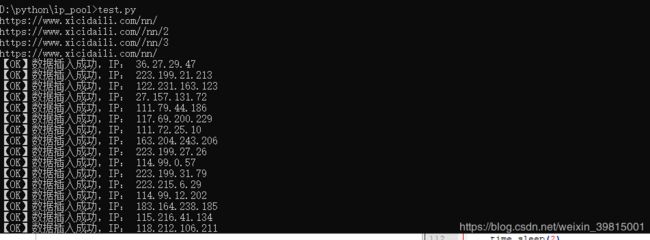
哎哟,我去。BUG?不存在的

打开数据库看看:

呵,整整齐齐

当然,免费代理IP大部分都是无效的。
所以,需要将获得的IP再进行有效性校验,删掉不可用的,保证我们在需要的时候取到的IP可用。
这里提供几个思路:
1.在插入数据库之前,先检查一下该代理IP是否可用,如果不可用,则直接下一个
2.由于有的代理IP有效期很短,所以需要定时检测数据表中代理IP的有效性,去掉不可用的
3.在使用之前,从数据库中取出的IP,先判断该IP的有效性。
自建IP池完整代码,git地址:~~在不久的将来,此处将会有一个git地址
眼泪不是答案,拼搏才是选择。只有回不了的过去,没有到不了的明天。
所有的不甘,都是因为还心存梦想,在你放弃之前,好好拼一把,只怕心老,不怕路长。
The end !