Coursera北大《数据结构基础》之线性表
本文基于Coursera北大课程《数据结构基础》,所有文中非标注图片均来自课件,侵删
线性结构是最简单而应用最广泛的一种数据结构,在不同的场合会采取不同的存储结构和实现方法。
本模块将介绍一种简单的线性结构——线性表,就是同类型的元素排成的一个线性序列,并且介绍了线性表的两种实现方法,即顺序表和链表。
重点:线性结构的逻辑定义,线性表的各种分类,顺序表、链表的定义和相关操作。
难点:注意顺序表、链表的各种时间空间效率讨论,包括插入删除检索等在各种概率分布情况下的讨论。链表要特别注意表头结点的作用,链表指针的正确操作。
1. 线性表
1.1 什么是线性表
线性表(表)是由大于等于0个元素组成的有穷序列。线性表操作十分灵活,长度可增可减。
下图是一个表长为n的线性表(当n=0时为空表),每个元素a称为表目(或者记录),a的下标称为索引。

1.2 线性结构定义
对于一组线性表{a0, a1, a2, ..., an-1},我们可以用二元组B=(K,R)的形式表示。K表示knots, R表示replationship。
那么线性结构的B=(K,R),其中K={a0, a1, a2, ..., an-1},R={r},r为前驱/后继关系。a0是唯一的开始结点,它没有前驱,有一个唯一的直接后继;类似的,an-1为唯一的终止结点,它没有后继,有一个唯一的直接前驱。其它从a1到an-2的结点都被称作内部结点,每个内部结点有且仅有唯一一个直接前驱和直接后继。
前驱/后继关系具有反对称性(ai和ai+1的前驱/后继关系无法逆转)和传递性(若ai是aj的前驱,aj是ak的前驱,那么ai也是ak的前驱)。
1.3 线性结构特点
(1)均匀性
对于同一线性表,各数据元素必须具有相同的数据类型和长度。
(2)有序性
正是因为线性结构简单易懂的顺序才使得它很好操作。各个元素在线性表中都有自己的位置,并且元素之间的相对位置是线性的。
1.4 线性结构的分类
通过不同的方面可以进行不同划分:
1.4.1 按复杂程度划分
简单的:线性表,栈,队列,散列表
高级的:广义表,多维数组,文件等
1.4.2 按访问方式划分
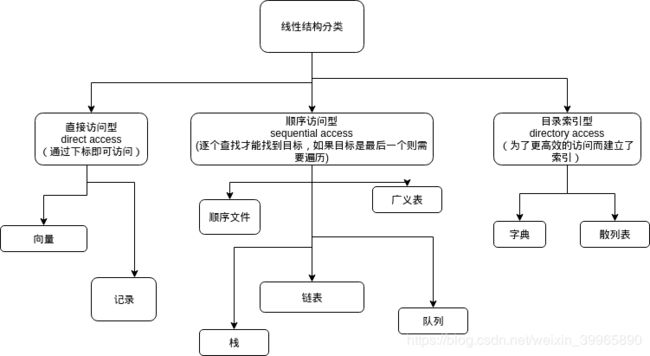
1.4.3 按操作方式划分
(1)线性表
(2)栈(LIFO, last in first out)
插入和删除操作只能在表的同一端进行
(3)队列(FIFO, first in first out)
插入操作在表的一端,则删除在另一端
2 顺序表和链表
2.1 顺序表
线性表根据存储方式的不同可以分为顺序表和链表两大类型,接下来就来一一介绍。
顺序表通常称为向量,使用数组(表目需要同类型,定长)实现的。顾名思义,就是表目按照index从小到大排列。只要确定了首地址,线性表中的任意元素都可以随机存取。
对于一组顺序表{a0, a1, a2, ..., an-1},a0的地址已知,那么计算第k个元素的地址公式为:Loc(ak)=Loc(a0)+c*k,c为每个元素的长度,Loc表示地址。
2.1.1 顺序表增加元素
对于表的操作可以有增加(插入)、删除、修改、查找,这里只介绍插入和删除。
在顺序表中插入一个元素很好理解:对于一组顺序表{a0, a1, a2, ..., an-1},我们想在a4和a5之间插入一个新的元素ak,那么,我们需要将a5到an-1的所有元素后移一位,为ak腾出一个位置,如下图所示。然后我们将ak插入a4之后,组成新的顺序表。

2.1.2 顺序表删除元素
顺序表删除元素也很简答, 接上例,如果要删除a5,只需要把a6到an-1的元素全部前移一个位置。
2.1.3 顺序表插入和删除元素的算法效率分析
(1) 在一个长度为n的顺序表中在第i位插入一个元素,需要移动n-i个元素。那么设每个位置被插入的概率为pi, 那么在第i个位置插入一个元素时要移动的元素的期望则为)(注意这里的i的取值范围是到n的):
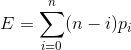
如果每个位置被插入的概率都是相等的,那么
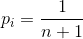
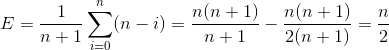
(2) 对于在一个长度为n的顺序表中删除一个元素,我们可以使用类似方法,得到期望为:

此处pi为删除一个位置i上的元素的概率,如果是等概率,则
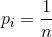

根据Coursera北大《数据结构基础》之概论中的大O表式法,n/2和(n-1)/2是在同一个量级的,时间代价都为O(n)。
2.2 链表 (linked list)
链表通过指针来表达数据元素之间的逻辑关系。每个存储结点有两部分构成:指针和值。
链表可以通过链接方式和指针数量进行分类:单链、双链、循环链。
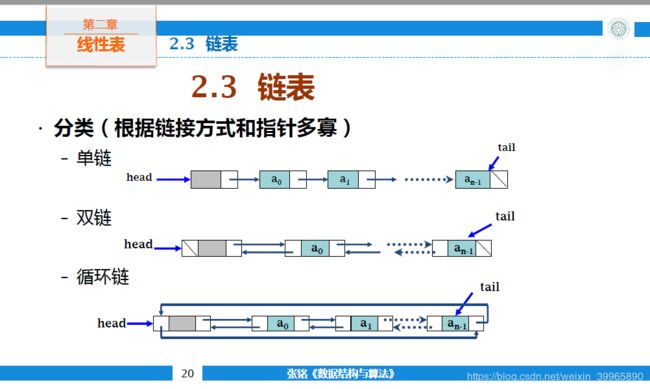
——摘自课程
2.2.1 单链表
单链表又可以分为头结点直接指向链表的第一个元素和单另放出来两种。
当head直接指向第一个链表元素,第一个节点就是head,空表判断就是head==NULL;
在带头结点的单链表中,第一个元素是head所指向的一个虚结点,head永不为空。当表示一个元素时,往往用前驱结点表示。
2.2.2 单链表的删除
和顺序表不同,单链表的每个存储单元都有一个对应的指针和值,所以在做删除和增加时,要更加麻烦一些。
单链表的运算都必须从第一个结点开始。
例如删除链表第i个元素时,需要把i-1的指针指向i+1元素(即改变直接前驱结点),然后才能删除第i个元素,释放第i个元素占据的空间(如下图所示)。要注意如果是删除最后一个元素,那么要保证新链表的最后一个元素指向空,以此停止对单链的遍历。
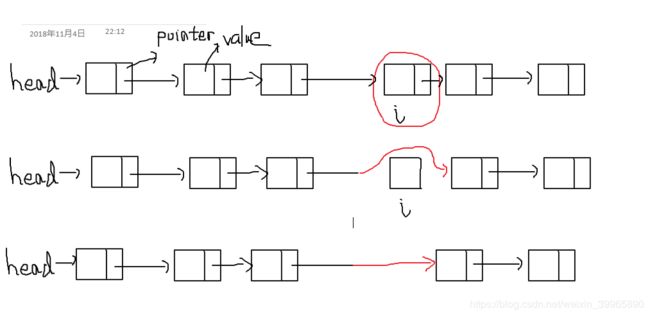
单链表的增加同理。
单链表的增加和删除时间复杂度都是O(1)【但是找到第i个元素运算代价为O(n)】.
2.2.3 双链表
单链表在找前驱时很麻烦,为了弥补这个不足,产生了双链表。双链表删除和增加的核心思想其实和单链表是一样的。

——摘自课程
2.2.4 循环链表
循环链表就是将单链表或者双链表的头和尾链接起来,“不增加额外的花销,却给不少操作带来了方便”(摘自课程)。这里,尾部的next链是指向head的。
3. 顺序表和链表的对比
顺序表没有指针(没有结构性存储开销),需要事先申请空间(如果空间不够可能申请失败),操作便捷易于理解(直接通过下表就可完成查找);顺序表适合静态数据存储。
链表无需事先指定线性表大小(但是由结构性存储开销,查找必须从表头开始),动态操作,很灵活;链表适合动态数据存储。
当数据越多,顺序表的空间效率就越高(临界值为指针的存储单元和数据元素存储单元大小相等时产生,值为可以在数组中存储的线性表元素的最大数目的一半)。