图卷积(二)-图神经网络
二、图卷积
- 结点映射
- 从“浅”到“深”
- 浅层编码的限制
- 使用图卷积来进行更加复杂的映射
- GCN
- 图卷积基础
- 模型训练
- 模型概述
- 归纳能力
- 小结
- 图卷积网络
- graphSAGE 观点
- 门卷积网络的观点
- MPNN(Message-Passing Neural Networks)
- 图attention 网络
- 注意力权重
- 通常的注意力(融合到message中)
- (子)图嵌入
接上一部分:https://blog.csdn.net/weixin_40248634/article/details/103040193
GCN只是GNN的一种,Graph可以跟卷积结合,也可以跟RNN,GRE结合。
这一部分的大纲:
- The Basics
- Graph Convolutional Networks
- GraphSAGE
- Gated Graph Neural Networks
- Graph Attention Networks
- Subgraph Embeddings
结点映射
目标是将原始空间的相似性也体现在映射空间中。
 目标: s i m i l a r t y ( u , v ) ≈ z v T z u similarty(u,v)\approx z_v^Tz_u similarty(u,v)≈zvTzu
目标: s i m i l a r t y ( u , v ) ≈ z v T z u similarty(u,v)\approx z_v^Tz_u similarty(u,v)≈zvTzu
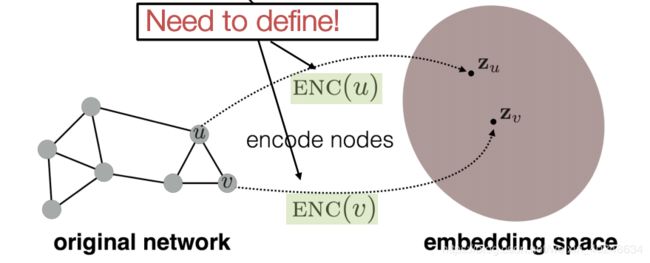 两个关键组件:
两个关键组件:
- 将每个点映射到一个低维向量

- 相似性函数指定向量空间中的关系如何映射到原始网络中的关系。

从“浅”到“深”
浅层编码器我们可以将节点矩阵映射到一个特定的矩阵Z ,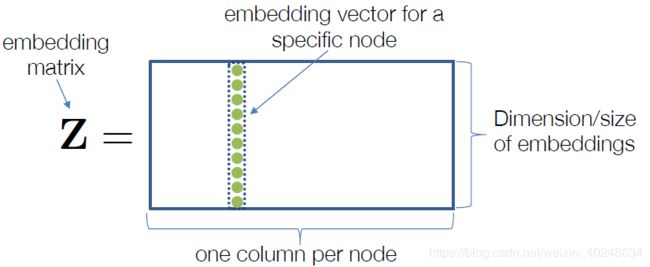
矩阵的每一列表示一个节点。
浅层编码的限制
1.需要 O ( ∣ V ∣ ) O(|V|) O(∣V∣)参数,每个节点有自己特定的编码
2.固定的“转换性”:不可能为在训练期间没有的节点生成嵌入
3.不能合并节点特性:许多图具有我们可以并且应该利用的特性
使用图卷积来进行更加复杂的映射
 通常来说,所有的复杂映射都可以用之前的相似的函数组合起来。
通常来说,所有的复杂映射都可以用之前的相似的函数组合起来。
GCN
下面是基于图卷积网络的深度编码方法
图卷积基础
v: 顶点集
A:邻接矩阵
X:节点特征矩阵
关键思想:
基于局部领域信息产生节点嵌入
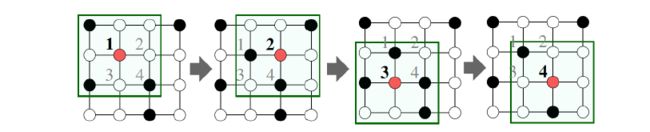
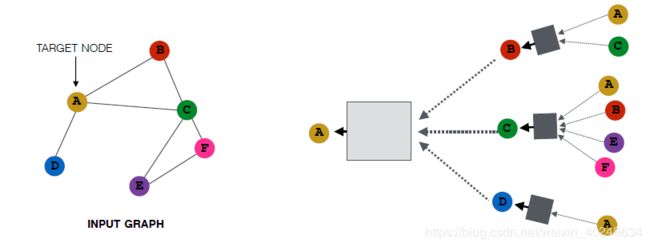 here,将A的领域信息整合起来,其一阶领域有BDC,让然后BCD又有其对应的一阶信息,右边图相当于是二阶领域信息整合。
here,将A的领域信息整合起来,其一阶领域有BDC,让然后BCD又有其对应的一阶信息,右边图相当于是二阶领域信息整合。
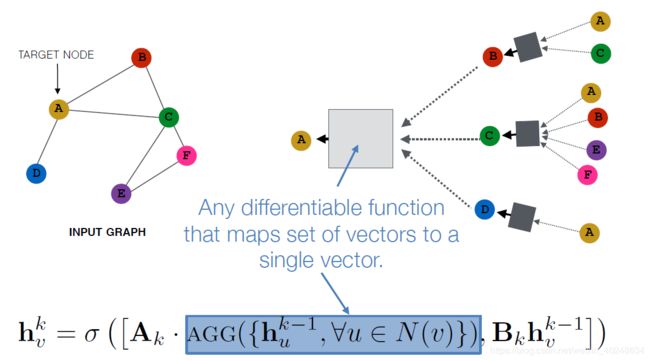
直观上:用神经网络将节点信息整合起来,每个节点具有其对应的计算图
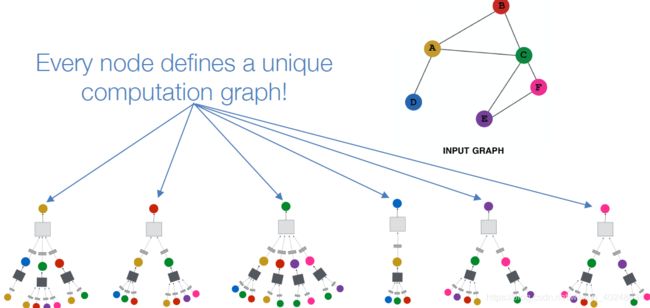 节点在每一层进行映射,模型有任意的深度,第0层是其输入特征
节点在每一层进行映射,模型有任意的深度,第0层是其输入特征
 ,领域集聚可以视作中心环过滤器
,领域集聚可以视作中心环过滤器
 在数学上,图卷积也可以用谱分解+ 傅里叶变换来解释。
在数学上,图卷积也可以用谱分解+ 傅里叶变换来解释。
不同方法关键的区别在于如何跨层聚合信息。
基础方法是:直接使用神经网络
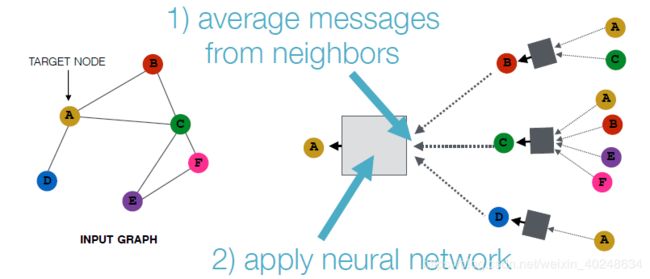 基础方法:运用神经网络平均领域信息。包括当前信息与过去信息的整合。
基础方法:运用神经网络平均领域信息。包括当前信息与过去信息的整合。
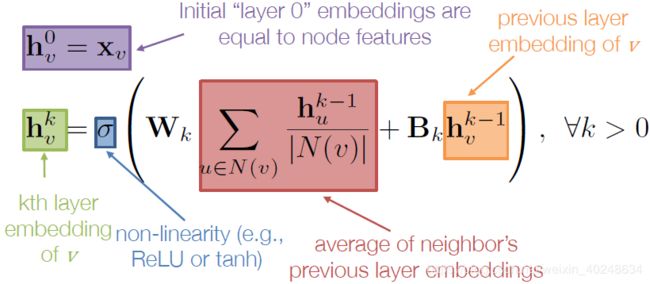
模型训练
训练模型需要定义一个好的损失函数
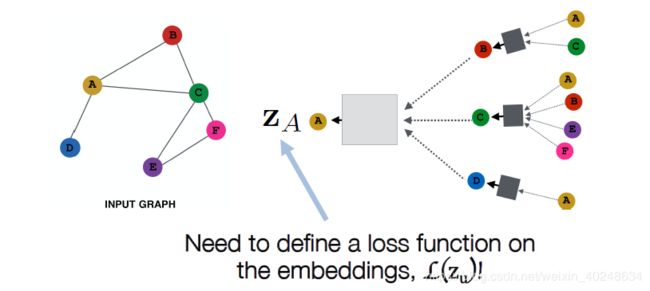
 通过K层的领域集聚,我们可以得到 每个节点的输出嵌入, Z v = h v k \bm{Z}_v=h_v^k Zv=hvk,接着将这些嵌入放进任何的损失函数,然后用随机梯度下降,就可训练集聚参数。
通过K层的领域集聚,我们可以得到 每个节点的输出嵌入, Z v = h v k \bm{Z}_v=h_v^k Zv=hvk,接着将这些嵌入放进任何的损失函数,然后用随机梯度下降,就可训练集聚参数。
仅仅使用图结构通过一种无监督法则去训练,无监督学习的损失函数可以来自上一部分的任何一个,比如随机游走,图分解,还有训练模型使得节点有相似的映射。
训练可选方案:
- 直接训练无监督任务的模型(如:节点分类)
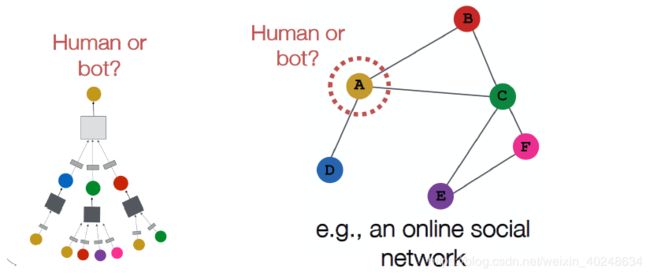

模型概述

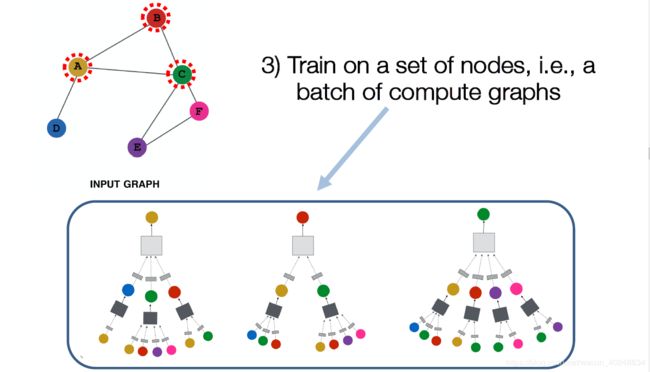
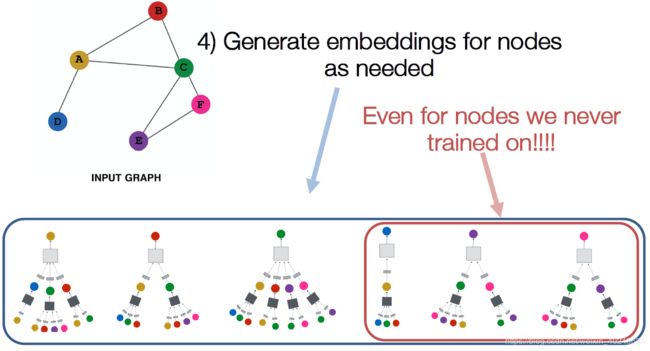
归纳能力
- 权值共享:相同的聚集参数被所有的节点共享
- 模型参数的数量是|V|的次线性,所以会产生一个看不见的节点

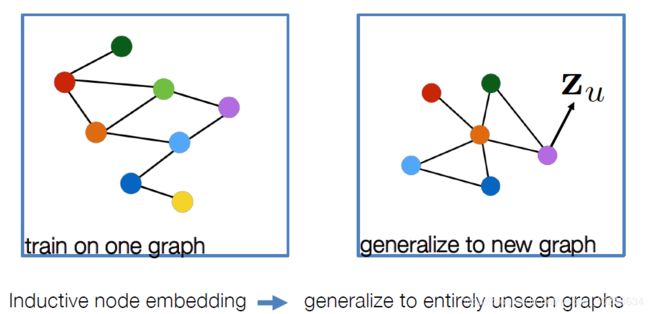 从模型A开始训练蛋白质相互作用图,并对新收集到的关于B的数据进行嵌入。
从模型A开始训练蛋白质相互作用图,并对新收集到的关于B的数据进行嵌入。
 很多应用设置会持续不断的面对看不见的节点(隐节点),像Google学术。则需要动态的产生新的节点嵌入。
很多应用设置会持续不断的面对看不见的节点(隐节点),像Google学术。则需要动态的产生新的节点嵌入。
小结
通过聚集领域信息去产生节点嵌入:
- 在编码器中实现权值共享
- 能够归纳学习
而关键在于如何去聚集这些信息,下面提到图卷积网络
图卷积网络
Kipf et al.’s Graph Convolutional
Networks (GCNs)跟前面提到的领域信息聚集有些不同,
 经验来看,他们找到了更好结果的相关配置,即
经验来看,他们找到了更好结果的相关配置,即
- 更多的权值共享
- 高阶领域具有更小的权值
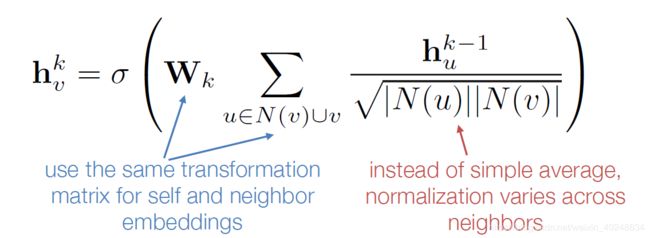
graphSAGE 观点
Hamilton et al., 2017. Inductive Representation Learning on Large Graphs.
NIPS.
更好的聚集:
 grapSAGE 与原本领域聚集的不同点:
grapSAGE 与原本领域聚集的不同点: 对应的AGG(即aggregation)形式有许多不同,包括平均、词化、LSTM
对应的AGG(即aggregation)形式有许多不同,包括平均、词化、LSTM

门卷积网络的观点
• Li et al., 2016. Gated Graph Sequence Neural Networks. ICLR.
• Gilmer et al., 2017. Neural Message Passing for Quantum Chemistry. ICML.
前面的GCNS与GraphSAGE通常只有2-3 层深度,即2-3阶邻域的信息整合,随着深度增加会带来以下挑战:
- 由于太多参数导致的过拟合
- 在负反馈传播中导致的梯度消失或者梯度爆炸问题。
所以这里采用现代的循环神经网络。
- idea1: 参数在不同层之间的共享
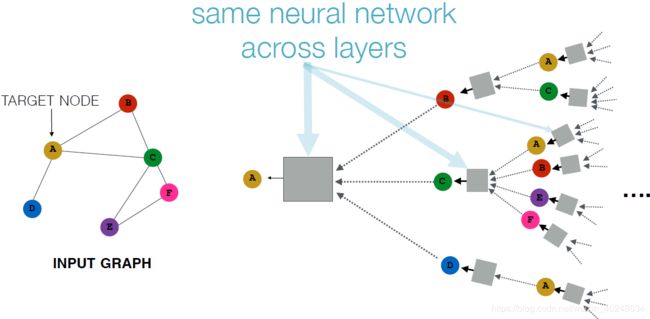
- idea 2:循环状态更新
 从数学上说,我们可以想到用RNN的状态更新机制来对领域信息进行信息更新
从数学上说,我们可以想到用RNN的状态更新机制来对领域信息进行信息更新
1… 在第k步获得领域信息,
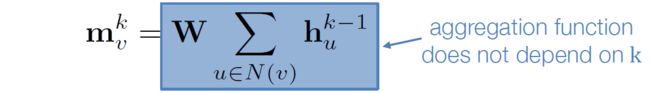 2. 用门循环单元去更新节点状态,新结点状态取决于上一步的state与当前的来自领域信息的整合,
2. 用门循环单元去更新节点状态,新结点状态取决于上一步的state与当前的来自领域信息的整合,

- 用门卷积模型我们可以处理深度大于20层的情况。
- 大多数的真实世界网络都是比较小直径的
- 允许将有关全局图结构的复杂信息传播到所有节点。
MPNN(Message-Passing Neural Networks)
从门卷积神经网络出发我们也可以将其思想推广到Message-Passing Neural Networks(MPNN) 中,
第一步,从邻域中整合信息,
 然后更新节点的状态
然后更新节点的状态
 下面这个是贯穿大多数GNNs的框架
下面这个是贯穿大多数GNNs的框架
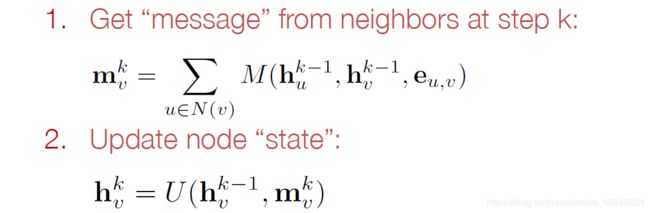 • Gilmer et al., 2017. Neural Message Passing for Quantum
• Gilmer et al., 2017. Neural Message Passing for Quantum
Chemistry. ICML.
图attention 网络
Based on material from:
• Velickovic et al., 2018. Graph Attention Networks. ICLR.
邻域注意力
有些领域的点的重要性大于其余点。
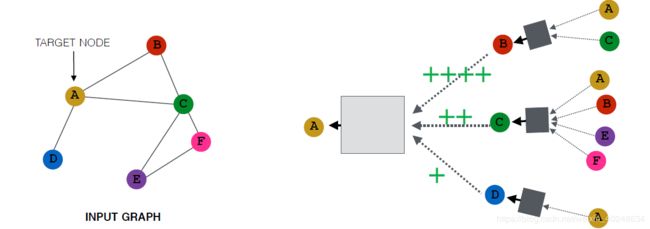
将基础的图神经网络扩展上注意力
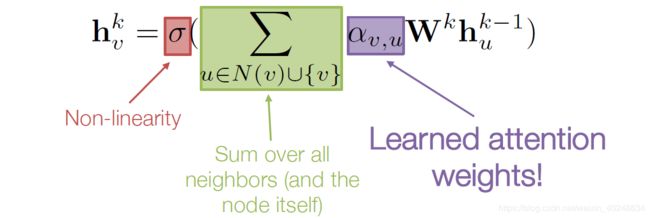
注意力权重
- 不同的注意力模型都是有可能的
- 之前的GAT论文用的是
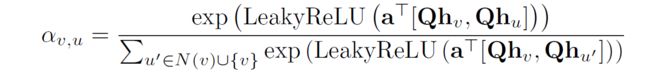 这里其实相当于是用了指数加权。
这里其实相当于是用了指数加权。
通常的注意力(融合到message中)
将不同的注意力机制融合到信息传递步骤里边
 也就是将注意力作为第k步的输入,经过函数M的作用(MLP,SUM, ect),将注意力信息给融合进去
也就是将注意力作为第k步的输入,经过函数M的作用(MLP,SUM, ect),将注意力信息给融合进去
图神经的最新进展:
- 普卷积的概述
Geometric Deep Learning (Bronstein et al., 2017)
Mixture Model CNNs (Monti et al., 2017) - 通过子采样来进行的速度提升
FastGCNs (Chen et al., 2018)
Stochastic GCNs (Chen et al., 2017) - 等等
标准集: - Cora, CiteSeer, PubMed
- Semi-supervised node classification
注意力,门,还要其他的修改已经在特定的领域上有所提升了,像分子分类,推荐系统等。
(子)图嵌入
Based on material from:
• Duvenaud et al. 2016. Convolutional Networks on Graphs for Learning Molecular Fingerprints. ICML.
• Li et al. 2016. Gated Graph Sequence Neural Networks. ICLR.
• Ying et al, 2018. Hierarchical Graph Representation Learning with Differentiable Pooling. NeurIPS.
- 节点映射
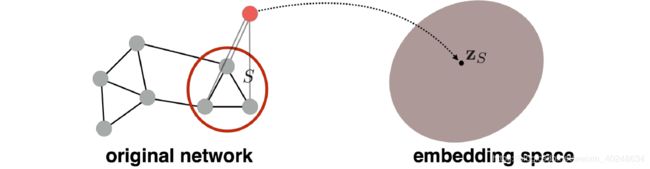
- 子图映射
 法一:
法一:
简单的方法是直接将子图中的节点嵌入进行求和(或者平均),
z S = ∑ v ∈ S z v z_S=\sum_{v\in{S}} z_v zS=v∈S∑zv
Used by Duvenaud et al., 2016 to
classify molecules based on their graph
structure.
法二:
引入一个“虚拟节点”来表示子图,并运行一个标准的图神经网络
 Proposed by Li et al., 2016 as a general
Proposed by Li et al., 2016 as a general
technique for subgraph embedding
法三(比较新颖):
idea:学习如何分层集群节点。(First proposed by Ying et al., 2018)

- 基础综述:
- 在图上运行GNN,获得节点嵌入表示
- 将节点嵌入聚在一起形成“粗化”图。
- 在“粗化”图上运行GNN
- 重复以上过程
- 聚类的不同方法
Soft clustering via learned softmax weights (Ying et al., 2018)
Hard clustering (Cangea et al., 2018 and Gao et al., 2018)