K8s系统核心组件:
我们学习了关于K8s常用的组件,也可以基于K8s搭建我们的环境及部署CICD的服务。接下去我们有必要来学习一下关于K8s的核心组件部分。本文主要是介绍一个基本的认知。如果小伙伴们感兴趣也可以相互探讨。
Master和Node
官网 :https://kubernetes.io/zh/docs/concepts/architecture/master-node-communication/
K8S集群中的控制节点,负责整个集群的管理和控制,可以做成高可用,防止一台Master打竞技或者不可用。其中有一些关键的组件:比如API Server,Controller Manager,Scheduler等。Node会被Master分配一些工作负载,当某个Node不可用时,会将工作负载转移到其他Node节点上。Node上有一些关键的进程:kubelet,kube-proxy,docker等
查看集群中的Node :kubectl get nodes kubectl describe node node-name
kubeadm:
kubeadm init:集群的基本环境安装好以后我们需要对 master进行初始化,这是初始化的时候的日志信息。
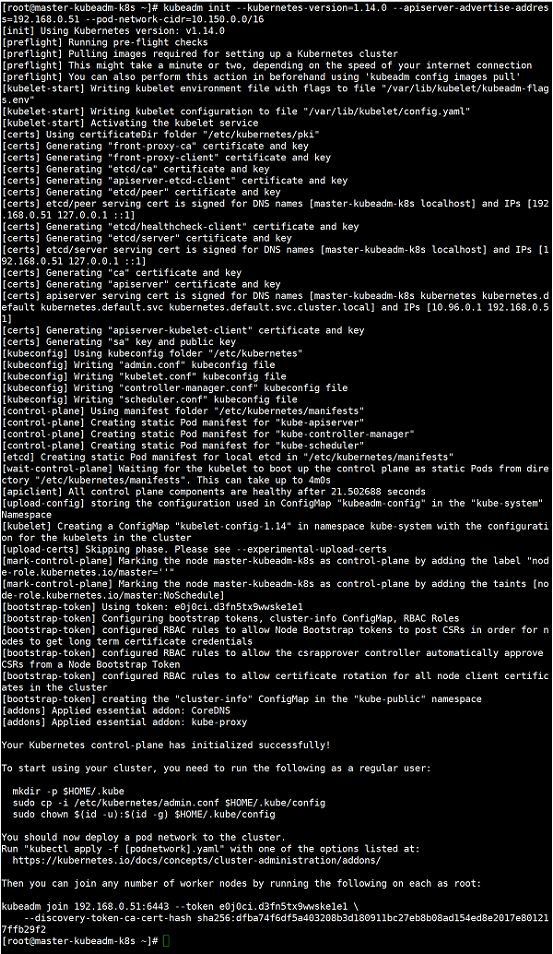
我们根据上图来简单的看一下在初始化的时候都做了哪些事。
01-进行一系列检查[init之前的检查],以确定这台机器可以部署kubernetes. kubeadm init pre-flight check:
(1)kubeadm版本与要安装的kubernetes版本的检查
(2)kubernetes安装的系统需求检查[centos版本、cgroup、docker等]
(3)用户、主机、端口、swap等
02-生成kubernetes对外提供服务所需要的各种证书可对应目录,也就是生成私钥和数字证书 /etc/kubernetes/pki/*
(1)自建ca,生成ca.key和ca.crt
(2)apiserver的私钥与公钥证书
(3)apiserver访问kubelet使用的客户端私钥与证书
(4)sa.key和sa.pub
(5)etcd相关私钥和数字证书
03-为其他组件生成访问kube-ApiServer所需的配置文件xxx.conf . ls /etc/kubernetes/
admin.conf controller-manager.conf kubelet.conf scheduler.conf
(1)# 有了$HOME/.kube/config就可以使用kubectl和K8s集群打交道了,这个文件是来自于admin.config
mkdir -p $HOME/.kube
sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
sudo chown $(id -u):$(id -g) $HOME/.kube/config
(2)kubeconfig中包含了cluster、user和context信息:kubectl config view
(3)允许kubectl快速切换context,管理多集群
04-为master生成Pod配置文件,这些组件会被master节点上的kubelet读取到,并且创建对应资源 ls /etc/kubernetes/manifests/*.yaml
kube-apiserver.yaml
kube-controller-manager.yaml
kube-scheduler.yaml
这些pod由kubelet直接管理,是静态pod,直接使用主机网络kubelet读取manifests目录并管理各控制平台组件pod的启动与停止要想修改这些pod,直接修改manifests下的yaml文件即可
05-下载镜像[这里的镜像我们已经提前准备好了],等待控制平面启动k8s.gcr.io下载不了,所以我们先提前下载并且tag好了
06-一旦这些 YAML 文件出现在被 kubelet 监视的/etc/kubernetes/manifests/目录下,kubelet就会自动创建这些yaml文件定义的pod,即master组件的容器。master容器启动后,
kubeadm会通过检查localhost:6443/healthz这个master组件的健康状态检查URL,等待master组件完全运行起来【cat kube-apiserver.yaml里面有健康检查的配置】
07-为集群生成一个bootstrap token,设定当前node为master,master节点将不承担工作负载
08-将ca.crt等 Master节点的重要信息,通过ConfigMap的方式保存在etcd中,工后续部署node节点使用
09-安装默认插件,kubernetes默认kube-proxy和DNS两个插件是必须安装的,dns插件安装了会出于pending状态,要等网络插件安装完成,比如calico
kubectl get daemonset -n kube-system可以看到kube-proxy和calico[或者其他网络插件]
kubeadm join:
kubeadm join 192.168.0.51:6443 --token yu1ak0.2dcecvmpozsy8loh \ --discovery-token-ca-cert-hash sha256:5c4a69b3bb05b81b675db5559b0e4d7972f1d0a61195f217161522f464c307b0
这个命令时主节点初始化的时候生成的,那么在节点加入集群的时候都做了什么呢?
01 join前检查
02 discovery-token-ca-cert-hash用于验证master身份
可以计算出来,在w节点上执行
openssl x509 -in /etc/kubernetes/pki/ca.crt -noout -pubkey | openssl rsa -pubin -outform DER 2>/dev/null | sha256sum | cut -d' ' -f1
最终hash的值
909adc03d6e4bd676cfc4e04b864530dd19927d8ed9d84e224101ef38ed0bb96
03 token用于master验证node
在master上节点上,可以查看对应的token
kubectl get secret -n kube-system | grep bootstrap-token
得到token的值
kubectl get secret/bootstrap-token-kggzhc -n kube-system -o yaml
对token的值进行解码
echo NHRzZHp0Y2RidDRmd2U5dw==|base64 -d --->4tsdztcdbt4fwe9w
最终token的值
kggzhc.4tsdztcdbt4fwe9w
04 实在忘了怎么办?有些小伙伴可能没有及时保存最后的join信息,或者24小时之后过期了,这时候可以重新生成
(1)重新生成token
kubeadm token create
(2)获取ca证书sha256编码hash值
openssl x509 -pubkey -in /etc/kubernetes/pki/ca.crt | openssl rsa -pubin -outform der 2>/dev/null | openssl dgst -sha256 -hex | sed 's/^.* //'
(3)重新生成join信息
kubeadm join 主节点ip地址:6443 --token token填这里 --discovery-token-ca-cert-hash sha256:哈希值填这里
主节点的初始化完成,以及node节点的加入也完成了,那么在此过程中涉及的内部组件的创建,以及后续我们需要通过某些核心组件同集群打交道,那么这些组件都扮演着什么样的角色呢?先把核心组件总体过一遍,不妨查看一下之前的K8s架构图,勾起回忆
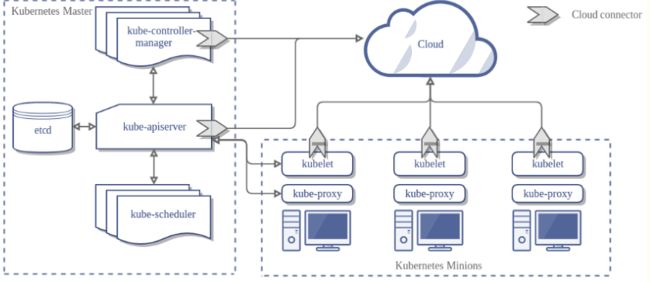
对之前理解的优化,先是整体
1 kubectl:总得要有一个操作集群的客户端,也就是和集群打交道
2 kube-apiserver:整个集群的中枢纽带,负责的事情很多
(1)/etc/kubernetes/manifests/kube-apiserver.yaml # kubelet管理的静态pod (2)--insecure-port=0 # 默认使用http非安全协议访问 (3)安全验证的一些文件 (4)准入策略的拦截器 (5)--authorization-mode=Node,RBAC (6)--etcd # 配置apiserver与etcd通信
3 kube-scheduler:单纯地调度pod,按照特定的调度算法和策略,将待调度Pod绑定到集群中某个适合的Node,并写入绑定信息,由对应节点的kubelet服务创建pod。
(1)/etc/kubernetes/manifests/kube-scheduler.yaml # kubelet管理的静态pod
(2)--address表示只在master节点上提供服务,不对外
(3)kubeconfig表示
4 kube-controller-manager:负责集群中Node、Pod副本、服务的endpoint、命名空间、Service Account、资源配合等管理会划分成不同类型的controller,每个controller都是一个死循环,在循环中controller通过apiserver监视自己控制资源的状态,一旦状态发生变化就会努力改变状态,直到变成期望状态
(1)/etc/kubernetes/manifests/kube-controller-manager.yaml # kubelet管理的静态pod
(2)参数设置ca-file
(3)多个manager,是否需要进行leader选举
5 kubelet 集群中的所有节点都有运行,用于管理pod和container,每个kubelet会向apiserver注册本节点的信息,并向master节点上报本节点资源使用的情况
(1)kubelet由操作系统init[systemd]进行启动
(2)ls /lib/systemd/system/kubelet.service
(3)systemctl daemon-reload & systemctl restart kubelet
6 kube-proxy:集群中的所有节点都有运行,像service的操作都是由kube-proxy代理的,对于客户端是透明的
(1)kube-proxy由daemonset控制器在各个节点上启动唯一实例
(2)配置参数:/var/lib/kube-proxy/config.conf(pod内) # 不是静态pod
(3)kubectl get pods -n kube-system
(4)kubectl exec kube-proxy-jt9n4 -n kube-system -- cat /var/lib/kube-proxy/config.conf
(5)mode:"" ---># iptables
7 DNS:域名解析的问题
8 dashboard:需要有监控面板能够监测整个集群的状态
9 etcd:整个集群的配置中心,所有集群的状态数据,对象数据都存储在etcd中,kubeadm引导启动的K8s集群,默认只启动一个etcd节点
(1)/etc/kubernetes/manifests/etcd.yaml # kubelet管理的静态pod (2)etcd所使用的相关秘钥在/etc/kubernetes/pki/etcd里面 (3)etcd挂载master节点本地路径/var/lib/etcd用于运行时数据存储,tree
Kubernetes源码查看方式:
源码地址 :https://github.com/kubernetes/kubernetes
https://github.com/kubernetes/kubernetes/tree/release-1.14
kubectl:
官网 :https://kubernetes.io/docs/reference/kubectl/overview/
Kubectl 是一个命令行接口,用于对 Kubernetes 集群运行命令。kubectl 在 $HOME/.kube 目录中寻找一个名为 config 的文件。语法 :kubectl [command] [TYPE] [NAME] [flag]
command:用于操作k8s集资源对象的命令,比如apply、delete、describe、get等
TYPE:要操作资源对象的类型,区分大小写,比如pod[pods/po]、deployment
NAME:要操作对象的具体名称,若不指定,则返回该资源类型的全部对象[是默认命名空间下的]
flags:可选
API Server:
官网 :https://kubernetes.io/zh/docs/reference/command-line-tools-reference/kube-apiserver/
APIServer提供了K8S各类资源对象的操作,是集群内各个功能模块之间数据交互和通信的中心枢纽,是整个系统的数据总线和数据中心。Kubernetes API server 为 api 对象验证并配置数据,包括 pods、 services、 replicationcontrollers 和其它 api 对象。API Server 提供 REST 操作和到集群共享状态的前端,所有其他组件通过它进行交互。
(1)查看yaml文件中的apiVersion 。grep -r "apiVersion" .

(2)REST API设计
api官网 :https://kubernetes.io/docs/concepts/overview/kubernetes-api/
v1.14 :https://kubernetes.io/docs/reference/generated/kubernetes-api/v1.14/

(3)想要写Pod的yaml文件,但是我们又不知道具体的标签,这个时候可以查阅如下网址:
https://kubernetes.io/docs/reference/generated/kubernetes-api/v1.14/#pod-v1-core
(4)kube-apiserver:
lsof -i tcp:8080
vi /etc/kubernetes/manifests/kube-apiserver.yaml [kubeadm安装方式]
# 查询insecure-port,并将修改端口为8080
insecure-port=8080
# kubect apply生效,需要等待一会
kubectl apply -f kube-apiserver.yaml
(5)查看端口以及访问测试。可以发现结果和kubectl使用一样
lsof -i tcp:8080
curl localhost:8080
curl localhost:8080/api
curl localhost:8080/api/v1
curl localhost:8080/api/v1/pods
curl localhost:8080/api/v1/services
(6)设计一个Pod的url请求
https://kubernetes.io/docs/reference/generated/kubernetes-api/v1.14/#-strong-write-operations-pod-v1-core-strong-
curl localhost:8080/api/v1/namespaces/default/pods 通过这个就可以看到默认的命名空间下的 pods的信息。
(7)这种操作还是相对比较麻烦的,哪怕使用kubectl,怎么办?已有先驱为我们做好了这一切https://github.com/kubernetes-client
Java :https://github.com/kubernetes-client/java
Go :https://github.com/kubernetes/client-go
集群安全机制之API Server:
官网 :https://v1-12.docs.kubernetes.io/docs/reference/access-authn-authz/controlling-access/
对于k8s集群的访问操作,都是通过api server的rest api来实现的,难道所有的操作都允许吗?当然不行,这里就涉及到认证、授权和准入等操作。
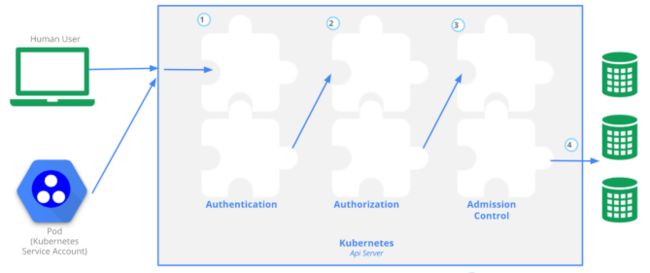
API Server认证(Authentication):
好比你是一个公司的员工,你有工卡,就能得到该公司的认证。
官网 :https://v1-12.docs.kubernetes.io/docs/reference/access-authn-authz/controlling-access/#authentication
说白了,就是如何来识别客户端的身份,K8s集群提供了3种识别客户端身份的方式
- HTTPS证书认证:基于CA根证书签名的双向数字证书认证方式
- HTTP Token认证:通过一个Token来识别合法用户
- HTTP Base认证:通过用户名+密码的方式认证
API Server授权(Authorization):
官网 :https://v1-12.docs.kubernetes.io/docs/reference/access-authn-authz/controlling-access/#authorization
- ABAC授权模式:基于属性的权限验证(ABAC: Attribute-Based Access Control)已经不大用了
- Webhook授权模式
- RBRC授权模式:基于角色的权限验证。
Role、ClusterRole、RoleBinding和ClusterRoleBinding。用户可以使用kubectl或者API调用等方式操作这些资源对象。
- Role对象只能用于授予对某一namespace中资源的访问权限。
- ClusterRole对象可以授予整个集群范围内资源访问权限
- RoleBinding可以将同一namespace中的subject(用户)绑定到某个具有特定权限的Role下,则此subject即具有该Role定义的权限。
- ClusterRoleBinding在整个集群级别和所有namespaces将特定的subject与ClusterRole绑定,授予权限。
如下图,我们可以看到当有人访问我们的k8s集群中的某些资源的时候,需要进行一些操作,那么需要通过RoleBinding或者ClusterRoleBinding找到他对应的Role或者是ClusterRole。也就是对应的权限。进而决定它可以又哪些操作

Admission Control(准入控制):
类似我们程序中的拦截器,过滤器
官网 :https://v1-12.docs.kubernetes.io/docs/reference/access-authn-authz/controlling-access/#admission-control
- Always:允许所有请求
- AlwaysPullImages:在启动容器之前总是尝试重新下载镜像
- AlwaysDeny:禁止所有请求
Scheduler:
官网 :https://kubernetes.io/docs/concepts/scheduling/kube-scheduler/
通过调度算法,为待调度Pod列表的每个Pod,从Node列表中选择一个最合适的Node。然后,目标节点上的kubelet通过API Server监听到Kubernetes Scheduler产生的Pod绑定事件,获取对应的Pod清单,下载Image镜像,并启动容器。
我们通过 kubectl apply 命令创建pod的时候,api server会将该命令持久化进etcd,然后pod Queue会去监听是否有新的请求,然后有序的进行pods的操作,还有一个事当node节点join到集群的时候,kubelet会汇报节点信息,这个时候Node queue就可以拿到节点信息,Scheduler通过这两个信息进行分配。架构图

流程描述:叙述了scheduler在分配过程中做的事。
https://kubernetes.io/docs/concepts/scheduling/kube-scheduler/#kube-scheduler-implementation
- 预选调度策略:遍历所有目标Node,刷选出符合Pod要求的候选节点
- 优选调度策略:在(1)的基础上,采用优选策略算法计算出每个候选节点的积分,积分最高者胜出
预选策略:
https://kubernetes.io/docs/concepts/scheduling/kube-scheduler/#filtering
PodFitsHostPorts:如果 Pod 中定义了 hostPort 属性,那么需要先检查这个指定端口是否 已经被 Node 上其他服务占用了。PodFitsHost:若 pod 对象拥有 hostname 属性,则检查 Node 名称字符串与此属性是否匹配。PodFitsResources:检查 Node 上是否有足够的资源(如,cpu 和内存)来满足 pod 的资源请求。PodMatchNodeSelector:检查 Node 的 标签 是否能匹配 Pod 属性上 Node 的 标签 值。NoVolumeZoneConflict:检测 pod 请求的 Volumes 在 Node 上是否可用,因为某些存储卷存在区域调度约束。NoDiskConflict:检查 Pod 对象请求的存储卷在 Node 上是否可用,若不存在冲突则通过检查。MaxCSIVolumeCount:检查 Node 上已经挂载的 CSI 存储卷数量是否超过了指定的最大值。CheckNodeMemoryPressure:如果 Node 上报了内存资源压力过大,而且没有配置异常,那么 Pod 将不会被调度到这个 Node 上。CheckNodePIDPressure:如果 Node 上报了 PID 资源压力过大,而且没有配置异常,那么 Pod 将不会被调度到这个 Node 上。CheckNodeDiskPressure:如果 Node 上报了磁盘资源压力过大(文件系统满了或者将近满了), 而且配置异常,那么 Pod 将不会被调度到这个 Node 上。CheckNodeCondition:Node 可以上报其自身的状态,如磁盘、网络不可用,表明 kubelet 未准备好运行 pod。 如果 Node 被设置成这种状态,那么 pod 将不会被调度到这个 Node 上。PodToleratesNodeTaints:检查 pod 属性上的 tolerations 能否容忍 Node 的 taints。CheckVolumeBinding:检查 Node 上已经绑定的和未绑定的 PVCs 能否满足 Pod 对象的存储卷需求。
优选策略:
https://kubernetes.io/docs/concepts/scheduling/kube-scheduler/#scoring
SelectorSpreadPriority:尽量将归属于同一个 Service、StatefulSet 或 ReplicaSet 的 Pod 资源分散到不同的 Node 上。InterPodAffinityPriority:遍历 Pod 对象的亲和性条目,并将那些能够匹配到给定 Node 的条目的权重相加,结果值越大的 Node 得分越高。LeastRequestedPriority:空闲资源比例越高的 Node 得分越高。换句话说,Node 上的 Pod 越多,并且资源被占用的越多,那么这个 Node 的得分就会越少。MostRequestedPriority:空闲资源比例越低的 Node 得分越高。这个调度策略将会把你所有的工作负载(Pod)调度到尽量少的 Node 上。RequestedToCapacityRatioPriority:为 Node 上每个资源占用比例设定得分值,给资源打分函数在打分时使用。BalancedResourceAllocation:优选那些使得资源利用率更为均衡的节点。NodePreferAvoidPodsPriority:这个策略将根据 Node 的注解信息中是否含有scheduler.alpha.kubernetes.io/preferAvoidPods来 计算其优先级。使用这个策略可以将两个不同 Pod 运行在不同的 Node 上。NodeAffinityPriority:基于 Pod 属性中 PreferredDuringSchedulingIgnoredDuringExecution 来进行 Node 亲和性调度。你可以通过这篇文章 Pods 到 Nodes 的分派 来了解到更详细的内容。TaintTolerationPriority:基于 Pod 中对每个 Node 上污点容忍程度进行优先级评估,这个策略能够调整待选 Node 的排名。ImageLocalityPriority:Node 上已经拥有 Pod 需要的 容器镜像 的 Node 会有较高的优先级。ServiceSpreadingPriority:这个调度策略的主要目的是确保将归属于同一个 Service 的 Pod 调度到不同的 Node 上。如果 Node 上 没有归属于同一个 Service 的 Pod,这个策略更倾向于将 Pod 调度到这类 Node 上。最终的目的:即使在一个 Node 宕机之后 Service 也具有很强容灾能力。CalculateAntiAffinityPriorityMap:这个策略主要是用来实现pod反亲和。EqualPriorityMap:将所有的 Node 设置成相同的权重为 1。
Node实战
(1)创建 scheduler-/scheduler-node.yaml。主要是体现node的调度
apiVersion: apps/v1 kind: Deployment metadata: name: scheduler-node spec: selector: matchLabels: app: scheduler-node replicas: 1 template: metadata: labels: app: scheduler-node spec: containers: - name: scheduler-node image: registry.cn-hangzhou.aliyuncs.com/itcrazy2016/test-docker-image:v1.0 ports: - containerPort: 8080 affinity: nodeAffinity: requiredDuringSchedulingIgnoredDuringExecution: nodeSelectorTerms: - matchExpressions: - key: beta.kubernetes.io/arch operator: In values: - amd641 preferredDuringSchedulingIgnoredDuringExecution: - weight: 1 preference: matchExpressions: - key: disktype operator: NotIn values: - ssd
kubectl get nodes w1 -o yaml 。找到labels,可以发现这里有6个标签。而我们的yaml里要求的是标签的key是 beta.kubernetes.io/arch ,而value是amd641他是不存在的,那么创建这个pod的时候会是怎么样的呢?

kubectl apply -f scheduler-node.yaml
kubectl get pods
kubectl describe pod pod-name

会发现整个pod会处于一个 Pending的状态,同时会报错,信息是两个节点是不可用的。没有匹配到选择。这个时候我们只要把value改成amd64就可以启动成功。
Pod的配置:
affinity: nodeAffinity: requiredDuringSchedulingIgnoredDuringExecution: #这个是必须要满足的 nodeSelectorTerms: - matchExpressions: - key: beta.kubernetes.io/arch operator: In values: - amd641 preferredDuringSchedulingIgnoredDuringExecution: #这个是最好满足 - weight: 1 preference: matchExpressions: - key: disktype operator: NotIn values: - ssd
kubelet:
官网 :https://kubernetes.io/docs/reference/command-line-tools-reference/kubelet/
在k8s集群中,每个Node上都会启动一个kubelet服务进程,用于处理master节点下发到本节点的任务。管理Pod及Pod中的容器,每个kubelet进程会在API Server上注册节点自身信息,定期向Master节点汇报节点资源的使用情况,并通过cAdvisor监控容器和节点资源。
kube-proxy:
官网 :https://kubernetes.io/docs/reference/command-line-tools-reference/kube-proxy/
在k8s集群中,每个Node上都会运行一个kube-proxy进行,它是Service的透明代理兼负载均衡器,核心功能是将某个Service的访问请求转发到后端的多个Pod实例上。