lightgbm原理和调参参考资料汇总
Lightgbm
总的来说,看完论文Lightgbm提高速度主要就是‘压缩数据的数量和维度’,降低训练数据的量,其中goss降低了数据数量,efb降低了数据的维度,基于Histogram的算法加快了扫描数据的速度,基于leaf-wise的树的生成,在同等所有节点上找到信息增益最大的进行分裂,对于一些 信息增益小的节点就不分裂,这样做减少开销。
Lightgbm 的四个特点:
一、 Gradient-based One-Side Sampling
GOSS是一个样本实例的采样算法,目的是丢弃一些对计算信息增益没有帮助的实例留下有帮助的。首先来了解一下信息增益)。可以看到具有较大梯度的数据对计算信息增益的贡献比较大【坑1】(参考论文Greedy Function Approximation: A Gradient Boosting Machine的证明),因此GOSS在进行数据采样的时候只保留了梯度较大的数据,但是如果直接将所有梯度较小的数据都丢弃掉势必会影响数据的总体分布,因此GOSS首先将要进行分裂的特征的所有取值按照绝对值大小降序排序(XGB一样也进行了排序,但是lgb不用保存排序后的结果),选取绝对值最大的a*100%个数据,然后在剩下的教小梯度数据中随机选择b*100%个数据,并且将这b%个数据乘以一个常数 (1-a)/b%,最后使用这(a+b)%个数据来计算信息增益。下图是GOSS的具体算法

从以上算法看,在d次迭代中lightGBM只使用了useSet实例进行训练,每一轮迭代都学习了一个弱学习器,并且在进行下一轮学习时,前面的每一轮所学习的弱学习器都将影响该轮的学习。
二、 Exclusive Feature Bundling
高维度的数据通常是非常稀疏的,这样的特性为特征的相互之间结合提供了便利。通过将一些特征进行融合绑定在一起,可以使特征数量大大减少,这样在进行histogram building时时间复杂度从O(#data * #feature)变为O(#data * #bundle),这里#bundle远小于#feature。
那么将哪些特征绑定在一起呢?又要怎么绑定呢?
对于第一个问题,将相互独立的特征进行bunding是一个NP难问题【坑2】,lightGBM将这个问题转化为图着色的为题来求解,将每个特征视为图G的一个顶点,将不是相互独立的特征用一条边连接起来,边的权重就是两个相连接的特征的总冲突值,这样需要绑定的特征就是在图着色问题中要涂上同一种颜色的那些点(特征)。(对于超高维数据来说依旧复杂)
更加高效的策略:通过对特征按照非0值的数量进行降序排序(两个特征非0值越多,越有可能冲突,在空间不正交),然后按照之前bundling策略是看新加入的特征是进入已有的bundle,还是新建的bundle.
对于第二个问题,绑定几个特征在同一个bundle里需要保证绑定前的原始特征的值可以在bundle中识别,考虑到 histogram-based算法将连续的值保存为离散的bins,我们可以使得不同特征的值分到bundle中的不同bins中,这可以通过在特征值中加一个偏置常量来解决,比如,我们在bundle中绑定了两个特征A和B,A特征的原始取值为区间[0,10),B特征的原始取值为区间[0,20),我们可以在B特征的取值上加一个偏置常量10,将其取值范围变为[10,30),这样就可以放心的融合特征A和B了。
因为在树模型中对于每一个特征都会计算分裂节点的,也就是通过将他们的取值范围限定在不同的bins中,在分裂时可以将不同特征很好的分裂到树的不同分支中去。

两种特征绑定的方法
三、 Histogram-based Algorithm
Histogram-based 算法不是lightGBM所特有的,其他GBDT算法也采用了这样的算法,XGB也有,但是它和lightGBM有所不同,这里介绍一下lgb的Histogram-based 算法。

Histogram-based 算法将连续的特征映射到离散的buckets中,组成一个个的bins,然后使用这些bins建立直方图。简而言之就是将连续变量离散化。
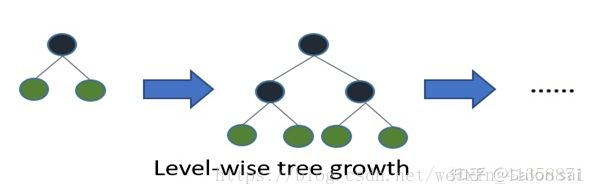
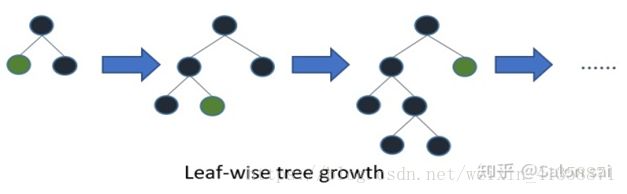
四、Leaf-wise
前面讲了XGB是level-wise。而lightGBM是Leaf-wise,即带深层限制的Leaf-wise的叶子生长策略,它具有快速收敛的效果,lgb在生成树的过程中不需要达到设置的树的深度只要树的叶子数量达到了设置的个数之后就终止当前树的生长,这样就不会为了达到深度而去生长一些对任务贡献不大的树叶。这也是lightGBM训练速度快的一个原因。但是Leaf-wise也容易过拟合,如果你设置参数不得当。
Lightgbm调参
调参
1. 使用num_leaves
因为LightGBM使用的是leaf-wise的算法,因此在调节树的复杂程度时,使用的是num_leaves而不是max_depth
大致换算关系:num_leaves = 2^(max_depth)
2.对于非平衡数据集:可以param['is_unbalance']='true’
3. Bagging参数:bagging_fraction+bagging_freq(必须同时设置)、feature_fraction
4. min_data_in_leaf、min_sum_hessian_in_leaf
知乎关于lightgbm 的专题:
https://www.zhihu.com/search?type=content&q=lightgbm
https://zhuanlan.zhihu.com/p/25308051
lightgbm关键参数利用for循环基于二分类损失调参:
http://www.mamicode.com/info-detail-2245866.html
LightGBM 中文文档 :
http://lightgbm.apachecn.org/cn/latest/Parameters.html(关于参数的详细介绍)
LightGBM 调参方法(具体操作)
基于网格搜索的回归预测问题:
https://www.cnblogs.com/bjwu/p/9307344.html
XGBoost、LightGBM的详细对比介绍:https://www.cnblogs.com/infaraway/p/7890558.html
,