pytorch_geometric自制数据集
1. 无权无向图数据格式与说明
‘x’ :节点特征矩阵,默认shape为[num_nodes, num_node_features],num_nodes为数据集节点数,node_features为每个节点的特征数。(如果输入一副完整的image,那么特征数可以是像素数嘛?待验证。。)
‘y’ :label,可以是节点label也可以是图graph的label。shape根据目标进行设点。
‘edge_index’ (LongTensor):graph连接矩阵,默认shape为[2, num_edges]。
例子: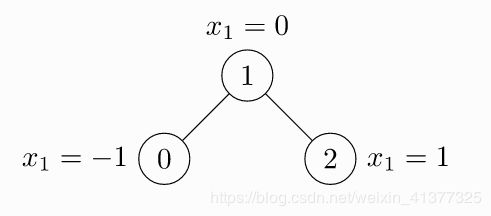
x = torch.tensor([[-1], [0], [1]], dtype=torch.float)
edge_index = torch.tensor([[0, 1], [1, 0], [1, 2], [2, 1]], dtype=torch.long)
其中edge_index表示0,1节点互相连接与1,2节点互相连接。
2. 自制数据集格式与说明
import torch
from torch_geometric.data import InMemoryDataset
class MyOwnDataset(InMemoryDataset):
def __init__(self, root, transform=None, pre_transform=None):
super(MyOwnDataset, self).__init__(root, transform, pre_transform)
self.data, self.slices = torch.load(self.processed_paths[0])
@property
def raw_file_names(self):
return ['some_file_1', 'some_file_2', ...]
@property
def processed_file_names(self):
return ['data.pt']
def download(self):
# Download to `self.raw_dir`.
def process(self):
# Read data into huge `Data` list.
data_list = [...]
if self.pre_filter is not None:
data_list = [data for data in data_list if self.pre_filter(data)]
if self.pre_transform is not None:
data_list = [self.pre_transform(data) for data in data_list]
data, slices = self.collate(data_list)
torch.save((data, slices), self.processed_paths[0])
制作数据集需要定义data与slices,data指的是以pytorch_geometric定义的数据类型Data构建的图数据集;slices指的是切片,即数据集中不同graph的划分,如slices[‘x’]=[0,75,150]指的是数据集中按照75个节点划分,共三个图,slices[‘y’],slices['edge_index ']以此类推。slices用于区分不同的graph与实现shuffle等功能。值得注意slices需要int的tensor类型,否则DataLoader不支持切片操作。
def raw_file_names与def processed_file_names定义了原始文件名与处理后的文件名,def download为下载,可以直接pass或者指向原始文件。def process指从原始文件到最终文件的处理过程,需要视具体任务而定,最重要的到前文1提过的数据格式。
需要注意数据集中的’x’,‘y’,'edge_index’指的是全数据集的graph属性,假设数据集共三个graph,每一张graph的连接格式都是一样的[[0,0,1,1,2,2],[1,2,0,2,0,1]],那么数据集中的’edge_index’应该为[[0,0,1,1,2,20,0,1,1,2,20,0,1,1,2,2],[1,2,0,2,0,11,2,0,2,0,11,2,0,2,0,1]]。
DataLoader与transforms等操作已由pytorch_geometric实现,直接继承即可。
参考:
- https://pytorch-geometric.readthedocs.io/en/latest/notes/create_dataset.html
- https://github.com/rusty1s/pytorch_geometric/tree/master/torch_geometric/datasets