超详细...搭建Redis缓存集群方案
一、Ubuntu 16.04下安装和配置Redis(这里采用的是apt安装,也可采用源码安装。若已安装,可直接跳过该节)
1.1 首先更新软件包sudo apt-get update
1.2 使用命令安装sudo apt-get install -y redis-server
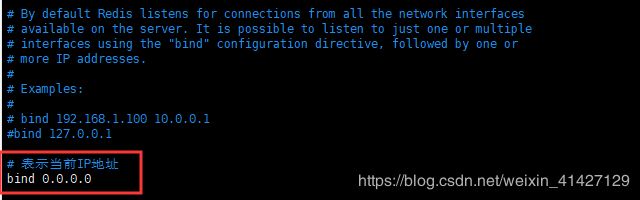
1.3 开启远程连接服务
找到/etc/redis/redis.conf文件,做如下修改。若不需要远程连接,则不需要该操作。
1.4 设置登录的密码
找到/etc/redis/redis.conf文件修改如下,添加requirepass kingredis(密码设置为kingredis)作为登录密码。此时,重启redis服务service redis restart

1.5 测试redis服务
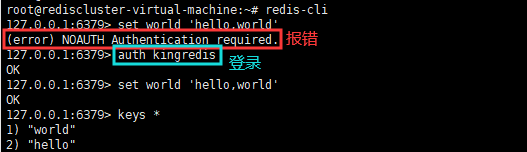
可以看到,此时需要登录后才能操作,使用auth kingredis进行登录,也可以在使用redis服务时,通过该命令直接指定登录的密码redis-cli -a 'kingredis'
1.6 在这里推荐一个开源的redis可视化工具RedisDesktopManager
网盘链接: https://pan.baidu.com/s/1H5z;hY062rtzsvm8Rx7WIlQ 提取码:geim
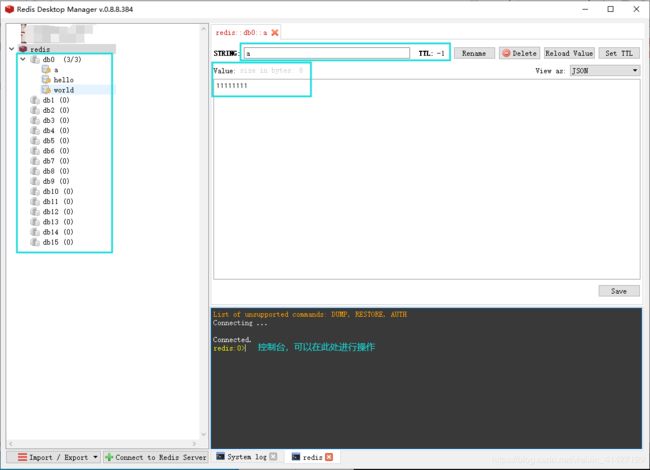
可以看到,redis单体实例有16个数据库,而接下来可以看到,redis缓存集群只有一个db0数据库,那这是为什么呢?详细可以参考该文:https://blog.csdn.net/weixin_41427129/article/details/106085319
二、Redis缓存集群简介
Redis Cluster,即Redis集群,Redis集群完全去中心化,由多个节点组成,所有节点彼此互联。Redis客户端可以直接连接任何一节点,从而获取集群中的键值对,不需要中间代理。如果该节点不存在用户所指定的键值,其内部会自动把客户端重定向到键值所在的节点。
Redis集群是一个网状结构,每个节点都通过TCP连接跟其他每个节点连接。在一个有 N 个节点的集群中,每个节点都有N-1个流出的TCP连接,和N-1个流入的连接,这些TCP连接会永久保持。

Redis Cluster 同其他分布式存储系统一样,主要具备以下两个功能:
1)数据分区:Redis集群会将用户数据分散保存至各个节点中,突破Redis单体内存最大存储容量。集群引入了哈希槽slots的概念,其搭建完成后会生成16384个哈希槽slots,(而为什么会是16384个哈希槽slots?个人是这么理解的:一个空的Redis实例占用1MB的内存空间,而有每个Redis实例默认有16个数据库,所以1024*16=16384),同时会根据节点的数量大致均等地将16384个哈希槽slot映射到不同的节点上。当用户存储key-value时,集群会先对key进行CRC16校验然后对16384取模来决定key-value放置哪个槽,从而实现自动地将数据分割到不同的节点上。
2)数据冗余:Redis集群支持主从复制和故障恢复。集群使用了主从复制模型,每个主节点master应至少有一个从节点slave。假设某个主节点故障,其所有子节点会广播一个数据包给集群里的其他主节点来请求选票(选举主节点),一旦某个从节点收到了大多数主节点的回应,那么它就赢得了选举,被推选为主节点,负责处理之前旧的主节点负责的哈希槽。
接下来简要说下搭建Redis集群的方式。
依据Redis Cluster内部的故障转移实现原理,Redis集群至少需要3个主节点,而每个主节点至少有1个从节点,因此搭建一个集群至少包含6个节点,三主三从,并且分别部署在不同机器上。
因为穷,本文采用在同一个虚拟机上创建一个伪集群,通过不同的TCP端口启动多个Redis实例来组成集群。在实际生成环境中,搭建方式无太大差异。目前搭建Redis Cluster有两种方案:
1)手动方式搭建,即手动执行cluster命令完成搭建流程。
2)自动方式搭建,使用官方提供的集群管理工具快速搭建。
两种方式原理一样,自动搭建方式只是将手动搭建方式中需要执行的Redis命令封装到了可执行程序。生产环境下推荐使用第二种方式,简单快捷,不易出错。
三、手动搭建redis缓存集群
3.1 明确每个节点的属性、主从关系及启动配置。

3.2 为每个节点创建启动配置文件的存放目录
# 为每个节点创建配置文件目录
mkdir -p 7001 7002 7003 9001 9002 9003

3.3 进入Redis的安装目录,将默认配置文件redis.conf复制到每个节点的存放目录下
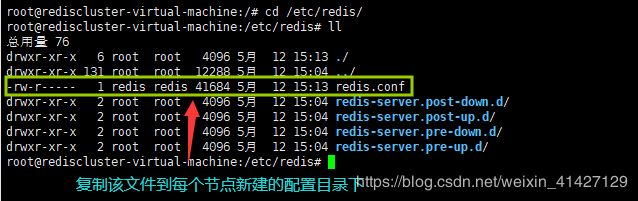
顺序执行图中命令,复制redis.conf文件。
cp redis.conf /usr/local/redis-cluster/7001/
cp redis.conf /usr/local/redis-cluster/7002/
cp redis.conf /usr/local/redis-cluster/7003/
cp redis.conf /usr/local/redis-cluster/9001/
cp redis.conf /usr/local/redis-cluster/9002/
cp redis.conf /usr/local/redis-cluster/9003/
3.4 分别修改每个节点的配置文件,下面是节点A的配置文件/usr/local/redis-cluster/7001/redis.conf中启用或修改的一些必要参数。其他节点B、C、D、E、F参照修改,仅把涉及端口的地方修改成上表明确的信息即可
bind 0.0.0.0 # 设置为当前节点主机地址
port 7001 # 设置客户端连接监听端口
pidfile /var/run/redis/redis-server_7001.pid # 设置 Redis 实例 pid 文件
daemonize yes # 以守护进程运行 Redis 实例
cluster-enabled yes # 启用集群模式
cluster-node-timeout 15000 # 设置当前节点连接超时毫秒数
cluster-config-file nodes-7001.conf # 设置当前节点集群配置文件路径
3.5 启动节点。完成上述工作后,通过如下命令启动待搭建的集群中的6个节点
redis-server /usr/local/redis-cluster/7001/redis.conf
redis-server /usr/local/redis-cluster/7002/redis.conf
redis-server /usr/local/redis-cluster/7003/redis.conf
redis-server /usr/local/redis-cluster/9001/redis.conf
redis-server /usr/local/redis-cluster/9002/redis.conf
redis-server /usr/local/redis-cluster/9003/redis.conf
通过命令ps -ef | grep redis看到,每个节点服务都已经启动了

3.6 进行节点握手
到了这一步,上面的6个节点都已经启用了集群支持, 但默认情况下它们是不相互信任或者说没有联系的。节点握手就是在各个节点之间创建连接(每个节点与其他节点相连),形成一个完整的网格,即集群。 进入任意一个节点,利用该命令cluster meet ip port即可实现节点握手。
为了创建集群,我们不需要发送形成完整网格所需的所有cluster meet命令。只要能发送足够的cluster meet消息,就可以让每个节点都可以通过一系列已知节点到达每个其他节点,缺失的链接将被自动创建。一个简单的例子就是:如果我们通过cluster meet将节点A与节点B连接起来,并将B与C连接起来,则A和C会自己找到握手方式并创建连接。
在这里,我们让节点A与其他5个节点进行握手。注意:在生产环境中,我们要将127.0.0.1换成外网IP地址。
通过该命令redis-cli -p 7001 -a 'kingredis'进入节点A,因为我们在前面的配置中,对redis设置了登录命令,所以需要输入密码选项才能登陆,你也可以在配置文件中将该选项注释。完整的握手过程如下:
# 进入节点A
redis-cli -p 7001 -a 'kingredis'
# 节点A分别与其他5个节点握手
127.0.0.1:7001> cluster meet 127.0.0.1 7002
OK
127.0.0.1:7001> cluster meet 127.0.0.1 7003
OK
127.0.0.1:7001> cluster meet 127.0.0.1 9001
OK
127.0.0.1:7001> cluster meet 127.0.0.1 9002
OK
127.0.0.1:7001> cluster meet 127.0.0.1 9003
OK
我们来验证任意两个节点之间的连接状态。这里选取节点B和F。结果如下所示:
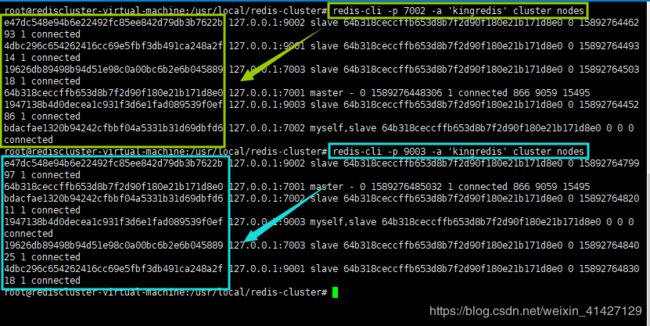
可以看到,节点B和F已经分别与其他5个节点建立了连接。至此,已经成功完成了握手过程。但是,此时集群还处于离线状态。
3.7 分配槽位slots
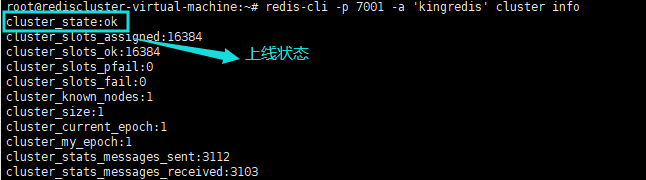
此时Redis集群还未处于上线状态,可以在任意一节点上执行`cluster info`命令来查看目前集群的运行状态。 只有给集群中所有主节点分配好槽位slots,集群才能上线。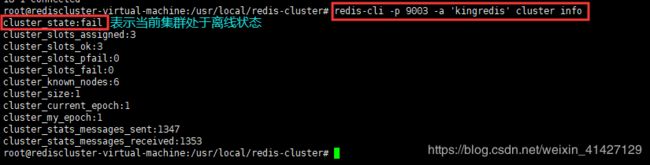
通过如下命令手动将16384个哈希槽大致均等分配给主节点 A、B、C:
redis-cli -p 7001 -a 'kingredis' cluster addslots {0..5461}
redis-cli -p 7001 -a 'kingredis' cluster addslots {5462..10922}
redis-cli -p 7001 -a 'kingredis' cluster addslots {10923..16383}
此时再次查看集群的运行状态,发现已经cluster_state: ok
可能你在分配槽位slots的时候,Redis会报如下错误:
(error) ERR Slot 866 is already busy
这表示某个槽位被占用了。若你在搭建Redis集群之前,已经在使用单体Redis了,且里面存在数据,则会报该错误。解决方案:依次进入集群内的每个节点,执行flushall命令和cluster reset命令,其中flushall用于清空所有数据库的数据,cluster reset重置集群。此时再重新分配槽位就不会有该错误了。
3.8 主从复制
此时Redis集群已经成功上线了,只是还未给主节点指定从节点。如果此时有一个节点故障,那么整个集群也就挂了,也就无法实现高可用。 为了实现集群的高可用,在集群中需要使用cluster replicate命令手动给从节点配置主节点。
1)首先,选择任意一个节点,使用cluster nodes命令查看每个节点的node-id。如下所示:

2)根据表格,A主D从、B主E从、C主F从。执行如下命令,分别为从节点D、E、F指定其主节点。
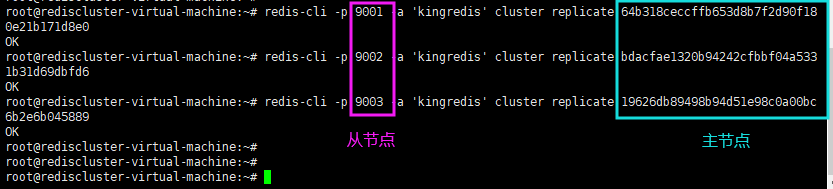
3)此时再次查看集群节点信息。

到这里,已经完成了手动方式搭建Redis集群。
四、利用集群管理工具搭建redis集群
4.1 先启动节点,步骤详见3.1 ~ 3.5
4.2 搭建集群管理工具
如果您安装的Redis是3.x和4.x的版本,则可以使用redis-trib.rb搭建,不过之前需要安装Ruby环境。命令如下:
sudo apt-get install -y ruby
安装完成后,使用redis-trib.rb脚本搭建集群。具体命令如下所示:
redis-5.0.0/src/redis-trib.rb create --replicas 1 127.0.0.1:7001 127.0.0.1:7002 127.0.0.1:7003 127.0.0.1:9001 127.0.0.1:9002 127.0.0.1:9003
因为本文实验环境使用的Redis版本是5.0.0,所以我可以直接使用redis-cli --cluster create命令搭建,具体命令如下所示:
redis-cli --cluster create 0.0.0.0:7001 0.0.0.0:7002 0.0.0.0:7003 0.0.0.0:9001 0.0.0.0:9002 0.0.0.0:9003 --cluster-replicas 1
注意事项:主节点在前,从节点在后。其中--cluster-replicas参数用来指定一个主节点带有的从节点个数,如--cluster-replicas 1即表示1个主节点有1个从节点。
上述命令执行完后的结果如下:

至此,成功使用集群管理工具搭建redis缓存集群。
五、测试效果
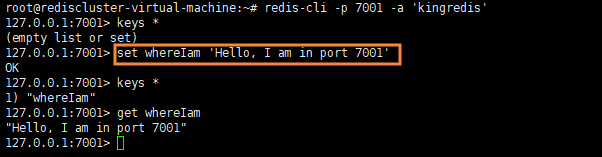
1)首先,我们进入端口号为7001的节点,并在里面存储数据。如下所示:
2)接下来,我们进入端口号为9002的节点,查看其中的数据,并尝试获取key为whereIam的数据。如下所示:

可以看到,成功获取到了key为whereIam的数据。需要注意的是:命令中要加入-c选项,表示启动集群模式操作数据。否则会报如下错误:
